Le meilleur scénario est qu'en cas de défaillance de la base de données, vous disposez d'un bon plan de reprise après sinistre (DRP) et d'un environnement hautement disponible avec un processus de basculement automatique, mais… que se passe-t-il en cas d'échec pour une raison inattendue? Que faire si vous devez effectuer un basculement manuel ? Dans ce blog, nous partagerons quelques recommandations à suivre au cas où vous auriez besoin de basculer votre base de données.
Vérifications
Avant d'effectuer toute modification, vous devez vérifier certaines choses de base pour éviter de nouveaux problèmes après le processus de basculement.
Statut de réplication
Il est possible qu'au moment de la panne, le nœud esclave ne soit pas à jour, en raison d'une panne de réseau, d'une charge élevée ou d'un autre problème, vous devez donc vous assurer que votre slave a toutes (ou presque toutes) les informations. Si vous avez plusieurs nœuds esclaves, vous devez également vérifier lequel est le nœud le plus avancé et le choisir pour le basculement.
par exemple :vérifions l'état de la réplication dans un serveur MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Dans le cas de PostgreSQL, c'est un peu différent car vous devez vérifier le statut des WAL et comparer ceux appliqués à ceux récupérés.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Identifiants
Avant d'exécuter le basculement, vous devez vérifier si votre application/vos utilisateurs pourront accéder à votre nouveau maître avec les informations d'identification actuelles. Si vous ne répliquez pas les utilisateurs de votre base de données, les informations d'identification ont peut-être été modifiées. Vous devrez donc les mettre à jour dans les nœuds esclaves avant toute modification.
par exemple :vous pouvez interroger la table des utilisateurs dans la base de données mysql pour vérifier les informations d'identification de l'utilisateur dans un serveur MariaDB/MySQL :
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)Dans le cas de PostgreSQL, vous pouvez utiliser la commande '\du' pour connaître les rôles, et vous devez également vérifier le fichier de configuration pg_hba.conf pour gérer l'accès utilisateur (pas les informations d'identification). Donc :
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}Et pg_hba.conf :
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustAccès réseau/pare-feu
Les informations d'identification ne sont pas le seul problème possible pour accéder à votre nouveau maître. Si le nœud se trouve dans un autre centre de données, ou si vous avez un pare-feu local pour filtrer le trafic, vous devez vérifier si vous êtes autorisé à y accéder ou même si vous avez la route réseau pour atteindre le nouveau nœud maître.
par exemple :iptables. Autorisons le trafic depuis le réseau 167.124.57.0/24 et vérifions les règles actuelles après l'avoir ajouté :
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationex :routes. Supposons que votre nouveau nœud maître est dans le réseau 10.0.0.0/24, votre serveur d'application est en 192.168.100.0/24, et vous pouvez atteindre le réseau distant en utilisant 192.168.100.100, donc dans votre serveur d'application, ajoutez la route correspondante :
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Points d'action
Après avoir vérifié tous les points mentionnés, vous devriez être prêt à effectuer les actions pour basculer votre base de données.
Nouvelle adresse IP
Comme vous allez promouvoir un nœud esclave, l'adresse IP maître changera, vous devrez donc la changer dans votre application ou votre accès client.
L'utilisation d'un équilibreur de charge est un excellent moyen d'éviter ce problème/changement. Après le processus de basculement, l'équilibreur de charge détectera l'ancien maître comme étant hors ligne et (selon la configuration) enverra le trafic au nouveau pour qu'il y écrive, vous n'avez donc rien à changer dans votre application.
ex :Voyons un exemple pour une configuration HAProxy :
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkDans ce cas, si un nœud est en panne, HAProxy n'y enverra pas de trafic et n'enverra le trafic qu'au nœud disponible.
Reconfigurer les nœuds esclaves
Si vous avez plus d'un nœud esclave, après avoir promu l'un d'entre eux, vous devez reconfigurer le reste des esclaves pour se connecter au nouveau maître. Cette tâche peut prendre du temps, selon le nombre de nœuds.
Vérifier et configurer les sauvegardes
Une fois que vous avez tout en place (nouveau maître promu, esclaves reconfigurés, application écrivant dans le nouveau maître), il est important de prendre les mesures nécessaires pour éviter un nouveau problème, les sauvegardes sont donc indispensables dans cette étape. Vous aviez très probablement une politique de sauvegarde en cours d'exécution avant l'incident (sinon, vous devez l'avoir à coup sûr), vous devez donc vérifier si les sauvegardes sont toujours en cours d'exécution ou si elles le feront dans la nouvelle topologie. Il est possible que les sauvegardes s'exécutent sur l'ancien maître ou utilisent le nœud esclave qui est maître maintenant, vous devez donc le vérifier pour vous assurer que votre politique de sauvegarde fonctionnera toujours après les modifications.
