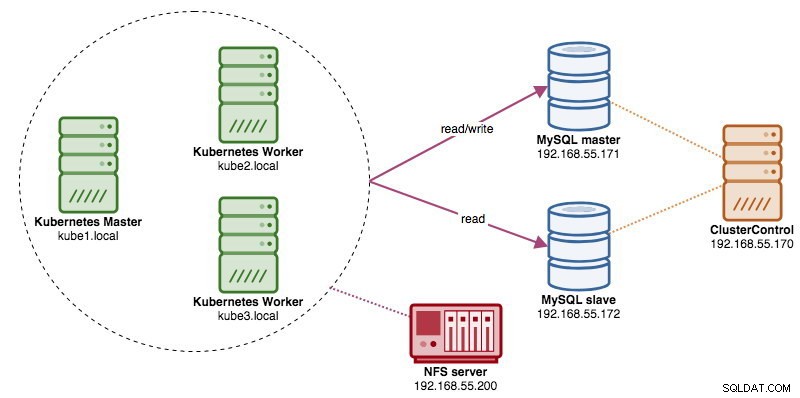
Lors de l'exécution de clusters de bases de données distribuées, il est assez courant de les associer à des équilibreurs de charge. Les avantages sont clairs :équilibrage de charge, basculement de connexion et découplage du niveau application des topologies de base de données sous-jacentes. Pour un équilibrage de charge plus intelligent, un proxy compatible avec les bases de données comme ProxySQL ou MaxScale serait la solution. Dans notre blog précédent, nous vous avons montré comment exécuter ProxySQL en tant que conteneur d'assistance dans Kubernetes. Dans cet article de blog, nous vous montrerons comment déployer ProxySQL en tant que service Kubernetes. Nous utiliserons Wordpress comme exemple d'application et le backend de la base de données s'exécute sur une réplication MySQL à deux nœuds déployée à l'aide de ClusterControl. Le schéma suivant illustre notre infrastructure :
Étant donné que nous allons déployer une configuration similaire à celle de cet article de blog précédent, attendez-vous à des doublons dans certaines parties de l'article de blog pour que l'article reste plus lisible.
ProxySQL sur Kubernetes
Commençons par un petit récapitulatif. La conception d'une architecture ProxySQL est un sujet subjectif et dépend fortement du placement de l'application, des conteneurs de base de données ainsi que du rôle de ProxySQL lui-même. Idéalement, nous pouvons configurer ProxySQL pour qu'il soit géré par Kubernetes avec deux configurations :
- ProxySQL en tant que service Kubernetes (déploiement centralisé)
- ProxySQL en tant que conteneur d'assistance dans un pod (déploiement distribué)
Les deux déploiements peuvent être distingués facilement en regardant le schéma suivant :
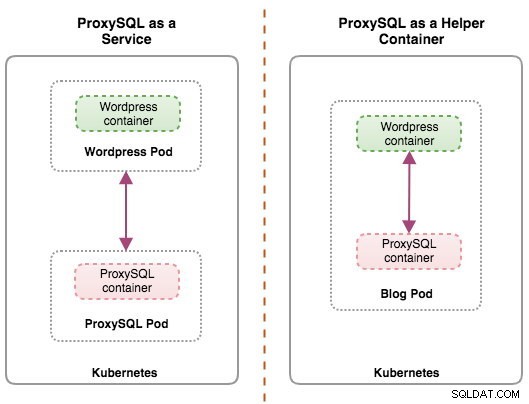
Ce billet de blog couvrira la première configuration - exécuter ProxySQL en tant que service Kubernetes. La deuxième configuration est déjà couverte ici. Contrairement à l'approche du conteneur d'assistance, l'exécution en tant que service permet aux pods ProxySQL de fonctionner indépendamment des applications et peut être facilement mis à l'échelle et regroupé à l'aide de Kubernetes ConfigMap. Il s'agit certainement d'une approche de clustering différente de la prise en charge du clustering natif ProxySQL qui repose sur la somme de contrôle de configuration sur les instances ProxySQL (alias proxysql_servers). Consultez cet article de blog si vous souhaitez en savoir plus sur le clustering ProxySQL simplifié avec ClusterControl.
