Galera Cluster, avec sa réplication (virtuellement) synchrone, est couramment utilisé dans de nombreux types d'environnements différents. Le mettre à l'échelle en ajoutant de nouveaux nœuds n'est pas difficile (ou simplement en quelques clics lorsque vous utilisez ClusterControl).
Le principal problème avec la réplication synchrone est, eh bien, la partie synchrone qui se traduit souvent par le fait que l'ensemble du cluster n'est aussi rapide que son nœud le plus lent. Toute écriture exécutée sur un cluster doit être répliquée sur tous les nœuds et certifiée sur eux. Si, pour une raison quelconque, ce processus ralentit, cela peut avoir un impact sérieux sur la capacité du cluster à gérer les écritures. Le contrôle de flux se déclenchera alors, ceci afin de s'assurer que le nœud le plus lent peut toujours suivre la charge. Cela rend la tâche assez délicate pour certains des scénarios courants qui se produisent dans un environnement réel.
Tout d'abord, parlons de la reprise après sinistre géographiquement distribuée. Bien sûr, vous pouvez exécuter des clusters sur un réseau étendu, mais la latence accrue aura un impact significatif sur les performances du cluster. Cela limite sérieusement la possibilité d'utiliser une telle configuration, en particulier sur de longues distances lorsque la latence est plus élevée.
Un autre cas d'utilisation assez courant - un environnement de test pour la mise à niveau d'une version majeure. Ce n'est pas une bonne idée de mélanger différentes versions des nœuds MariaDB Galera Cluster dans le même cluster, même si c'est possible. En revanche, la migration vers la version la plus récente nécessite des tests approfondis. Idéalement, les lectures et les écritures auraient été testées. Une façon d'y parvenir consiste à créer un cluster Galera séparé et à exécuter les tests, mais vous souhaitez exécuter les tests dans un environnement aussi proche que possible de la production. Une fois provisionné, un cluster peut être utilisé pour des tests avec des requêtes du monde réel mais il serait difficile de générer une charge de travail qui serait proche de celle de la production. Vous ne pouvez pas déplacer une partie du trafic de production vers un tel système de test, car les données ne sont pas à jour.
Enfin, la migration elle-même. Encore une fois, ce que nous avons dit précédemment, même s'il est possible de mélanger les anciennes et les nouvelles versions des nœuds Galera dans le même cluster, ce n'est pas la manière la plus sûre de le faire.
Heureusement, la solution la plus simple pour ces trois problèmes serait de connecter des clusters Galera séparés avec une réplication asynchrone. Qu'est-ce qui en fait une si bonne solution ? Eh bien, c'est asynchrone, ce qui n'affecte pas la réplication de Galera. Il n'y a pas de contrôle de flux, ainsi les performances du cluster "maître" ne seront pas affectées par les performances du cluster "esclave". Comme pour toute réplication asynchrone, un décalage peut apparaître, mais tant qu'il reste dans des limites acceptables, cela peut parfaitement fonctionner. Vous devez également garder à l'esprit qu'aujourd'hui, la réplication asynchrone peut être parallélisée (plusieurs threads peuvent fonctionner ensemble pour augmenter la bande passante) et réduire encore plus le délai de réplication.
Dans cet article de blog, nous discuterons des étapes à suivre pour déployer la réplication asynchrone entre les clusters MariaDB Galera.
Comment configurer la réplication asynchrone entre les clusters MariaDB Galera ?
Tout d'abord, nous devons déployer un cluster. Pour nos besoins, nous avons configuré un cluster à trois nœuds. Nous garderons la configuration au minimum, nous ne discuterons donc pas de la complexité de l'application et de la couche proxy. La couche proxy peut être très utile pour gérer les tâches pour lesquelles vous souhaitez déployer une réplication asynchrone - en redirigeant un sous-ensemble du trafic en lecture seule vers le cluster de test, en aidant dans la situation de reprise après sinistre lorsque le cluster "principal" n'est pas disponible en redirigeant le le trafic vers le cluster DR. Il existe de nombreux proxys que vous pouvez essayer, selon vos préférences - HAProxy, MaxScale ou ProxySQL - tous peuvent être utilisés dans de telles configurations et, selon le cas, certains d'entre eux peuvent vous aider à gérer votre trafic.
Configuration du cluster source
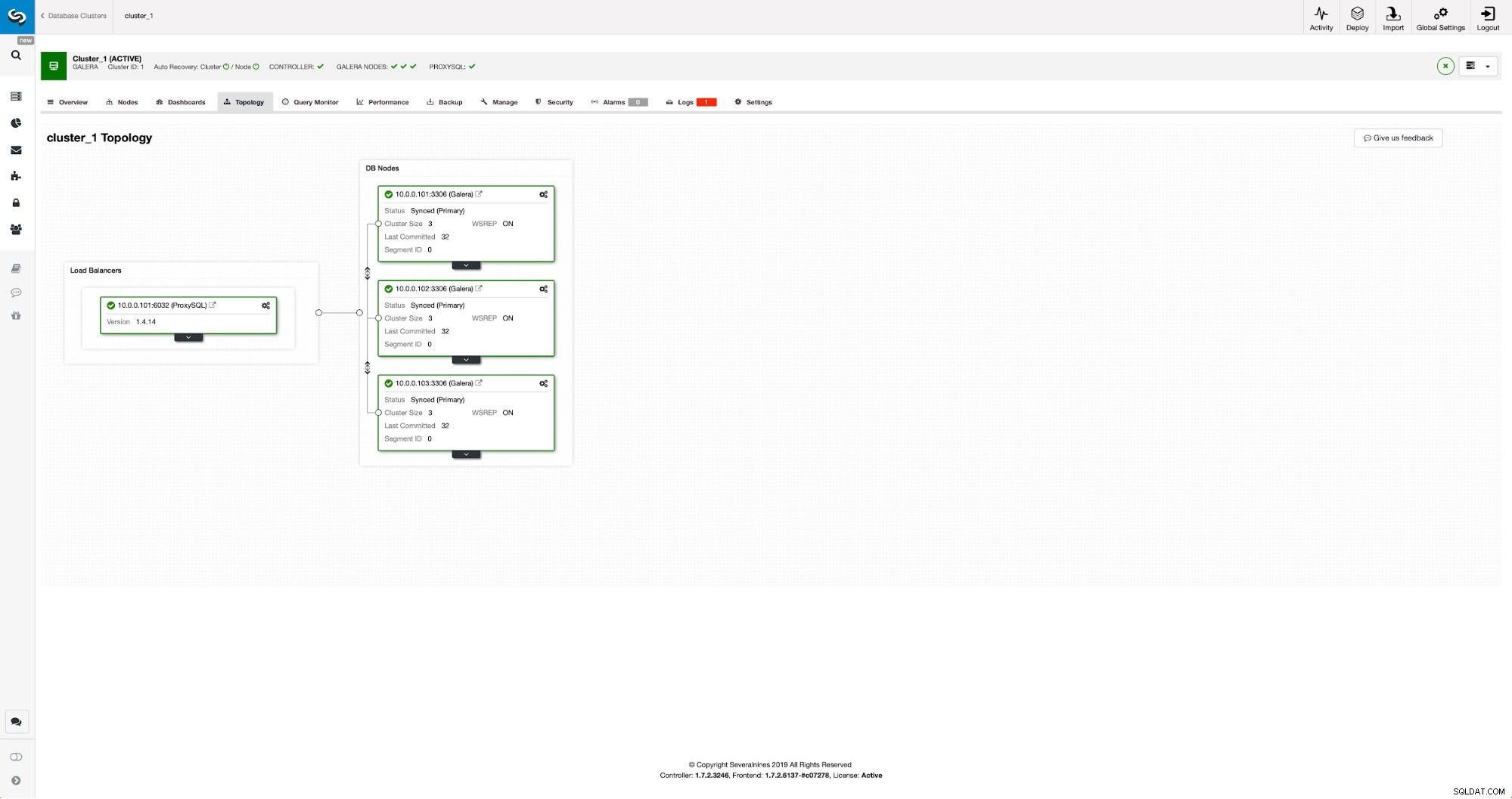
Notre cluster se compose de trois nœuds MariaDB 10.3, nous avons également déployé ProxySQL pour faire la séparation lecture-écriture et répartir le trafic sur tous les nœuds du cluster. Ce n'est pas un déploiement de niveau production, pour cela nous devrions déployer plus de nœuds ProxySQL et un Keepalived par-dessus. C'est encore suffisant pour nos besoins. Pour configurer la réplication asynchrone, nous devrons activer un journal binaire sur notre cluster. Au moins un nœud, mais il est préférable de le garder activé sur chacun d'eux au cas où le seul nœud avec binlog activé tomberait en panne - alors vous voulez avoir un autre nœud dans le cluster opérationnel que vous pouvez asservir.
