Dans cet article, nous discuterons des erreurs typiques auxquelles les développeurs débutants peuvent être confrontés lors de la conception de code T-SQL. En outre, nous examinerons les meilleures pratiques et quelques conseils utiles qui peuvent vous aider lorsque vous travaillez avec SQL Server, ainsi que des solutions de contournement pour améliorer les performances.
Contenu :
1. Types de données
2. *
3. Alias
4. Ordre des colonnes
5. NOT IN vs NULL
6. Format de date
7. Filtre de date
8. Calcul
9. Convertir implicite
10. LIKE &Index supprimé
11. Unicode contre ANSI
12. ASSEMBLAGE
13. ASSEMBLAGE BINAIRE
14. Style de code
15. [var]char
16. Longueur des données
17. ISNULL contre COALESCE
18. Mathématiques
19. UNION vs UNION TOUS
20. Relisez
21. Sous-requête
22. CAS QUAND
23. Fonction scalaire
24. VUES
25. CURSEURS
26. STRING_CONCAT
27. Injection SQL
Types de données
Le principal problème auquel nous sommes confrontés lorsque nous travaillons avec SQL Server est un choix incorrect de types de données.
Supposons que nous ayons deux tables identiques :
DECLARE @Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , BirthDate VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABLE ( EmployeeID INT PRIMARY KEY , IsMale BIT , BirthDate DATE)INSERT INTO @Employees2VALUES (123, 1, '2012-09-01')
Exécutons une requête pour vérifier quelle est la différence :
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
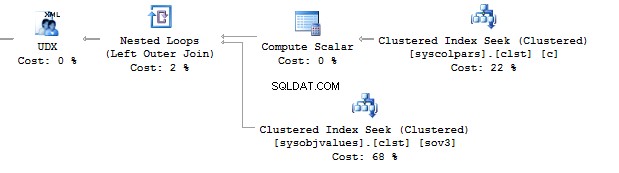
Dans le premier cas, les types de données sont plus redondants qu'ils ne pourraient l'être. Pourquoi devrions-nous stocker une valeur de bit comme OUI/NON rangée? Pourquoi devrions-nous stocker une date sous forme de ligne ? Pourquoi devrions-nous utiliser BIGINT pour les employés dans le tableau, plutôt que INT ?
Cela entraîne les inconvénients suivants :
- Les tableaux peuvent occuper beaucoup d'espace sur le disque ;
- Nous devons lire plus de pages et mettre plus de données dans BufferPool pour gérer les données.
- Performances médiocres.
*
J'ai été confronté à la situation où les développeurs récupèrent toutes les données d'une table, puis côté client, utilisent DataReader pour sélectionner uniquement les champs obligatoires. Je ne recommande pas d'utiliser cette approche :
USE AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Il y aura une différence significative dans le temps d'exécution de la requête. De plus, l'index de couverture peut réduire un certain nombre de lectures logiques.
Table 'Personne'. Nombre d'analyses 1, lectures logiques 3819, lectures physiques 3, ... Temps d'exécution SQL Server :temps CPU =31 ms, temps écoulé =1235 ms.Table 'Person'. Nombre d'analyses 1, lectures logiques 109, lectures physiques 1, ... Temps d'exécution de SQL Server :temps CPU =0 ms, temps écoulé =227 ms.
Alias
Créons un tableau :
UTILISER AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') N'EST PAS NULL DROP TABLE Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency ( CurrencyCode NCHAR(3) PRIMARY KEY)INSERT INTO Sales.UserCurrencyVALUES ('USD') Supposons que nous ayons une requête qui renvoie le nombre de lignes identiques dans les deux tables :
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN (SELECT CurrencyCode FROM Sales.UserCurrency)
Tout fonctionnera comme prévu, jusqu'à ce que quelqu'un renomme une colonne dans Sales.UserCurrency tableau :
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLONNE'
Ensuite, nous allons exécuter une requête et voir que nous obtenons toutes les lignes dans Sales.Currency tableau, au lieu d'une ligne. Lors de la construction d'un plan d'exécution, lors de l'étape de liaison, SQL Server vérifierait les colonnes de Sales.UserCurrency, il ne trouvera pas CurrencyCode là et décide que cette colonne appartient à la Sales.Currency table. Après cela, un optimiseur supprimera le CurrencyCode =CurrencyCode état.
