Presto est un moteur SQL open source distribué en parallèle pour le traitement du Big Data. Il a été développé à partir de zéro par Facebook. La première version interne a eu lieu en 2013 et était une solution assez révolutionnaire pour leurs problèmes de Big Data.
Avec les centaines de serveurs géolocalisés et les pétaoctets de données, Facebook a commencé à chercher une plateforme alternative pour ses clusters Hadoop. Son équipe chargée de l'infrastructure souhaitait réduire le temps nécessaire à l'exécution de tâches d'analyse par lots et simplifier le développement du pipeline en utilisant le langage de programmation largement connu dans l'organisation : SQL.
Selon la fondation Presto, « Facebook utilise Presto pour des requêtes interactives sur plusieurs magasins de données internes, y compris leur entrepôt de données de 300 PB. Plus de 1 000 employés de Facebook utilisent Presto quotidiennement pour exécuter plus de 30 000 requêtes qui analysent au total plus d'un pétaoctet chacune par jour."
Bien que Facebook dispose d'un environnement d'entrepôt de données exceptionnel, les mêmes défis sont présents dans de nombreuses organisations traitant du Big Data.
Dans ce blog, nous verrons comment configurer un environnement presto de base à l'aide d'un serveur Docker à partir du fichier tar. En tant que source de données, nous nous concentrerons sur la source de données MySQL, mais il pourrait s'agir de n'importe quel autre SGBDR courant.
Exécution de Presto dans un environnement Big Data
Avant de commencer, jetons un coup d'œil sur ses grands principes d'architecture. Presto est une alternative aux outils qui interrogent HDFS à l'aide de pipelines de travaux MapReduce, tels que Hive. Contrairement à Hive, Presto n'utilise pas MapReduce. Presto s'exécute avec un moteur d'exécution de requêtes à usage spécial avec des opérateurs de haut niveau et un traitement en mémoire.
Contrairement à Hive, Presto peut diffuser des données à travers toutes les étapes à la fois en exécutant simultanément des blocs de données. Il est conçu pour exécuter des requêtes analytiques ad hoc sur des sources de données hétérogènes uniques ou distribuées. Il peut accéder à partir d'une plate-forme Hadoop pour interroger des bases de données relationnelles ou d'autres magasins de données comme des fichiers plats.
Presto utilise le SQL ANSI standard, y compris les agrégations, les jointures ou les fonctions de fenêtre analytique. SQL est bien connu et beaucoup plus facile à utiliser que MapReduce écrit en Java.
Déployer Presto sur Docker
La configuration de base de Presto peut être déployée avec une image Docker préconfigurée ou une archive de serveur presto.
Le serveur docker et les conteneurs Presto CLI peuvent être facilement déployés avec :
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliVous pouvez choisir entre deux versions de serveur Presto. Version communautaire et version entreprise de Starburst. Étant donné que nous allons l'exécuter dans un environnement sandbox hors production, nous utiliserons la version Apache dans cet article.
Pré-requis
Presto est entièrement implémenté en Java et nécessite l'installation de JVM sur votre système. Il fonctionne à la fois sur OpenJDK et Oracle Java. La version minimale est Java 8u151 ou Java 11.
Pour télécharger JAVA JDK, visitez https://openjdk.java.net/ ou https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Vous pouvez vérifier votre version Java avec
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Installation rapide
Pour installer Presto, nous allons télécharger le serveur tar et l'exécutable Presto CLI jar.
L'archive contiendra un seul répertoire de niveau supérieur, presto-server-0.223, que nous appellerons le répertoire d'installation.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoDe plus, Presto a besoin d'un répertoire de données pour stocker les journaux, etc.
Il est recommandé de créer un répertoire de données en dehors du répertoire d'installation.
$ mkdir -p ~/data/presto/Cet emplacement est l'endroit où nous commençons notre dépannage.
Configurer Presto
Avant de démarrer notre première instance, nous devons créer un ensemble de fichiers de configuration. Commencez par créer un répertoire etc/ dans le répertoire d'installation. Cet emplacement contiendra les fichiers de configuration suivants :
etc/
- Propriétés du nœud - configuration de l'environnement du nœud
- Configuration JVM (jvm.config) - Configuration de la machine virtuelle Java
- Propriétés de configuration (config.properties) - configuration pour le serveur Presto
- Propriétés du catalogue - configuration des connecteurs (sources de données)
- Propriétés du journal – Configuration des enregistreurs
Vous trouverez ci-dessous une configuration de base pour exécuter le bac à sable Presto. Pour plus de détails, consultez la documentation.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.propriétés
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoLa structure etc/ de base peut ressembler à ceci :

La prochaine étape consiste à configurer le connecteur MySQL.
