Un équilibreur de charge de base de données, ou proxy inverse de base de données, distribue la charge de travail entrante de la base de données sur plusieurs serveurs de base de données exécutés derrière lui. Les objectifs des équilibreurs de charge de base de données sont de fournir un point de terminaison de base de données unique aux applications auxquelles se connecter, d'augmenter le débit des requêtes, de minimiser la latence et de maximiser l'utilisation des ressources des serveurs de base de données.
Il peut y avoir deux manières de topologie d'équilibreur de charge de base de données :
- Topologie centralisée
- Topologie distribuée
Dans cet article de blog, nous allons couvrir les deux topologies et comprendre certains avantages et inconvénients de chaque configuration. Aussi, serait-il possible de mélanger les deux topologies ensemble ?
Topologie centralisée
Dans une configuration centralisée, un proxy inverse est situé entre les niveaux de données et de présentation, comme représenté par le schéma suivant :
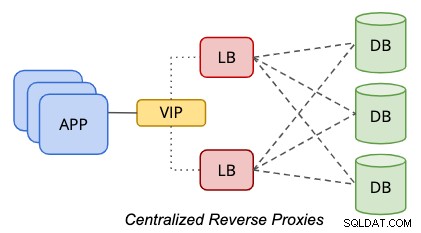
Pour éliminer un point de défaillance unique, il faut définir deux ou plusieurs nœuds d'équilibrage de charge à des fins de redondance. Si votre application peut gérer plusieurs points de terminaison de base de données, par exemple, si l'application ou le pilote de base de données est capable d'effectuer des vérifications de l'état si l'équilibreur de charge est sain pour le traitement des requêtes, vous pouvez probablement ignorer la partie adresse IP virtuelle. Sinon, les deux nœuds d'équilibrage de charge doivent être liés avec un nom d'hôte ou une adresse IP virtuelle communs, pour assurer la transparence aux clients de base de données où il suffit d'utiliser un seul point de terminaison de base de données pour accéder au niveau données. L'utilisation du DNS ou du mappage d'hôte est également possible si vous souhaitez ignorer l'utilisation d'adresses IP virtuelles.
Cette approche basée sur les niveaux est beaucoup plus simple à gérer en raison de son placement d'hôte statique indépendant. Il est très peu probable que le niveau d'équilibrage de charge soit mis à l'échelle (en ajoutant plus de nœuds) en raison de sa base solide de résilience, de redondance et de transparence pour le niveau d'application. Vous devrez probablement faire évoluer l'hôte (en ajoutant plus de ressources à l'hôte), ce qui se produira généralement longtemps dans le futur, après que les charges de travail de l'équilibreur de charge soient devenues plus exigeantes à mesure que votre entreprise se développe.
Cette topologie nécessite un niveau et des hôtes supplémentaires, ce qui peut être coûteux dans une infrastructure bare metal avec des serveurs physiques. Cette configuration est plus facile à gérer dans un cloud ou un environnement virtuel, où vous avez la possibilité d'ajouter un niveau supplémentaire entre le niveau application et base de données, sans vous coûter trop cher sur le coût de l'infrastructure physique comme l'électricité, l'espace rack et les coûts de mise en réseau.
Topologie distribuée
Dans une configuration de topologie distribuée, les équilibreurs de charge sont colocalisés au sein de la couche de présentation (serveurs d'application ou Web), comme simplifié par le schéma suivant :
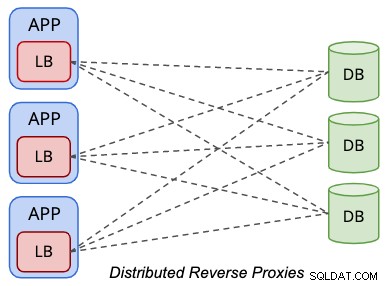
Les applications traitent l'équilibreur de charge de base de données de la même manière qu'un serveur de base de données local, où le L'équilibreur de charge devient la représentation des bases de données distantes du point de vue de l'application. Généralement, l'équilibreur de charge écoutera l'interface réseau locale comme 127.0.0.1 ou "localhost", ce qui rationalisera l'hôte de la base de données du point de terminaison de la base de données pour les applications.