Ainsi, je recommande d'utiliser des alias :
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
Ordre des colonnes
Supposons que nous ayons une table :
IF OBJECT_ID('dbo.DatePeriod') N'EST PAS NULL DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE) Nous y insérons toujours des données en fonction des informations sur l'ordre des colonnes.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Supposons que quelqu'un modifie l'ordre des colonnes :
CREATE TABLE dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Les données seront insérées dans un ordre différent. Dans ce cas, il est judicieux de spécifier explicitement les colonnes dans l'instruction INSERT :
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Voici un autre exemple :
SELECT TOP(1) *FROM dbo.DatePeriodORDER BY 2 DESC
Sur quelle colonne allons-nous ordonner les données ? Cela dépendra de l'ordre des colonnes dans une table. Dans le cas où l'on change l'ordre, nous obtenons des résultats erronés.
NOT IN vs NULL
Parlons du PAS DANS déclaration.
Par exemple, vous devez écrire quelques requêtes :renvoyer les enregistrements de la première table, qui n'existent pas dans la deuxième table et inversement. Habituellement, les développeurs juniors utilisent IN et PAS DANS :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1))INSERT INTO @t1 VALUES (1), (2)DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2))INSERT INTO @t2 VALUES (1 )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
La première requête a renvoyé 2, la seconde - 1. De plus, nous ajouterons une autre valeur dans la deuxième table - NULL :
INSÉRER DANS @t2 VALEURS (1), (NULL)
Lors de l'exécution de la requête avec NOT IN , nous n'obtiendrons aucun résultat. Pourquoi IN fonctionne et NOT In not ? La raison en est que SQL Server utilise TRUE , FAUX , et INCONNU logique lors de la comparaison des données.
Lors de l'exécution d'une requête, SQL Server interprète la condition IN de la manière suivante :
a IN (1, NULL) ==a=1 OR a=NULL
PAS DANS :
a NOT IN (1, NULL) ==a<>1 AND a<>NULL
Lors de la comparaison d'une valeur avec NULL, SQL Server renvoie UNKNOWN. Soit 1=NULL ou NULL=NULL – les deux aboutissent à INCONNU. Dans la mesure où nous avons ET dans l'expression, les deux côtés renvoient UNKNOWN.
Je précise que ce cas n'est pas rare. Par exemple, vous marquez une colonne comme NOT NULL. Au bout d'un moment, un autre développeur décide d'autoriser les NULLs pour cette colonne. Cela peut conduire à la situation où un rapport client cesse de fonctionner une fois qu'une valeur NULL est insérée dans la table.
Dans ce cas, je recommanderais d'exclure les valeurs NULL :
SELECT *FROM @t1WHERE t1 NOT IN ( SELECT t2 FROM @t2 WHERE t2 IS NOT NULL)
De plus, il est possible d'utiliser SAUF :
SELECT * FROM @t1EXCEPTSELECT * FROM @t2
Alternativement, vous pouvez utiliser NOT EXISTS :
SELECT *FROM @t1WHERE NOT EXISTS( SELECT 1 FROM @t2 WHERE t1 =t2 )
Quelle option est la plus préférable ? La dernière option avec N'EXISTE PAS semble être le plus productif car il génère le refoulement de prédicat le plus optimal opérateur pour accéder aux données de la seconde table.
En fait, les valeurs NULL peuvent renvoyer un résultat inattendu.
Considérez-le sur cet exemple particulier :
USE AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Couleur ='Gris'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Couleur <> 'Gris'
Comme vous pouvez le constater, vous n'avez pas obtenu le résultat attendu car les valeurs NULL ont des opérateurs de comparaison distincts :
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Voici un autre exemple avec CHECK contraintes :
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL DROP TABLE #tempGOCREATE TABLE #temp ( Color VARCHAR(15) --NULL , CONTRAINTE CK CHECK (Color IN ('Black', 'White') )) Nous créons un tableau avec la permission d'insérer uniquement des couleurs blanches et noires :
INSERT INTO #temp VALUES ('Black')(1 rangée(s) affectée(s)) Tout fonctionne comme prévu.