Surveillance de la base de données
Lorsque vous effectuez un processus de basculement, la surveillance est indispensable avant, pendant et après le processus. Grâce à cela, vous pouvez prévenir un problème avant qu'il ne s'aggrave, détecter un problème inattendu lors du basculement ou même savoir si quelque chose ne va pas après. Par exemple, vous devez surveiller si votre application peut accéder à votre nouveau maître en vérifiant le nombre de connexions actives.
Métriques clés à surveiller
Voyons quelques-unes des mesures les plus importantes à prendre en compte :
- Délai de réplication
- Statut de réplication
- Nombre de connexions
- Utilisation du réseau/erreurs
- Charge du serveur (CPU, Mémoire, Disque)
- Journaux de la base de données et du système
Restauration
Bien sûr, en cas de problème, vous devez pouvoir revenir en arrière. Bloquer le trafic vers l'ancien nœud et le garder aussi isolé que possible pourrait être une bonne stratégie pour cela, donc au cas où vous auriez besoin de revenir en arrière, vous aurez l'ancien nœud disponible. Si la restauration est après quelques minutes, en fonction du trafic, vous devrez probablement insérer les données de ces minutes dans l'ancien maître, alors assurez-vous d'avoir également votre nœud maître temporaire disponible et isolé pour prendre ces informations et les appliquer en retour .
