Avoir des tables de référence dans votre base de données n'est pas un gros problème, n'est-ce pas ? Il vous suffit d'associer un code ou un identifiant à une description pour chaque type de référence. Mais que se passe-t-il si vous avez littéralement des dizaines et des dizaines de tables de référence ? Existe-t-il une alternative à l'approche une table par type ? Lisez la suite pour découvrir un générique et extensible conception de base de données pour gérer toutes vos données de référence.
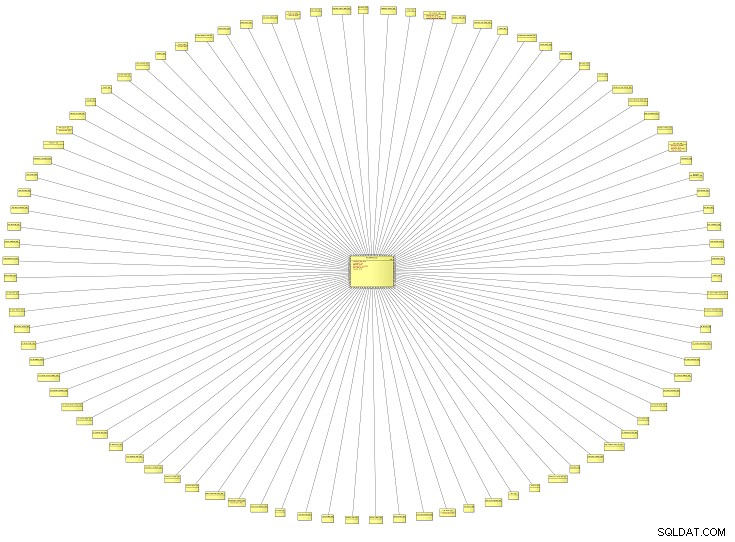
Ce diagramme d'apparence inhabituelle est une vue d'ensemble d'un modèle de données logique (MLD) contenant tous les types de référence pour un système d'entreprise. Il provient d'un établissement d'enseignement, mais il pourrait s'appliquer au modèle de données de tout type d'organisation. Plus le modèle est grand, plus vous êtes susceptible de découvrir de types de référence.
Par types de référence, j'entends des données de référence, ou des valeurs de recherche, ou - si vous voulez être flash - des taxonomies . Généralement, les valeurs définies ici sont utilisées dans les listes déroulantes de l'interface utilisateur de votre application. Ils peuvent également apparaître sous forme d'en-têtes dans un rapport.
Ce modèle de données particulier avait environ 100 types de référence. Faisons un zoom avant et regardons seulement deux d'entre eux.
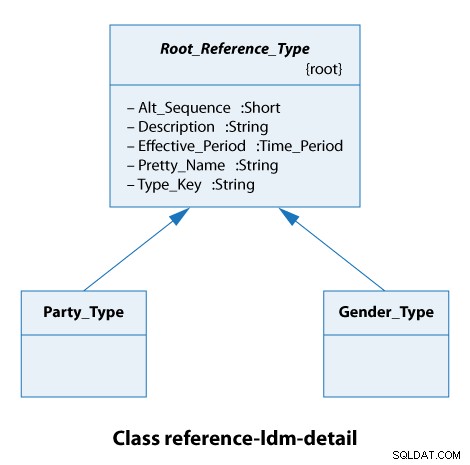
À partir de ce diagramme de classes, nous voyons que tous les types de référence étendent le Root_Reference_Type . En pratique, cela signifie simplement que tous nos types de référence ont les mêmes attributs de Alt_Sequence jusqu'à Type_Key inclus, comme indiqué ci-dessous.
| Attribut | Description |
|---|---|
Alt_Sequence | Utilisé pour définir une séquence alternative lorsqu'un ordre non alphabétique est requis. |
Description | La description du type. |
Effective_Period | Définit effectivement si l'entrée de référence est activée ou non. Une fois qu'une référence a été utilisée, elle ne peut pas être supprimée en raison de contraintes référentielles ; il peut seulement être désactivé. |
| Le joli nom du type. C'est ce que l'utilisateur voit à l'écran. |
Type_Key | La clé interne unique pour le type. Ceci est caché à l'utilisateur, mais les développeurs d'applications peuvent en faire un usage intensif dans leur SQL. |
Le type de parti ici est soit une organisation, soit une personne. Les types de genre sont masculin et féminin. Ce sont donc des cas très simples.
