Si vous gérez une base de données de production, il y a de fortes chances que vous ayez dû cloner votre base de données sur un serveur différent du serveur de production. La méthode de base pour créer un clone consiste à restaurer une base de données à partir d'une sauvegarde récente sur un autre serveur de base de données. Une autre méthode consiste à répliquer à partir d'une base de données source alors qu'elle est encore en cours d'exécution, auquel cas il est important que la base de données d'origine ne soit pas affectée par une procédure de clonage.
Pourquoi auriez-vous besoin de cloner une base de données ?
Un cluster de base de données cloné est utile dans un certain nombre de scénarios :
- Dépannez votre cluster de production cloné dans la sécurité de votre environnement de test tout en effectuant des opérations destructrices sur la base de données.
- Test de correctif/mise à niveau d'une base de données clonée pour valider le processus de mise à niveau avant de l'appliquer au cluster de production.
- Valider la sauvegarde et la restauration d'un cluster de production à l'aide d'un cluster cloné
- Valider ou tester de nouvelles applications sur un cluster de production cloné avant de les déployer sur le cluster de production en direct.
- Clonez rapidement la base de données pour les exigences d'audit ou de conformité des informations, par exemple avant la fin du trimestre ou de l'année, lorsque le contenu de la base de données ne doit pas être modifié.
- Une base de données de rapports peut être créée à intervalles réguliers afin d'éviter les modifications de données lors des générations de rapports.
- Migrez une base de données vers de nouveaux serveurs, un nouvel environnement de déploiement ou un nouveau centre de données
Lors de l'exécution de votre infrastructure de base de données sur le cloud, le coût de possession d'un hôte (machine virtuelle partagée ou dédiée) est nettement inférieur par rapport à la manière traditionnelle de louer de l'espace dans un centre de données ou de posséder un serveur physique. De plus, la plupart des déploiements dans le cloud peuvent être automatisés facilement via les API des fournisseurs, les logiciels clients et les scripts. Par conséquent, le clonage d'un cluster peut être un moyen courant de dupliquer votre environnement de déploiement, par exemple, du développement à la mise en place à la production ou vice versa.
Nous n'avons vu cette fonctionnalité offerte par personne sur le marché, c'est donc notre privilège de montrer comment cela fonctionne avec ClusterControl.
Cloner un cluster MySQL Galera
L'une des fonctionnalités intéressantes de ClusterControl est qu'il vous permet de cloner rapidement un cluster MySQL Galera existant afin d'avoir une copie exacte de l'ensemble de données sur l'autre cluster. ClusterControl effectue l'opération de clonage en ligne, sans aucun verrouillage ni interruption du cluster existant. C'est comme une opération de scale-out de cluster, sauf que les deux clusters sont indépendants l'un de l'autre une fois la synchronisation terminée. Le cluster cloné n'a pas nécessairement besoin d'avoir la même taille de cluster que celui existant. Nous pourrions commencer avec un cluster à un nœud et le mettre à l'échelle avec plus de nœuds de base de données ultérieurement.
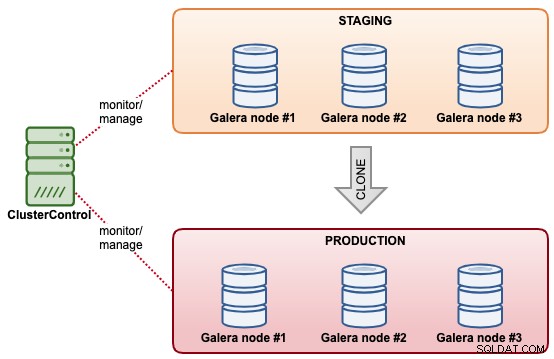
Dans cet exemple, nous avons un cluster appelé "Staging" que nous voudrions cloner comme un autre cluster appelé "Production". Le principe est que le cluster intermédiaire a déjà stocké les données nécessaires qui seront bientôt en production. Le cluster de production se compose de 3 autres nœuds, avec des spécifications de production.
Le diagramme suivant résume l'architecture finale de ce que nous voulons réaliser :
La première chose à faire est de configurer un SSH sans mot de passe à partir du serveur ClusterControl aux serveurs de production. Sur le serveur ClusterControl, exécutez ce qui suit :
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comEntrez le mot de passe root du serveur cible si vous y êtes invité.