L'un des avantages de l'exécution dans cette topologie est que vous n'avez pas besoin d'hôtes supplémentaires à des fins d'équilibrage de charge. En combinant le niveau d'équilibrage de charge au sein du niveau de présentation, nous pourrions économiser au moins deux hôtes. Dans un environnement sans système d'exploitation, cette topologie pourrait potentiellement vous faire économiser beaucoup d'argent au fil des ans. Généralement, la charge de travail de l'équilibreur de charge est beaucoup moins exigeante par rapport aux charges de travail de base de données ou d'application, ce qui justifie le partage des mêmes ressources matérielles avec les applications.
Lorsqu'il est colocalisé avec le serveur d'applications, vous rapprochez le proxy inverse de l'application et éliminez le point de défaillance unique. Cela peut améliorer considérablement les performances de l'application lorsque vous avez une séparation géographique entre l'application et la couche de données, en particulier pour les équilibreurs de charge de base de données qui prennent en charge la mise en cache des jeux de résultats comme ProxySQL et MaxScale. D'autre part, le nombre d'équilibreurs de charge de base de données est généralement égal au nombre de nœuds d'application, ce qui signifie que si le niveau d'application est mis à l'échelle, le nombre d'équilibreurs de charge de base de données augmentera, ce qui pourrait potentiellement dégrader les performances pour la santé de la base de données. vérifier le service. Notez que les vérifications de l'état de l'équilibreur de charge sont un peu plus bavardes en raison de sa responsabilité de suivre l'état correct des nœuds de la base de données.
Avec l'aide d'outils d'automatisation de l'infrastructure informatique tels que Chef, Puppet et Ansible, ainsi que des outils d'orchestration de conteneurs, il n'est plus impossible d'automatiser le déploiement et la gestion de plusieurs instances d'équilibrage de charge pour cette topologie. Cependant, il y aura une autre courbe d'apprentissage pour l'équipe d'exploitation pour proposer des politiques de déploiement et de gestion de niveau production testées au combat afin de réduire le travail excessif lors de la gestion de nombreux nœuds d'équilibrage de charge. Ne manquez pas tous les aspects de gestion importants pour l'équilibreur de charge de base de données, tels que la sauvegarde/restauration, la mise à niveau/rétrogradation, la gestion de la configuration, le contrôle des services, la gestion des pannes, etc.
La topologie distribuée peut être mélangée avec la topologie centralisée pour certains équilibreurs de charge de base de données pris en charge comme ProxySQL, comme illustré dans le schéma suivant :
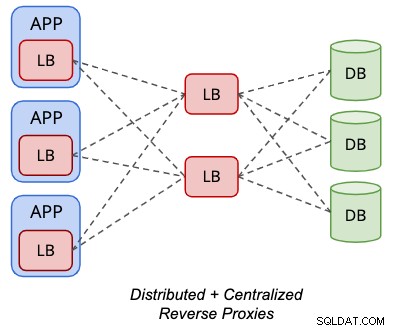
Les "serveurs" principaux d'une instance ProxySQL peuvent être un autre ensemble de ProxySQL nœuds à la place. Avec cette configuration, une adresse IP virtuelle n'est pas nécessaire pour l'accès d'un point de terminaison unique aux nœuds de la base de données, puisque l'instance ProxySQL locale hébergée localement sur le serveur d'application sera l'accès au point de terminaison unique du point de vue de l'application.
Cependant, cela nécessite deux versions de configurations d'équilibreur de charge - une qui réside sur le niveau d'application et une autre réside sur les niveaux d'équilibreur de charge. Cela nécessite également plus d'hôtes, excluant la nécessité de se renseigner sur la technologie d'adresse IP virtuelle, le basculement IP, etc. Les avantages et les inconvénients des configurations distribuées et centralisées sont fusionnés dans cette topologie.
Conclusion
Chaque topologie a ses propres avantages et inconvénients et doit être bien planifiée dès le début. Cette décision précoce est essentielle et peut grandement influencer les performances, l'évolutivité, la fiabilité et la disponibilité de votre application à long terme.