Présentation
Ce tutoriel comprend des informations sur SQL (DDL, DML) que j'ai recueillies au cours de ma vie professionnelle. C'est le minimum que vous devez savoir lorsque vous travaillez avec des bases de données. S'il est nécessaire d'utiliser des constructions SQL complexes, je surfe généralement sur la bibliothèque MSDN, qui peut être facilement trouvée sur Internet. À mon avis, il est très difficile de tout garder en tête et, soit dit en passant, ce n'est pas nécessaire. Je vous recommande de connaître toutes les principales constructions utilisées dans la plupart des bases de données relationnelles telles qu'Oracle, MySQL et Firebird. Pourtant, ils peuvent différer dans les types de données. Par exemple, pour créer des objets (tables, contraintes, index, etc.), vous pouvez simplement utiliser un environnement de développement intégré (IDE) pour travailler avec des bases de données et il n'est pas nécessaire d'étudier des outils visuels pour un type de base de données particulier (MS SQL, Oracle , MySQL, Firebird, etc.). C'est pratique car vous pouvez voir tout le texte et vous n'avez pas besoin de parcourir de nombreux onglets pour créer, par exemple, un index ou une contrainte. Si vous travaillez constamment avec des bases de données, créer, modifier et surtout reconstruire un objet à l'aide de scripts est beaucoup plus rapide qu'en mode visuel. De plus, à mon avis, en mode script (avec la précision requise), il est plus facile de spécifier et de contrôler les règles de nommage des objets. De plus, il est pratique d'utiliser des scripts lorsque vous devez transférer des modifications de base de données d'une base de données de test vers une base de données de production.
SQL est divisé en plusieurs parties. Dans mon article, je passerai en revue les plus importantes :
DDL – Langage de définition de données
LMD – Langage de manipulation de données, qui comprend les constructions suivantes :
- SELECT - sélection de données
- INSERT – insertion de nouvelles données
- MISE À JOUR - mise à jour des données
- DELETE - suppression des données
- MERGE – fusion de données
J'expliquerai toutes les constructions dans des études de cas. De plus, je pense qu'un langage de programmation, en particulier SQL, devrait être étudié dans la pratique pour une meilleure compréhension.
Il s'agit d'un tutoriel étape par étape, où vous devez effectuer des exemples tout en le lisant. Cependant, si vous avez besoin de connaître les détails de la commande, naviguez sur Internet, par exemple, MSDN.
Lors de la création de ce didacticiel, j'ai utilisé la base de données MS SQL Server, version 2014, et MS SQL Server Management Studio (SSMS) pour exécuter des scripts.
En bref MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) est l'utilitaire Microsoft SQL Server pour la configuration, la gestion et l'administration des composants de base de données. Il comprend un éditeur de script et un programme graphique qui fonctionne avec les objets et les paramètres du serveur. L'outil principal de SQL Server Management Studio est l'Explorateur d'objets, qui permet à un utilisateur d'afficher, de récupérer et de gérer des objets serveur. Ce texte est partiellement extrait de Wikipédia.
Pour créer un nouvel éditeur de script, utilisez le bouton Nouvelle requête :
Pour passer de la base de données actuelle, vous pouvez utiliser le menu déroulant :
Pour exécuter une commande particulière ou un ensemble de commandes, mettez-le en surbrillance et appuyez sur le bouton Exécuter ou sur F5. S'il n'y a qu'une seule commande dans l'éditeur ou si vous devez exécuter toutes les commandes, ne mettez rien en surbrillance.
Après avoir exécuté des scripts qui créent des objets (tables, colonnes, index), sélectionnez l'objet correspondant (par exemple, Tables ou Colonnes), puis cliquez sur Actualiser dans le menu contextuel pour voir les modifications.
En fait, c'est tout ce que vous devez savoir pour exécuter les exemples fournis ici.
Théorie
Une base de données relationnelle est un ensemble de tables liées entre elles. En général, une base de données est un fichier qui stocke des données structurées.
Le système de gestion de base de données (SGBD) est un ensemble d'outils permettant de travailler avec des types de bases de données particuliers (MS SQL, Oracle, MySQL, Firebird, etc.).