Dans la liste des clusters de la base de données ClusterControl, cliquez sur le bouton Action de cluster et choisissez Cloner le cluster. L'assistant suivant apparaît :
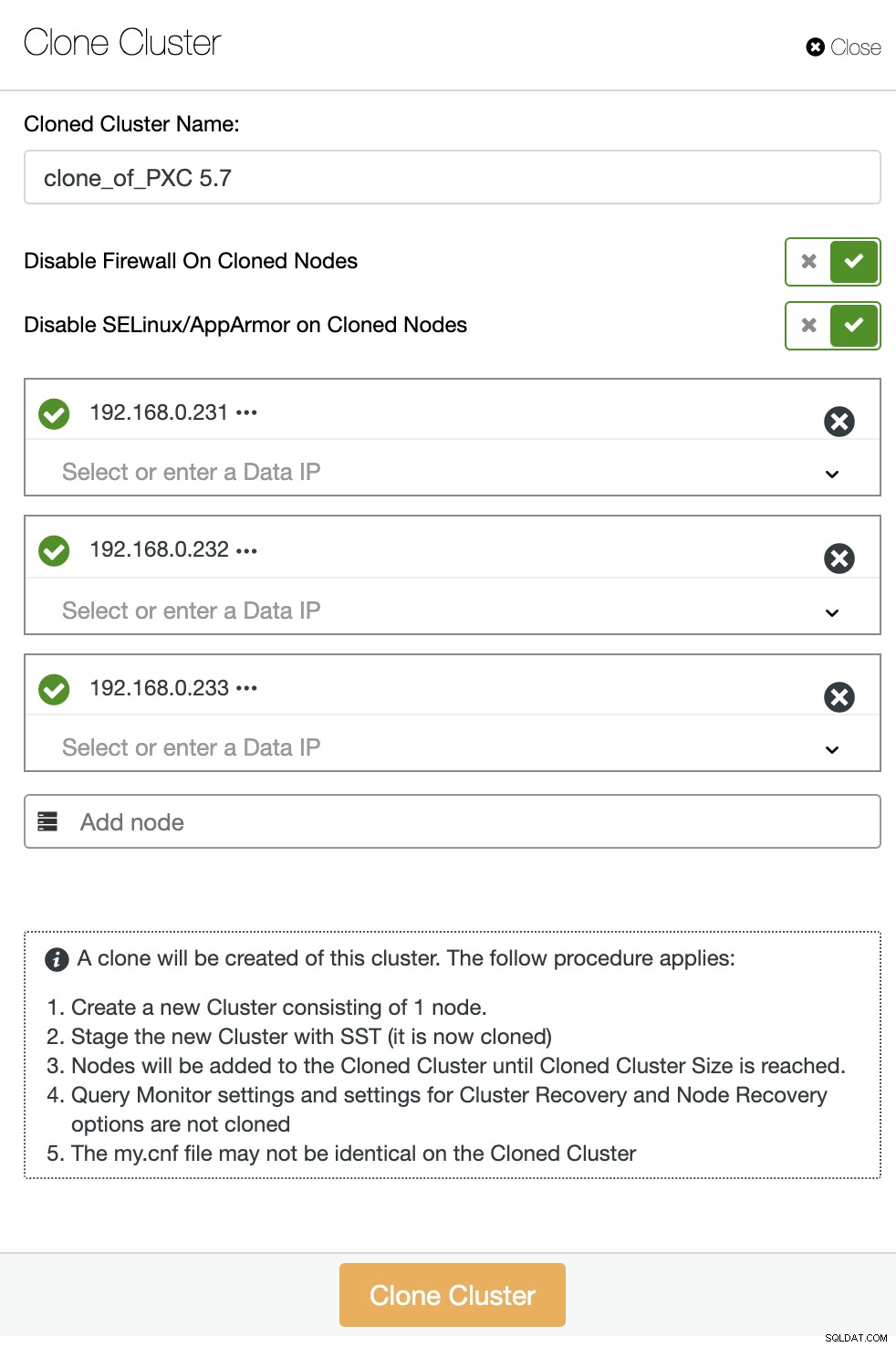
Spécifiez les adresses IP ou les noms d'hôte du nouveau cluster et assurez-vous d'obtenir toutes les coches vertes à côté de l'hôte spécifié. L'icône verte signifie que ClusterControl est capable de se connecter à l'hôte via SSH sans mot de passe. Cliquez sur le bouton "Clone Cluster" pour lancer le déploiement.