Nous allons nous connecter à l'un des 3 nœuds MariaDB Cluster.
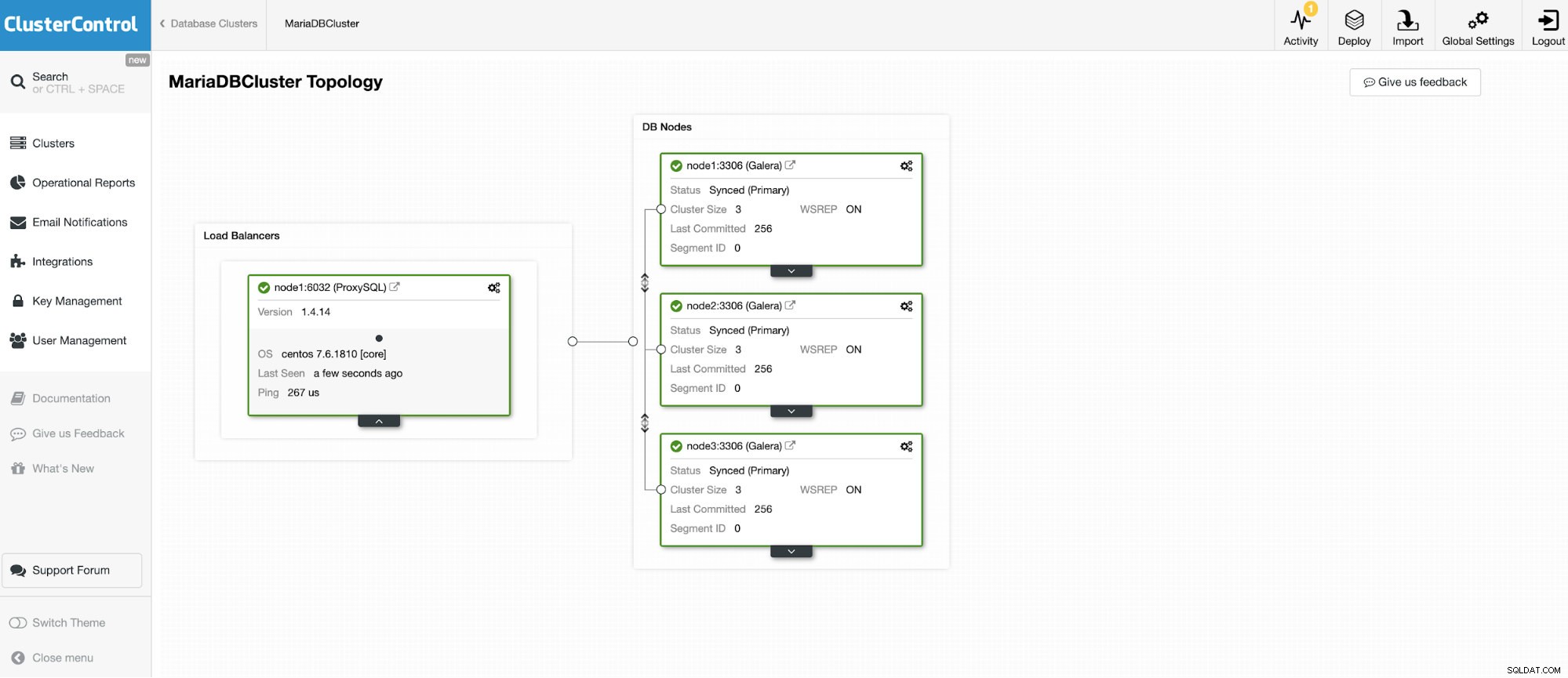
Et une autre instance autonome exécutant Oracle MySQL 5.7.