Lors de l'activation du journal binaire, assurez-vous de configurer la rotation du journal binaire afin que les anciens journaux soient supprimés à un moment donné. Vous utiliserez le format de journal binaire ROW. Vous devez également vous assurer que GTID est configuré et utilisé - cela vous sera très utile lorsque vous devrez réasservir votre cluster "esclave" ou si vous devrez activer la réplication multithread. Comme il s'agit d'un cluster Galera, vous souhaitez configurer "wsrep_gtid_domain_id" et activer "wsrep_gtid_mode". Ces paramètres garantiront que les GTID seront générés pour le trafic provenant du cluster Galera. Plus d'informations peuvent être trouvées dans la documentation. Une fois que tout cela est fait, vous pouvez procéder à la configuration du deuxième cluster.
Configuration du cluster cible
Étant donné qu'il n'existe actuellement aucun cluster cible, nous devons commencer par le déployer. Nous ne couvrirons pas ces étapes en détail, vous pouvez trouver des instructions dans la documentation. De manière générale, le processus se compose de plusieurs étapes :
- Configurer les dépôts MariaDB
- Installer les packages MariaDB 10.3
- Configurer des nœuds pour former un cluster
Au début, nous commencerons avec un seul nœud. Vous pouvez tous les configurer pour former un cluster, mais vous devez ensuite les arrêter et n'en utiliser qu'un pour l'étape suivante. Ce nœud deviendra esclave du cluster d'origine. Nous utiliserons mariabackup pour le provisionner. Ensuite, nous configurerons la réplication.
Tout d'abord, nous devons créer un répertoire dans lequel nous stockerons la sauvegarde :
mkdir /mnt/mariabackupEnsuite, nous exécutons la sauvegarde et la créons dans le répertoire préparé à l'étape ci-dessus. Assurez-vous d'utiliser le bon utilisateur et le bon mot de passe pour vous connecter à la base de données :
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Ensuite, nous devons copier les fichiers de sauvegarde sur le premier nœud du deuxième cluster. Nous avons utilisé scp pour cela, vous pouvez utiliser ce que vous voulez - rsync, netcat, tout ce qui fonctionnera.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Une fois la sauvegarde copiée, nous devons la préparer en appliquant les fichiers journaux :
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!En cas d'erreur, vous devrez peut-être réexécuter la sauvegarde. Si tout s'est bien passé, nous pouvons supprimer les anciennes données et les remplacer par les informations de sauvegarde
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Nous souhaitons également définir le propriétaire correct des fichiers :
chown -R mysql.mysql /var/lib/mysql/Nous nous appuierons sur GTID pour maintenir la cohérence de la réplication. Nous devons donc voir quel a été le dernier GTID appliqué dans cette sauvegarde. Ces informations se trouvent dans le fichier xtrabackup_info qui fait partie de la sauvegarde :
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Nous devrons également nous assurer que le nœud esclave a activé les journaux binaires avec "log_slave_updates". Idéalement, cela sera activé sur tous les nœuds du deuxième cluster - juste au cas où le nœud "esclave" échouerait et vous devriez configurer la réplication à l'aide d'un autre nœud du cluster esclave.
La dernière chose que nous devons faire avant de pouvoir configurer la réplication est de créer un utilisateur que nous utiliserons pour exécuter la réplication :
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)C'est tout ce dont nous avons besoin. Maintenant, nous pouvons démarrer le premier nœud du deuxième cluster, notre to-be-slave :
galera_new_clusterUne fois qu'il est démarré, nous pouvons entrer MySQL CLI et le configurer pour devenir un esclave, en utilisant la position GITD que nous avons trouvée quelques étapes plus tôt :
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Une fois cela fait, nous pouvons enfin configurer la réplication et la démarrer :
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)À ce stade, nous avons un cluster Galera composé d'un nœud. Ce nœud est également un esclave du cluster d'origine (en particulier, son maître est le nœud 10.0.0.101). Pour rejoindre d'autres nœuds, nous utiliserons SST, mais pour le faire fonctionner, nous devons d'abord nous assurer que la configuration SST est correcte. N'oubliez pas que nous venons de remplacer tous les utilisateurs de notre deuxième cluster par le contenu du cluster source. Ce que vous devez faire maintenant est de vous assurer que la configuration "wsrep_sst_auth" du deuxième cluster correspond à celle du premier cluster. Une fois cela fait, vous pouvez démarrer les nœuds restants un par un et ils doivent rejoindre le nœud existant (10.0.0.104), obtenir les données via SST et former le cluster Galera. Finalement, vous devriez vous retrouver avec deux clusters, trois nœuds chacun, avec un lien de réplication asynchrone entre eux (de 10.0.0.101 à 10.0.0.104 dans notre exemple). Vous pouvez confirmer que la réplication fonctionne en vérifiant la valeur de :
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Comment configurer la réplication asynchrone entre les clusters MariaDB Galera à l'aide de ClusterControl ?
Au moment de ce blog, ClusterControl n'a pas la fonctionnalité pour configurer la réplication asynchrone sur plusieurs clusters, nous y travaillons au moment où je tape ceci. Néanmoins, ClusterControl peut être d'une grande aide dans ce processus - nous vous montrerons comment vous pouvez accélérer les étapes manuelles laborieuses en utilisant l'automatisation fournie par ClusterControl.
D'après ce que nous avons montré précédemment, nous pouvons conclure que ce sont les étapes générales à suivre lors de la configuration de la réplication entre deux clusters Galera :
- Déployer un nouveau cluster Galera
- Provisionner le nouveau cluster à l'aide des données de l'ancien
- Configurer le nouveau cluster (configuration SST, journaux binaires)
- Configurer la réplication entre l'ancien et le nouveau cluster
Les trois premiers points sont quelque chose que vous pouvez facilement faire en utilisant ClusterControl même maintenant. Nous allons vous montrer comment faire cela.