Remarque : Comme dans notre quotidien, on dit "Oracle DB" ou juste "Oracle" signifiant en fait "Oracle SGBD", alors dans ce tutoriel, j'utiliserai le terme "base de données".
Un tableau est un ensemble de colonnes. Très souvent, vous pouvez entendre les définitions suivantes de ces termes :champs, lignes et enregistrements, qui signifient la même chose.
Une table est l'objet principal de la base de données relationnelle. Toutes les données sont stockées ligne par ligne dans les colonnes du tableau.
Pour chaque tableau ainsi que pour ses colonnes, vous devez spécifier un nom, selon lequel vous pouvez trouver un élément requis.
Le nom de l'objet, de la table, de la colonne et de l'index peut avoir la longueur minimale - 128 symboles.
Remarque : Dans les bases de données Oracle, un nom d'objet peut avoir la longueur minimale - 30 symboles. Ainsi, dans une base de données particulière, il est nécessaire de créer des règles personnalisées pour les noms d'objets.
SQL est un langage qui permet d'exécuter des requêtes dans des bases de données via un SGBD. Dans un SGBD particulier, un langage SQL peut avoir son propre dialecte.
DDL et DML – le sous-langage SQL :
- Le langage DDL sert à créer et modifier une structure de base de données (suppression de table et de lien) ;
- Le langage DML permet de manipuler les données d'un tableau, ses lignes. Il sert également à sélectionner des données dans des tables, à ajouter de nouvelles données, ainsi qu'à mettre à jour et à supprimer des données actuelles.
Il est possible d'utiliser deux types de commentaires en SQL (sur une seule ligne et délimités) :
-- commentaire sur une seule ligne
et
/* commentaire délimité */
C'est tout pour la théorie.
LDD – Langage de définition de données
Considérons un exemple de tableau avec des données sur les employés représentés d'une manière familière à une personne qui n'est pas un programmeur.
| ID d'employé | Nom complet | Date de naissance | Position | Département | |
| 1 000 | Jean | 19.02.1955 | exemple@sqldat.com | PDG | Administration |
| 1001 | Daniel | 03.12.1983 | exemple@sqldat.com | programmeur | informatique |
| 1002 | Mike | 07.06.1976 | exemple@sqldat.com | Comptable | Comptabilité |
| 1003 | Jordanie | 17.04.1982 | exemple@sqldat.com | Programmeur senior | informatique |
Dans ce cas, les colonnes ont les titres suivants :ID d'employé, Nom complet, Date de naissance, E-mail, Poste et Service.
Nous pouvons décrire chaque colonne de ce tableau par son type de données :
- ID d'employé – nombre entier
- Nom complet – chaîne
- Date de naissance – date
- E-mail – chaîne
- Position – chaîne
- Département – chaîne
Un type de colonne est une propriété qui spécifie le type de données que chaque colonne peut stocker.
Pour commencer, vous devez vous souvenir des principaux types de données utilisés dans MS SQL :
| Définition | Désignation dans MS SQL | Description |
| Chaîne de longueur variable | varchar(N) et nvarchar(N) | En utilisant le nombre N, nous pouvons spécifier la longueur de chaîne maximale possible pour une colonne particulière. Par exemple, si on veut dire que la valeur de la colonne Full Name peut contenir 30 symboles (au plus), alors il faut préciser le type de nvarchar(30).
