Il est assez courant de voir des bases de données réparties sur plusieurs emplacements géographiques. Un scénario pour effectuer ce type de configuration est la reprise après sinistre, où votre centre de données de secours est situé dans un emplacement distinct de votre centre de données principal. Il pourrait tout aussi bien être nécessaire pour que les bases de données soient situées plus près des utilisateurs.
Le principal défi pour réaliser cette configuration consiste à concevoir la base de données de manière à réduire les risques de problèmes liés au partitionnement du réseau. L'une des solutions pourrait être d'utiliser Galera Cluster au lieu d'une réplication asynchrone (ou semi-synchrone) régulière. Dans ce blog, nous discuterons des avantages et des inconvénients de cette approche. Ceci est la première partie d'une série de deux blogs. Dans la deuxième partie, nous allons concevoir le cluster Galera géo-distribué et voir comment ClusterControl peut nous aider à déployer un tel environnement.
Pourquoi le cluster Galera au lieu de la réplication asynchrone pour les clusters géo-distribués ?
Considérons les principales différences entre la Galera et la réplication régulière. La réplication régulière vous fournit un seul nœud sur lequel écrire, ce qui signifie que chaque écriture depuis un centre de données distant devrait être envoyée sur le réseau étendu (WAN) pour atteindre le maître. Cela signifie également que tous les proxys situés dans le centre de données distant devront être en mesure de surveiller l'ensemble de la topologie, couvrant tous les centres de données impliqués, car ils doivent être en mesure de dire quel nœud est actuellement le maître.
Cela conduit au nombre de problèmes. Tout d'abord, plusieurs connexions doivent être établies sur le WAN, ce qui ajoute de la latence et ralentit les vérifications que le proxy peut exécuter. De plus, cela ajoute une surcharge inutile sur les proxys et les bases de données. La plupart du temps, vous êtes uniquement intéressé par le routage du trafic vers les nœuds de base de données locaux. La seule exception est le maître et ce n'est qu'à cause de cela que les mandataires sont obligés de surveiller l'ensemble de l'infrastructure plutôt que la partie située dans le centre de données local. Bien sûr, vous pouvez essayer de surmonter cela en utilisant des proxys pour router uniquement les SELECT, tout en utilisant une autre méthode (nom d'hôte dédié pour le maître géré par DNS) pour pointer l'application vers le maître, mais cela ajoute des niveaux inutiles de complexité et de pièces mobiles, ce qui pourrait sérieusement affecter votre capacité à gérer plusieurs pannes de nœuds et de réseau sans perdre la cohérence des données.
Galera Cluster peut prendre en charge plusieurs écrivains. La latence est également un facteur, car tous les nœuds du cluster Galera doivent se coordonner et communiquer pour certifier les jeux d'écriture, cela peut même être la raison pour laquelle vous pouvez décider de ne pas utiliser Galera lorsque la latence est trop élevée. C'est également un problème dans les clusters de réplication - dans les clusters de réplication, la latence n'affecte que les écritures à partir des centres de données distants, tandis que les connexions à partir du centre de données où se trouve le maître bénéficieraient d'un commit à faible latence.
Dans la réplication MySQL, vous devez également prendre en compte le pire des cas et vous assurer que l'application est d'accord avec les écritures différées. Le maître peut toujours changer et vous ne pouvez pas être sûr que vous écrirez tout le temps sur un nœud local.
Une autre différence entre la réplication et Galera Cluster est la gestion du décalage de réplication. Les clusters géo-distribués peuvent être sérieusement affectés par le décalage :latence, débit limité de la connexion WAN, tout cela impactera la capacité d'un cluster répliqué à suivre la réplication. Veuillez garder à l'esprit que la réplication génère un pour tout le trafic.
