Introduction
Stocker des données est une chose; stocker significatif, utile, correct les données en sont une autre. Alors que le sens et l'utilité sont eux-mêmes des qualités subjectives, l'exactitude peut au moins être logiquement définie et appliquée. Les types garantissent déjà que les nombres sont des nombres et que les dates sont des dates, mais ne peuvent pas garantir que le poids ou la distance sont des nombres positifs ou empêcher les plages de dates de se chevaucher. Les contraintes de tuple, de table et de base de données appliquent des règles aux données stockées et rejettent les valeurs ou les combinaisons de valeurs qui ne réussissent pas.
Les contraintes ne rendent aucunement inutiles les autres techniques de validation des entrées, même lorsqu'elles testent les mêmes assertions. Le temps passé à essayer et à échouer à stocker des données invalides est du temps perdu. Message de violation, comme assert dans les systèmes et les langages de programmation d'application, ne révèle que le premier problème avec le premier enregistrement de candidat de manière beaucoup plus détaillée que quiconque n'est pas immédiatement impliqué dans les besoins de la base de données. Mais en ce qui concerne l'exactitude des données, les contraintes font loi, pour le meilleur ou pour le pire; tout le reste est un conseil.
Sur les tuples :Not Null, Default et Check
Les contraintes non nulles sont la catégorie la plus simple. Un tuple doit avoir une valeur pour l'attribut contraint, ou en d'autres termes, l'ensemble des valeurs autorisées pour la colonne n'inclut plus l'ensemble vide. Aucune valeur signifie aucun tuple :l'insertion ou la mise à jour est rejetée.
La protection contre les valeurs nulles est aussi simple que de déclarer column_name COLUMN_TYPE NOT NULL dans CREATE TABLE ou ADD COLUMN . Les valeurs nulles causent des catégories entières de problèmes entre la base de données et les utilisateurs finaux, donc définir par réflexe des contraintes non nulles sur n'importe quelle colonne sans une bonne raison d'autoriser les valeurs nulles est une bonne habitude à prendre.
La fourniture d'une valeur par défaut si rien n'est précisé (par omission ou un NULL explicite ) dans une insertion ou une mise à jour n'est pas toujours considérée comme une contrainte, puisque les enregistrements candidats sont modifiés et stockés au lieu d'être rejetés. Dans de nombreux SGBD, les valeurs par défaut peuvent être générées par une fonction, bien que MySQL n'autorise pas les fonctions définies par l'utilisateur à cette fin.
Toute autre règle de validation qui dépend uniquement des valeurs d'un seul tuple peut être implémentée en tant que CHECK contrainte. Dans un sens, NOT NULL lui-même est un raccourci pour CHECK (column_name IS NOT NULL); le message d'erreur reçu en violation fait la majeure partie de la différence. CHECK , cependant, peut appliquer et faire respecter la vérité de n'importe quel prédicat booléen sur un seul tuple. Par exemple, une table stockant des emplacements géographiques doit CHECK (latitude >= -90 AND latitude < 90) , et de même pour la longitude entre -180 et 180 -- ou, si disponible, utilisez et validez une GEOGRAPHY type de données.
Sur les tables :unique et exclusion
Les contraintes au niveau de la table testent les tuples les uns par rapport aux autres. Dans une contrainte unique, un seul enregistrement peut avoir un ensemble donné de valeurs pour les colonnes contraintes. La nullité peut causer des problèmes ici, car NULL n'est jamais égal à autre chose, jusqu'à et y compris NULL lui-même. Une contrainte unique sur (batman, robin) permet donc des copies infinies de n'importe quel Batman sans Robin.
Les contraintes d'exclusion ne sont prises en charge que dans PostgreSQL et DB2, mais remplissent une niche très utile :elles peuvent empêcher les chevauchements. Spécifiez les champs contraints et les opérations par lesquelles chacun sera évalué, et un nouvel enregistrement ne sera accepté que si aucun enregistrement existant n'est comparable avec chaque champ et opération. Par exemple, un schedules table peut être configurée pour rejeter les conflits :
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Opérations d'upsert telles que ON CONFLICT de PostgreSQL ou la clause ON DUPLICATE KEY UPDATE de MySQL utiliser une contrainte au niveau de la table pour détecter les conflits. Et comme les contraintes non nulles peuvent être exprimées sous la forme CHECK contraintes, une contrainte d'unicité peut être exprimée comme une contrainte d'exclusion sur l'égalité.