La différence entre varchar et nvarchar est que varchar permet de stocker des chaînes au format ASCII, tandis que nvarchar stocke des chaînes au format Unicode, où chaque symbole prend 2 octets. |
| Chaîne de longueur fixe | car(N) et nchar(N) | Ce type diffère de la chaîne de longueur variable dans ce qui suit :si la longueur de la chaîne est inférieure à N symboles, des espaces sont toujours ajoutés à la longueur N à droite. Ainsi, dans une base de données, il faut exactement N symboles, où un symbole prend 1 octet pour char et 2 octets pour nchar. Dans ma pratique, ce type n'est pas beaucoup utilisé. Pourtant, si quelqu'un l'utilise, alors généralement ce type a le format char(1), c'est-à-dire lorsqu'un champ est défini par 1 symbole. |
| Entier | entier | Ce type nous permet d'utiliser uniquement des entiers (positifs et négatifs) dans une colonne. Remarque :une plage de numéros pour ce type est la suivante :de 2 147 483 648 à 2 147 483 647. Il s'agit généralement du type principal utilisé pour identifier les identifiants. |
| Nombre à virgule flottante | flottant | Nombres avec un point décimal. |
| Date | date | Il est utilisé pour stocker uniquement une date (date, mois et année) dans une colonne. Par exemple, 15/02/2014. Ce type peut être utilisé pour les colonnes suivantes :date de réception, date de naissance, etc., lorsque vous devez spécifier uniquement une date ou lorsque l'heure n'est pas importante pour nous et que nous pouvons la supprimer. |
| Heure | heure | Vous pouvez utiliser ce type s'il est nécessaire de stocker l'heure :heures, minutes, secondes et millisecondes. Par exemple, vous avez 17:38:31.3231603 ou vous devez ajouter l'heure de départ du vol. |
| Date et heure | dateheure | Ce type permet aux utilisateurs de stocker à la fois la date et l'heure. Par exemple, vous avez l'événement le 15/02/2014 17:38:31.323. |
| Indicateur | bit | Vous pouvez utiliser ce type pour stocker des valeurs telles que "Oui"/"Non", où "Oui" est 1 et "Non" est 0. |
De plus, il n'est pas nécessaire de préciser la valeur du champ, sauf si cela est interdit. Dans ce cas, vous pouvez utiliser NULL.
Pour exécuter des exemples, nous allons créer une base de données de test nommée "Test".
Pour créer une base de données simple sans aucune propriété supplémentaire, exécutez la commande suivante :
Test CRÉER UNE BASE DE DONNÉES
Pour supprimer une base de données, exécutez cette commande :
Test de suppression de la base de données
Pour basculer vers notre base de données, utilisez la commande :
TEST D'UTILISATION
Vous pouvez également sélectionner la base de données de test dans le menu déroulant de la zone de menu SSMS.
Maintenant, nous pouvons créer un tableau dans notre base de données en utilisant des descriptions, des espaces et des symboles cyrilliques :
CREATE TABLE [Employés]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar( 30) )
Dans ce cas, nous devons mettre les noms entre crochets […].
Néanmoins, il est préférable de spécifier tous les noms d'objets en latin et de ne pas utiliser d'espaces dans les noms. Dans ce cas, chaque mot commence par une majuscule. Par exemple, pour le champ "EmployeeID", nous pourrions spécifier le nom PersonnelNumber. Vous pouvez également utiliser des chiffres dans le nom, par exemple, PhoneNumber1.
Remarque : Dans certains SGBD, il est plus pratique d'utiliser le format de nom suivant «PHONE_NUMBER». Par exemple, vous pouvez voir ce format dans les bases de données ORACLE. De plus, le nom du champ ne doit pas coïncider avec les mots clés utilisés dans le SGBD.
Pour cette raison, vous pouvez oublier la syntaxe des crochets et supprimer la table Employés :
SUPPRIMER TABLE [Employés]
Par exemple, vous pouvez nommer la table avec les employés comme "Employés" et définir les noms suivants pour ses champs :
- ID
- Nom
- Anniversaire
- Poste
- Département
Très souvent, nous utilisons ‘ID’ pour le champ identifiant.
Maintenant, créons un tableau :
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Pour définir les colonnes obligatoires, vous pouvez utiliser l'option NOT NULL.
Pour la table en cours, vous pouvez redéfinir les champs à l'aide des commandes suivantes :
-- champ ID updateALTER TABLE Employees ALTER COLUMN ID int NOT NULL-- Name field updateALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Remarque : Le concept général du langage SQL pour la plupart des SGBD est le même (d'après ma propre expérience). La différence entre les DDL dans différents SGBD réside principalement dans les types de données (ils peuvent différer non seulement par leurs noms mais aussi par leur implémentation spécifique). De plus, l'implémentation SQL spécifique (commandes) est la même, mais il peut y avoir de légères différences dans le dialecte. Connaissant les bases de SQL, vous pouvez facilement passer d'un SGBD à un autre. Dans ce cas, vous n'aurez qu'à comprendre les spécificités de l'implémentation des commandes dans un nouveau SGBD.
