L'exécution de sauvegardes régulières de votre cluster de bases de données est impérative pour la haute disponibilité et la reprise après sinistre. Si, pour une raison quelconque, vous perdiez l'intégralité de votre cluster et que vous deviez effectuer une restauration complète à partir d'une sauvegarde, vous auriez besoin d'une sauvegarde fiable et à jour pour commencer.
Meilleures pratiques pour les sauvegardes
Quelques recommandations à prendre en compte pour un bon régime de sauvegarde planifiée :
- Vous devriez être en mesure de récupérer complètement d'une panne catastrophique à partir d'au moins deux sauvegardes complètes précédentes. Juste au cas où la sauvegarde complète la plus récente serait endommagée, perdue ou corrompue,
- Votre sauvegarde doit contenir au moins une sauvegarde complète dans un cycle choisi, normalement hebdomadaire,
- Stocker les sauvegardes loin de l'emplacement actuel des données, de préférence hors site,
- Utilisez un mélange de mysqldump et Xtrabackup pour plus de sécurité, et ne vous fiez pas à une seule méthode,
- Testez régulièrement la restauration de vos sauvegardes, par ex. tous les deux mois.
Une sauvegarde complète hebdomadaire combinée à une sauvegarde incrémentielle quotidienne est normalement suffisante. Conserver un certain nombre de sauvegardes pendant un certain temps est toujours un bon plan, peut-être conserver chaque sauvegarde hebdomadaire pendant un mois. Cela vous permet de récupérer une base de données plus ancienne en cas d'urgence ou si, pour une raison quelconque, vous avez une corruption du fichier de sauvegarde local.
mysqldump ou Xtrabackup
mysqldump est très probablement le moyen le plus populaire de sauvegarder MySQL. Il effectue une sauvegarde logique des données, en lisant chaque table à l'aide d'instructions SQL, puis en exportant les données dans des fichiers texte. Restauration d'un mysqldump est aussi simple que de créer le fichier de vidage. Les principaux inconvénients sont qu'il est très lent pour les grandes bases de données, qu'il n'est pas "chaud" et qu'il efface le pool de mémoire tampon InnoDB.
Xtrabackup effectue des sauvegardes à chaud, ne verrouille pas la base de données pendant la sauvegarde et est généralement plus rapide. Les sauvegardes à chaud sont importantes pour la haute disponibilité, car elles s'exécutent sans bloquer l'application. C'est également un facteur important lorsqu'il est utilisé avec Galera, car Galera s'appuie sur la réplication synchrone. Cependant, la restauration d'une xtrabackup peut être un peu délicate en utilisant des méthodes manuelles.
ClusterControl prend en charge la planification de mysqldump et de Xtrabackup (complète et incrémentielle), ainsi que la restauration de la sauvegarde directement depuis l'interface utilisateur.
Restauration complète à partir de la sauvegarde
Dans cet article, nous allons vous montrer comment restaurer Xtrabackup (complète + incrémentielle) sur un cluster vide exécuté sur MariaDB Galera Cluster. Ces étapes devraient également fonctionner sur Percona XtraDB Cluster ou Galera Cluster for MySQL de Codership.