Dans Kubernetes, le système de configuration multicouche de ProxySQL rend possible le clustering de pods avec ConfigMap. Cependant, il existe un certain nombre de lacunes et de solutions de contournement pour que cela fonctionne correctement comme le fait la fonctionnalité de clustering native de ProxySQL. Pour le moment, la signalisation d'un pod lors de la mise à jour de ConfigMap est une fonctionnalité en cours. Nous aborderons ce sujet plus en détail dans un prochain article de blog.
Fondamentalement, nous devons créer des pods ProxySQL et attacher un service Kubernetes auquel les autres pods du réseau Kubernetes ou de l'extérieur pourront accéder. Les applications se connecteront ensuite au service ProxySQL via le réseau TCP/IP sur les ports configurés. La valeur par défaut est 6033 pour les connexions à équilibrage de charge MySQL et 6032 pour la console d'administration ProxySQL. Avec plus d'un réplica, les connexions au pod seront automatiquement équilibrées par le composant Kubernetes kube-proxy exécuté sur chaque nœud Kubernetes.
ProxySQL en tant que service Kubernetes
Dans cette configuration, nous exécutons à la fois ProxySQL et Wordpress en tant que pods et services. Le schéma suivant illustre notre architecture de haut niveau :
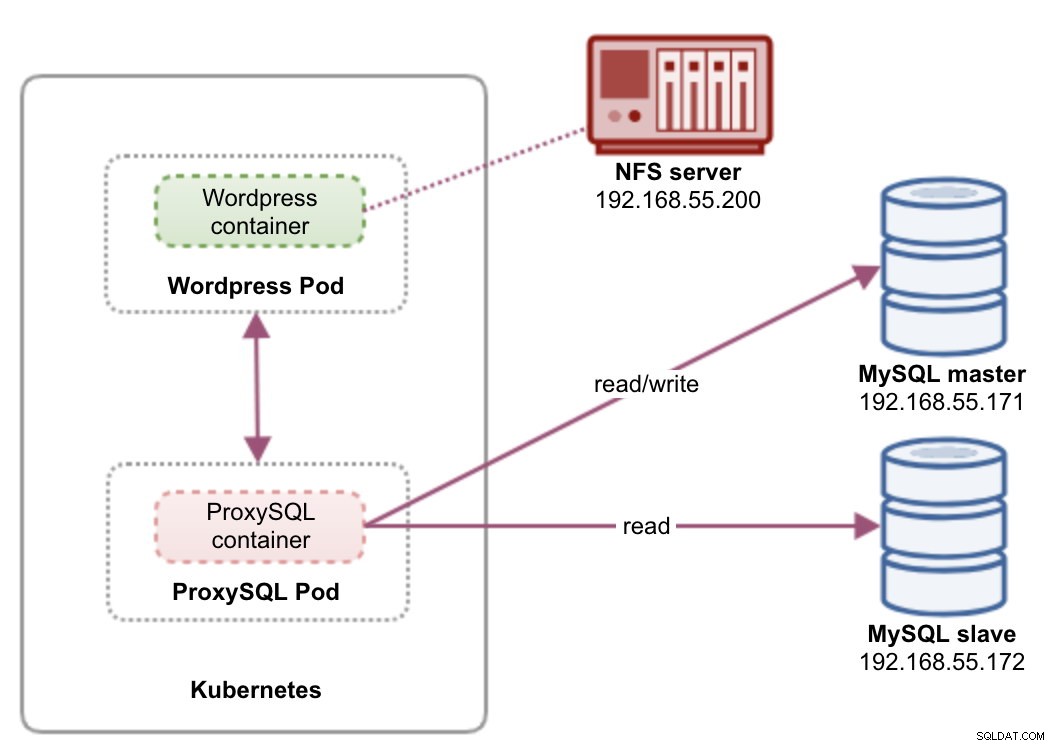
Dans cette configuration, nous allons déployer deux pods et services - "wordpress" et "proxysql". Nous fusionnerons la déclaration de déploiement et de service dans un fichier YAML par application et les gérerons comme une seule unité. Pour conserver le contenu des conteneurs d'application persistant sur plusieurs nœuds, nous devons utiliser un système de fichiers en cluster ou distant, qui dans ce cas est NFS.
