Dans la section des commentaires de l'un de nos blogs, un lecteur a posé une question sur l'impact de wsrep_slave_threads sur les performances et l'évolutivité des E/S de Galera Cluster. À ce moment-là, nous ne pouvions pas facilement répondre à cette question et l'étayer avec plus de données, mais nous avons finalement réussi à configurer l'environnement et à exécuter quelques tests.
Notre lecteur a pointé vers des benchmarks qui ont montré que l'augmentation de wsrep_slave_threads n'avait aucun impact sur les performances du cluster Galera.
Pour expliquer l'impact de ce paramètre, nous avons configuré un petit cluster de trois nœuds (m5d.xlarge). Cela nous a permis d'utiliser le SSD nvme directement attaché pour le répertoire de données MySQL. Ce faisant, nous avons minimisé le risque que le stockage ne devienne le goulot d'étranglement de notre configuration.
Nous avons configuré le pool de mémoire tampon InnoDB sur 8 Go et refait les journaux sur deux fichiers de 1 Go chacun. Nous avons également augmenté innodb_io_capacity à 2000 et innodb_io_capacity_max à 10000. Cela visait également à garantir qu'aucun de ces paramètres n'affecterait nos performances.
Tout le problème avec de tels benchmarks est qu'il y a tellement de goulots d'étranglement qu'il faut les éliminer un par un. Ce n'est qu'après avoir effectué quelques réglages de configuration et après s'être assuré que le matériel ne posera pas de problème que l'on peut espérer que des limites plus subtiles apparaîtront.
Nous avons généré environ 90 Go de données à l'aide de sysbench :
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareEnsuite, le benchmark a été exécuté. Nous avons testé deux paramètres :wsrep_slave_threads=1 et wsrep_slave_threads=16. Le matériel n'était pas assez puissant pour bénéficier d'une augmentation supplémentaire de cette variable. Veuillez également garder à l'esprit que nous n'avons pas effectué d'analyse comparative détaillée afin de déterminer si wsrep_slave_threads doit être défini sur 16, 8 ou peut-être 4 pour obtenir les meilleures performances. Nous étions intéressés de voir si nous pouvions montrer un impact sur le cluster. Et oui, l'impact était clairement visible. Pour commencer, quelques graphiques de contrôle de flux.
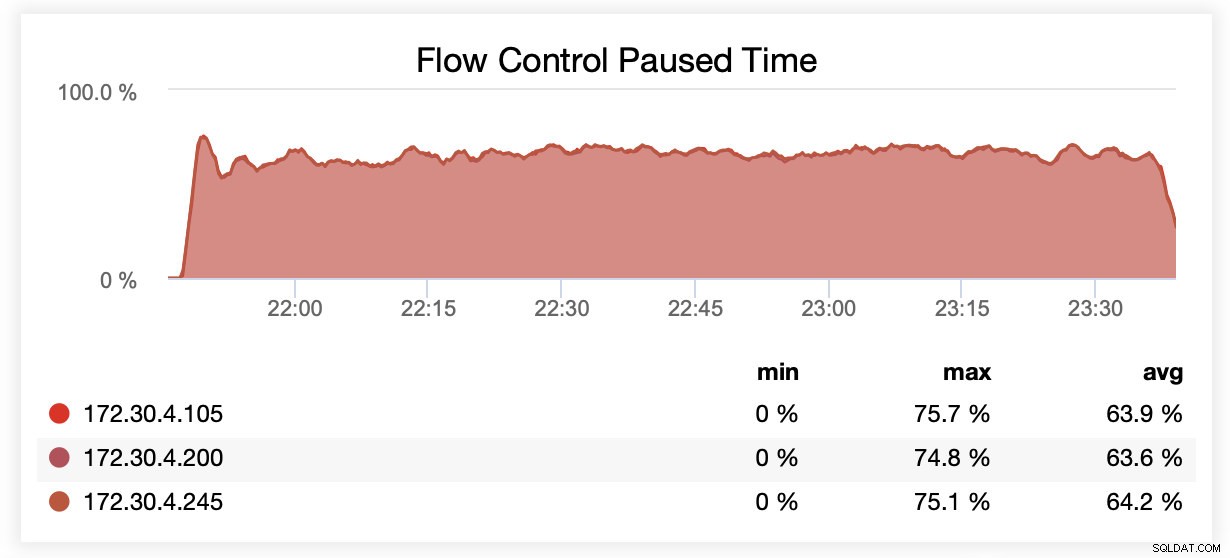
Lors de l'exécution avec wsrep_slave_threads=1, en moyenne, les nœuds ont été suspendus en raison du contrôle de flux environ 64 % du temps.