La clé primaire
Les contraintes uniques ont un cas particulier particulièrement utile. Avec une contrainte supplémentaire non nulle sur la ou les colonnes uniques, chaque enregistrement de la table peut être identifié individuellement par ses valeurs pour les colonnes contraintes, qui sont collectivement appelées une clé . Plusieurs clés candidates peuvent coexister dans une table, telles que users ayant encore parfois un email distinct unique et non nul s et username s ; mais déclarer une clé primaire établit un critère unique selon lequel les enregistrements sont publiquement et exclusivement connus. Certains SGBDR organisent même les lignes sur les pages par la clé primaire, appelée à cet effet un index cluster , pour rendre la recherche par valeurs de clé primaire aussi rapide que possible.
Il existe deux types de clé primaire. Une clé naturelle est définie sur une colonne ou des colonnes incluses "naturellement" dans les données de la table, tandis qu'une clé de substitution ou synthétique est inventée uniquement dans le but de devenir la clé. Les clés naturelles nécessitent des soins -- plus de choses peuvent changer que les concepteurs de bases de données ne le pensent souvent, des noms aux schémas de numérotation. Une table de recherche contenant des noms de pays et de régions peut utiliser leurs codes ISO 3166 respectifs comme clé primaire naturelle sûre, mais un users table avec une clé naturelle basée sur des valeurs modifiables telles que des noms ou des adresses e-mail invite les ennuis. En cas de doute, créez une clé de substitution.
Si une clé naturelle s'étend sur plusieurs colonnes, une clé de substitution doit toujours au moins être envisagée, car les clés multi-colonnes nécessitent plus d'efforts à gérer. Si la clé naturelle convient, cependant, les colonnes doivent être triées par ordre croissant de spécificité comme elles le sont dans les index :code de pays alors code de région, plutôt que l'inverse.
La clé de substitution a toujours été une seule colonne entière, ou BIGINT où des milliards seront éventuellement affectés. Les bases de données relationnelles peuvent remplir automatiquement les clés de substitution avec le prochain entier d'une série, une fonctionnalité généralement appelée SERIAL ou IDENTITY .
Un compteur numérique à incrémentation automatique n'est pas sans inconvénients :l'ajout d'enregistrements avec des clés prégénérées peut provoquer des conflits, et si des valeurs séquentielles sont exposées aux utilisateurs, il leur est facile de deviner quelles pourraient être les autres clés valides. Les identificateurs universels uniques, ou UUID, évitent ces faiblesses et sont devenus un choix courant pour les clés de substitution, bien qu'ils soient également beaucoup plus gros dans la page qu'un simple numéro. Les types d'UUID v1 (basé sur l'adresse MAC) et v4 (pseudo-aléatoire) sont les plus fréquemment utilisés.
Sur la base de données :clés étrangères
Les bases de données relationnelles implémentent une seule classe de contraintes multi-tables, l'
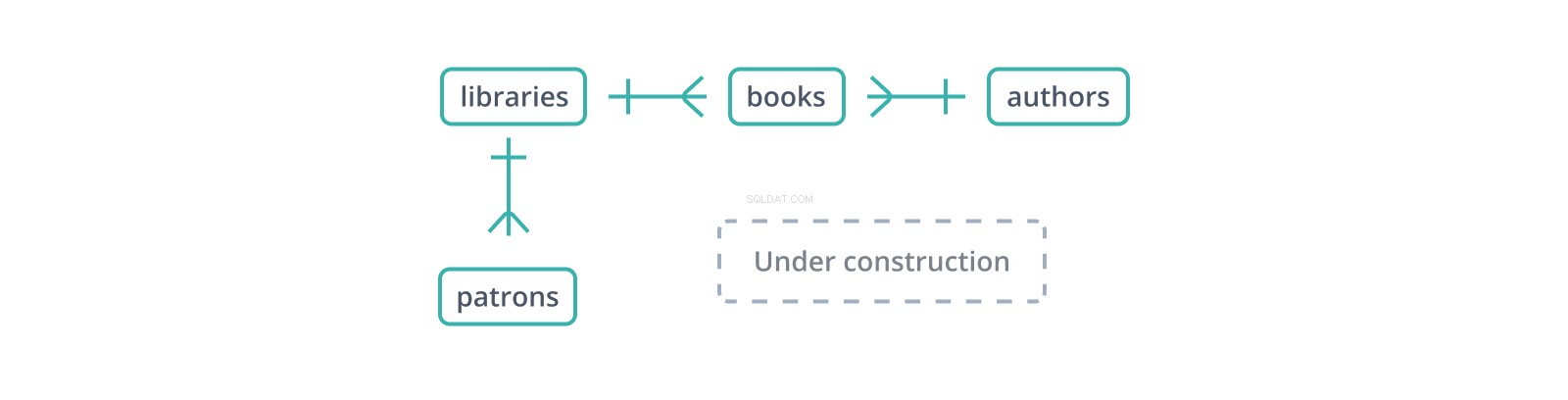
Ce "diagramme entité-relation" informel ou ERD montre les débuts d'un schéma pour une base de données des bibliothèques et de leurs collections et usagers. Chaque arête représente une relation entre les tables qu'elle connecte. Le | Le glyphe indique un seul enregistrement sur le côté, tandis que le glyphe "patte d'oie" en représente plusieurs :une bibliothèque contient de nombreux livres et a de nombreux usagers.