Le déploiement de ProxySQL en tant que service apporte quelques avantages par rapport à l'approche du conteneur d'assistance :
- En utilisant l'approche ConfigMap de Kubernetes, ProxySQL peut être mis en cluster avec une configuration immuable.
- Kubernetes gère la récupération ProxySQL et équilibre automatiquement les connexions aux instances.
- Point de terminaison unique avec mise en œuvre d'une adresse IP virtuelle Kubernetes appelée ClusterIP.
- Niveau de proxy inverse centralisé avec architecture sans partage
- Peut être utilisé avec des applications externes en dehors de Kubernetes.
Nous commencerons le déploiement avec deux répliques pour ProxySQL et trois pour Wordpress afin de démontrer l'exécution à grande échelle et les capacités d'équilibrage de charge offertes par Kubernetes.
Préparer la base de données
Créez la base de données wordpress et l'utilisateur sur le maître et attribuez-leur le privilège correct :
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Créez également l'utilisateur de surveillance ProxySQL :
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Ensuite, rechargez le tableau des subventions :
mysql-master> FLUSH PRIVILEGES;Pod et définition de service ProxySQL
La prochaine consiste à préparer notre déploiement ProxySQL. Créez un fichier nommé proxysql-rs-svc.yml et ajoutez les lignes suivantes :
apiVersion: v1
kind: Deployment
metadata:
name: proxysql
labels:
app: proxysql
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: proxysql
tier: frontend
spec:
restartPolicy: Always
containers:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap
---
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendVoyons en quoi consistent ces définitions. Le YAML se compose de deux ressources combinées dans un fichier, séparées par le délimiteur "---". La première ressource est le Déploiement, dont nous définissons la spécification suivante :
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdateCe qui précède signifie que nous aimerions déployer deux pods ProxySQL en tant que ReplicaSet qui correspond aux conteneurs étiquetés avec "app=proxysql,tier=frontend". La stratégie de déploiement spécifie la stratégie utilisée pour remplacer les anciens pods par de nouveaux. Dans ce déploiement, nous avons choisi RollingUpdate, ce qui signifie que les pods seront mis à jour de manière continue, un pod à la fois.
La partie suivante est le modèle du conteneur :
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmapDans spec.templates.spec.containers.* section, nous disons à Kubernetes de déployer ProxySQL en utilisant plusieurs neufs/proxysql image version 1.4.12. Nous souhaitons également que Kubernetes monte notre fichier de configuration préconfiguré personnalisé et le mappe sur /etc/proxysql.cnf à l'intérieur du conteneur. Les pods en cours d'exécution publieront deux ports - 6033 et 6032. Nous définissons également la section "volumes", dans laquelle nous demandons à Kubernetes de monter le ConfigMap en tant que volume à l'intérieur des pods ProxySQL à monter par volumeMounts.
La deuxième ressource est le service. Un service Kubernetes est une couche d'abstraction qui définit l'ensemble logique de pods et une politique permettant d'y accéder. Dans cette section, nous définissons les éléments suivants :
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendDans ce cas, nous voulons que notre ProxySQL soit accessible depuis le réseau externe, donc le type NodePort est le type choisi. Cela publiera le nodePort sur tous les nœuds Kubernetes du cluster. La plage de ports valides pour la ressource NodePort est 30000-32767. Nous avons choisi le port 30033 pour les connexions MySQL à charge équilibrée qui est mappé sur le port 6033 des pods ProxySQL et le port 30032 pour le port d'administration ProxySQL mappé sur 6032.