Dans notre cluster d'origine, nous avions une xtrabackup complète planifiée quotidiennement, avec des sauvegardes incrémentielles créées toutes les heures. Les sauvegardes sont stockées sur ClusterControl comme indiqué dans la capture d'écran suivante :
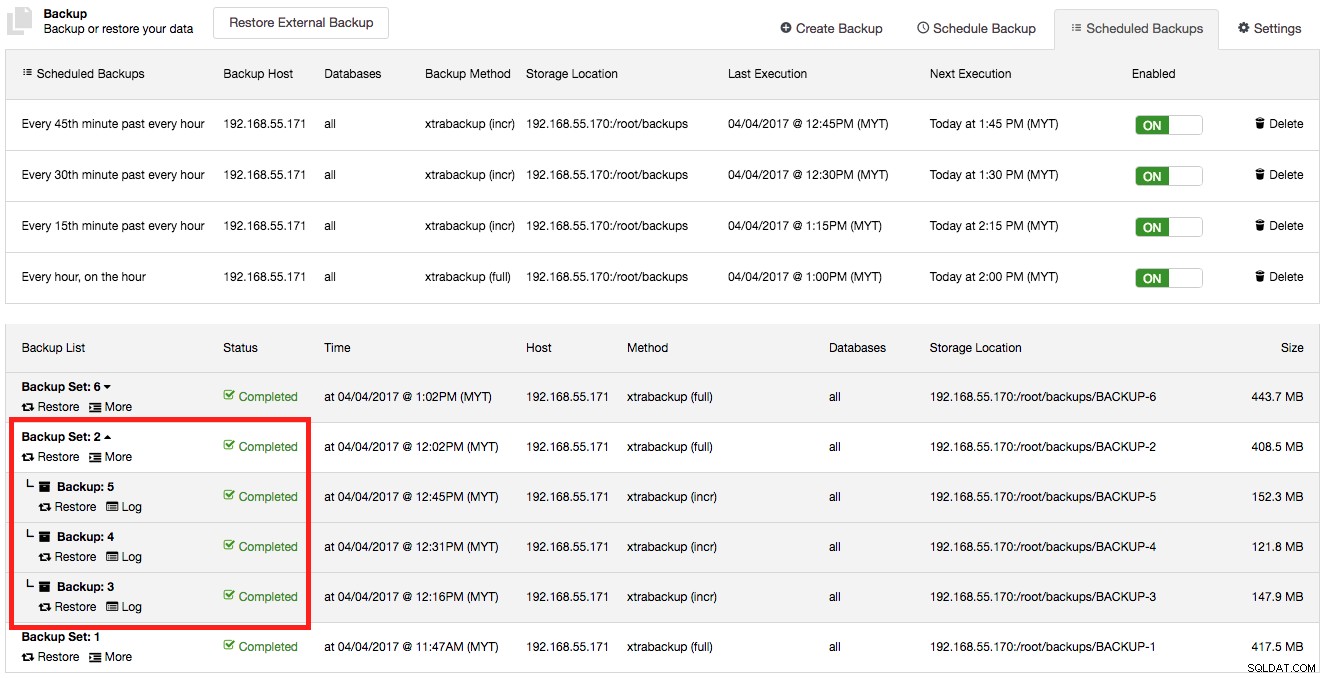
Supposons maintenant que nous ayons perdu notre cluster d'origine et que nous devions effectuer une restauration complète sur un nouveau cluster. Les étapes incluent :
- Configurer un nouveau serveur ClusterControl.
- Configurer un nouveau cluster MariaDB.
- Exportez les enregistrements et les fichiers de sauvegarde vers le nouveau serveur ClusterControl.
- Démarrez le processus de restauration.
- Démarrez les nœuds restants.
Le schéma suivant illustre notre architecture pour cet exercice :
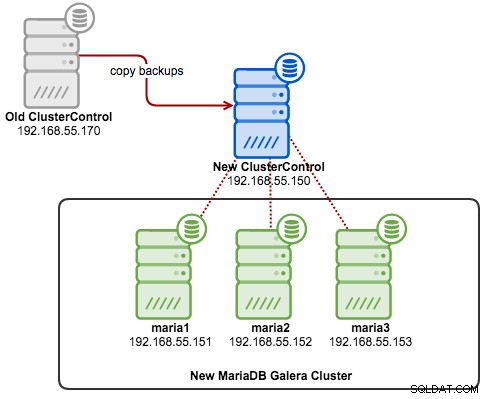
Étape 1 : Configurer un nouveau cluster MariaDB
Installez ClusterControl et déployez un nouveau cluster MariaDB. Allez dans ClusterControl -> Deploy -> Deploy Database Cluster -> MySQL Galera et spécifiez les informations requises dans la boîte de dialogue de déploiement :
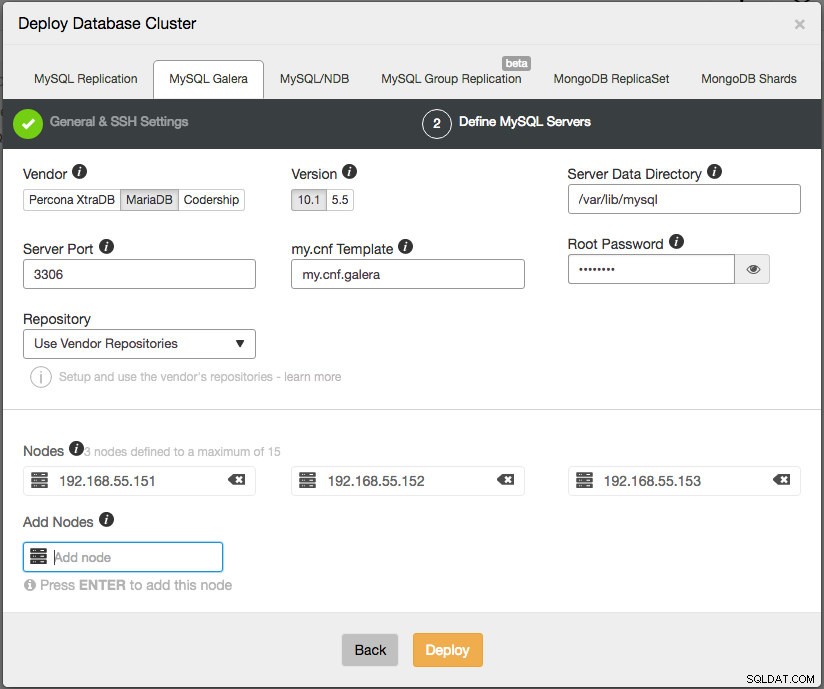
Cliquez sur le bouton Déployer et lancez le déploiement. Étant donné que nous n'avons qu'un cluster sur l'ancien serveur, l'ID de cluster doit donc être identique (ID de cluster :1) dans cette nouvelle instance.