La solution de table de référence traditionnelle
Alors, comment allons-nous implémenter le modèle logique dans le monde physique d'une base de données réelle ?
Nous pourrions considérer que chaque type de référence correspondra à sa propre table. Vous pourriez vous référer à cela comme le plus traditionnel une table par classe Solution. C'est assez simple et ressemblerait à ceci :
L'inconvénient est qu'il pourrait y avoir des dizaines et des dizaines de ces tables, ayant toutes les mêmes colonnes, faisant toutes à peu près la même chose.
De plus, nous créons peut-être beaucoup plus de travail de développement . Si une interface utilisateur pour chaque type est requise pour que les administrateurs maintiennent les valeurs, la quantité de travail se multiplie rapidement. Il n'y a pas de règles strictes pour cela - cela dépend vraiment de votre environnement de développement - donc vous devrez parler à vos développeurs pour comprendre quel impact cela a.
Mais étant donné que tous nos types de référence ont les mêmes attributs, ou colonnes, existe-t-il un moyen plus générique d'implémenter notre modèle de données logique ? Oui il y a! Et cela ne nécessite que deux tables .
La solution à deux tables
La première discussion que j'ai eue à ce sujet remonte au milieu des années 90, lorsque je travaillais pour une compagnie d'assurance du marché londonien. À l'époque, nous allions directement à la conception physique et utilisions principalement des clés naturelles/professionnelles, et non des identifiants. Là où des données de référence existaient, nous avons décidé de conserver une table par type composée d'un code unique (le VARCHAR PK) et d'une description. En fait, il y avait alors beaucoup moins de tables de référence. Le plus souvent, un ensemble restreint de codes d'entreprise serait utilisé dans une colonne, éventuellement avec une contrainte de vérification de base de données définie ; il n'y aurait aucune table de référence.
Mais le jeu a évolué depuis. C'est ce qu'une solution à deux tables pourrait ressembler à :
Comme vous pouvez le voir, ce modèle physique de données est très simple. Mais c'est assez différent du modèle logique, et pas parce que quelque chose a pris la forme d'une poire. C'est parce qu'un certain nombre de choses ont été faites dans le cadre de la conception physique .
Le reference_type table représente chaque classe de référence individuelle du MLD. Donc, si vous avez 20 types de référence dans votre MLD, vous aurez 20 lignes de métadonnées dans le tableau. Le reference_value le tableau contient les valeurs autorisées pour tous les types de référence.
A l'époque de ce projet, il y avait des discussions assez animées entre les développeurs. Certains ont préféré la solution à deux tables et d'autres ont préféré une table par type méthode.
Il y a des avantages et des inconvénients pour chaque solution. Comme vous pouvez le deviner, les développeurs étaient principalement préoccupés par la quantité de travail que l'interface utilisateur prendrait. Certains pensaient que créer une interface utilisateur d'administration pour chaque table serait assez rapide. D'autres pensaient que la création d'une interface utilisateur d'administration unique serait plus complexe, mais finalement payante.
Sur ce projet particulier, la solution à deux tables a été privilégiée. Regardons cela plus en détail.
Le modèle de données de référence extensible et flexible
Comme votre modèle de données évolue au fil du temps et que de nouveaux types de référence sont requis, vous n'avez pas besoin de continuer à apporter des modifications à votre base de données pour chaque nouveau type de référence. Il vous suffit de définir de nouvelles données de configuration. Pour ce faire, vous ajoutez une nouvelle ligne au reference_type table et ajoutez sa liste contrôlée de valeurs autorisées au reference_value tableau.