INSERT INTO #temp VALUES ('Red')L'instruction INSERT est en conflit avec la contrainte CHECK... L'instruction a été terminée. Maintenant, ajoutons NULL :
INSERT INTO #temp VALUES (NULL)(1 ligne(s) affectée(s))
Pourquoi la contrainte CHECK a passé la valeur NULL ? Eh bien, la raison en est qu'il y a assez de PAS FAUX condition de faire un enregistrement. La solution consiste à définir explicitement une colonne comme NOT NULL ou utilisez NULL dans la contrainte.
Format de date
Très souvent, vous pouvez avoir des difficultés avec les types de données.
Par exemple, vous devez obtenir la date actuelle. Pour cela, vous pouvez utiliser la fonction GETDATE :
SELECT GETDATE()
Ensuite, copiez simplement le résultat renvoyé dans une requête requise et supprimez l'heure :
SELECT *FROM sys.objectsWHERE create_date <'2016-11-14'
Est-ce exact ?
La date est spécifiée par une constante de chaîne :
SET LANGUAGE FrenchSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Toutes les valeurs ont une interprétation univoque :
----------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Cela ne causera aucun problème jusqu'à ce que la requête avec cette logique métier soit exécutée sur un autre serveur où les paramètres peuvent différer :
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-déc -2016'SELECT @d1, @d2, @d3, @d4
Cependant, ces options peuvent conduire à une interprétation incorrecte de la date :
----------- ----------- ----------- -----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
De plus, ce code peut conduire à la fois à un bogue visible et latent.
Prenons l'exemple suivant. Nous devons insérer des données dans une table de test. Sur un serveur de test tout fonctionne parfaitement :
DECLARE @t TABLE (a DATETIME)INSERT INTO @t VALUES ('05/13/2016') Néanmoins, côté client, cette requête aura des problèmes car nos paramètres de serveur diffèrent :
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT INTO @t VALUES ('05/13/2016') Msg 242, Niveau 16, État 3, Ligne 28La conversion d'un type de données varchar en un type de données datetime a entraîné une valeur hors plage.
Ainsi, quel format devons-nous utiliser pour déclarer les constantes de date ? Pour répondre à cette question, exécutez cette requête :
SET DATEFORMAT YMDSET LANGUAGE FrenchDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
L'interprétation des constantes peut différer selon le langage installé :
----------- ----------- ----------- -----------2016-01 -12 12/01/2016 12/01/2016 12/01/2016 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Ainsi, il est préférable d'utiliser les deux dernières options. De plus, je voudrais ajouter que spécifier explicitement la date n'est pas une bonne idée :
SET LANGUAGE FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Par conséquent, si vous souhaitez que les constantes avec les dates soient interprétées correctement, vous devez les spécifier au format suivant AAAAMMJJ.
De plus, j'aimerais attirer votre attention sur le comportement de certains types de données :
SET LANGUAGE FrenchSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
Contrairement à DATETIME, le DATE type est interprété correctement avec différents paramètres sur un serveur :
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Filtre de dates
Pour continuer, nous verrons comment filtrer efficacement les données. Commençons par eux DATETIME/DATE :
USE AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Maintenant, nous allons essayer de savoir combien de lignes la requête renvoie pour un jour donné :
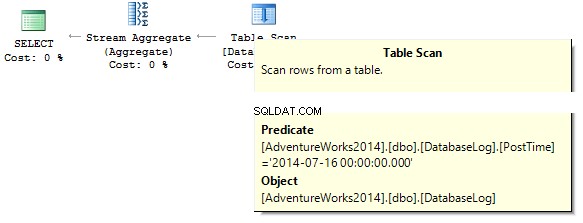
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
La requête renverra 0. Lors de la construction d'un plan d'exécution, le serveur SQL essaie de convertir une constante de chaîne en type de données de la colonne que nous devons filtrer :
Créer un index :
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)
Il existe des options correctes et incorrectes pour les données de sortie. Par exemple, vous devez supprimer la colonne de temps :
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Ou nous devons spécifier une plage :
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140716' AND PostTime <'20140717'
Compte tenu de l'optimisation, je peux dire que ces deux requêtes sont les plus correctes. Le fait est que toutes les conversions et tous les calculs de colonnes d'index qui sont filtrés peuvent réduire considérablement les performances et augmenter le temps de lecture logique :
Table 'DatabaseLog'. Scan count 1, lectures logiques 7, ...Table 'DatabaseLog'. Scan compte 1, lectures logiques 2, ...