Par conséquent, sur la base de notre définition YAML ci-dessus, nous devons préparer la ressource Kubernetes suivante avant de pouvoir commencer à déployer le pod "proxysql" :
- ConfigMap :pour stocker le fichier de configuration ProxySQL en tant que volume afin qu'il puisse être monté sur plusieurs pods et puisse être remonté si le pod est reprogrammé sur l'autre nœud Kubernetes.
Préparation de ConfigMap pour ProxySQL
Semblable au billet de blog précédent, nous allons utiliser l'approche ConfigMap pour découpler le fichier de configuration du conteneur et également à des fins d'évolutivité. Notez que dans cette configuration, nous considérons que notre configuration ProxySQL est immuable.
Tout d'abord, créez le fichier de configuration ProxySQL, proxysql.cnf et ajoutez les lignes suivantes :
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="proxysql-admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)Faites attention aux admin_variables.admin_credentials variable où nous avons utilisé l'utilisateur non par défaut qui est "proxysql-admin". ProxySQL réserve l'utilisateur "admin" par défaut pour la connexion locale via localhost uniquement. Par conséquent, nous devons utiliser d'autres utilisateurs pour accéder à distance à l'instance ProxySQL. Sinon, vous obtiendrez l'erreur suivante :
ERROR 1040 (42000): User 'admin' can only connect locallyNotre configuration ProxySQL est basée sur nos deux serveurs de base de données exécutés dans la réplication MySQL, comme résumé dans la capture d'écran de la topologie suivante tirée de ClusterControl :
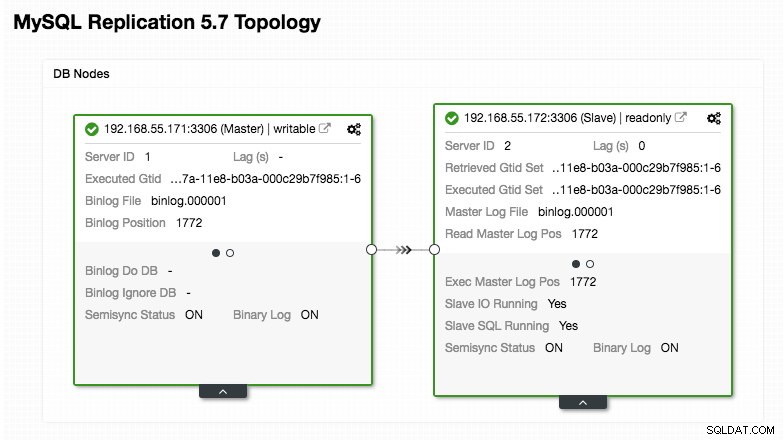
Toutes les écritures doivent aller au nœud maître tandis que les lectures sont transmises au groupe d'hôtes 20, comme défini dans la section "mysql_query_rules". C'est la base du fractionnement lecture/écriture et nous voulons les utiliser ensemble.
Ensuite, importez le fichier de configuration dans ConfigMap :
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVérifiez si le ConfigMap est chargé dans Kubernetes :
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sPod WordPress et définition de service
Maintenant, collez les lignes suivantes dans un fichier appelé wordpress-rs-svc.yml sur l'hôte où kubectl est configuré :
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033 # proxysql.default.svc.cluster.local:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_DATABASE
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendSemblable à notre définition ProxySQL, le YAML se compose de deux ressources, séparées par le délimiteur "---" combiné dans un fichier. La première est la ressource Deployment, qui sera déployée en tant que ReplicaSet, comme indiqué dans la section "spec.*" :
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdateCette section fournit la spécification de déploiement - 3 pods pour démarrer qui correspond à l'étiquette "app=wordpress,tier=backend". La stratégie de déploiement est RollingUpdate, ce qui signifie que Kubernetes remplacera le pod en utilisant le mode de mise à jour progressive, comme avec notre déploiement ProxySQL.