Étape 2 - Exporter et importer les fichiers de sauvegarde Une fois le cluster déployé, nous devrons importer les sauvegardes de l'ancien serveur ClusterControl dans le nouveau. Tout d'abord, exportez le contenu de cmon.backup_records vers les fichiers de vidage. Étant donné que l'ancien ID de cluster et le nouveau sont identiques, il suffit de modifier le fichier de vidage avec la nouvelle adresse IP et de l'importer dans le nouveau nœud ClusterControl. Si l'ID de cluster est différent, vous devez modifier la valeur "cid" en conséquence dans les fichiers de vidage avant d'importer dans la base de données CMON sur le nouveau nœud. De plus, il est plus facile de conserver l'emplacement de stockage de sauvegarde comme dans l'ancien serveur afin que le nouveau ClusterControl puisse localiser les fichiers de sauvegarde dans le nouveau serveur.Sur l'ancien serveur ClusterControl, exportez la table backup_records dans des fichiers de vidage :
$ mysqldump -uroot -p --single-transaction --no-create-info cmon backup_records > backup_records.sqlEnsuite, effectuez une copie à distance des fichiers de sauvegarde de l'ancien serveur vers le nouveau serveur ClusterControl :
$ scp -r /root/backups 192.168.55.150:/root/
$ scp ~/backup_records.sql 192.168.55.150:~Ensuite, modifiez les fichiers de vidage pour refléter la nouvelle adresse IP du serveur ClusterControl. N'oubliez pas d'échapper le point dans l'adresse IP :
$ sed -i "s/192\.168\.55\.170/192\.168\.55\.150/g" backup_records.sqlSur le nouveau serveur ClusterControl, importez les fichiers de vidage :
$ mysql -uroot -p cmon < backup_records.sqlVérifiez que la liste de sauvegarde est correcte dans le nouveau serveur ClusterControl :
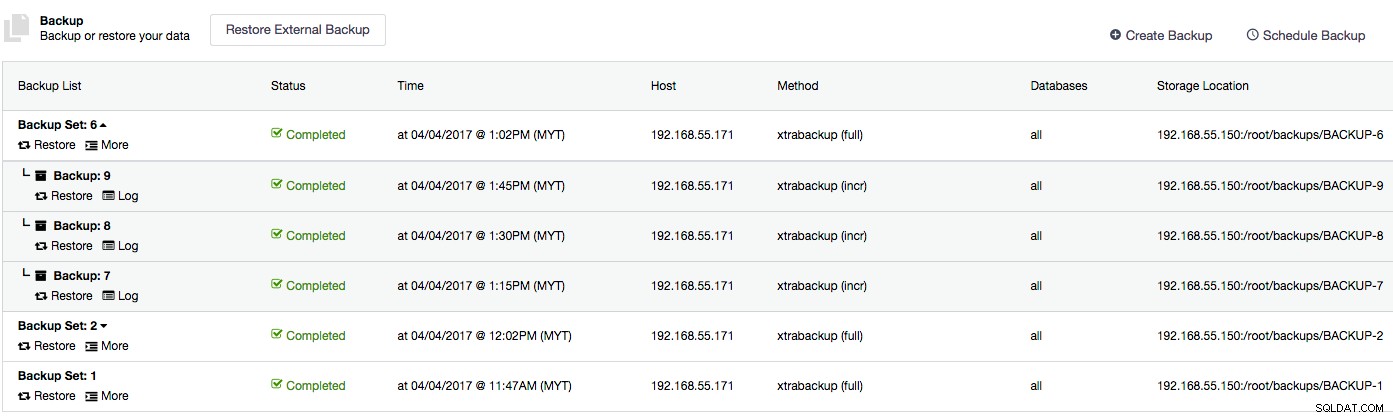