Déployer et provisionner un nouveau cluster MariaDB Galera à l'aide de ClusterControl
La situation initiale est similaire - nous avons un cluster opérationnel. Nous devons mettre en place le second. L'une des fonctionnalités les plus récentes de ClusterControl est une option permettant de déployer un nouveau cluster et de le provisionner à l'aide des données de la sauvegarde. Ceci est très utile pour créer des environnements de test, c'est également une option que nous utiliserons pour provisionner notre nouveau cluster pour la configuration de la réplication. Par conséquent, la première étape que nous allons suivre est de créer une sauvegarde à l'aide de mariabackup :
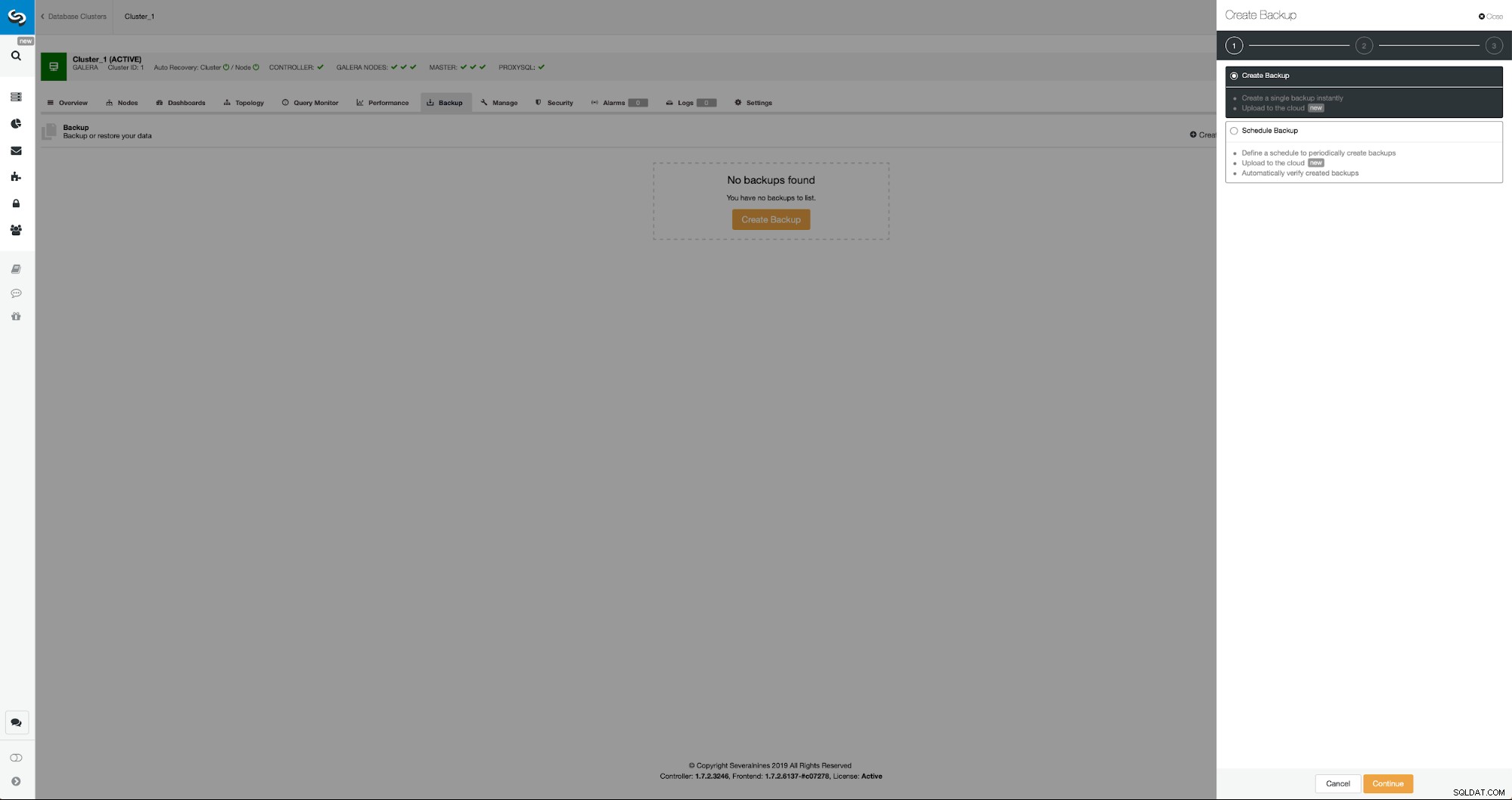
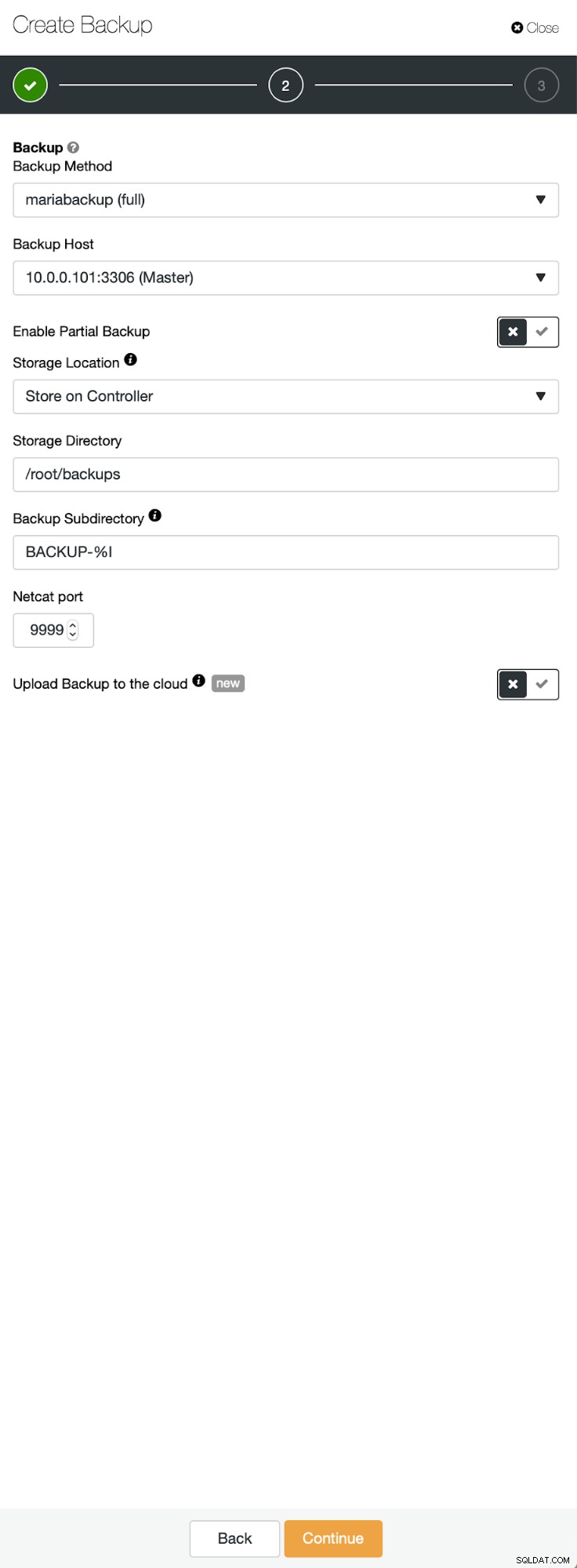
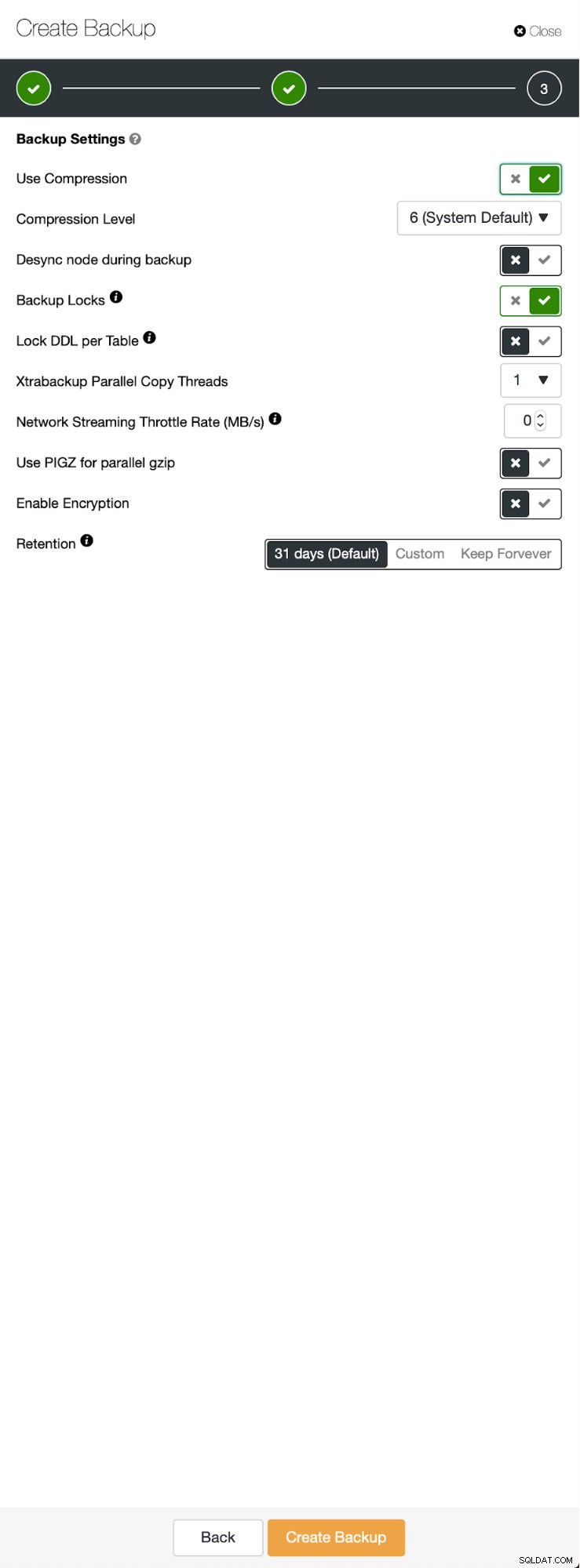
Trois étapes au cours desquelles nous avons choisi le nœud pour en retirer la sauvegarde. Ce nœud (10.0.0.101) deviendra un maître. Les journaux binaires doivent être activés. Dans notre cas, tous les nœuds ont binlog activé, mais s'ils ne l'avaient pas fait, il est très facile de l'activer à partir du ClusterControl - nous montrerons les étapes plus tard, lorsque nous le ferons pour le deuxième cluster.