La partie suivante est la section "spec.template.spec.*" :
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
Dans cette section, nous indiquons à Kubernetes de déployer Wordpress 4.9 à l'aide du serveur Web Apache et nous avons donné au conteneur le nom "wordpress". Le conteneur sera redémarré chaque fois qu'il est arrêté, quel que soit son état. Nous souhaitons également que Kubernetes transmette un certain nombre de variables d'environnement :
- WORDPRESS_DB_HOST - L'hébergeur de la base de données MySQL. Puisque nous utilisons ProxySQL en tant que service, le nom du service sera la valeur de metadata.name qui est "proxysql". ProxySQL écoute sur le port 6033 les connexions à charge équilibrée MySQL tandis que la console d'administration ProxySQL est sur 6032.
- WORDPRESS_DB_USER - Spécifiez l'utilisateur de la base de données wordpress qui a été créé dans la section "Préparation de la base de données".
- WORDPRESS_DB_PASSWORD - Le mot de passe pour WORDPRESS_DB_USER . Puisque nous ne voulons pas exposer le mot de passe dans ce fichier, nous pouvons le cacher en utilisant Kubernetes Secrets. Ici, nous demandons à Kubernetes de lire la ressource secrète "mysql-pass" à la place. Les secrets doivent être créés à l'avance avant le déploiement du pod, comme expliqué plus bas.
Nous souhaitons également publier le port 80 du pod pour l'utilisateur final. Le contenu Wordpress stocké dans /var/www/html dans le conteneur sera monté dans notre stockage persistant fonctionnant sur NFS. Nous utiliserons les ressources PersistentVolume et PersistentVolumeClaim à cette fin, comme indiqué dans la section "Préparation du stockage persistant pour Wordpress".
Après la ligne de rupture "---", nous définissons une autre ressource appelée Service :
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendDans cette configuration, nous aimerions que Kubernetes crée un service appelé "wordpress", écoute sur le port 30088 sur tous les nœuds (alias NodePort) vers le réseau externe et le transmette au port 80 sur tous les pods étiquetés avec "app=wordpress,tier=frontal".
Par conséquent, sur la base de notre définition YAML ci-dessus, nous devons préparer un certain nombre de ressources Kubernetes avant de pouvoir commencer à déployer le pod et le service "wordpress" :
- Volume persistant et PersistentVolumeClaim - Pour stocker le contenu Web de notre application Wordpress, ainsi, lorsque le pod est reprogrammé vers un autre nœud de travail, nous ne perdrons pas les dernières modifications.
- Secrets - Pour masquer le mot de passe de l'utilisateur de la base de données Wordpress dans le fichier YAML.
Préparer le stockage persistant pour Wordpress
Un bon stockage persistant pour Kubernetes doit être accessible par tous les nœuds Kubernetes du cluster. Pour les besoins de cet article de blog, nous avons utilisé NFS comme fournisseur PersistentVolume (PV) car il est simple et pris en charge immédiatement. Le serveur NFS est situé quelque part en dehors de notre réseau Kubernetes (comme indiqué dans le premier schéma d'architecture) et nous l'avons configuré pour autoriser tous les nœuds Kubernetes avec la ligne suivante dans /etc/exports :
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Notez que le package client NFS doit être installé sur tous les nœuds Kubernetes. Sinon, Kubernetes ne pourrait pas monter correctement le NFS. Sur tous les nœuds :
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSAssurez-vous également que sur le serveur NFS, le répertoire cible existe :
(nfs-server)$ mkdir /nfs/kubernetes/wordpressEnsuite, créez un fichier appelé wordpress-pv-pvc.yml et ajoutez les lignes suivantes :
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: wordpress
tier: frontendDans la définition ci-dessus, nous disons à Kubernetes d'allouer 3 Go d'espace de volume sur le serveur NFS pour notre conteneur Wordpress. Notez que pour une utilisation en production, NFS doit être configuré avec un provisionneur automatique et une classe de stockage.
Créez les ressources PV et PVC :
$ kubectl create -f wordpress-pv-pvc.ymlVérifiez si ces ressources sont créées et que le statut doit être "Lié" :
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hPréparer les secrets pour Wordpress
Créez un secret à utiliser par le conteneur Wordpress pour WORDPRESS_DB_PASSWORD variables d'environnement. La raison est simplement parce que nous ne voulons pas exposer le mot de passe en texte clair dans le fichier YAML.
