Récemment, j'ai participé au développement de la fonctionnalité qui nécessitait un transfert rapide et fréquent de gros volumes de données sur disque. De plus, ces données étaient censées être lues à partir du disque de temps en temps. Par conséquent, j'étais destiné à découvrir l'endroit, la manière et les moyens de stocker ces données. Dans cet article, je vais brièvement passer en revue la tâche, ainsi que rechercher et comparer des solutions pour l'achèvement de cette tâche.
Contexte de la tâche :Je travaille dans une équipe qui développe des outils de développement relatif de bases de données (SQL Server, MySQL, Oracle). La gamme d'outils comprend à la fois des outils autonomes et des compléments pour MS SSMS.
Tâche :Restauration des documents qui ont été ouverts au moment de la fermeture de l'IDE au prochain démarrage de l'IDE.
Cas d'utilisation :Pour fermer IDE rapidement avant de quitter le bureau sans penser aux documents qui ont été sauvegardés, et lesquels ne l'ont pas été. Au prochain démarrage de l'IDE, nous devons récupérer le même environnement qu'au moment de la fermeture et continuer le travail. Tous les résultats de travail doivent être sauvegardés au moment de la fermeture désordonnée, par ex. pendant le plantage d'un programme ou d'un système d'exploitation, ou pendant la mise hors tension.
Analyse des tâches :La fonctionnalité similaire est présente dans les navigateurs Web. Cependant, les navigateurs stockent uniquement les URL composées d'environ 100 symboles. Dans notre cas, nous devons stocker l'intégralité du contenu du document. Par conséquent, nous avons besoin d'un endroit pour enregistrer et stocker les documents de l'utilisateur. De plus, les utilisateurs travaillent parfois avec SQL d'une manière différente qu'avec d'autres langages. Par exemple, si j'écris une classe C# de plus de 1000 lignes, ce sera difficilement acceptable. Alors que, dans l'univers SQL, parallèlement aux requêtes de 10 à 20 lignes, les vidages monstrueux de la base de données existent. Ces vidages sont difficilement modifiables, ce qui signifie que les utilisateurs préfèrent conserver leurs modifications en toute sécurité.
Exigences pour un stockage :
- Il doit s'agir d'une solution intégrée légère.
- Il doit avoir une vitesse d'écriture élevée.
- Il devrait avoir une option d'accès multitraitement. Cette exigence n'est pas critique, car nous pouvons garantir l'accès à l'aide des objets de synchronisation, mais ce serait quand même bien d'avoir cette option.
Candidats
Le premier candidat est plutôt maladroit, c'est-à-dire de tout stocker dans un dossier, quelque part dans AppData.
Le deuxième candidat est évident - SQLite, un standard de bases de données embarquées. Candidat très solide et populaire.
Le troisième candidat est la base de données LiteDB. Il s'agit du premier résultat de la requête "base de données intégrée pour .net" dans Google.
Première vue
Système de fichiers. Les fichiers sont des fichiers, ils nécessitent une maintenance et une dénomination appropriée. Outre le contenu du fichier, nous aurons besoin de stocker un petit ensemble de propriétés (chemin d'origine sur le disque, chaîne de connexion, version de l'IDE dans lequel il a été ouvert). Cela signifie que nous devrons soit créer deux fichiers pour un document, soit inventer un format qui sépare les propriétés du contenu.
SQLite est une base de données relationnelle classique. La base de données est représentée par un fichier sur disque. Ce fichier est lié au schéma de la base de données, après quoi nous devons interagir avec lui à l'aide des moyens SQL. Nous pourrons créer 2 tables, une pour les propriétés et l'autre pour le contenu, - au cas où nous aurions besoin d'utiliser les propriétés ou le contenu séparément.
LiteDB est une base de données non relationnelle. Semblable à SQLite, la base de données est représentée par un seul fichier. Il est entièrement écrit en С#. Sa simplicité d'utilisation est captivante :il suffit de donner un objet à la bibliothèque, tandis que la sérialisation se fera par ses propres moyens.
Test de performances
Avant de fournir du code, j'aimerais expliquer la conception générale et fournir des résultats de comparaison.
La conception générale compare la vitesse d'écriture d'une grande quantité de petits fichiers dans la base de données, la quantité moyenne de fichiers moyens et une petite quantité de gros fichiers. Le cas avec des fichiers moyens est majoritairement proche du cas réel, tandis que les cas avec des fichiers petits et gros sont des cas limites, qu'il faut également prendre en compte.
J'écrivais du contenu dans un fichier à l'aide de FileStream avec la taille de tampon standard.
Il y avait une nuance dans SQLite que je voudrais mentionner. Nous n'avons pas pu mettre tout le contenu du document (comme je l'ai mentionné ci-dessus, ils peuvent être très volumineux) dans une cellule de base de données. Le fait est qu'à des fins d'optimisation, nous stockons le texte du document ligne par ligne. Cela signifie que pour mettre du texte dans une seule cellule, nous devons mettre tous les documents dans une seule ligne, ce qui doublerait la quantité de mémoire de fonctionnement utilisée. L'autre côté du problème se révélerait lors de la lecture des données de la base de données. C'est pourquoi, il y avait une table séparée dans SQLite, où les données étaient stockées ligne par ligne et les données étaient liées à l'aide d'une clé étrangère avec la table contenant uniquement les propriétés du fichier. De plus, j'ai réussi à accélérer la base de données avec l'insertion de données par lots (plusieurs milliers de lignes à la fois) en mode de synchronisation OFF sans journalisation et en une seule transaction.