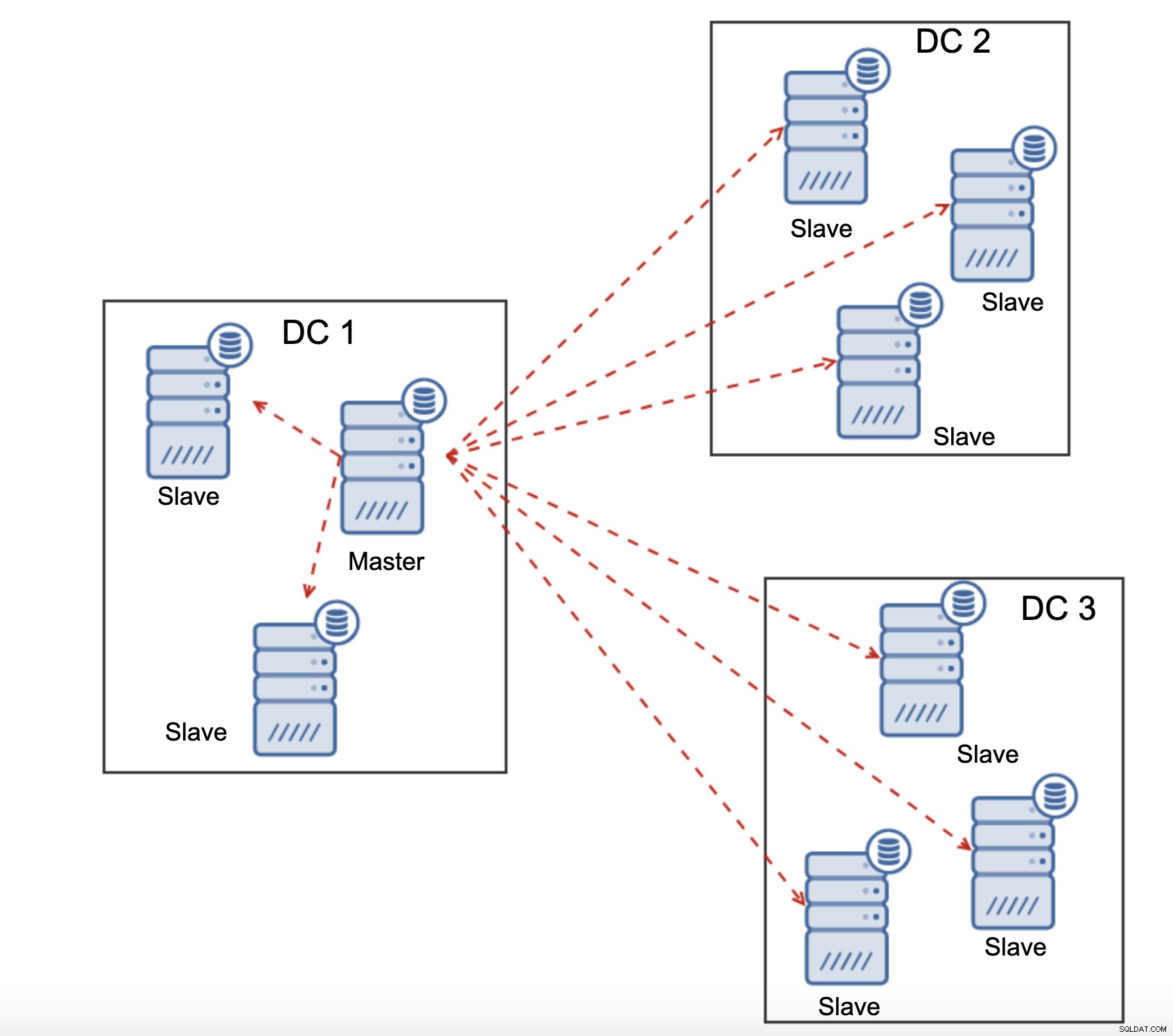
Tous les esclaves doivent recevoir l'intégralité du trafic de réplication - la quantité de données dont vous disposez à envoyer aux esclaves distants via le WAN augmente avec chaque esclave distant que vous ajoutez. Cela peut facilement entraîner la saturation de la liaison WAN, surtout si vous effectuez de nombreuses modifications et que la liaison WAN n'a pas un bon débit. Comme vous pouvez le voir sur le diagramme ci-dessus, avec trois centres de données et trois nœuds dans chacun d'eux, le maître doit envoyer 6 fois le trafic de réplication via une connexion WAN.