Comme vous pouvez le voir, toutes les occurrences de l'ancienne adresse IP (192.168.55.170) ont été remplacées par la nouvelle adresse IP (192.168.55.150). Nous sommes maintenant prêts à effectuer la restauration sur le nouveau serveur.
Étape 3 - Effectuer la restauration
La restauration via l'interface utilisateur de ClusterControl est une simple étape pointer-cliquer. Choisissez la sauvegarde à restaurer et cliquez sur le bouton "Restaurer". Nous allons restaurer la dernière sauvegarde incrémentale disponible (Backup :9). Cliquez sur le bouton "Restaurer" juste en dessous du nom de la sauvegarde et la boîte de dialogue de pré-restauration suivante s'affichera :
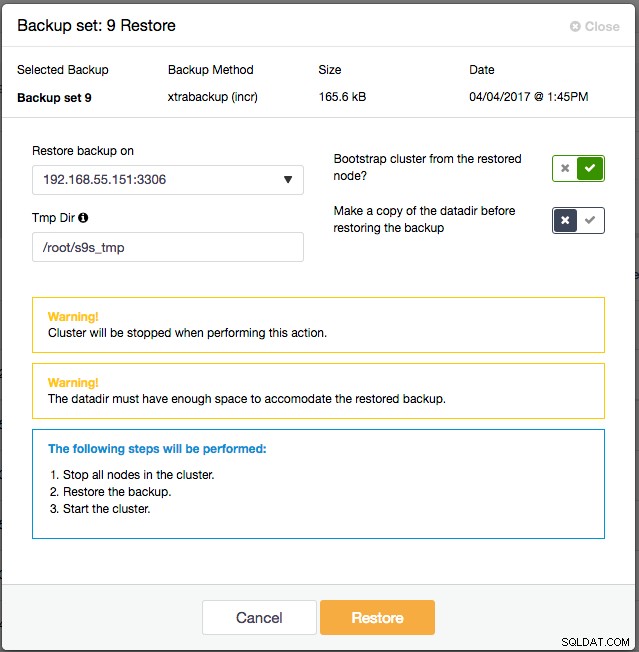
Il semble que la taille de la sauvegarde soit assez petite (165,6 ko). Cela n'a pas vraiment d'importance car ClusterControl préparera toutes les sauvegardes incrémentielles regroupées sous le jeu de sauvegarde 6, qui contient le Xtrabackup complet. Vous disposez également de plusieurs options post-restauration :
- Restaurer la sauvegarde sur :choisissez le nœud sur lequel restaurer la sauvegarde.
- Tmp Dir - Le répertoire sera utilisé sur le serveur ClusterControl local comme stockage temporaire pendant la préparation de la sauvegarde. Il doit être aussi grand que le répertoire de données MySQL estimé.
- Amorcer le cluster à partir du nœud restauré :puisqu'il s'agit d'un nouveau cluster, nous allons activer cette option afin que ClusterControl amorce automatiquement le cluster une fois la restauration réussie.