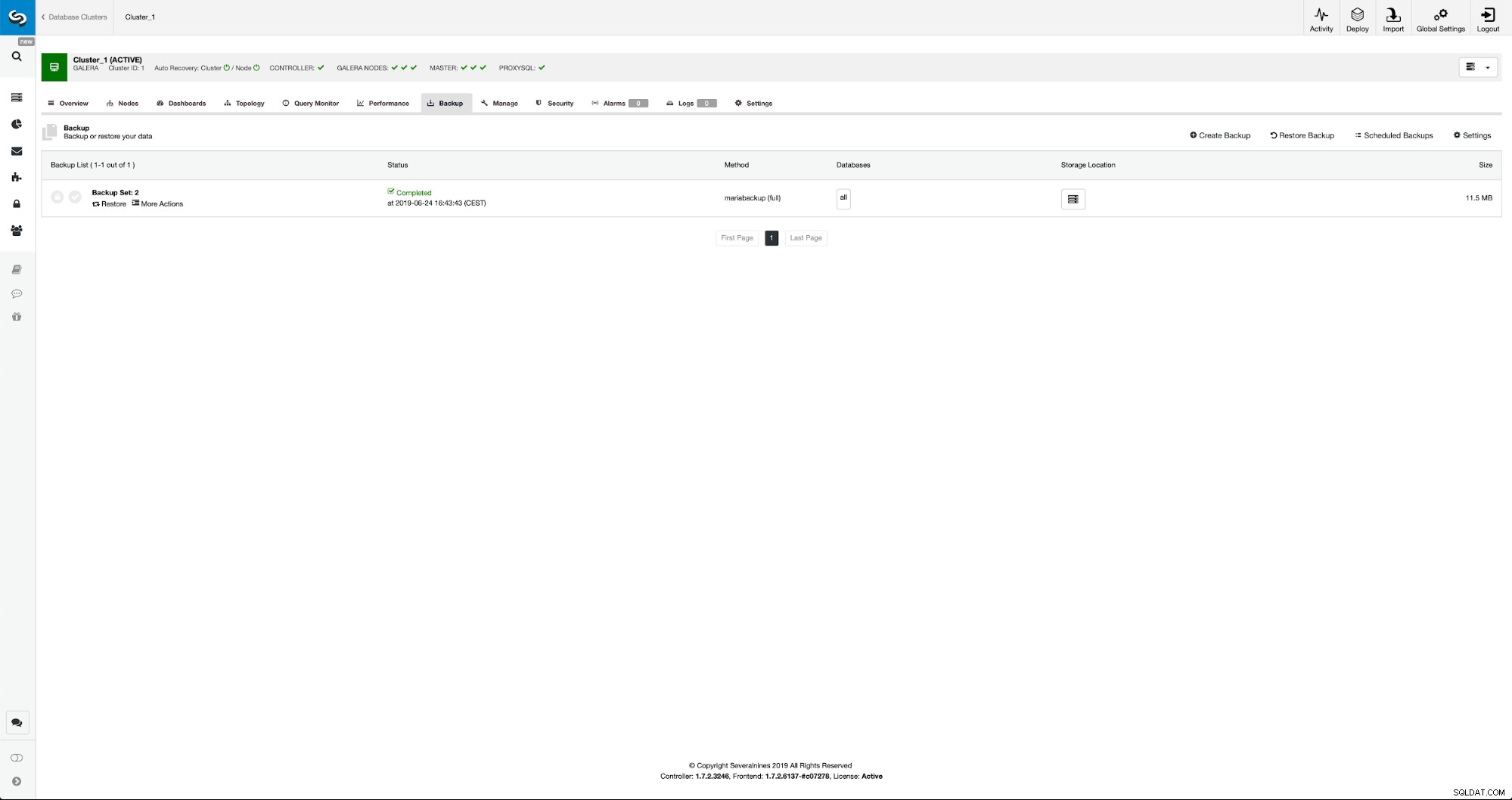
Une fois la sauvegarde terminée, elle deviendra visible dans la liste. Nous pouvons ensuite procéder et le restaurer :

Si nous le voulions, nous pourrions même faire la récupération ponctuelle, mais dans notre cas, cela n'a pas vraiment d'importance :une fois la réplication configurée, toutes les transactions requises des binlogs seront appliquées sur le nouveau cluster.

Ensuite, nous choisissons l'option de créer un cluster à partir de la sauvegarde. Cela ouvre une autre boîte de dialogue :
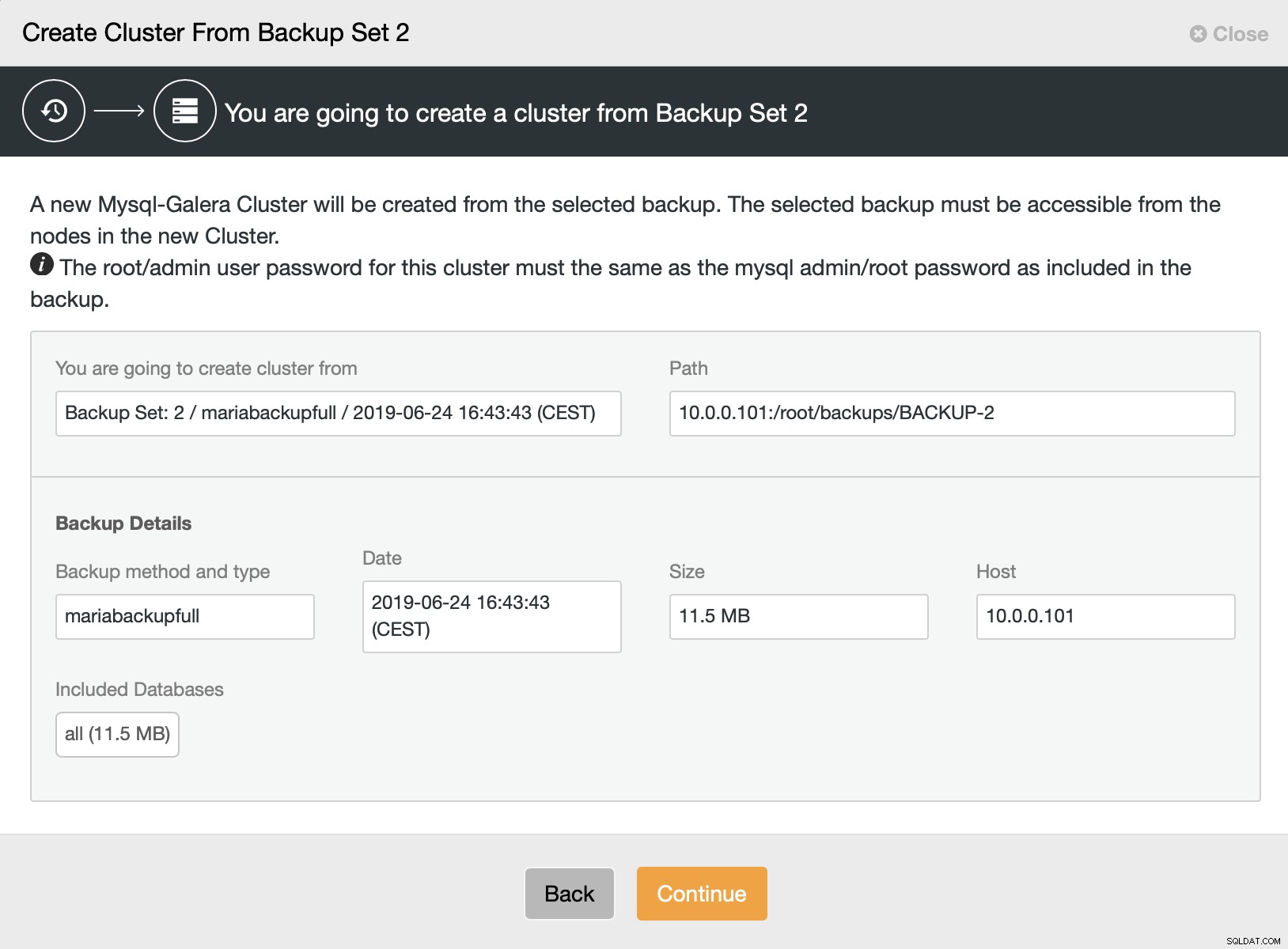
Il s'agit d'une confirmation de la sauvegarde qui sera utilisée, de l'hôte à partir duquel la sauvegarde a été prise, de la méthode utilisée pour la créer et de certaines métadonnées pour aider à vérifier si la sauvegarde semble correcte.