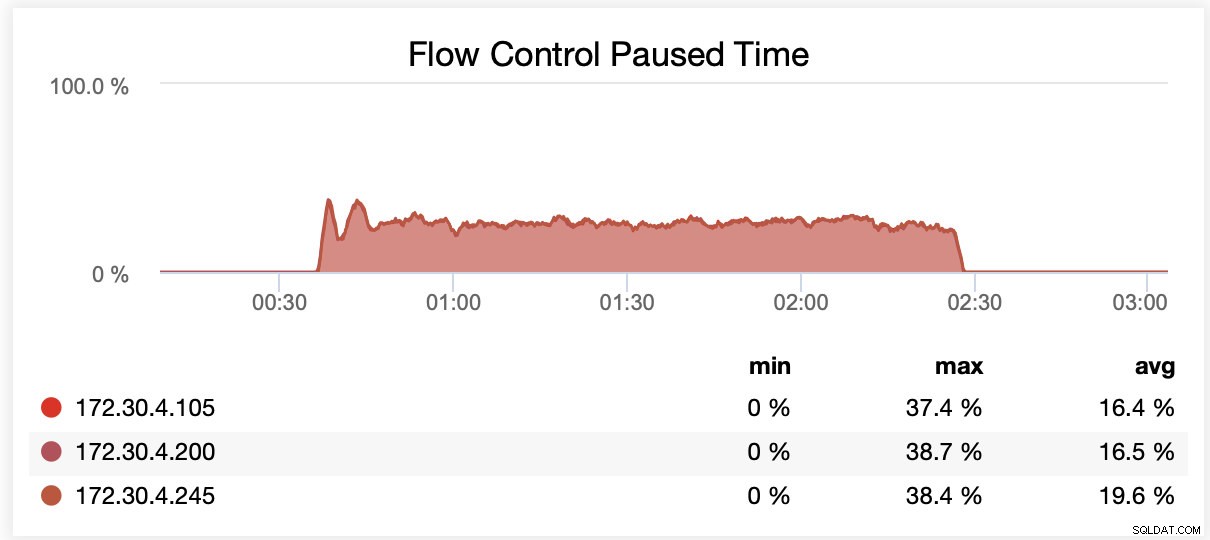
Lors de l'exécution avec wsrep_slave_threads=16, en moyenne, les nœuds ont été mis en pause en raison du contrôle de flux environ 20 % du temps.
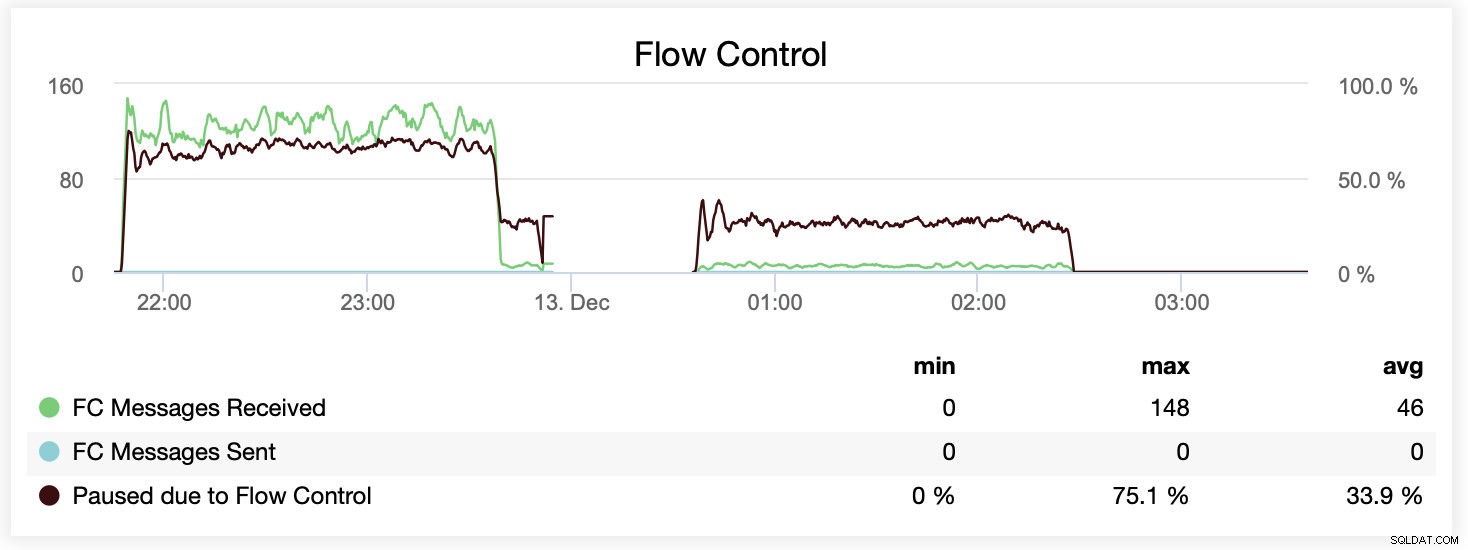
Vous pouvez également comparer la différence sur un seul graphique. La suppression à la fin de la première partie est la première tentative d'exécution avec wsrep_slave_threads=16. Les serveurs ont manqué d'espace disque pour les journaux binaires et nous avons dû réexécuter ce benchmark une fois de plus ultérieurement.