LiteDB a reçu un objet ayant List parmi ses propriétés et la bibliothèque l'a enregistré sur disque tout seul.
Au cours du développement de l'application de test, j'ai compris que je préférais LiteDB. Le fait est que le code de test pour SQLite prend plus de 120 lignes, alors que le code, qui résout le même problème dans LiteDb, ne prend que 20 lignes.
Tester la génération de données
FileStrings.cs
classe interne FileStrings { private static readonly Random random =new Random(); chaînes de liste publiques { obtenir ; Positionner; } =nouvelle liste(); public int SomeInfo { obtenir ; Positionner; } public FileStrings() { } public FileStrings(int id, int minLines, decimal lineIncrement) { SomeInfo =id; int lines =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES)) .ToList();
SQLite
private static void SaveToDb(List files) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Data Source=data\database.db;FailIfMissing=False;"; connexion.Open(); var commande =connexion.CreateCommand(); command.CommandText =@"CREATE TABLE files( id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings( id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number); PRAGMA synchrone =OFF ; PRAGMA journal_mode =OFF" ; command.ExecuteNonQuery(); var insertFilecommand =connection.CreateCommand(); insertFilecommand.CommandText ="INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =connection.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (élément var dans les fichiers) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } private static void SaveToDb (élément FileStrings, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =fileName; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0 ; foreach (var line in item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(List item) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("files"); data.EnsureIndex(f => f.SomeInfo); data.Insert(item); } }
Le tableau suivant montre les résultats moyens pour plusieurs exécutions du code de test. Lors des modifications, l'écart statistique était assez imperceptible.
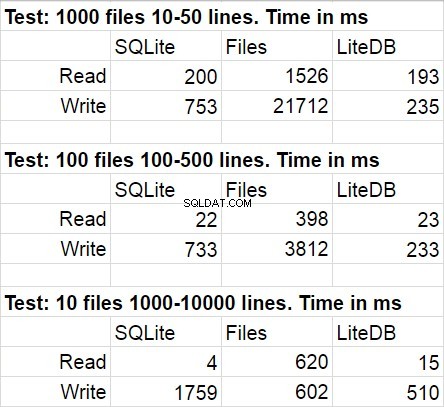
Je n'ai pas été surpris que LiteDB ait gagné dans cette comparaison. Cependant, j'ai été choqué par la victoire de LiteDB sur les fichiers. Après une brève étude du référentiel de la bibliothèque, j'ai découvert une écriture paginale sur disque très méticuleusement implémentée, mais je suis sûr que ce n'est qu'une des nombreuses astuces de performance utilisées là-bas. Une autre chose que je voudrais souligner est une vitesse rapide d'accès au système de fichiers qui diminue lorsque la quantité de fichiers dans le dossier devient très importante.
Nous avons sélectionné LiteDB pour le développement de notre fonctionnalité, et nous n'avons guère regretté ce choix. Le fait est que la bibliothèque est écrite en C# natif pour tout le monde, et si quelque chose n'était pas tout à fait clair, nous pourrions toujours nous référer au code source.
Inconvénients
Outre les avantages mentionnés ci-dessus de LiteDB par rapport à ses concurrents, nous avons commencé à remarquer des inconvénients au cours du développement. La plupart de ces inconvénients peuvent être expliqués par la « jeunesse » de la bibliothèque. Après avoir commencé à utiliser la bibliothèque légèrement au-delà des limites du scénario "standard", nous avons découvert plusieurs problèmes (#419, #420, #483, #496). L'auteur de la bibliothèque a répondu assez rapidement aux questions et la plupart des problèmes ont été rapidement résolus. Maintenant, il ne reste qu'une seule tâche (ne pas confondre avec son statut Fermé). C'est une question d'accès concurrentiel. Il semble qu'une race-condition très désagréable se cache quelque part au fond de la bibliothèque. Nous avons passé ce bug de manière assez originale (j'ai l'intention d'écrire un article séparé sur ce sujet).
Je voudrais également mentionner l'absence d'éditeur et de visualiseur soignés. Il existe LiteDBShell, mais uniquement pour les vrais fans de consoles.
Résumé
Nous avons construit une grande et importante fonctionnalité sur LiteDB, et maintenant nous travaillons sur une autre grande fonctionnalité où nous utiliserons également cette bibliothèque. Pour ceux qui recherchent une base de données en cours, je suggère de prêter attention à LiteDB et à la façon dont elle fera ses preuves dans le contexte de votre tâche, car, comme vous le savez, si quelque chose avait fonctionné pour une tâche, cela ne serait pas nécessairement préparez-vous pour une autre tâche.