Automatiser le processus de basculement avec ClusterControl
En voyant toutes ces tâches nécessaires pour effectuer un basculement, vous souhaitez probablement l'automatiser et éviter tout ce travail manuel. Pour cela, vous pouvez profiter de certaines des fonctionnalités que ClusterControl peut vous offrir pour différentes technologies de base de données, comme la récupération automatique, les sauvegardes, la gestion des utilisateurs, la surveillance, entre autres fonctionnalités, toutes à partir du même système.
Avec ClusterControl, vous pouvez vérifier l'état de la réplication et son décalage, créer ou modifier les informations d'identification, connaître l'état du réseau et de l'hôte, et encore plus de vérifications.
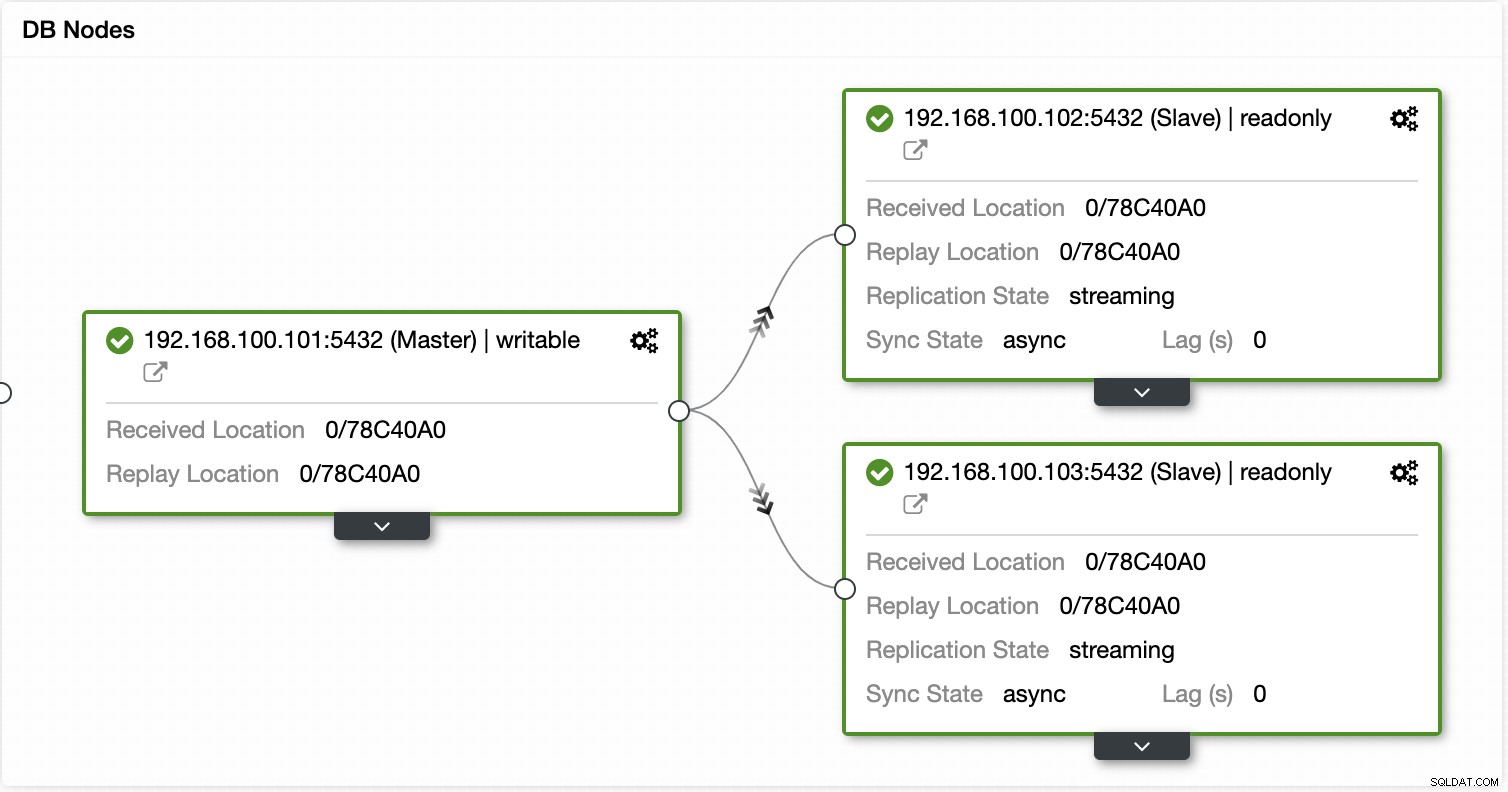
En utilisant ClusterControl, vous pouvez également effectuer différentes actions de cluster et de nœud, comme promouvoir l'esclave , redémarrez la base de données et le serveur, ajoutez ou supprimez des nœuds de base de données, ajoutez ou supprimez des nœuds d'équilibrage de charge, reconstruisez un esclave de réplication, etc.
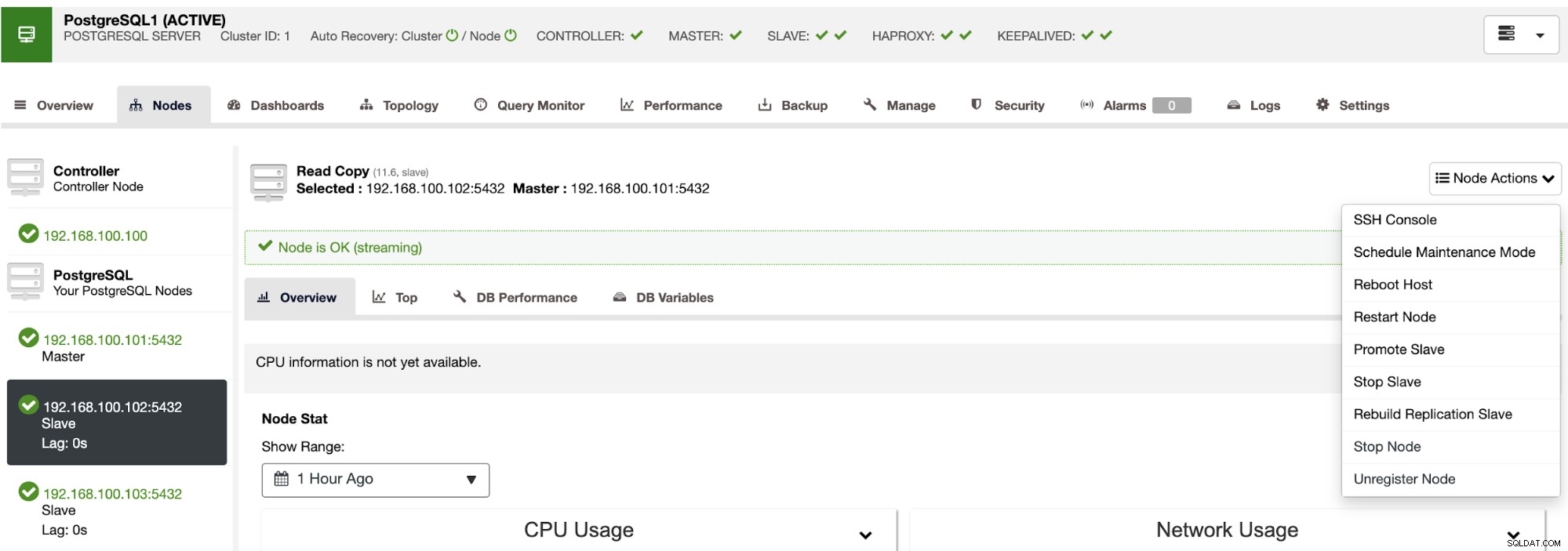
À l'aide de ces actions, vous pouvez également annuler votre basculement si nécessaire en reconstruisant et en promouvant le maître précédent.