Comment cela s'est-il traduit en termes de performances ? La différence est visible bien que certainement pas si spectaculaire.
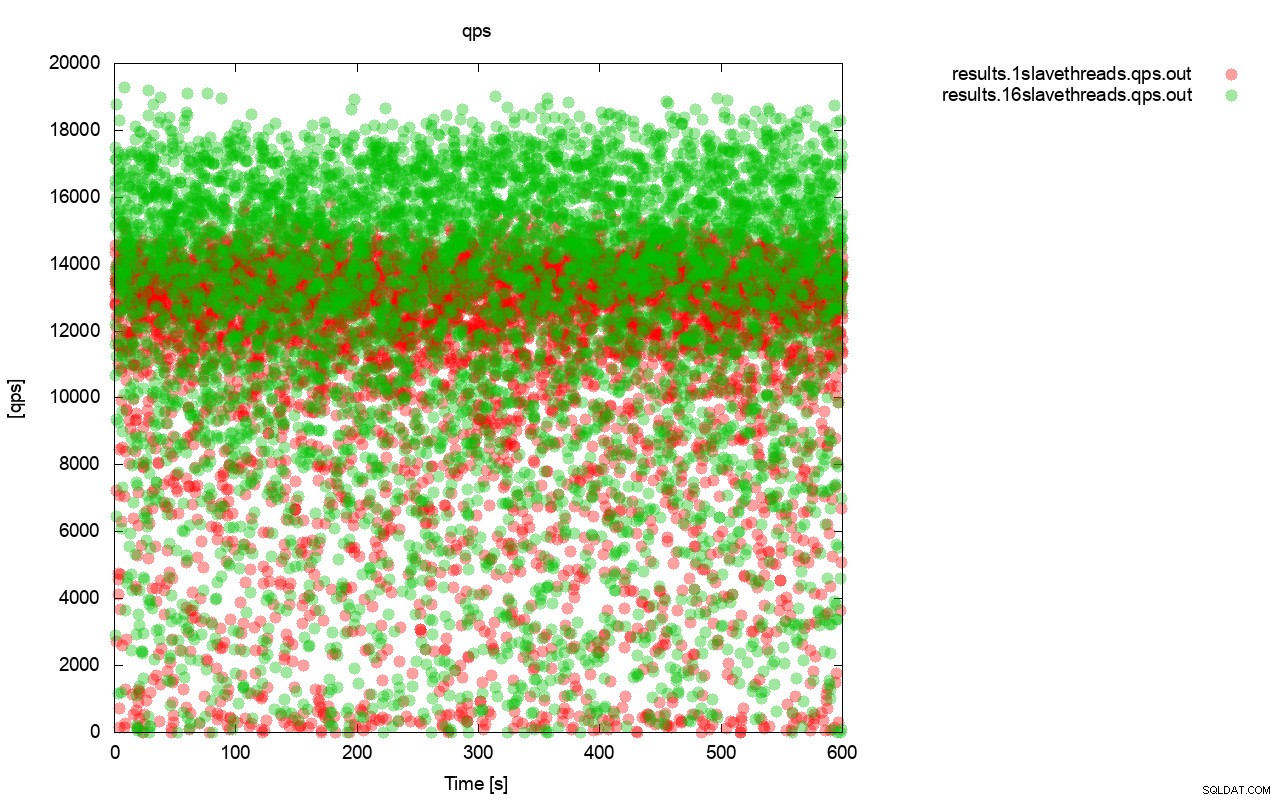
Tout d'abord, le graphique requête par seconde. Tout d'abord, vous pouvez remarquer que dans les deux cas, les résultats sont partout. Ceci est principalement lié aux performances instables du stockage d'E / S et au contrôle de flux qui s'active de manière aléatoire. Vous pouvez toujours voir que les performances du résultat «rouge» (wsrep_slave_threads =1) sont bien inférieures à celles du résultat «vert» ( wsrep_slave_threads=16).