- Faites une copie du répertoire de données avant de restaurer la sauvegarde - Si les données restaurées sont corrompues ou non comme prévu, vous aurez une sauvegarde du répertoire de données MySQL précédent. Comme il s'agit d'un nouveau cluster, nous allons ignorer celui-ci.
La restauration de Percona Xtrabackup entraînera l'arrêt du cluster. ClusterControl :
- Arrêtez tous les nœuds du cluster.
- Restaurer la sauvegarde sur le nœud sélectionné.
- Amorcer le nœud sélectionné.
Pour voir la progression de la restauration, allez dans Activité -> Tâches -> Restaurer la sauvegarde et cliquez sur le bouton "Détails complets de la tâche". Vous devriez voir quelque chose comme ceci :
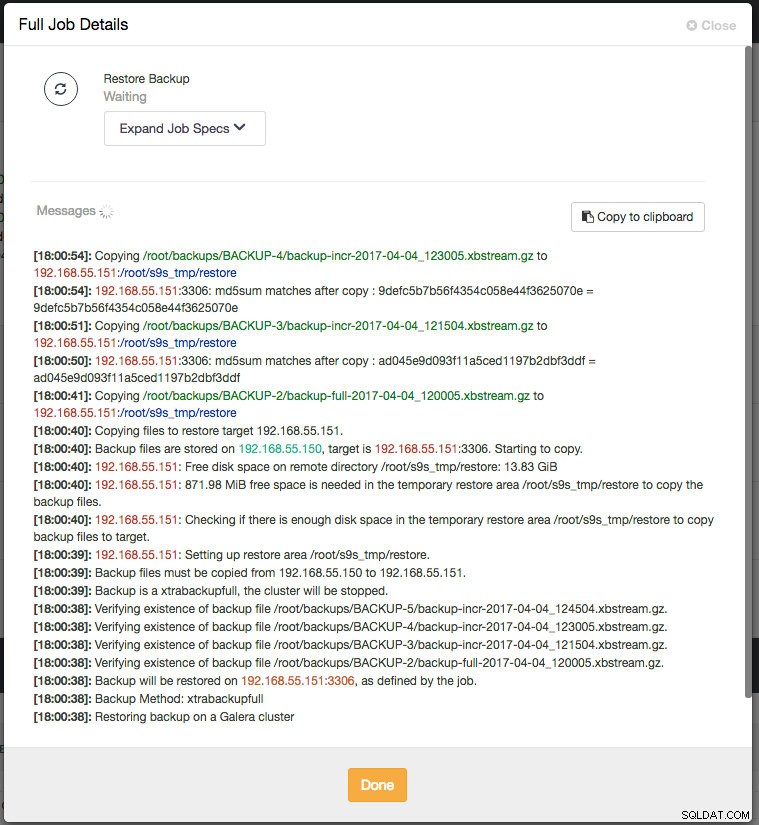
Une chose importante que vous devez faire est de surveiller la sortie du journal des erreurs MySQL sur le nœud cible (192.168.55.151) pendant le processus de restauration. Une fois la restauration terminée et pendant le processus d'amorçage, vous devriez voir les lignes suivantes commencer à apparaître :
Version: '10.1.22-MariaDB' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Server
2017-04-07 18:03:51 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)
2017-04-07 18:03:51 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)
2017-04-07 18:03:51 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)
2017-04-07 18:03:52 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)
2017-04-07 18:03:53 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)