Avec le cluster Galera, les choses sont légèrement différentes. Pour commencer, Galera utilise le contrôle de flux pour synchroniser les nœuds. Si l'un des nœuds commence à prendre du retard, il a la capacité de demander au reste du cluster de ralentir et de le laisser rattraper son retard. Bien sûr, cela réduit les performances de l'ensemble du cluster, mais c'est toujours mieux que lorsque vous ne pouvez pas vraiment utiliser d'esclaves pour les SELECT car ils ont tendance à être à la traîne de temps en temps - dans de tels cas, les résultats que vous obtiendrez pourraient être obsolètes et incorrects.
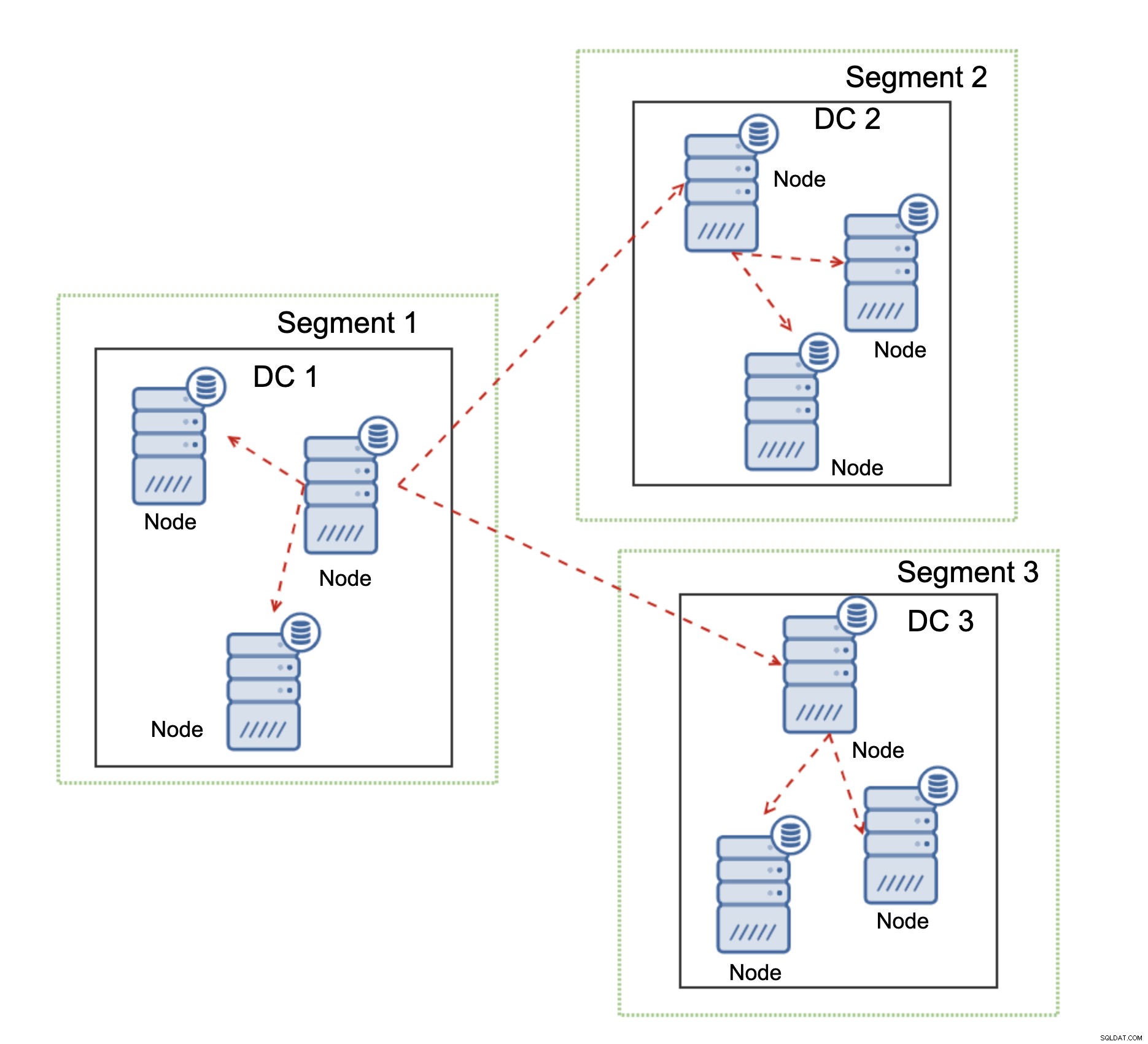
Une autre fonctionnalité de Galera Cluster, qui peut améliorer considérablement ses performances lorsqu'il est utilisé sur WAN, sont des segments. Par défaut, Galera utilise la communication all to all et chaque jeu d'écriture est envoyé par le nœud à tous les autres nœuds du cluster. Ce comportement peut être modifié à l'aide de segments. Les segments permettent aux utilisateurs de diviser le cluster Galera en plusieurs parties. Chaque segment peut contenir plusieurs nœuds et il élit l'un d'eux