Comparez les mêmes commandes dans le SGBD ORACLE :
-- create table CREATE TABLE Employees( ID int, -- Dans ORACLE le type int est une valeur pour number(38) Name nvarchar2(30), -- dans ORACLE nvarchar2 est identique à nvarchar dans MS SQL Date d'anniversaire, E-mail nvarchar2(30), Poste nvarchar2(30), Département nvarchar2(30) ); -- Mise à jour des champs ID et Nom (ici nous utilisons MODIFY(…) au lieu de ALTER COLUMNALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (dans ce cas la construction est la même comme dans MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE diffère dans l'implémentation du type varchar2. Son format dépend des paramètres de la base de données et vous pouvez enregistrer un texte, par exemple, en UTF-8. De plus, vous pouvez spécifier la longueur du champ en octets et en symboles. Pour ce faire, vous devez utiliser les valeurs BYTE et CHAR suivies du champ de longueur. Par exemple :
NAME varchar2(30 BYTE) – la capacité du champ est égale à 30 octets NAME varchar2(30 CHAR) -- la capacité du champ est égale à 30 symboles
La valeur (BYTE ou CHAR) à utiliser par défaut lorsque vous indiquez simplement varchar2(30) dans ORACLE dépendra des paramètres de la base de données. Souvent, vous pouvez être facilement confus. Ainsi, je recommande de spécifier explicitement CHAR lorsque vous utilisez le type varchar2 (par exemple, avec UTF-8) dans ORACLE (car il est plus pratique de lire la longueur de la chaîne en symboles).
Cependant, dans ce cas, s'il y a des données dans la table, alors pour exécuter avec succès les commandes, il est nécessaire de remplir les champs ID et Nom dans toutes les lignes de la table.
Je vais le montrer dans un exemple particulier.
Insérons des données dans les champs ID, Poste et Service à l'aide du script suivant :
INSERT Employees(ID,Position,Department) VALUES (1000,'CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Programmeur principal',N'IT')
Dans ce cas, la commande INSERT renvoie également une erreur. Cela se produit parce que nous n'avons pas spécifié la valeur du champ obligatoire Nom.
S'il y avait des données dans la table d'origine, la commande "ALTER TABLE Employees ALTER COLUMN ID int NOT NULL" fonctionnerait, tandis que la commande "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" renverrait une erreur que le champ Nom a Valeurs NULL.
Ajoutons des valeurs dans le champ Nom :
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan')
De plus, vous pouvez utiliser NOT NULL lors de la création d'une nouvelle table avec l'instruction CREATE TABLE.
Dans un premier temps, supprimons un tableau :
SUPPRIMER TABLE Employés
Maintenant, nous allons créer une table avec les champs obligatoires ID et Nom :
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
De plus, vous pouvez spécifier NULL après un nom de colonne, ce qui implique que les valeurs NULL sont autorisées. Ce n'est pas obligatoire, car cette option est définie par défaut.
Si vous devez rendre la colonne actuelle non obligatoire, utilisez la syntaxe suivante :
ALTER TABLE Employés ALTER COLUMN Nom nvarchar(30) NULL
Vous pouvez également utiliser cette commande :
ALTER TABLE Employés ALTER COLUMN Nom nvarchar(30)
De plus, avec cette commande, nous pouvons soit modifier le type de champ en un autre compatible, soit changer sa longueur. Par exemple, étendons le champ Nom à 50 symboles :
ALTER TABLE Employés ALTER COLUMN Nom nvarchar(50)
Clé primaire
Lors de la création d'un tableau, vous devez spécifier une colonne ou un ensemble de colonnes unique pour chaque ligne. À l'aide de cette valeur unique, vous pouvez identifier un enregistrement. Cette valeur est appelée la clé primaire. La colonne ID (qui contient « le numéro personnel d'un employé » - dans notre cas, il s'agit de la valeur unique pour chaque employé et ne peut pas être dupliquée) peut être la clé primaire de notre table Employés.