2017-04-07 18:03:54 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)
2017-04-07 18:03:55 140608191986432 [Warning] Access denied for user 'cmon'@'192.168.55.150' (using password: YES)Ne pas paniquer. Il s'agit d'un comportement attendu car ce jeu de sauvegarde ne stocke pas les informations d'identification de connexion cmon du nouveau mot de passe cmon ClusterControl. Il a restauré/remplacé l'ancien utilisateur cmon à la place. Ce que vous devez faire est de réattribuer l'utilisateur cmon au serveur en exécutant l'instruction suivante sur ce nœud de base de données :
GRANT ALL PRIVILEGES ON *.* to example@sqldat.com'192.168.55.150' IDENTIFIED BY 'mynewCMONpassw0rd' WITH GRANT OPTION;
FLUSH PRIVILEGES;ClusterControl serait alors en mesure de se connecter au nœud amorcé et de déterminer l'état du nœud et de la sauvegarde. Si tout est OK, vous devriez voir quelque chose comme ceci :
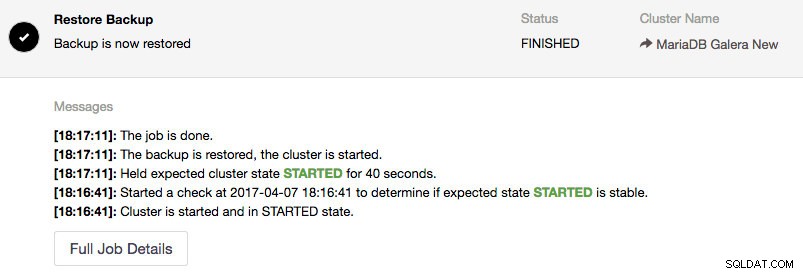
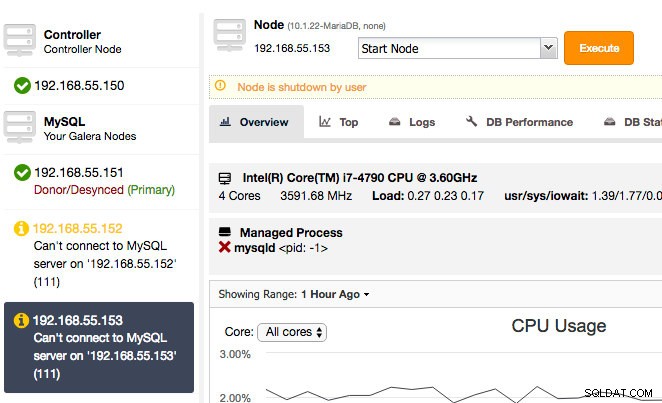
À ce stade, le nœud cible est amorcé et en cours d'exécution. Nous pouvons démarrer les nœuds restants sous Nœuds -> choisir le nœud -> Démarrer le nœud et cocher la case "Effectuer un démarrage initial" :
La restauration est maintenant terminée et vous pouvez vous attendre à ce que Performance -> DB Growth signale la taille mise à jour de notre ensemble de données nouvellement restauré :
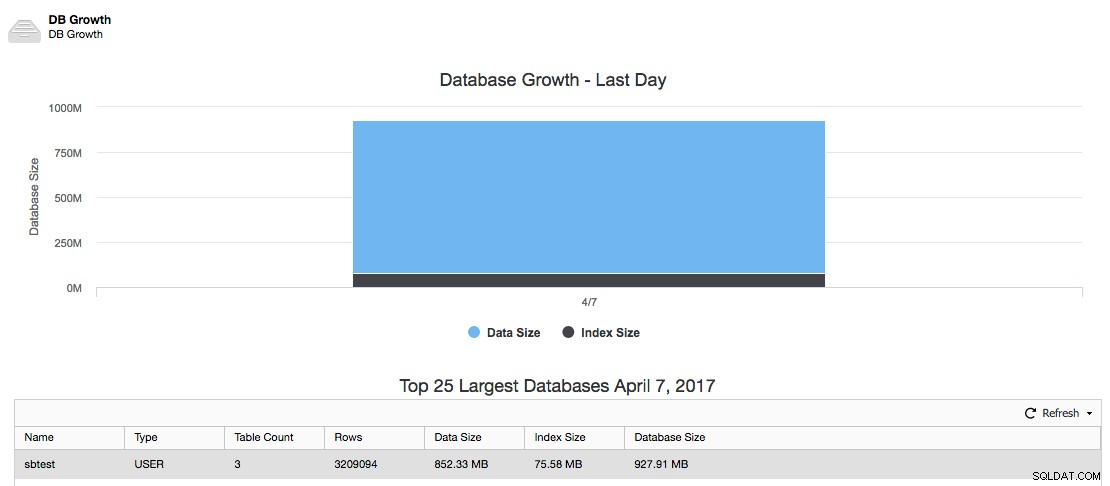
Bonne restauration !