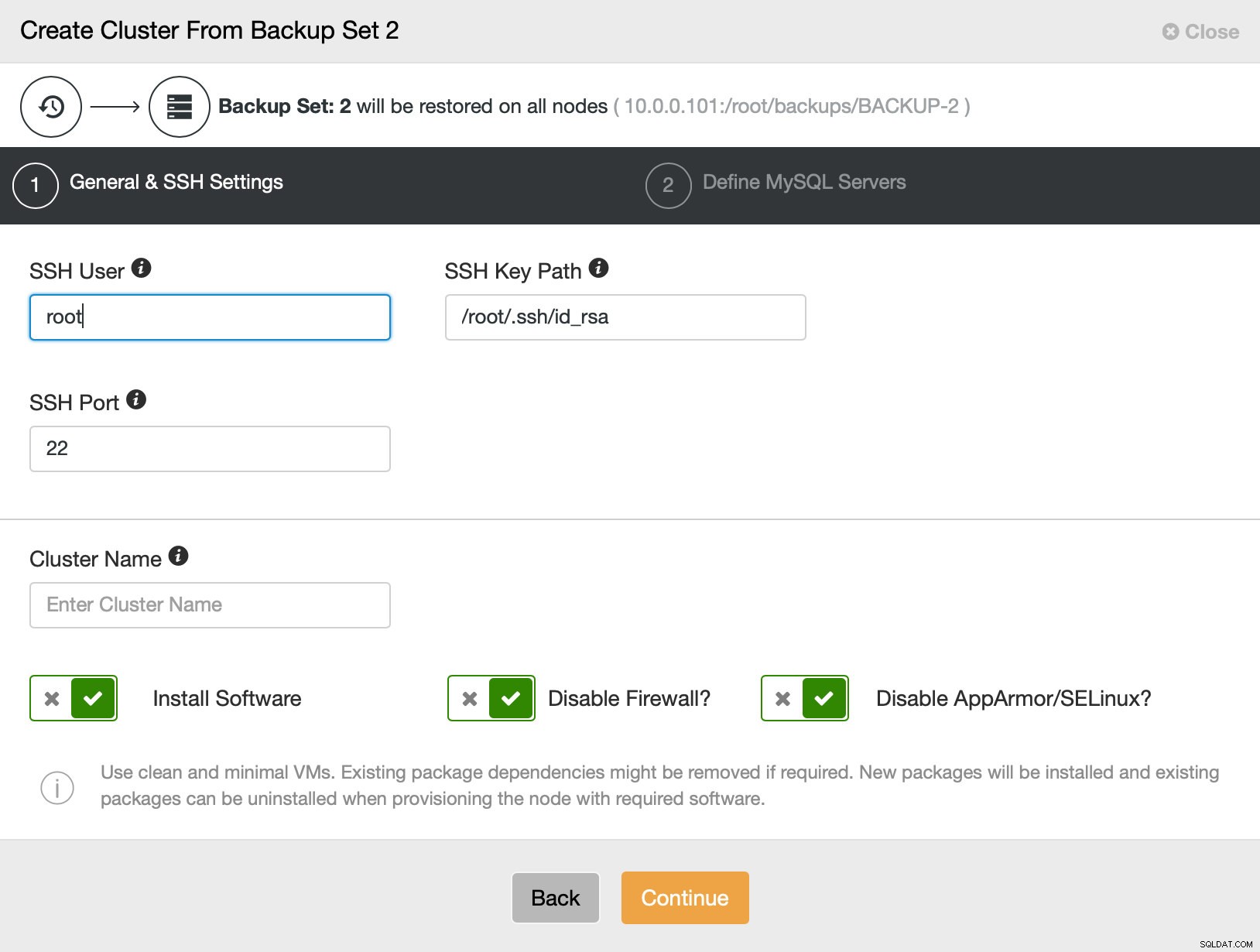
Ensuite, nous passons essentiellement à l'assistant de déploiement standard dans lequel nous devons définir la connectivité SSH entre l'hôte ClusterControl et les nœuds sur lesquels déployer le cluster (l'exigence pour ClusterControl) et, dans la deuxième étape, le fournisseur, la version, le mot de passe et les nœuds à déployer le :
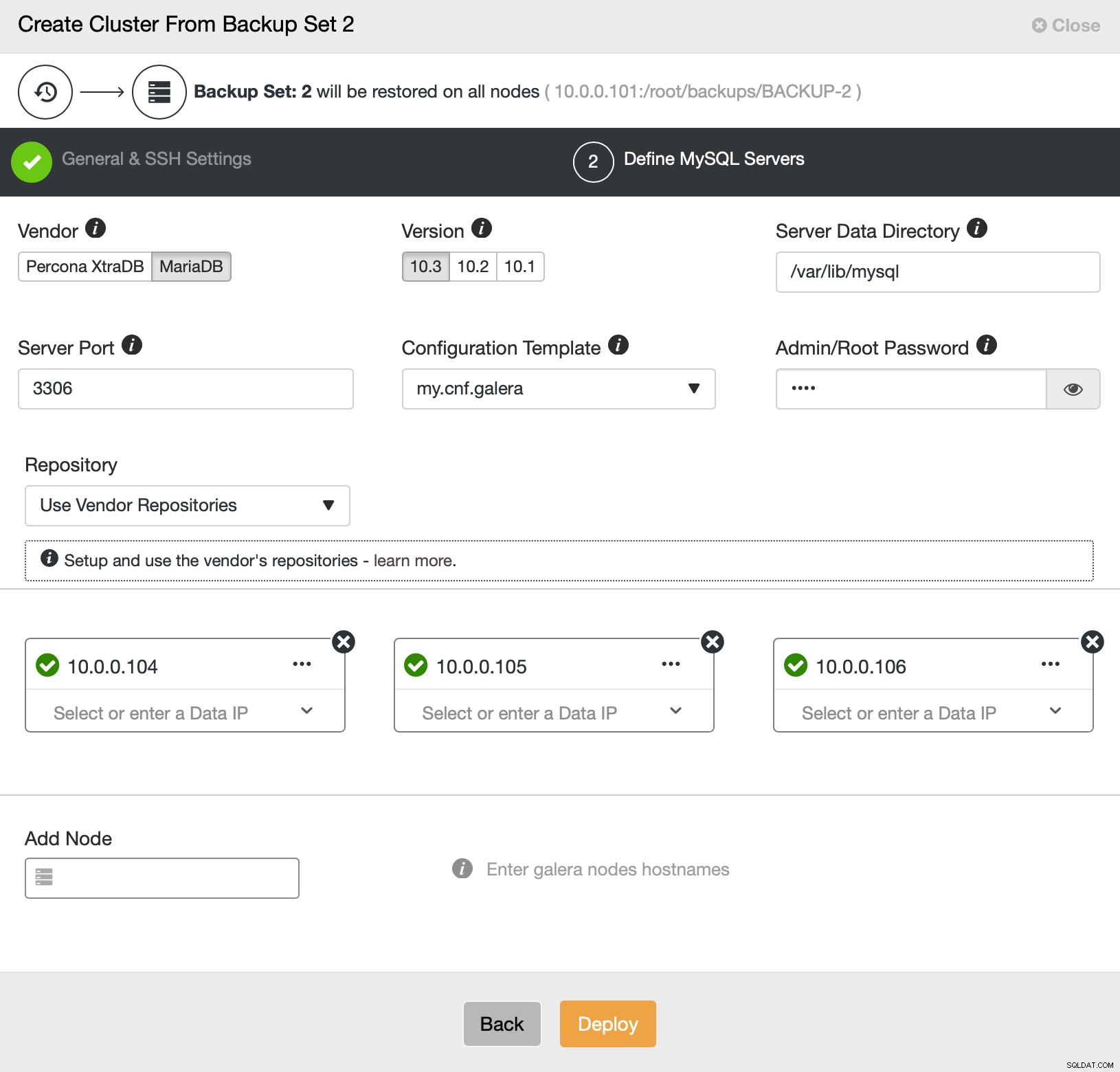
C'est tout ce qui concerne le déploiement et le provisionnement. ClusterControl configurera le nouveau cluster et le provisionnera en utilisant les données de l'ancien.
