L'analyse de données XML à l'aide de XQuery est une pratique courante. Afin de le faire le plus efficacement possible, peu d'efforts sont nécessaires.
Supposons que nous ayons besoin d'analyser les données du fichier disque avec la structure suivante :
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Utilisez BULK INSERT, si vous avez besoin de lire des données à partir d'un fichier :
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Un exemple de fichier xml est ici.
Cependant, gardez à l'esprit une chose en particulier… Essayez de ne pas lire les données directement :
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Affecter des données à une variable. De cette façon, vous pouvez obtenir un plan d'exécution plus efficace :
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Comparez les résultats :
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Comme vous pouvez le constater, la deuxième option est nettement plus rapide.
Une autre caractéristique importante de SQL Server lorsque vous travaillez avec XQuery est que la lecture d'un élément parent peut entraîner de mauvaises performances. Prenons l'exemple suivant :
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Examinons le nombre réel de lignes reçues de l'opérateur. La valeur est anormalement grande :
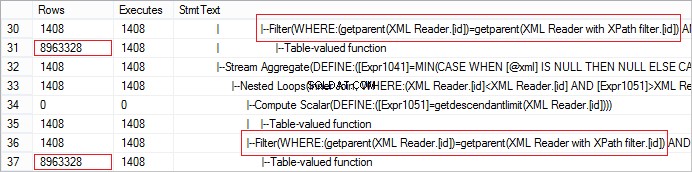
La demande peut être facilement optimisée en utilisant CROSS APPLY :
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Comparons le temps d'exécution :
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Comme vous pouvez le voir sur l'exemple, la requête avec CROSS APPLY fonctionne instantanément.
Merci de votre attention. J'espère que cet article a été utile. N'hésitez pas à poser des questions, laisser vos commentaires et suggestions concernant cet article.