L'heure de la poste champ n'avait pas été inclus dans l'index auparavant, et nous n'avons pu voir aucune efficacité dans l'utilisation de cette approche correcte dans le filtrage. Une autre chose est lorsque nous devons générer des données pour un mois :
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 AND DATEPART(MONTH, PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='20140731'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE Heure_poste>='20140701' ET Heure_poste <'20140801'
Encore une fois, cette dernière option est préférable :
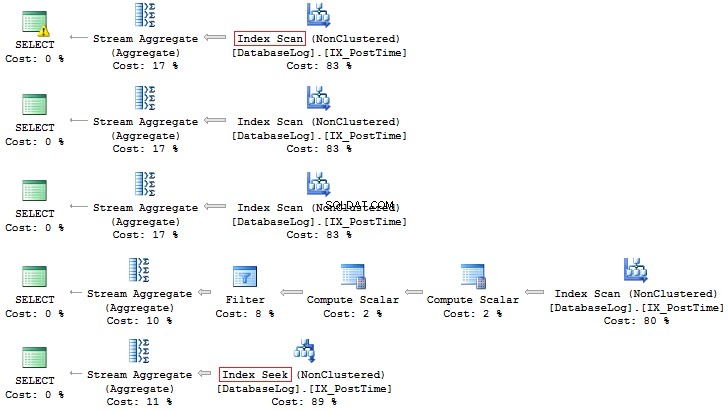
De plus, vous pouvez toujours créer un index basé sur un champ calculé :
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTEDGOCREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay) Par rapport à la requête précédente, la différence de lectures logiques peut être importante (s'il s'agit de grandes tables) :
SET STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE MonthLastDay ='20140731'SET STATISTICS IO OFFTable 'DatabaseLog'. Scan count 1, lectures logiques 7, ...Table 'DatabaseLog'. Scan count 1, lectures logiques 3, ...
Calcul
Comme cela a déjà été discuté, tout calcul sur les colonnes d'index diminue les performances et augmente le temps de lecture logique :
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =5000Table 'Person'. Scan count 1, lectures logiques 67, ...Table 'Person'. Scan count 0, lectures logiques 3, ...
Si nous regardons les plans d'exécution, alors dans le premier, SQL Server exécute IndexScan :
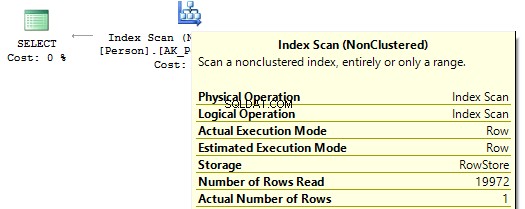
Ensuite, lorsqu'il n'y a pas de calculs sur les colonnes d'index, nous verrons IndexSeek :

Convertir implicite
Examinons ces deux requêtes qui filtrent par la même valeur :
USE AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Les plans d'exécution fournissent les informations suivantes :
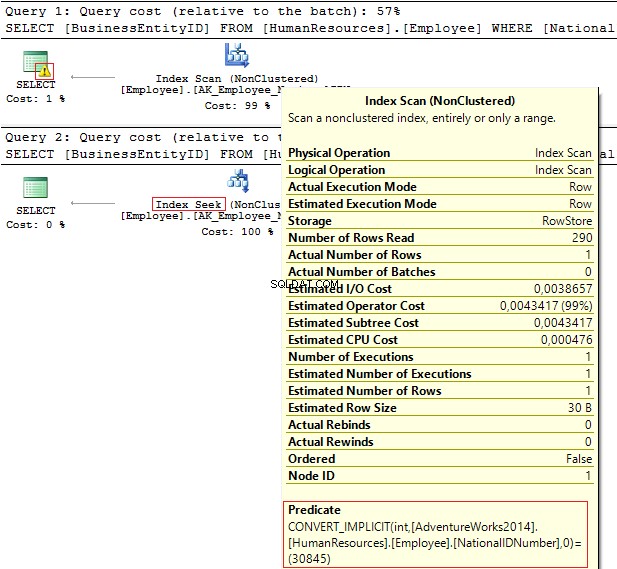
- Avertissement et IndexScan sur le premier plan
- IndexSeek – sur le second.
Table 'Employé'. Nombre de scans 1, lectures logiques 4, ... Table 'Employé'. Scan count 0, lectures logiques 2, ...