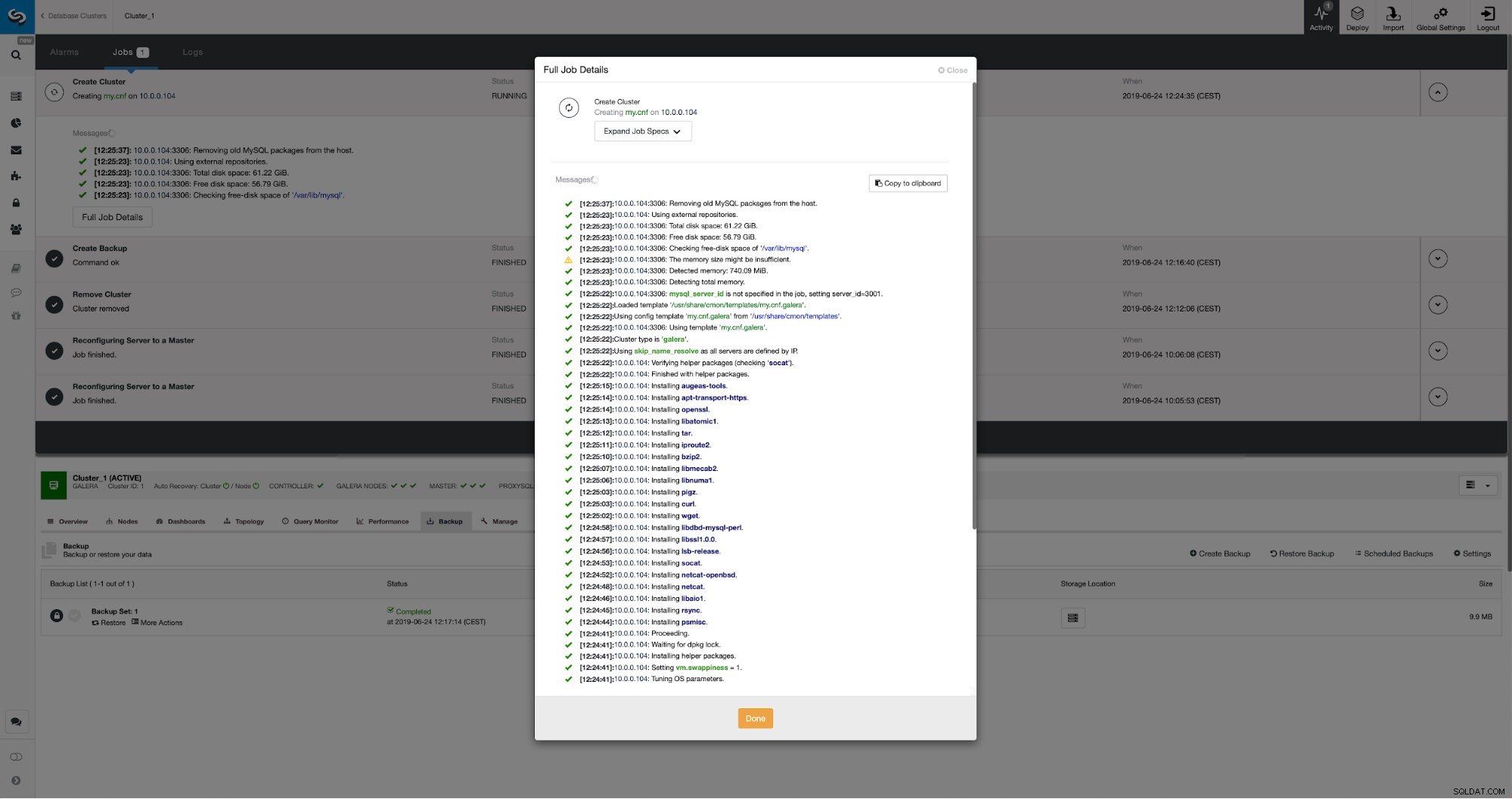
Nous pouvons suivre la progression dans l'onglet d'activité. Une fois terminé, le deuxième cluster apparaîtra sur la liste des clusters dans ClusterControl.
Reconfiguration du nouveau cluster à l'aide de ClusterControl
Maintenant, nous devons reconfigurer le cluster - nous allons activer les journaux binaires. Dans le processus manuel, nous avons dû apporter des modifications à la configuration wsrep_sst_auth ainsi qu'aux entrées de configuration dans les sections [mysqldump] et [xtrabackup] du fichier config. Ces paramètres se trouvent dans le fichier secrets-backup.cnf. Cette fois, ce n'est pas nécessaire car ClusterControl a généré de nouveaux mots de passe pour le cluster et configuré les fichiers correctement. Ce qu'il est important de garder à l'esprit, cependant, si vous modifiez le mot de passe de l'utilisateur 'backupuser'@'127.0.0.1' dans le cluster d'origine, vous devrez également apporter des modifications de configuration dans le deuxième cluster pour refléter cela comme des changements dans le premier cluster sera répliqué sur le deuxième cluster.