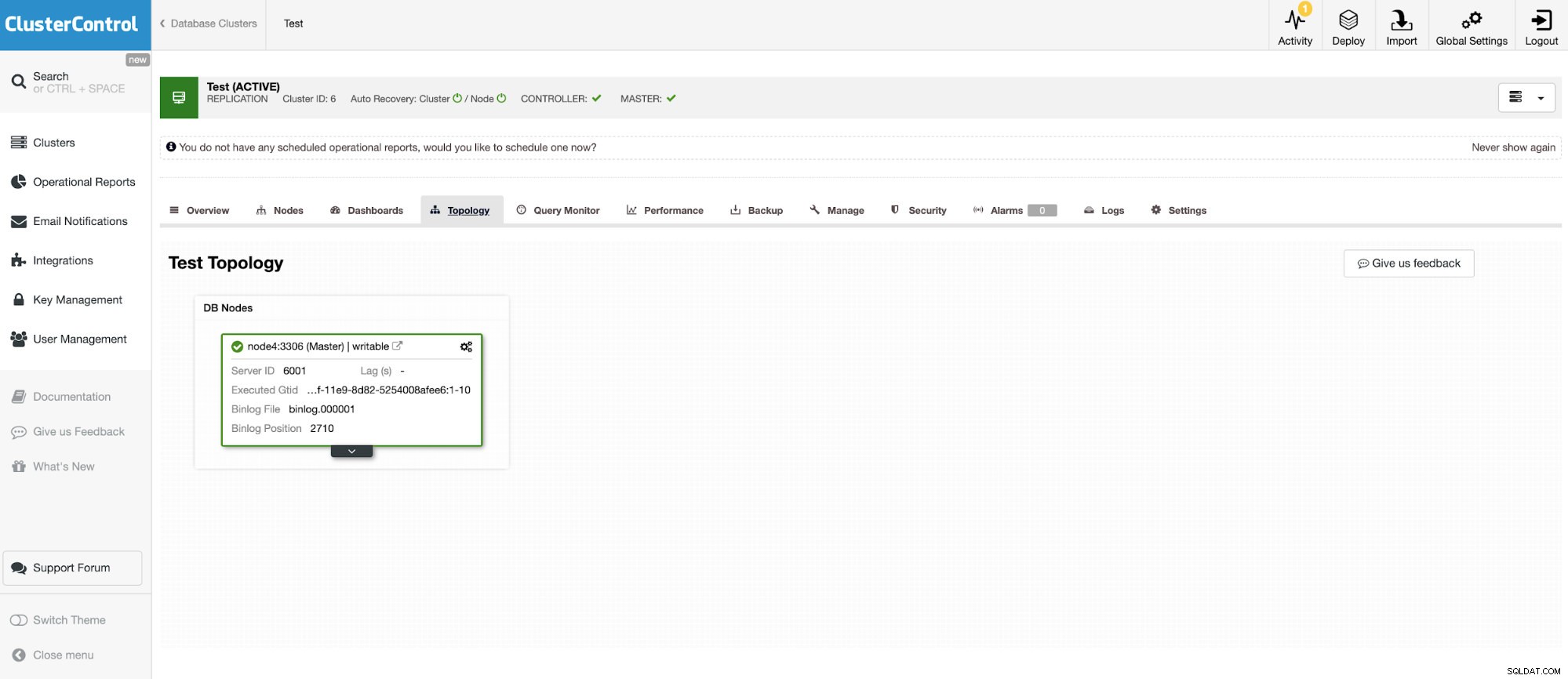
Le connecteur MySQL permet d'interroger et de créer des tables dans une base de données MySQL externe. Cela peut être utilisé pour joindre des données entre différents systèmes comme MariaDB et MySQL d'Oracle.
Presto utilise des connecteurs enfichables et la configuration est très simple. Pour configurer le connecteur MySQL, créez un fichier de propriétés de catalogue dans etc/catalog nommé, par exemple, mysql.properties, pour monter le connecteur MySQL en tant que catalogue mysql. Chacun des fichiers représentant une connexion à un autre serveur. Dans ce cas, nous avons deux fichiers :
vi etc/catalog/mysq.properties :
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretExécuter Presto
Lorsque tout est défini, il est temps de démarrer l'instance Presto. Pour démarrer presto, accédez au répertoire bin sous l'installation de preso et exécutez ce qui suit :
$ bin/launcher start
Started as 18363Pour arrêter l'exécution de Presto
$ bin/launcher stopMaintenant, lorsque le serveur est opérationnel, nous pouvons nous connecter à Presto avec CLI et interroger la base de données MySQL.