Créez une ressource secrète appelée mysql-pass et transmettez le mot de passe en conséquence :
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVérifiez que notre secret est créé :
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mDéployer ProxySQL et Wordpress
Enfin, nous pouvons commencer le déploiement. Déployez d'abord ProxySQL, suivi de Wordpress :
$ kubectl create -f proxysql-rs-svc.yml
$ kubectl create -f wordpress-rs-svc.ymlNous pouvons ensuite répertorier tous les pods et services qui ont été créés sous le niveau "frontend" :
$ kubectl get pods,services -l tier=frontend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
pod/proxysql-95b8d8446-qfbf2 1/1 Running 0 12m 10.36.0.2 kube2.local <none>
pod/proxysql-95b8d8446-vljlr 1/1 Running 0 12m 10.44.0.6 kube3.local <none>
pod/wordpress-59489d57b9-4dzvk 1/1 Running 0 37m 10.36.0.1 kube2.local <none>
pod/wordpress-59489d57b9-7d2jb 1/1 Running 0 30m 10.44.0.4 kube3.local <none>
pod/wordpress-59489d57b9-gw4p9 1/1 Running 0 30m 10.36.0.3 kube2.local <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/proxysql NodePort 10.108.195.54 <none> 6033:30033/TCP,6032:30032/TCP 10m app=proxysql,tier=frontend
service/wordpress NodePort 10.109.144.234 <none> 80:30088/TCP 37m app=wordpress,tier=frontend
kube2.local <none>La sortie ci-dessus vérifie notre architecture de déploiement où nous avons actuellement trois pods Wordpress, exposés publiquement sur le port 30088 ainsi que notre instance ProxySQL qui est exposée sur les ports 30033 et 30032 en externe plus 6033 et 6032 en interne.
À ce stade, notre architecture ressemble à ceci :
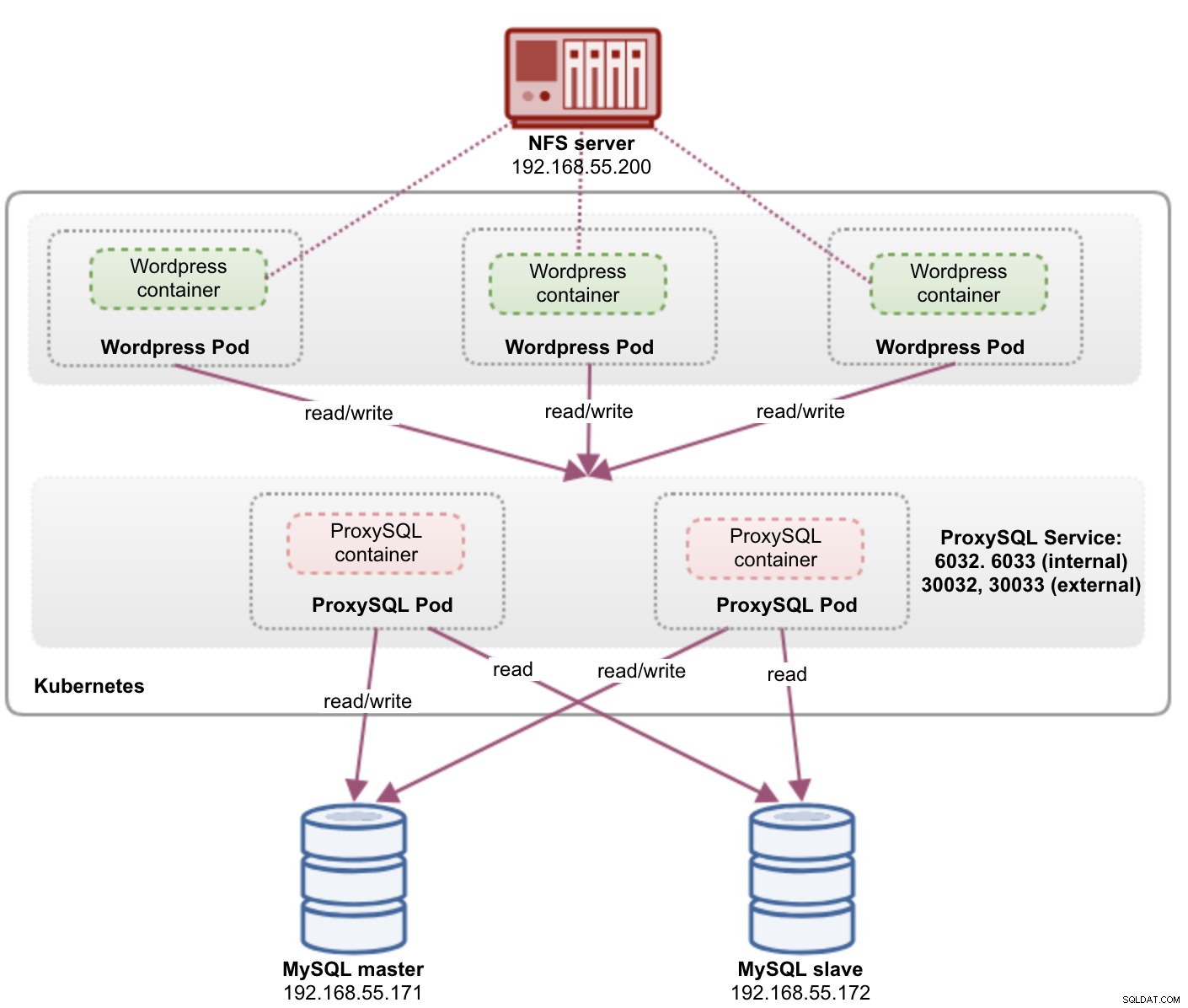