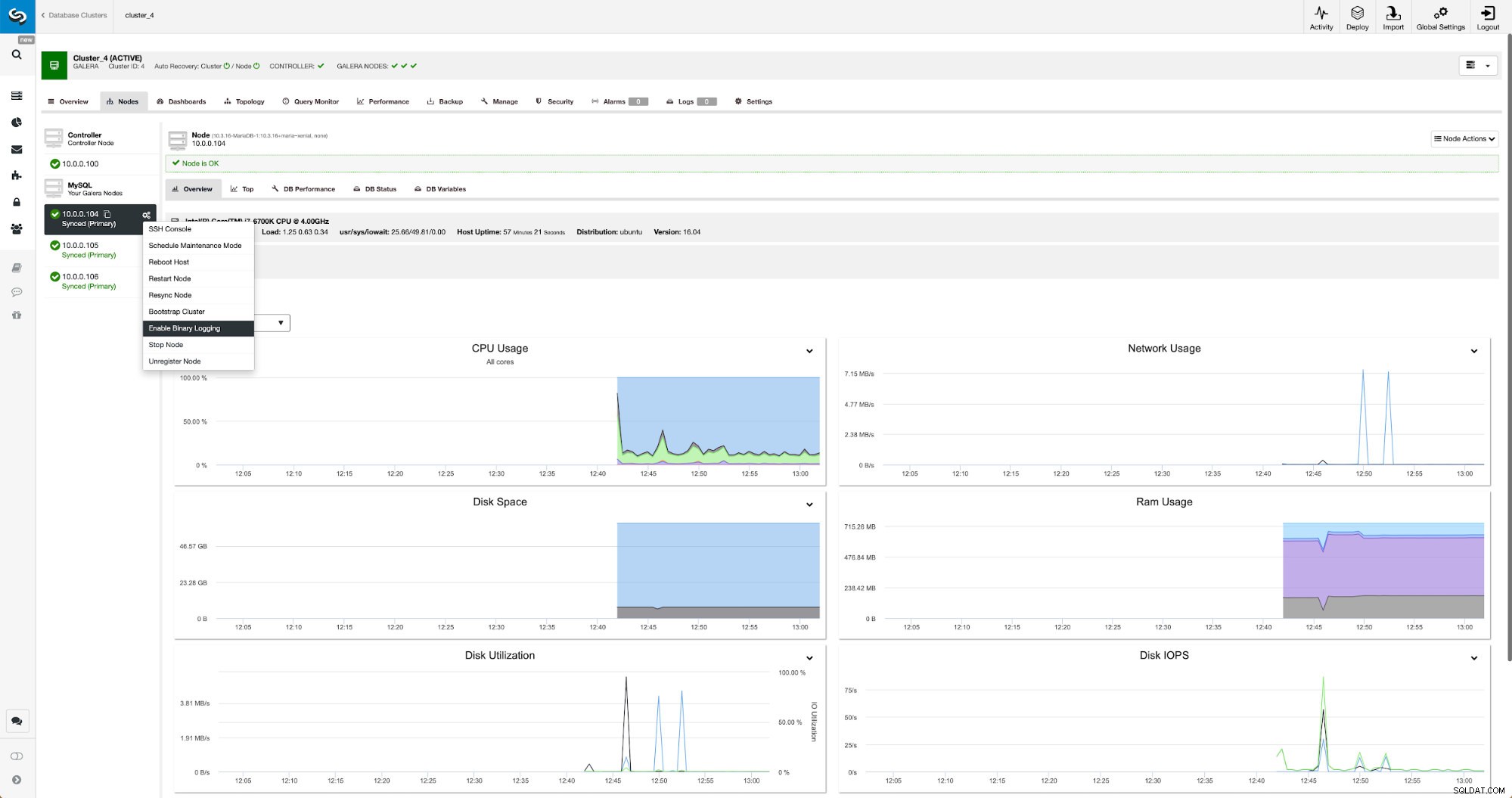
Les journaux binaires peuvent être activés à partir de la section Nœuds. Vous devez choisir nœud par nœud et exécuter le travail "Activer la journalisation binaire". Une boîte de dialogue s'affichera :
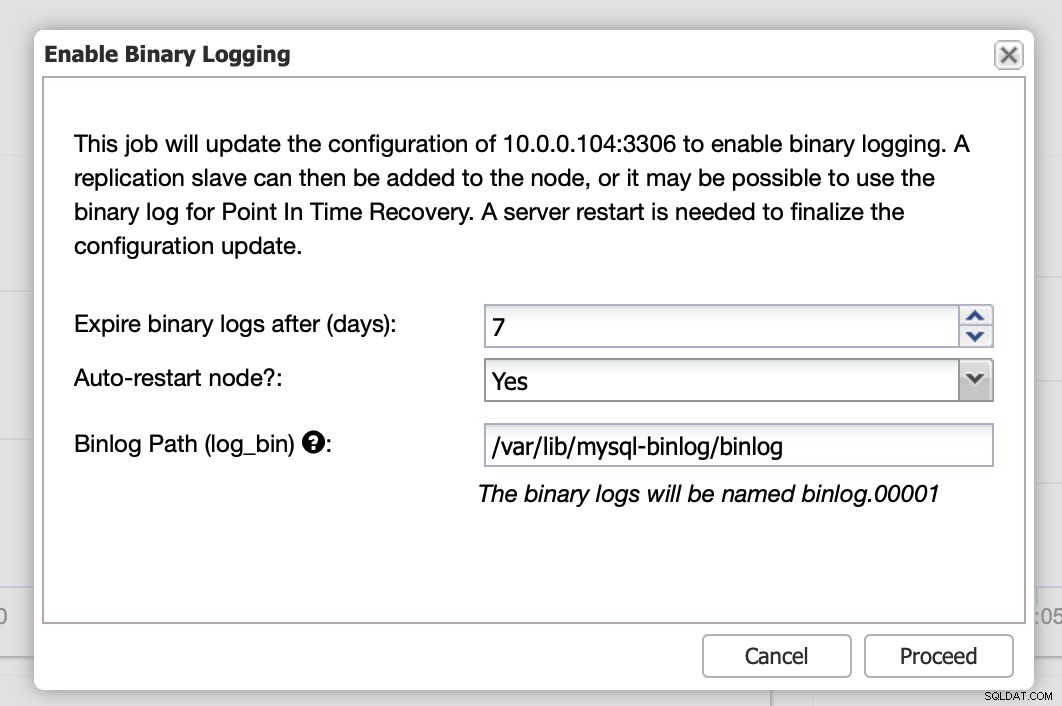
Ici, vous pouvez définir combien de temps vous souhaitez conserver les journaux, où ils doivent être stockés et si ClusterControl doit redémarrer le nœud pour que vous puissiez appliquer les modifications - la configuration des journaux binaires n'est pas dynamique et MariaDB doit être redémarrée pour appliquer ces modifications.
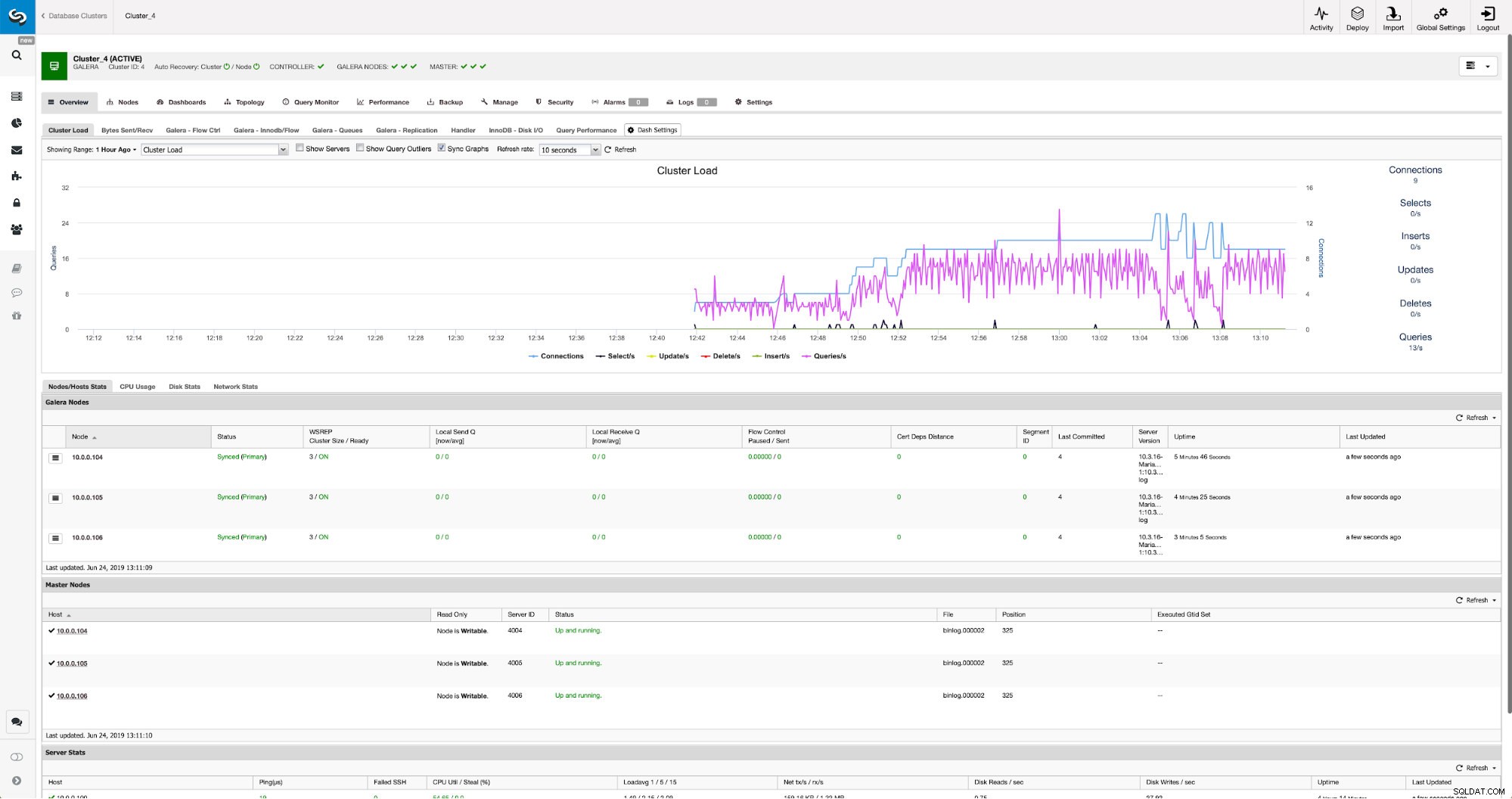
Lorsque les modifications seront terminées, vous verrez tous les nœuds marqués comme "maître", ce qui signifie que ces nœuds ont un journal binaire activé et peuvent agir en tant que maître.