Les étapes de déploiement sont :
- Créer un nouveau cluster composé d'un nœud.
- Synchronisez le nouveau cluster à nœud unique via SST. Le donateur est l'un des serveurs source.
- Les nouveaux nœuds restants rejoindront le cluster après la synchronisation du donneur du cluster cloné avec le cluster.
Une fois cela fait, un nouveau cluster MySQL Galera sera répertorié sous le tableau de bord du cluster ClusterControl une fois la tâche de déploiement terminée.
Notez que le clonage de cluster ne clone que les serveurs de base de données et non l'ensemble de la pile du cluster. Cela signifie que d'autres composants de support liés au cluster tels que les équilibreurs de charge, l'adresse IP virtuelle, l'arbitre Galera ou l'esclave asynchrone ne seront pas clonés par ClusterControl. Néanmoins, si vous souhaitez cloner une copie exacte de votre infrastructure de base de données existante, vous pouvez y parvenir avec ClusterControl en déployant ces composants séparément une fois l'opération de clonage de base de données terminée.
Création d'un cluster de bases de données à partir d'une sauvegarde
Une autre fonctionnalité similaire offerte par ClusterControl est "Créer un cluster à partir d'une sauvegarde". Cette fonctionnalité est introduite dans ClusterControl 1.7.1, spécifiquement pour les clusters Galera Cluster et PostgreSQL où l'on peut créer un nouveau cluster à partir de la sauvegarde existante. Contrairement au clonage de cluster, cette opération n'apporte pas de charge supplémentaire au cluster source avec pour contrepartie que le cluster cloné ne sera pas dans l'état actuel en tant que cluster source.
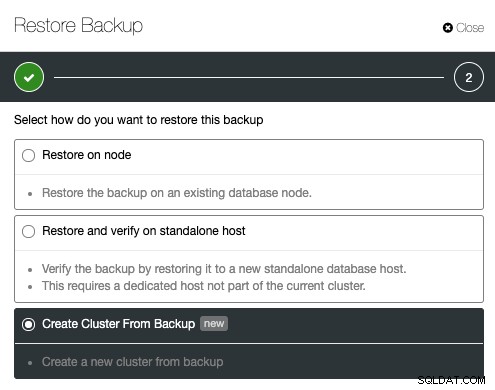
Afin de créer un cluster à partir d'une sauvegarde, vous devez créer une sauvegarde de travail. Pour Galera Cluster, toutes les méthodes de sauvegarde sont prises en charge tandis que pour PostgreSQL, seul pgbackrest n'est pas pris en charge pour le déploiement d'un nouveau cluster. À partir de ClusterControl, une sauvegarde peut être créée ou planifiée facilement sous ClusterControl -> Sauvegardes -> Créer une sauvegarde. Dans la liste de la sauvegarde créée, cliquez sur Restaurer la sauvegarde, choisissez la sauvegarde dans la liste et choisissez "Créer un cluster à partir de la sauvegarde" dans l'option de restauration :