Vous pouvez utiliser la commande suivante pour créer une clé primaire pour la table :
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
‘PK_Employees’ est un nom de contrainte définissant la clé primaire. Habituellement, le nom d'une clé primaire se compose du préfixe "PK_" et du nom de la table.
Si la clé primaire contient plusieurs champs, alors vous devez lister ces champs entre parenthèses séparés par une virgule :
ALTER TABLE nom_table ADD CONSTRAINT nom_contrainte PRIMARY KEY(field1,field2,…)
Gardez à l'esprit que dans MS SQL, tous les champs de la clé primaire doivent être NOT NULL.
De plus, vous pouvez définir une clé primaire lors de la création d'une table. Supprimons le tableau :
SUPPRIMER TABLE Employés
Ensuite, créez une table en utilisant la syntaxe suivante :
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK après tous les champs comme contrainte )
Ajouter des données au tableau :
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
En fait, vous n'avez pas besoin de spécifier le nom de la contrainte. Dans ce cas, un nom de système sera attribué. Par exemple, « PK__Employé__3214EC278DA42077 » :
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
ou
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Personnellement, je recommanderais de spécifier explicitement le nom de la contrainte pour les tables permanentes, car il est plus facile de travailler avec ou de supprimer une valeur explicitement définie et claire à l'avenir. Par exemple :
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Néanmoins, il est plus confortable d'appliquer cette syntaxe courte, sans noms de contraintes lors de la création de tables de base de données temporaires (le nom d'une table temporaire commence par # ou ##.
Résumé :
Nous avons déjà analysé les commandes suivantes :
- CRÉER UN TABLEAU table_name (liste des champs et de leurs types, ainsi que des contraintes) - sert à créer une nouvelle table dans la base de données actuelle ;
- SUPPRIMER LE TABLEAU table_name – sert à supprimer une table de la base de données actuelle ;
- ALTER TABLE table_name ALTER COLUMN nom_colonne … – sert à mettre à jour le type de colonne ou à modifier ses paramètres (par exemple, lorsque vous devez définir NULL ou NOT NULL);
- ALTER TABLE table_name AJOUTER UNE CONTRAINTE nom_contrainte CLÉ PRIMAIRE (champ1, champ2,…) - utilisé pour ajouter une clé primaire à la table courante ;
- ALTER TABLE table_name SUPPRIMER LA CONTRAINTE nom_contrainte – utilisé pour supprimer une contrainte de la table.
Tableaux temporaires
Résumé de MSDN. Il existe deux types de tables temporaires dans MS SQL Server :locales (#) et globales (##). Les tables temporaires locales ne sont visibles que par leurs créateurs avant que l'instance de SQL Server ne soit déconnectée. Ils sont automatiquement supprimés après la déconnexion de l'utilisateur de l'instance de SQL Server. Les tables temporaires globales sont visibles par tous les utilisateurs lors de toutes les sessions de connexion après la création de ces tables. Ces tables sont supprimées une fois que les utilisateurs sont déconnectés de l'instance de SQL Server.
Les tables temporaires sont créées dans la base de données système tempdb, ce qui signifie que nous n'inondons pas la base de données principale. De plus, vous pouvez les supprimer à l'aide de la commande DROP TABLE. Très souvent, des tables temporaires locales (#) sont utilisées.
Pour créer une table temporaire, vous pouvez utiliser la commande CREATE TABLE :
CRÉER TABLE #Temp( ID int, Nom nvarchar(30) )
Vous pouvez supprimer la table temporaire avec la commande DROP TABLE :
DOP TABLE #Temp
De plus, vous pouvez créer une table temporaire et la remplir avec les données en utilisant la syntaxe SELECT … INTO :
SELECT ID,Name INTO #Temp FROM Employees
Remarque : Dans différents SGBD, l'implémentation des bases de données temporaires peut varier. Par exemple, dans les SGBD ORACLE et Firebird, la structure des tables temporaires doit être définie au préalable par la commande CREATE GLOBAL TEMPORARY TABLE. En outre, vous devez spécifier le mode de stockage des données. Après cela, un utilisateur le voit parmi les tables communes et travaille avec comme avec une table conventionnelle.