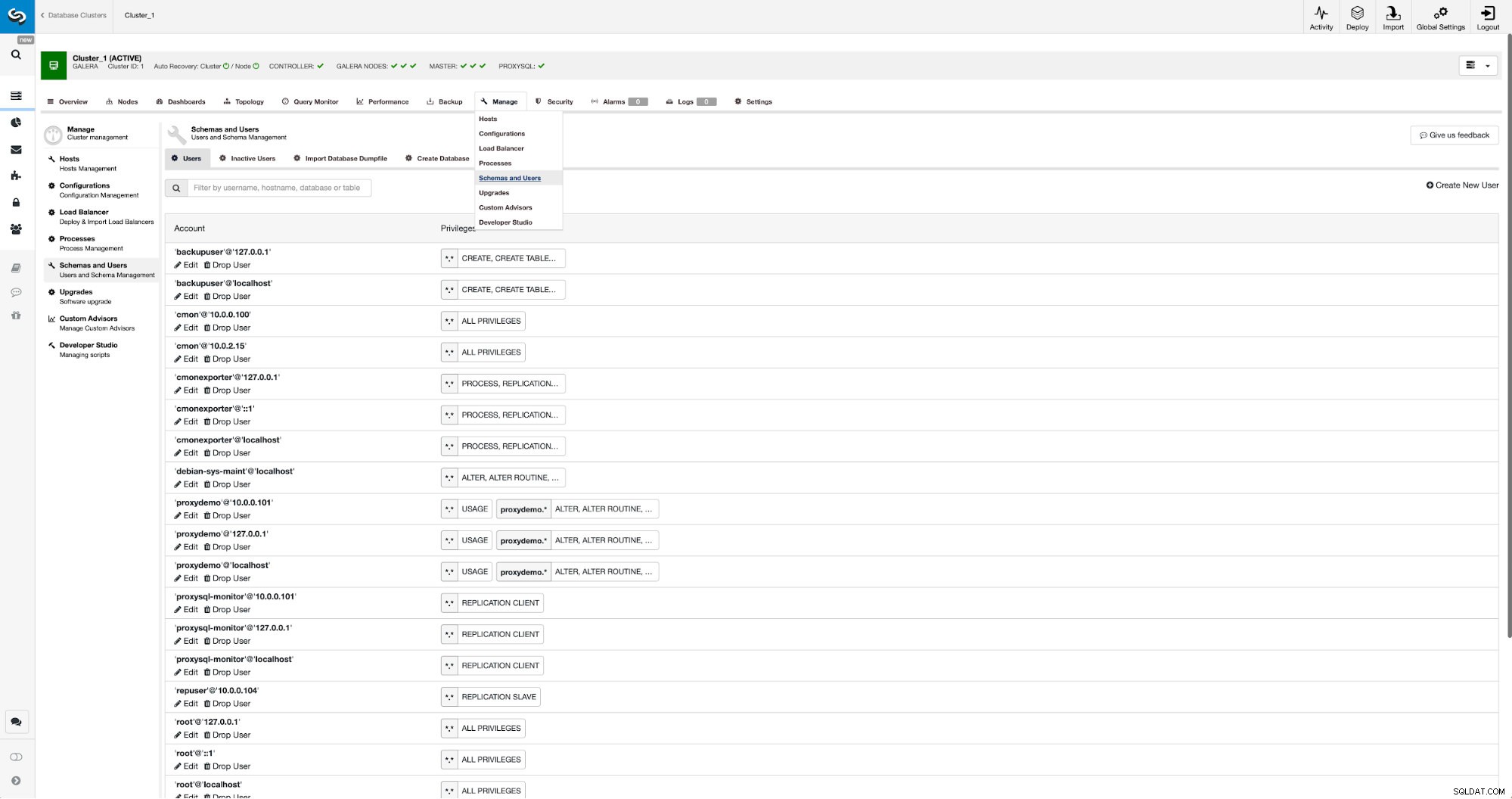
Si nous n'avons pas déjà créé d'utilisateur de réplication, nous devons le faire. Dans le premier cluster, nous devons aller dans Gérer -> Schémas et utilisateurs :
Sur le côté droit, nous avons une option pour créer un nouvel utilisateur :
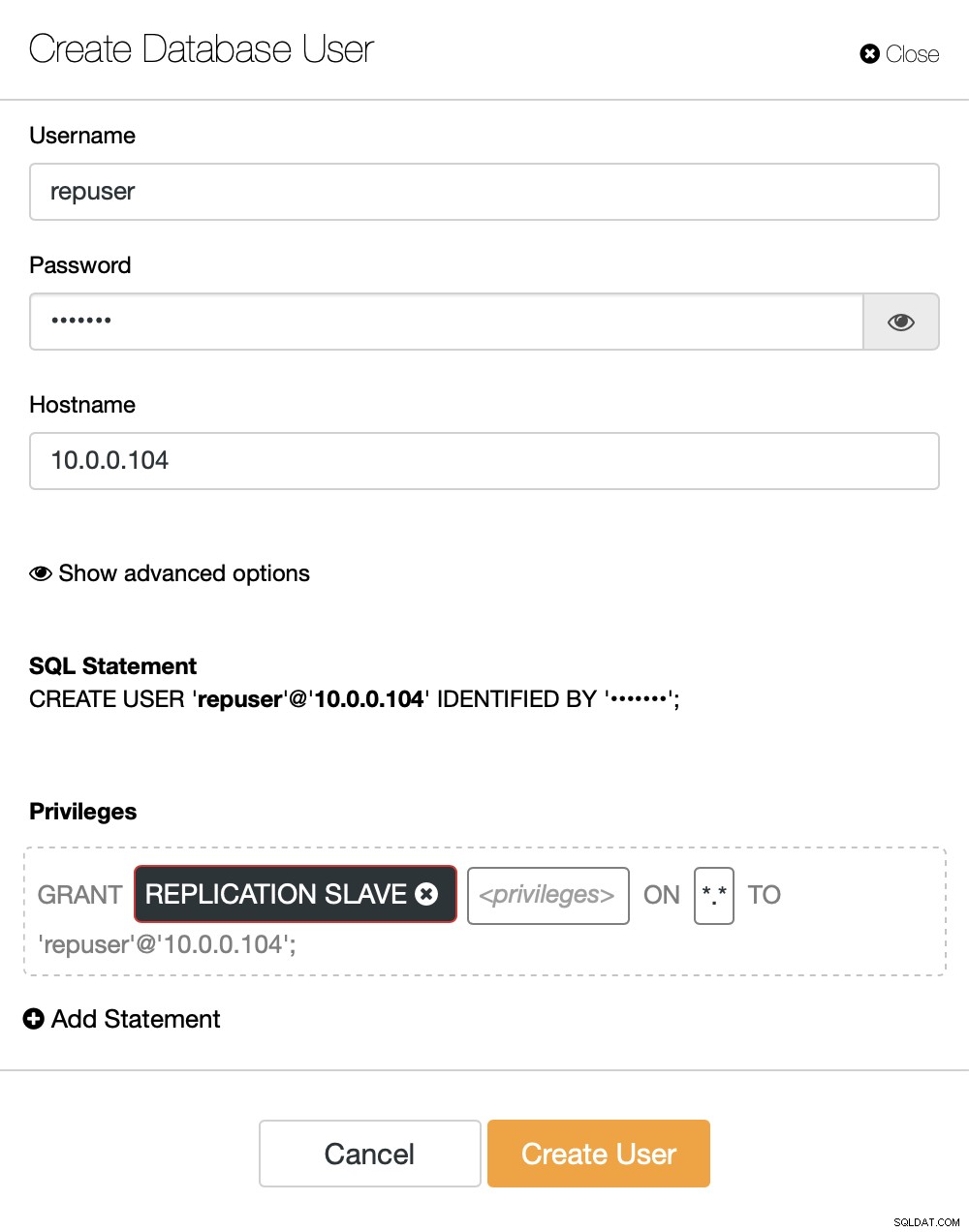
Ceci conclut la configuration requise pour configurer la réplication.
Configuration de la réplication entre les clusters à l'aide de ClusterControl
Comme nous l'avons dit, nous travaillons à l'automatisation de cette partie. Actuellement, il doit être fait manuellement. Comme vous vous en souvenez peut-être, nous avons besoin de la position GITD de notre sauvegarde, puis exécutons quelques commandes à l'aide de MySQL CLI. Les données GTID sont disponibles dans la sauvegarde. ClusterControl crée une sauvegarde à l'aide de xbstream/mbstream et la compresse ensuite. Notre sauvegarde est stockée sur l'hôte ClusterControl où nous n'avons pas accès au binaire mbstream. Vous pouvez essayer de l'installer ou vous pouvez copier le fichier de sauvegarde à l'emplacement où ce binaire est disponible :
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Une fois cela fait, le 10.0.0.104 nous voulons vérifier le contenu du fichier xtrabackup_info :
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Enfin, nous configurons la réplication et la démarrons :
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Ça y est - nous venons de configurer la réplication asynchrone entre deux clusters MariaDB Galera à l'aide de ClusterControl. Comme vous avez pu le voir, ClusterControl a pu automatiser la majorité des étapes que nous avons dû suivre pour mettre en place cet environnement.