Le port 80 publié par les pods Wordpress est désormais mappé vers le monde extérieur via le port 30088. Nous pouvons accéder à notre article de blog à l'adresse https://{any_kubernetes_host}:30088/ et devons être redirigés vers la page d'installation de Wordpress. Si nous poursuivons l'installation, cela sauterait la partie de connexion à la base de données et afficherait directement cette page :
Cela indique que notre configuration MySQL et ProxySQL est correctement configurée dans le fichier wp-config.php. Sinon, vous seriez redirigé vers la page de configuration de la base de données.
Notre déploiement est maintenant terminé.
Pods ProxySQL et gestion des services
Le basculement et la récupération devraient être gérés automatiquement par Kubernetes. Par exemple, si un travailleur Kubernetes tombe en panne, le pod sera recréé dans le prochain nœud disponible après --pod-eviction-timeout (par défaut à 5 minutes). Si le conteneur tombe en panne ou est tué, Kubernetes le remplacera presque instantanément.
Certaines tâches de gestion courantes sont censées être différentes lorsqu'elles sont exécutées dans Kubernetes, comme indiqué dans les sections suivantes.
Connexion à ProxySQL
Alors que ProxySQL est exposé en externe sur les ports 30033 (MySQL) et 30032 (Admin), il est également accessible en interne via les ports publiés, respectivement 6033 et 6032. Ainsi, pour accéder aux instances ProxySQL au sein du réseau Kubernetes, utilisez le CLUSTER-IP, ou le nom de service "proxysql" comme valeur d'hôte. Par exemple, dans le module Wordpress, vous pouvez accéder à la console d'administration ProxySQL en utilisant la commande suivante :
$ mysql -uproxysql-admin -p -hproxysql -P6032Si vous souhaitez vous connecter en externe, utilisez le port défini sous la valeur nodePort du service YAML et choisissez l'un des nœuds Kubernetes comme valeur d'hôte :
$ mysql -uproxysql-admin -p -hkube3.local -P30032Il en va de même pour la connexion MySQL à charge équilibrée sur les ports 30033 (externe) et 6033 (interne).