Le numéro d'identification national colonne a le NVARCHAR(15) Type de données. La constante que nous utilisons pour filtrer les données est définie sur INT ce qui nous amène à une conversion implicite de type de données. À son tour, cela peut diminuer les performances. Vous pouvez le surveiller lorsque quelqu'un modifie le type de données dans la colonne, cependant, les requêtes ne sont pas modifiées.
Il est important de comprendre qu'une conversion de type de données implicite peut entraîner des erreurs lors de l'exécution. Par exemple, avant que le champ PostalCode ne soit numérique, il s'est avéré qu'un code postal pouvait contenir des lettres. Ainsi, le type de données a été mis à jour. Néanmoins, si nous insérons un code postal alphabétique, l'ancienne requête ne fonctionnera plus :
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
Un autre exemple est lorsque vous devez utiliser EntityFramework sur le projet, qui interprète par défaut tous les champs de ligne comme Unicode :
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Par conséquent, des requêtes incorrectes sont générées :

Pour résoudre ce problème, assurez-vous que les types de données correspondent.
LIKE et index supprimé
En fait, avoir un indice de couverture ne signifie pas que vous l'utiliserez efficacement.
Vérifions-le sur cet exemple particulier. Supposons que nous devions afficher toutes les lignes commençant par…
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3) ='100'SELECT AddressLine1FROM Person.[ Adresse]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Nous obtiendrons les lectures logiques et les plans d'exécution suivants :
Table 'Adresse'. Nombre de balayages 1, lectures logiques 216, ... Table 'Adresse'. Nombre de balayages 1, lectures logiques 216, ... Table 'Adresse'. Nombre de balayages 1, lectures logiques 216, ... Table 'Adresse'. Scan compte 1, lectures logiques 4, ...
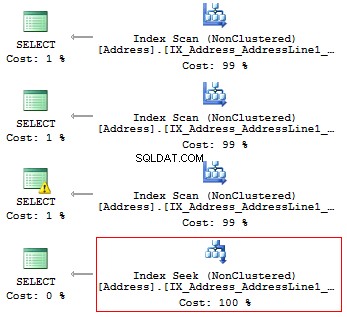
Ainsi, s'il existe un index, il ne doit contenir aucun calcul ou conversion de types, de fonctions, etc.
Mais que faites-vous si vous avez besoin de trouver l'occurrence d'une sous-chaîne dans une chaîne ?
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
Nous reviendrons sur cette question plus tard.
Unicode contre ANSI
Il est important de se rappeler qu'il existe des UNICODE et ANSI cordes. Le type UNICODE inclut NVARCHAR/NCHAR (2 octets pour un symbole). Pour stocker ANSI chaînes, il est possible d'utiliser VARCHAR/CHAR (1 octet pour 1 symbole). Il y a aussi TEXT/NTEXT , mais je ne recommande pas de les utiliser car ils peuvent diminuer les performances.
Si vous spécifiez une constante Unicode dans une requête, il est nécessaire de la faire précéder du symbole N. Pour le vérifier, exécutez la requête suivante :
SELECT '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI ou UNICODE
Si N ne précède pas la constante, SQL Server essaiera de trouver un symbole approprié dans le codage ANSI. S'il ne trouve pas, il affichera un point d'interrogation.
COLLER
Très souvent, lors d'un entretien pour le poste de développeur de base de données intermédiaire/sénior, un intervieweur pose souvent la question suivante :cette requête renverra-t-elle les données ?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
Ça dépend. Premièrement, le symbole N ne précède pas une constante de chaîne, il sera donc interprété comme ANSI. Deuxièmement, beaucoup dépend de la valeur COLLATE actuelle, qui est un ensemble de règles, lors de la sélection et de la comparaison des données de chaîne.
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1 ) ='Ô'SELECT @a, @bWHERE @a =@b Cette instruction COLLATE renverra des points d'interrogation car leurs symboles sont égaux :
---- ---- ? ?
Si nous changeons l'instruction COLLATE pour une autre instruction :
Test ALTER DATABASE COLLATE Cyrillic_General_100_CI_AS
Dans ce cas, la requête ne renverra rien, car les caractères cyrilliques seront interprétés correctement.