Un concept important contenu dans cette solution est celui de définir des périodes de temps effectives pour certaines valeurs. Par exemple, votre organisation peut avoir besoin de saisir une nouvelle reference_value de « preuve d'identité » qui sera acceptable à une date ultérieure. Il s'agit simplement d'ajouter ce nouveau reference_value avec le effective_period_from date correctement réglée. Cela peut être fait à l'avance. Jusqu'à cette date, la nouvelle entrée n'apparaîtra pas dans la liste déroulante des valeurs que voient les utilisateurs de votre application. En effet, votre application n'affiche que les valeurs actuelles ou activées.
D'autre part, vous devrez peut-être empêcher les utilisateurs d'utiliser un reference_value . Dans ce cas, mettez-le simplement à jour avec le effective_period_to date correctement réglée. Une fois ce jour passé, la valeur n'apparaîtra plus dans la liste déroulante. Il devient désactivé à partir de ce moment. Mais comme il existe toujours physiquement en tant que ligne dans la table, l'intégrité référentielle est maintenue pour les tables où il a déjà été référencé.
Maintenant que nous travaillions sur la solution à deux tables, il est devenu évident que certaines colonnes supplémentaires seraient utiles sur le reference_type table. Celles-ci étaient principalement centrées sur les problèmes d'interface utilisateur.
Par exemple, pretty_name sur le reference_type table a été ajoutée pour être utilisée dans l'interface utilisateur. Il est utile pour les grandes taxonomies d'utiliser une fenêtre avec une fonction de recherche. Puis pretty_name pourrait être utilisé pour le titre de la fenêtre.
En revanche, si une liste déroulante de valeurs est suffisante, pretty_name peut être utilisé pour l'invite LOV. De la même manière, la description peut être utilisée dans l'interface utilisateur pour remplir l'aide de survol.
Examiner le type de configuration ou de métadonnées qui entre dans ces tableaux aidera à clarifier un peu les choses.
Comment gérer tout cela
Si l'exemple utilisé ici est très simple, les valeurs de référence pour un gros projet peuvent rapidement devenir assez complexes. Il peut donc être conseillé de conserver tout cela dans un tableur. Si tel est le cas, vous pouvez utiliser la feuille de calcul elle-même pour générer le SQL à l'aide de la concaténation de chaînes. Ceci est collé dans des scripts, qui sont exécutés sur les bases de données cibles qui prennent en charge le cycle de développement et la base de données de production (en direct). Cela alimente la base de données avec toutes les données de référence nécessaires.
Voici les données de configuration pour les deux types de LDM, Gender_Type et Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Il y a une ligne dans reference_type pour chaque sous-type LDM de Root_Reference_Type . La description dans reference_type est tiré de la description de la classe LDM. Pour Gender_Type , cela se lirait "Identifie le sexe d'une personne". Les extraits DML montrent les différences dans les descriptions entre le type et la valeur, qui peuvent être utilisées dans l'interface utilisateur ou dans les rapports.
Vous verrez que reference_type appelé Gender_Type a été alloué une plage de 13000000 à 13999999 pour son reference_value.ids associé . Dans ce modèle, chaque reference_type se voit attribuer une plage d'ID unique et sans chevauchement. Ce n'est pas strictement nécessaire, mais cela nous permet de regrouper les ID de valeur associés. Cela imite en quelque sorte ce que vous obtiendriez si vous aviez des tables séparées. C'est bien de l'avoir, mais si vous pensez qu'il n'y a aucun avantage à cela, vous pouvez vous en passer.
Une autre colonne qui a été ajoutée au PDM est admin_role . Voici pourquoi.
Qui sont les administrateurs
Certaines taxonomies peuvent avoir des valeurs ajoutées ou supprimées avec peu ou pas d'impact. Cela se produit lorsqu'aucun programme n'utilise les valeurs dans leur logique, ou lorsque le type n'est pas interfacé avec d'autres systèmes. Dans de tels cas, les administrateurs des utilisateurs peuvent les tenir à jour en toute sécurité.