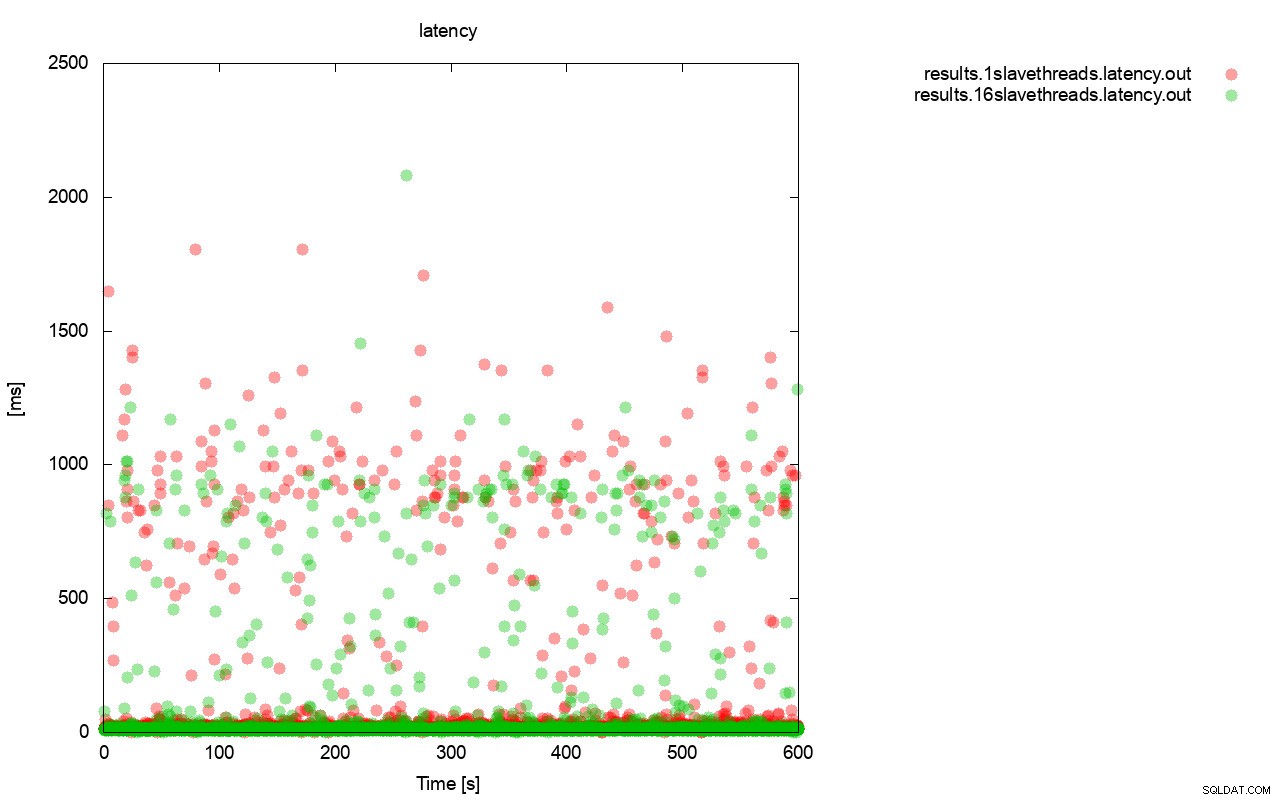
Une image assez similaire est lorsque nous regardons la latence. Vous pouvez voir plus de stands (et généralement plus profonds) pour la course avec wsrep_slave_thread=1.