Une clé étrangère est une copie de la clé primaire d'une autre table, colonne par colonne (un point en faveur des clés de substitution :une seule colonne à copier et à référencer), avec des valeurs liant les enregistrements de cette table aux enregistrements "parents" qu'elle contient. Dans le schéma ci-dessus, les books table maintient un library_id clé étrangère vers les libraries , qui contiennent des livres, et un author_id aux authors , qui les écrivent. Mais que se passe-t-il si un livre est inséré avec un author_id qui n'existe pas dans authors ?
Si la clé étrangère n'est pas contrainte - c'est-à-dire qu'il s'agit simplement d'une autre colonne ou de colonnes - un livre peut avoir un auteur qui n'existe pas. C'est un problème :si quelqu'un essaie de suivre le lien entre les books et authors , ils finissent nulle part. Si authors.author_id est un entier en série, il est également possible que personne ne le remarque jusqu'à ce que le faux author_id est finalement attribué, et vous vous retrouvez avec une copie particulière de Don Quichotte attribué d'abord à personne connue puis à Pierre Menard, avec Miguel Cervantes introuvable.
Contraindre la clé étrangère ne peut pas empêcher qu'un livre soit mal attribué si le author_id erroné pointe vers une notice existante dans authors , les autres vérifications et tests restent donc importants. Cependant, l'ensemble des valeurs de clés étrangères existantes est presque toujours un petit sous-ensemble des possibles valeurs de clé étrangère, de sorte que les contraintes de clé étrangère intercepteront et empêcheront la plupart des valeurs erronées. Avec une contrainte de clé étrangère, le Quichotte avec un auteur inexistant sera rejeté au lieu d'être enregistré.
Est-ce de là que vient le "relationnel" dans "base de données relationnelle" ?
Les clés étrangères créent des relations entre les tables, mais les tables telles que nous les connaissons sont mathématiquement des relations parmi les ensembles de valeurs possibles pour chaque attribut. Un tuple unique relie une valeur de la colonne A à une valeur de la colonne B et au-delà. L'article original d'E.F. Codd utilise "relationnel" dans ce sens.
Cela a causé une confusion sans fin et continuera probablement à le faire à perpétuité.
Pour certaines valeurs de Correct
Il existe de nombreuses autres façons dont les données peuvent être incorrectes que celles abordées ici. Les contraintes aident, mais même elles ne sont que si flexibles; de nombreuses spécifications intra-table courantes, comme une limite de deux ou plus sur le nombre de fois qu'une valeur est autorisée à apparaître dans une colonne, ne peuvent être appliquées qu'avec des déclencheurs.
Mais il y a aussi des façons dont la structure même d'un tableau peut conduire à des incohérences. Pour éviter cela, nous devrons rassembler les clés primaires et étrangères non seulement pour définir et valider, mais pour normaliser les relations entre les tables. Mais d'abord, nous avons à peine effleuré la façon dont les relations entre les tables définissent la structure de la base de données elle-même.