Normalisation de la base de données :fractionnement en sous-tables (tables de référence) et définition des relations entre les tables
Notre table Employés actuelle présente un inconvénient :un utilisateur peut saisir n'importe quel texte dans les champs Poste et Service, ce qui peut renvoyer des erreurs, car pour un employé, il peut spécifier "IT" comme service, tandis que pour un autre employé, il peut spécifier "IT département". Par conséquent, on ne comprendra pas ce que l'utilisateur voulait dire, si ces employés travaillent pour le même service ou s'il y a une faute d'orthographe et qu'il y a 2 services différents. De plus, dans ce cas, nous ne pourrons pas regrouper correctement les données pour un rapport, où nous devons afficher le nombre d'employés pour chaque service.
Un autre inconvénient est le volume de stockage et sa duplication, c'est-à-dire qu'il faut spécifier un nom complet de service pour chaque employé, ce qui nécessite de la place dans les bases de données pour stocker chaque symbole du nom de service.
Le troisième inconvénient est la complexité de la mise à jour des données de terrain lorsque vous devez modifier le nom de n'importe quel poste - du programmeur au programmeur junior. Dans ce cas, vous devrez ajouter de nouvelles données dans chaque ligne du tableau où le poste est "Programmeur".
Pour éviter de telles situations, il est recommandé d'utiliser la normalisation de la base de données - fractionnement en sous-tables - tables de référence.
Créons 2 tables de référence "Postes" et "Départements":
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) PAS NULL )
Notez qu'ici nous avons utilisé une nouvelle propriété IDENTITY. Cela signifie que les données de la colonne ID seront automatiquement répertoriées en commençant par 1. Ainsi, lors de l'ajout de nouveaux enregistrements, les valeurs 1, 2, 3, etc. seront attribuées de manière séquentielle. Généralement, ces champs sont appelés champs d'auto-incrémentation. Un seul champ avec la propriété IDENTITY peut être défini comme clé primaire dans une table. Habituellement, mais pas toujours, ce champ est la clé primaire de la table.
Remarque : Dans différents SGBD, l'implémentation des champs avec un incrémenteur peut différer. Dans MySQL, par exemple, un tel champ est défini par la propriété AUTO_INCREMENT. Dans ORACLE et Firebird, vous pouvez émuler cette fonctionnalité par des séquences (SEQUENCE). Mais pour autant que je sache, la propriété GENERATED AS IDENTITY a été ajoutée dans ORACLE.
Remplissons ces tables automatiquement en fonction des données actuelles des champs Poste et Service de la table Employés :
-- remplissez le champ Nom de la table Postes avec des valeurs uniques du champ Poste de la table Employés INSERT Postes(Nom) SELECT DISTINCT Poste FROM Employés WHERE Poste N'EST PAS NULL – supprimer les enregistrements où un poste n'est pas spécifiéVous devez effectuer les mêmes étapes pour la table Départements :
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULLMaintenant, si nous ouvrons les tables Postes et Départements, nous verrons une liste numérotée de valeurs dans le champ ID :
SELECT * FROM Postes
| ID | Nom |
| 1 | Comptable |
| 2 | PDG |
| 3 | Programmeur |
| 4 | Programmeur senior |
SELECT * FROM Départements
| identifiant | Nom |
| 1 | Administration |
| 2 | Comptabilité |
| 3 | informatique |
Ces tables seront les tables de référence pour définir les postes et les départements. Maintenant, nous nous référerons aux identifiants des postes et des départements. Dans un premier temps, créons de nouveaux champs dans la table Employés pour stocker les identifiants :
-- ajouter un champ pour le poste ID ALTER TABLE Employees ADD PositionID int -- ajouter un champ pour le département ID ALTER TABLE Employees ADD DepartmentID int
Le type des champs de référence doit être le même que dans les tables de référence, dans ce cas, c'est int.