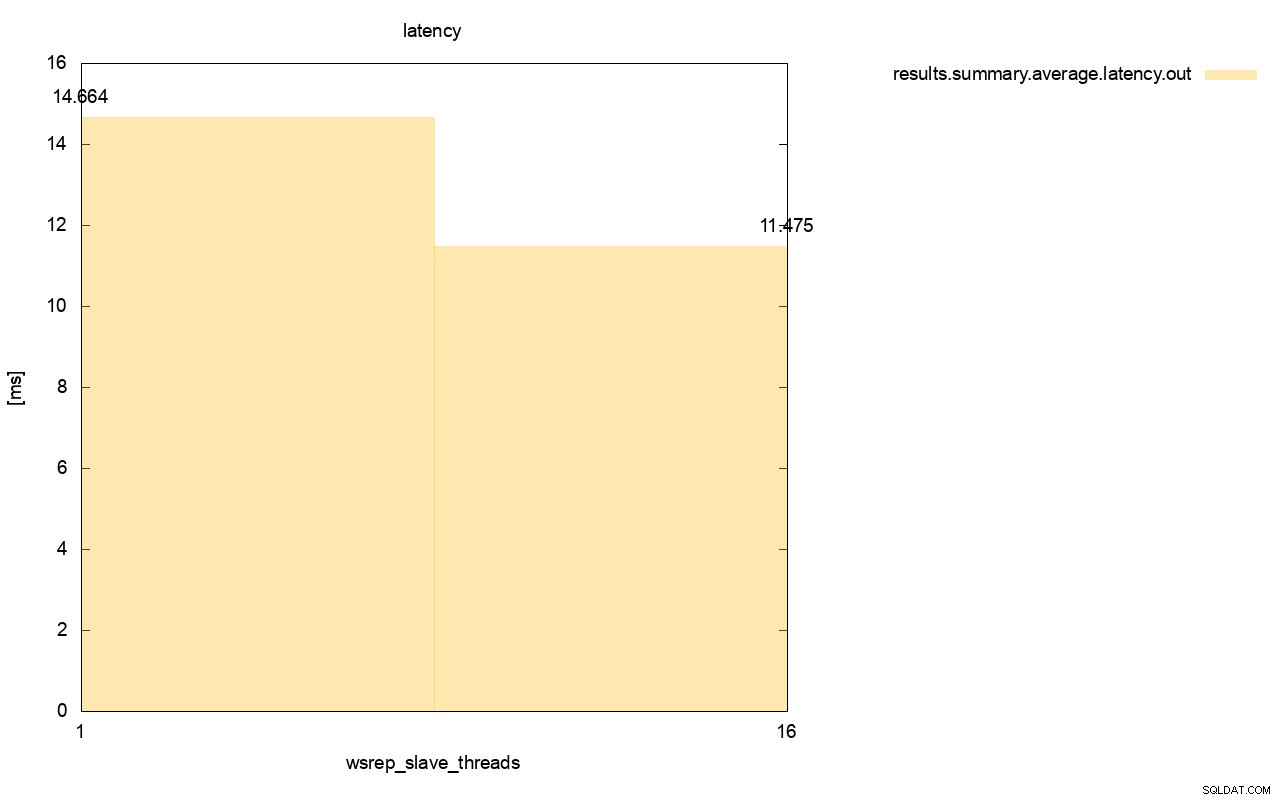
La différence est encore plus visible lorsque nous avons calculé la latence moyenne sur toutes les exécutions et vous pouvez voir que la latence de wsrep_slave_thread=1 est supérieure de 27 % à la latence avec 16 threads esclaves, ce qui n'est évidemment pas bon car nous voulons que la latence soit plus faible , pas plus haut.