Pour lancer l'exécution de la console Presto :
./presto --server localhost:8080 --catalog mysql --schema employeesNous pouvons maintenant interroger nos bases de données via CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Les deux bases de données MariaDB cluster et MySQL ont été alimentées avec la base de données des employés.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlL'état de la requête est également visible dans la console Web Presto :https://localhost:8080/ui/#
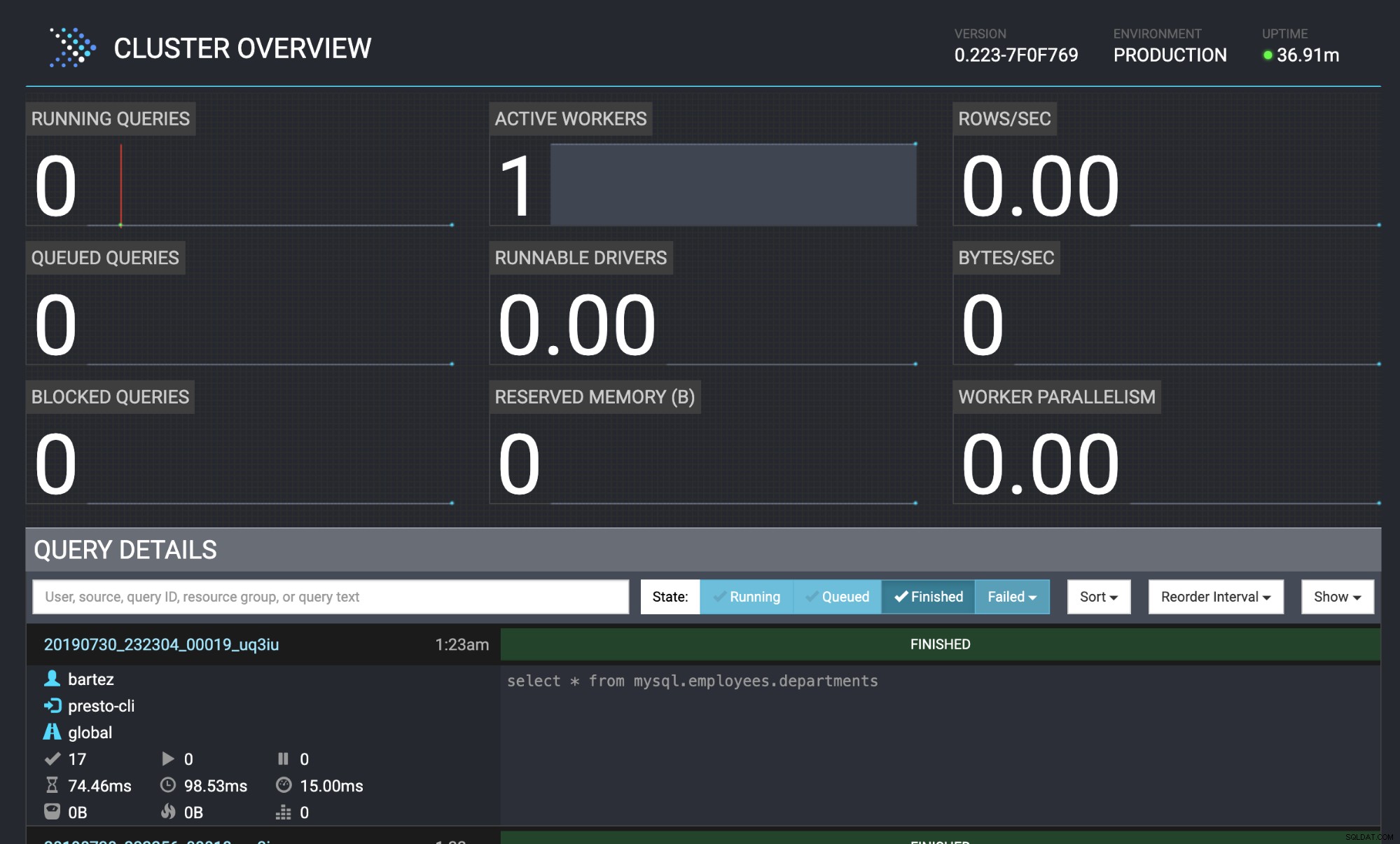 Présentation du cluster Presto
Présentation du cluster Presto Conclusion
De nombreuses entreprises bien connues (comme Airbnb, Netflix, Twitter) adoptent Presto pour des performances à faible latence. C'est sans aucun doute un logiciel très intéressant qui peut éliminer le besoin d'exécuter de lourds processus d'entrepôt de données ETL. Dans ce blog, nous venons d'examiner brièvement le connecteur MySQL, mais vous pouvez l'utiliser pour analyser les données de HDFS, de magasins d'objets, de RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB et bien d'autres.