ClusterControl dispose de services de surveillance et d'alerte qui vous aident à savoir ce qui se passe ou même si quelque chose s'est passé auparavant.
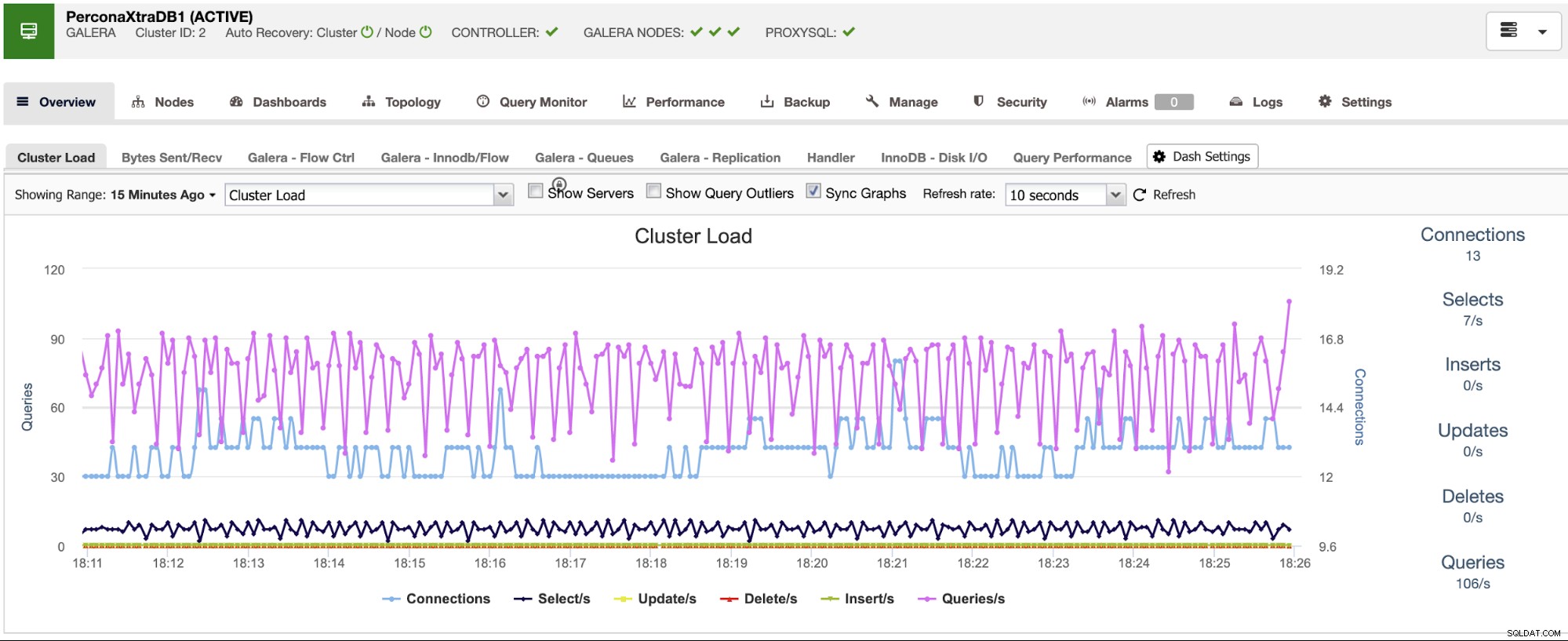
Vous pouvez également utiliser la section tableau de bord pour avoir une vue plus conviviale sur l'état de vos systèmes.
Conclusion
En cas de défaillance de la base de données principale, vous souhaiterez avoir toutes les informations en place pour prendre les mesures nécessaires dès que possible. Avoir un bon DRP est la clé pour que votre système fonctionne tout le temps (ou presque). Ce DRP doit inclure un processus de basculement bien documenté pour avoir un RTO (objectif de temps de récupération) acceptable pour l'entreprise.