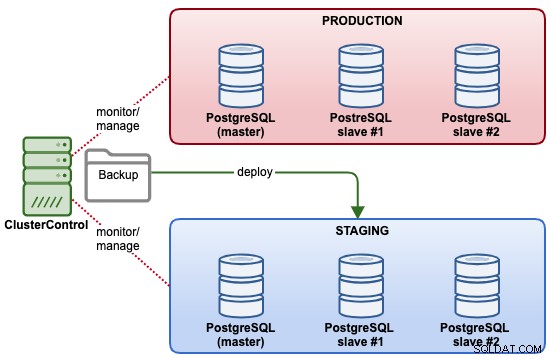
Dans cet exemple, nous allons déployer un nouveau cluster PostgreSQL Streaming Replication pour l'environnement intermédiaire, basé sur la sauvegarde existante que nous avons dans le cluster de production. Le schéma suivant illustre l'architecture finale :
La première chose à faire est de configurer un SSH sans mot de passe à partir du serveur ClusterControl aux serveurs de production. Sur le serveur ClusterControl, exécutez ce qui suit :
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comLorsque vous choisissez Créer un cluster à partir de la sauvegarde, ClusterControl ouvre une boîte de dialogue d'assistant de déploiement pour vous aider à configurer le nouveau cluster :
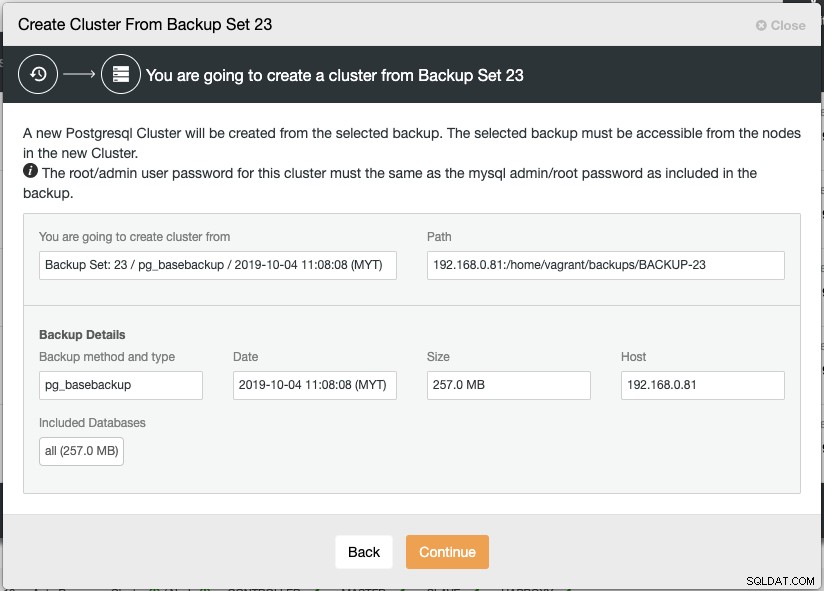
Une nouvelle instance de PostgreSQL Streaming Replication sera créée à partir de la sauvegarde sélectionnée, qui sera utilisé comme jeu de données de base pour le nouveau cluster. La sauvegarde sélectionnée doit être accessible à partir des nœuds du nouveau cluster ou stockée dans l'hôte ClusterControl.
Cliquer sur "Continuer" ouvrira l'assistant de déploiement de cluster de base de données standard :
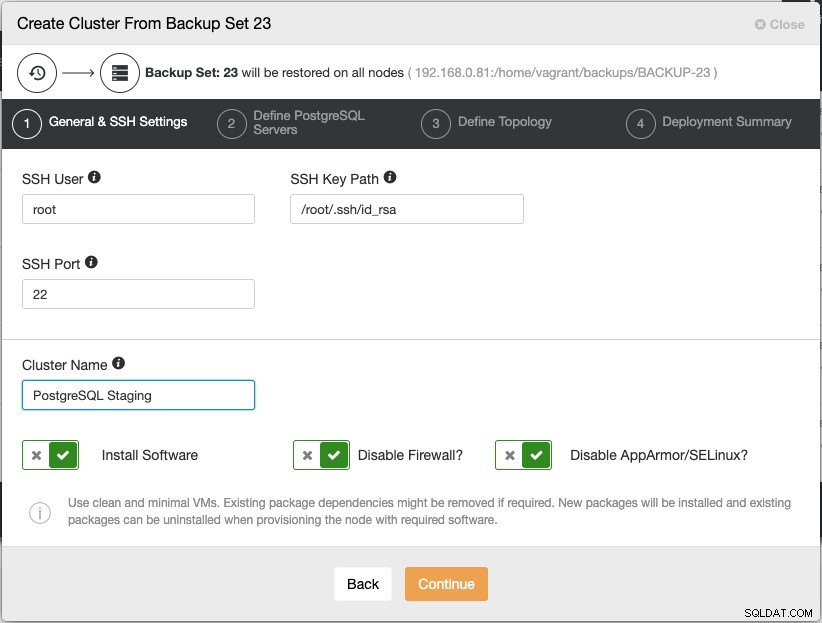
Notez que le mot de passe de l'utilisateur root/admin pour ce cluster doit être le même que le mot de passe admin/root PostgreSQL tel qu'inclus dans la sauvegarde. Suivez l'assistant de configuration en conséquence et ClusterControl effectue ensuite le déploiement dans l'ordre suivant :
- Installez les logiciels et les dépendances nécessaires sur tous les nœuds PostgreSQL.
- Démarrez le premier nœud.
- Diffusion et restauration de la sauvegarde sur le premier nœud.
- Configurez et ajoutez le reste des nœuds.
Une fois cela fait, un nouveau cluster de réplication PostgreSQL sera répertorié sous le tableau de bord du cluster ClusterControl une fois la tâche de déploiement terminée.