Mise à l'échelle vers le haut et vers le bas
La mise à l'échelle est facile avec Kubernetes :
$ kubectl scale deployment proxysql --replicas=5
deployment.extensions/proxysql scaledVérifiez l'état du déploiement :
$ kubectl rollout status deployment proxysql
deployment "proxysql" successfully rolled outLa réduction est également similaire. Ici, nous souhaitons revenir de 5 à 2 réplicas :
$ kubectl scale deployment proxysql --replicas=2
deployment.extensions/proxysql scaledNous pouvons également examiner les événements de déploiement de ProxySQL pour obtenir une meilleure image de ce qui s'est passé pour ce déploiement en utilisant l'option "describe" :
$ kubectl describe deployment proxysql
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 0
Normal ScalingReplicaSet 7m10s deployment-controller Scaled up replica set proxysql-6c55f647cb to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled down replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled up replica set proxysql-6c55f647cb to 2
Normal ScalingReplicaSet 6m53s deployment-controller Scaled down replica set proxysql-769895fbf7 to 0
Normal ScalingReplicaSet 54s deployment-controller Scaled up replica set proxysql-6c55f647cb to 5
Normal ScalingReplicaSet 21s deployment-controller Scaled down replica set proxysql-6c55f647cb to 2Les connexions aux pods seront automatiquement équilibrées par Kubernetes.
Modifications de configuration
Une façon d'apporter des modifications à la configuration de nos pods ProxySQL consiste à versionner notre configuration à l'aide d'un autre nom ConfigMap. Dans un premier temps, modifiez notre fichier de configuration directement via votre éditeur de texte préféré :
$ vim /root/proxysql.cnfEnsuite, chargez-le dans Kubernetes ConfigMap avec un nom différent. Dans cet exemple, nous ajoutons "-v2" dans le nom de la ressource :
$ kubectl create configmap proxysql-configmap-v2 --from-file=proxysql.cnfVérifiez si le ConfigMap est correctement chargé :
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 3d15h
proxysql-configmap-v2 1 19mOuvrez le fichier de déploiement ProxySQL, proxysql-rs-svc.yml et remplacez la ligne suivante sous la section configMap par la nouvelle version :
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap-v2 #change this lineEnsuite, appliquez les modifications à notre déploiement ProxySQL :
$ kubectl apply -f proxysql-rs-svc.yml
deployment.apps/proxysql configured
service/proxysql configuredVérifiez le déploiement en examinant l'événement ReplicaSet à l'aide de l'indicateur "describe" :
$ kubectl describe proxysql
...
Pod Template:
Labels: app=proxysql
tier=frontend
Containers:
proxysql:
Image: severalnines/proxysql:1.4.12
Ports: 6033/TCP, 6032/TCP
Host Ports: 0/TCP, 0/TCP
Environment: <none>
Mounts:
/etc/proxysql.cnf from proxysql-config (rw)
Volumes:
proxysql-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: proxysql-configmap-v2
Optional: false
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: proxysql-769895fbf7 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 53s deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 41s deployment-controller Scaled down replica set proxysql-95b8d8446 to 0Faites attention à la section "Volumes" avec le nouveau nom ConfigMap. Vous pouvez également voir les événements de déploiement au bas de la sortie. À ce stade, notre nouvelle configuration a été chargée dans tous les pods ProxySQL, où Kubernetes a réduit le ProxySQL ReplicaSet à 0 (obéissant à la stratégie RollingUpdate) et les a ramenés à l'état souhaité de 2 répliques.
Réflexions finales
Jusqu'à présent, nous avons couvert l'approche de déploiement possible pour ProxySQL dans Kubernetes. L'exécution de ProxySQL à l'aide de Kubernetes ConfigMap ouvre une nouvelle possibilité de clustering ProxySQL, où il est quelque peu différent par rapport à la prise en charge native du clustering intégrée à ProxySQL.
Dans le prochain article de blog, nous explorerons ProxySQL Clustering à l'aide de Kubernetes ConfigMap et comment le faire correctement. Restez à l'écoute !