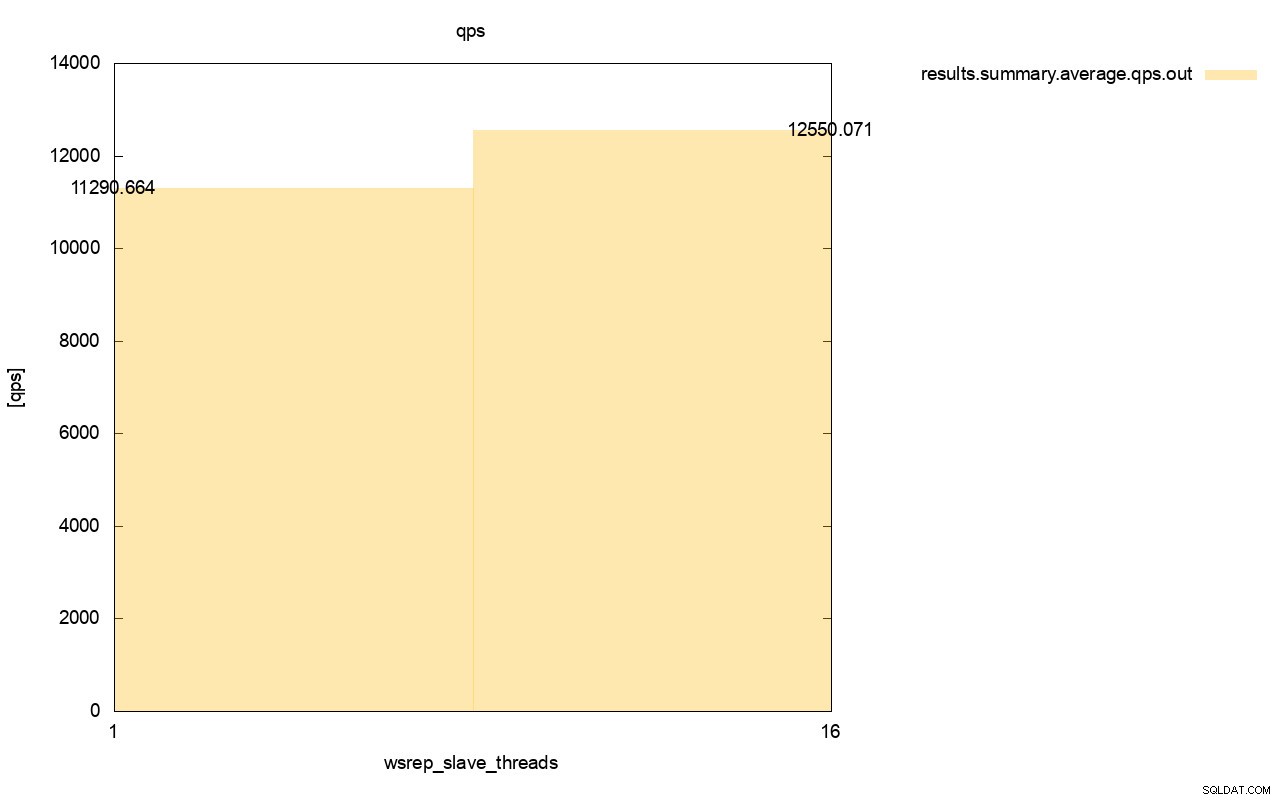
La différence de débit est également visible, environ 11 % de l'amélioration lorsque nous avons ajouté plus de wsrep_slave_threads.
Comme vous pouvez le voir, l'impact est là. Ce n'est en aucun cas 16x (même si c'est ainsi que nous avons augmenté le nombre de threads esclaves dans Galera), mais c'est suffisamment important pour que nous ne puissions pas le classer comme une simple anomalie statistique.
Veuillez garder à l'esprit que dans notre cas, nous avons utilisé des nœuds assez petits. La différence devrait être encore plus importante si nous parlons d'instances volumineuses exécutées sur des volumes EBS avec des milliers d'IOPS provisionnés.
Ensuite, nous serions en mesure d'exécuter sysbench de manière encore plus agressive, avec un plus grand nombre d'opérations simultanées. Cela devrait améliorer la parallélisation des jeux d'écriture, améliorant encore plus le gain du multithreading. De plus, un matériel plus rapide signifie que Galera pourra utiliser ces 16 threads de manière plus efficace.
Lorsque vous exécutez des tests comme celui-ci, vous devez garder à l'esprit que vous devez pousser votre configuration presque jusqu'à ses limites. La réplication monothread peut gérer une charge assez importante et vous devez gérer un trafic important pour qu'elle ne soit pas assez performante pour gérer la tâche.
Nous espérons que cet article de blog vous donnera plus d'informations sur les capacités de Galera Cluster à appliquer des jeux d'écriture en parallèle et sur les facteurs limitants qui l'entourent.