De plus, vous pouvez ajouter plusieurs champs à l'aide d'une seule commande en listant les champs séparés par des virgules :
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Maintenant, nous allons ajouter des contraintes de référence (CLÉ ÉTRANGÈRE) à ces champs, afin qu'un utilisateur ne puisse ajouter aucune valeur qui ne soit pas les valeurs d'ID des tables de référence.
ALTER TABLE Employés ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Les mêmes étapes doivent être effectuées pour le deuxième champ :
ALTER TABLE Employés ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Désormais, les utilisateurs ne peuvent insérer dans ces champs que les valeurs d'ID de la table de référence correspondante. Ainsi, pour utiliser un nouveau service ou poste, un utilisateur doit ajouter un nouvel enregistrement dans la table de référence correspondante. Comme les postes et les départements sont stockés dans des tables de référence en un seul exemplaire, pour changer leur nom, vous devez le changer uniquement dans la table de référence.
Le nom d'une contrainte de référence est généralement composé. Il se compose du préfixe « FK » suivi d'un nom de table et d'un nom de champ qui fait référence à l'identifiant de la table de référence.
L'identifiant (ID) est généralement une valeur interne utilisée uniquement pour les liens. Peu importe sa valeur. Ainsi, n'essayez pas de vous débarrasser des lacunes dans la séquence de valeurs qui apparaissent lorsque vous travaillez avec la table, par exemple lorsque vous supprimez des enregistrements de la table de référence.
Dans certains cas, il est possible de construire une référence à partir de plusieurs champs :
ALTER TABLE table ADD CONSTRAINT nom_contrainte FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
Dans ce cas, une clé primaire est représentée par un ensemble de plusieurs champs (champ1, champ2, …) dans la table "reference_table".
Maintenant, mettons à jour les champs PositionID et DepartmentID avec les valeurs d'ID des tables de référence.
Pour cela, nous allons utiliser la commande UPDATE :
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employés e
Exécutez la requête suivante :
SELECT * FROM Employés
| identifiant | Nom | Anniversaire | Position | Département | ID de position | ID de service | |
| 1 000 | Jean | NULL | NULL | PDG | Administration | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Programmeur | informatique | 3 | 3 |
| 1002 | Mike | NULL | NULL | Comptable | Comptabilité | 1 | 2 |
| 1003 | Jordanie | NULL | NULL | Programmeur senior | informatique | 4 | 3 |
Comme vous pouvez le constater, les champs PositionID et DepartmentID correspondent aux postes et aux services. Ainsi, vous pouvez supprimer les champs Poste et Service dans la table Employés en exécutant la commande suivante :
ALTER TABLE Employés DROP COLUMN Poste, Département
Maintenant, exécutez cette instruction :
SELECT * FROM Employés
| ID | Nom | Anniversaire | ID de position | ID de service | |
| 1 000 | Jean | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordanie | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
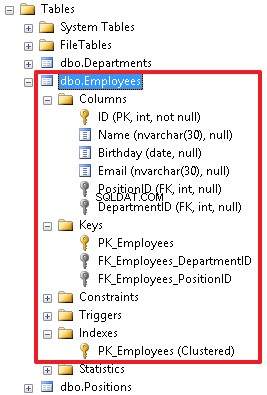
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
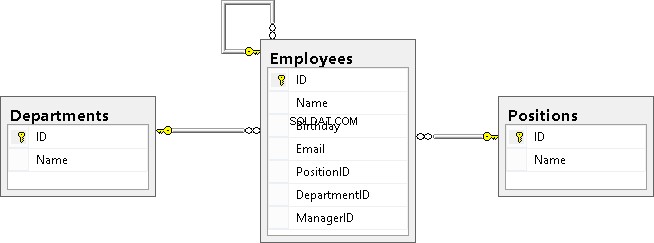
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ONINSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
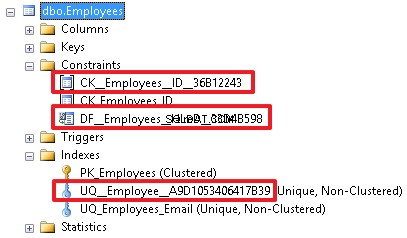
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Summary
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.