Mais dans d'autres cas, il faut faire preuve de beaucoup plus de prudence. Une nouvelle valeur de référence peut avoir des conséquences imprévues sur la logique du programme ou sur les systèmes en aval.
Par exemple, supposons que nous ajoutions ce qui suit à la taxonomie Type de sexe :
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Cela devient rapidement un problème si nous avons la logique suivante intégrée quelque part :
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
De toute évidence, la logique "si vous n'êtes pas un homme, vous devez être une femme" ne s'applique plus dans la taxonomie étendue.
C'est là que le admin_role colonne entre en jeu. Il est né de discussions avec les développeurs sur la conception physique et a fonctionné en conjonction avec leur solution d'interface utilisateur. Mais si la solution d'une table par classe avait été choisie, alors reference_type n'aurait pas existé. Les métadonnées qu'il contenait auraient été codées en dur dans l'application Gender_Type table – , qui n'est ni flexible ni extensible.
Seuls les utilisateurs disposant des privilèges appropriés peuvent administrer la taxonomie. Cela est susceptible d'être basé sur l'expertise en la matière (PME ). D'un autre côté, certaines taxonomies peuvent devoir être administrées par le service informatique pour permettre une analyse d'impact, des tests approfondis et la publication harmonieuse de toute modification de code à temps pour la nouvelle configuration. (Que cela soit fait par des demandes de modification ou d'une autre manière dépend de votre organisation.)
Vous avez peut-être remarqué que les colonnes d'audit created_by , created_date , updated_by , et updated_date ne sont pas du tout référencés dans le script ci-dessus. Encore une fois, si vous n'êtes pas intéressé par ceux-ci, vous n'êtes pas obligé de les utiliser. Cette organisation particulière avait une norme qui imposait d'avoir des colonnes d'audit sur chaque table.
Déclencheurs :maintenir la cohérence
Les déclencheurs garantissent que ces colonnes d'audit sont constamment mises à jour, quelle que soit la source du SQL (scripts, votre application, mises à jour par lots planifiées, mises à jour ad hoc, etc.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Mon expérience est principalement Oracle et, malheureusement, Oracle limite les identifiants à 30 octets. Pour éviter de dépasser cela, chaque table reçoit un alias court de trois à cinq caractères et d'autres artefacts liés à la table utilisent cet alias dans leurs noms. Donc, reference_value L'alias de est reva – les deux premiers caractères de chaque mot. Avant l'insertion de ligne et avant la mise à jour de la ligne est abrégé en bri et bru respectivement. Le nom de la séquence reva_seq , et ainsi de suite.
Les déclencheurs de codage manuel comme celui-ci, table après table, nécessitent beaucoup de travail de passe-partout démoralisant pour les développeurs. Heureusement, ces déclencheurs peuvent être créés via la génération de code , mais c'est le sujet d'un autre article !
L'importance des clés
Le ref_type_key et type_key les colonnes sont toutes deux limitées à 30 octets. Cela permet de les utiliser dans des requêtes SQL de type PIVOT (dans Oracle. D'autres bases de données peuvent ne pas avoir la même restriction de longueur d'identifiant).
Étant donné que l'unicité de la clé est assurée par la base de données et que le déclencheur garantit que sa valeur reste la même à tout moment, ces clés peuvent - et doivent - être utilisées dans les requêtes et le code pour les rendre plus lisibles . Qu'est-ce que je veux dire par là ? Eh bien, au lieu de :
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Vous écrivez :
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Fondamentalement, la clé indique clairement ce que fait la requête .
Du LDM au PDM, avec de l'espace pour évoluer
Le voyage de LDM à PDM n'est pas nécessairement une route droite. Ce n'est pas non plus une transformation directe de l'un à l'autre. C'est un processus distinct qui introduit ses propres considérations et ses propres préoccupations.
Comment modélisez-vous les données de référence dans votre base de données ?