comme nœud relais. Ce nœud reçoit des jeux d'écriture d'autres segments et les redistribue entre les nœuds Galera locaux au segment. En conséquence, comme vous pouvez le voir sur le schéma ci-dessus, il est possible de réduire le trafic de réplication passant sur le WAN par trois - seulement deux "répliques" du flux de réplication sont envoyées sur le WAN :une par centre de données contre une par esclave. dans la réplication MySQL.
Gestion du partitionnement réseau du cluster Galera
Là où Galera Cluster brille, c'est la gestion du partitionnement du réseau. Galera Cluster surveille en permanence l'état des nœuds du cluster. Chaque nœud tente de se connecter avec ses pairs et d'échanger l'état du cluster. Si un sous-ensemble de nœuds n'est pas accessible, Galera tente de relayer la communication, donc s'il existe un moyen d'atteindre ces nœuds, ils seront atteints.

Un exemple peut être vu sur le schéma ci-dessus :DC 1 a perdu la connectivité avec DC2 mais DC2 et DC3 peuvent se connecter. Dans ce cas, l'un des nœuds de DC3 sera utilisé pour relayer les données de DC1 à DC2 en veillant à ce que la communication intra-cluster puisse être maintenue.
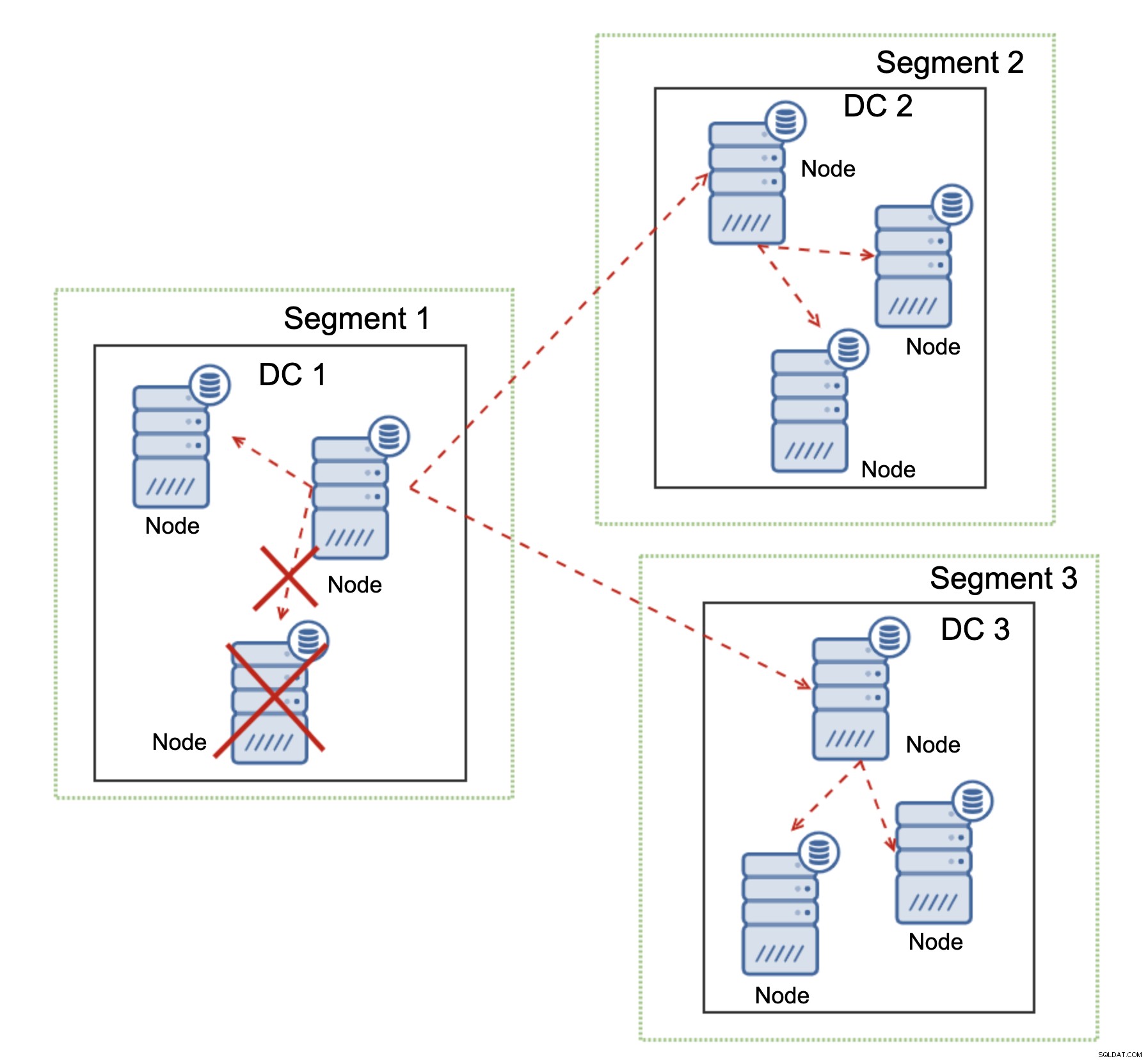
Galera Cluster peut prendre des mesures en fonction de l'état du cluster. Il implémente le quorum - la majorité des nœuds doivent être disponibles pour que le cluster puisse fonctionner. Si le nœud est déconnecté du cluster et ne peut atteindre aucun autre nœud, il cessera de fonctionner.
Comme on peut le voir sur le diagramme ci-dessus, il y a une perte partielle de la communication réseau dans DC1 et le nœud affecté est supprimé du cluster, garantissant que l'application n'accédera pas aux données obsolètes.
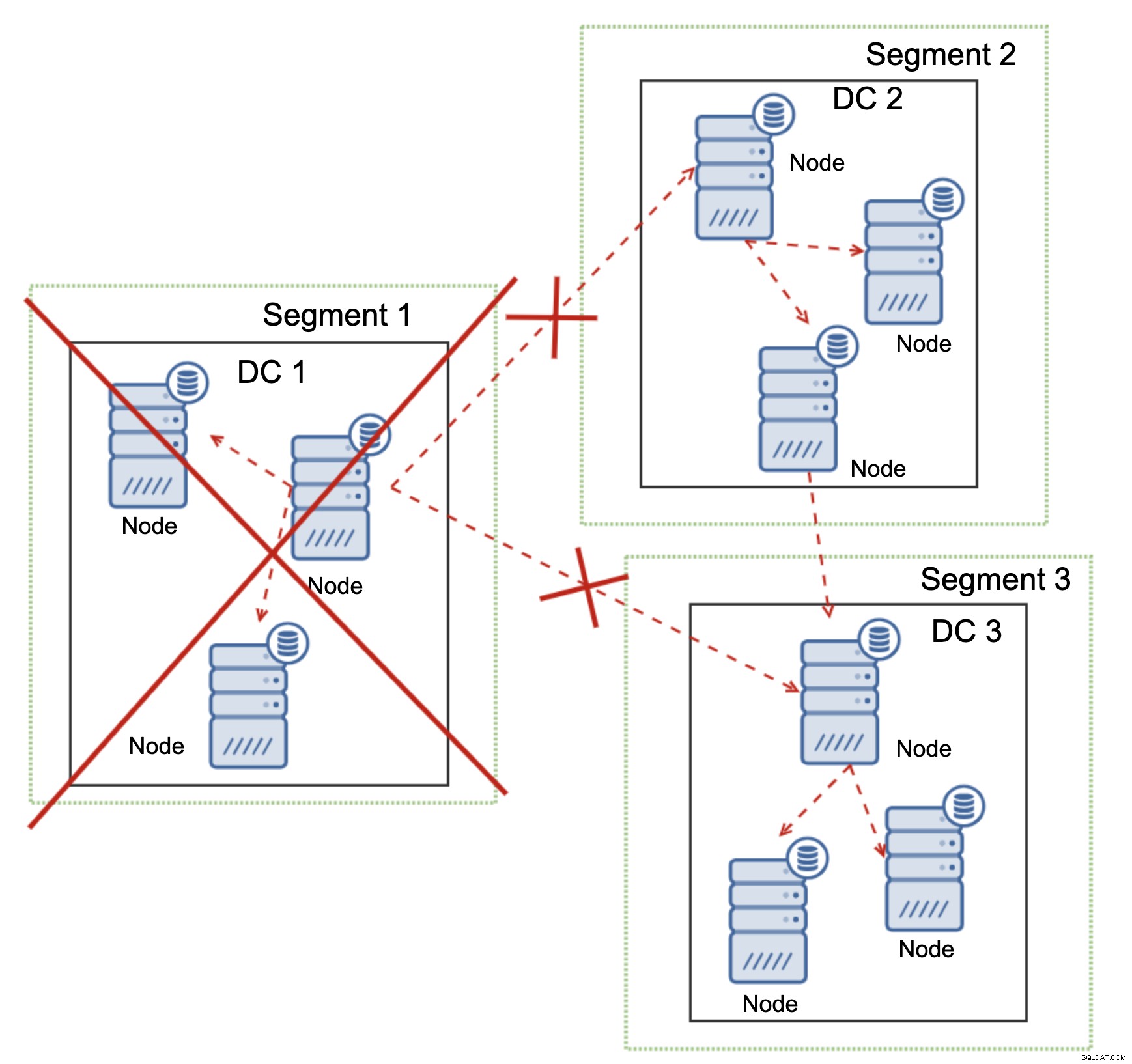
Cela est également vrai à plus grande échelle. Le DC1 s'est vu couper toutes ses communications. En conséquence, tout le centre de données a été supprimé du cluster et aucun de ses nœuds ne desservira le trafic. Le reste du cluster est resté majoritaire (6 nœuds sur 9 sont disponibles) et s'est reconfiguré pour conserver la connexion entre DC 2 et DC3. Dans le diagramme ci-dessus, nous avons supposé que l'écriture atteignait le nœud dans DC2, mais gardez à l'esprit que Galera est capable de fonctionner avec plusieurs écrivains.
MySQL Replication n'a aucun type de prise en compte des clusters, ce qui rend problématique la gestion des problèmes de réseau. Il ne peut pas s'arrêter en cas de perte de connexion avec d'autres nœuds. Il n'y a pas de moyen facile d'empêcher l'ancien maître d'apparaître après la division du réseau.
Les seules possibilités sont limitées à la couche proxy ou même supérieure. Vous devez concevoir un système qui essaierait de comprendre l'état du cluster et de prendre les mesures nécessaires. Une méthode possible consiste à utiliser des outils compatibles avec les clusters tels qu'Orchestrator, puis à exécuter des scripts qui vérifieraient l'état du cluster Orchestrator RAFT et, en fonction de cet état, prendraient les actions requises sur la couche de base de données. C'est loin d'être idéal car toute action entreprise sur une couche supérieure à la base de données ajoute une latence supplémentaire :cela permet que le problème apparaisse et que la cohérence des données soit compromise avant qu'une action correcte puisse être entreprise. Galera, d'autre part, prend des mesures au niveau de la base de données, assurant la réaction la plus rapide possible.