Par conséquent, si une constante de chaîne prend UNICODE, il est nécessaire de définir N devant une constante de chaîne. Néanmoins, je ne recommanderais pas de le mettre partout pour les raisons que nous avons discutées ci-dessus.
Une autre question à poser lors de l'entretien fait référence à la comparaison des lignes.
Prenons l'exemple suivant :
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Ces lignes sont-elles égales ? Pour vérifier cela, nous devons spécifier explicitement COLLATE :
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Comme il existe des COLLATE sensibles à la casse (CS) et insensibles à la casse (CI) lors de la comparaison et de la sélection de lignes, nous ne pouvons pas dire avec certitude s'ils sont égaux. De plus, il existe différents COLLATE à la fois côté serveur de test et côté client.
Il y a un cas où COLLATEs d'une base cible et tempdb ne correspondent pas.
Créez une base de données avec COLLATE :
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Albanais_100_CS_ASGOUSE testGOCREATE TABLE t (c CHAR(1))INSERT INTO t VALUES ('a ')GOIF OBJECT_ID('tempdb.dbo.#t1') N'EST PAS NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') N'EST PAS NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') N'EST PAS NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t Lors de la création d'une table, elle hérite de COLLATE d'une base de données. La seule différence pour la première table temporaire, pour laquelle nous déterminons explicitement une structure sans COLLATE, est qu'elle hérite de COLLATE de la tempdb base de données.
------ --------------------------tempdb Cyrillic_General_CI_AStest Albanais_100_CS_ASt Albanais_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Albanais_100_CS_AS#t3 Albanais_100_CS_AS@t Albanais_100_CS_AS
Je décrirai le cas où les COLLATE ne correspondent pas sur l'exemple particulier avec #t1.
Par exemple, les données ne sont pas filtrées correctement, car COLLATE peut ne pas prendre en compte un cas :
SELECT *FROM #t1WHERE c ='A'
Alternativement, nous pouvons avoir un conflit pour connecter des tables avec différents COLLATE :
SELECT *FROM #t1JOIN t ON [#t1].c =t.c
Tout semble fonctionner parfaitement sur un serveur de test, alors que sur un serveur client nous obtenons une erreur :
Msg 468, Niveau 16, État 9, Ligne 93Impossible de résoudre le conflit de classement entre "Albanian_100_CS_AS" et "Cyrillic_General_CI_AS" dans l'opération égale à.
Pour contourner ce problème, nous devons installer des hacks partout :
SELECT *FROM #t1JOIN t ON [#t1].c =t.c COLLATE database_default
ASSEMBLAGE BINAIRE
Nous allons maintenant découvrir comment utiliser COLLATE à votre avantage.
Prenons l'exemple avec l'occurrence d'une sous-chaîne dans une chaîne :
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
Il est possible d'optimiser cette requête et de réduire son temps d'exécution.
Dans un premier temps, nous devons générer un grand tableau :
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE test MODIFY FILE (NAME =N'test', SIZE =64MB)GOALTER Test DATABASE MODIFY FILE (NAME =N'test_log', SIZE =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( VALEURS (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b)INSERT INTO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Créez des colonnes calculées avec des COLLATE et des index binaires :
ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX ansi ON t (ansi)CREATE NONCLUSTERED INDEX unicod ON t (unicod)CREATE NONCLUSTERED INDEXt ans (i_bin2CREATE INDEX ansi_bin)CRÉER UN INDEX NON CLUSTÉRÉ unicod_bin ON t (unicod_bin)
Exécutez le processus de filtrage :
SET STATISTICS TIME, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Comme vous pouvez le voir, cette requête renvoie le résultat suivant :
Temps d'exécution de SQL Server :temps CPU =350 ms, temps écoulé =354 ms.Temps d'exécution de SQL Server :temps CPU =335 ms, temps écoulé =355 ms.Temps d'exécution de SQL Server :temps CPU =16 ms, temps écoulé =18 ms.Temps d'exécution SQL Server :temps CPU =17 ms, temps écoulé =18 ms.
Le fait est que le filtrage basé sur la comparaison binaire prend moins de temps. Ainsi, si vous avez besoin de filtrer fréquemment et rapidement l'occurrence des chaînes, il est alors possible de stocker des données avec COLLATE se terminant par BIN. Cependant, il convient de noter que tous les COLLATE binaires sont sensibles à la casse.
Style de code
Un style de codage est strictement individuel. Néanmoins, ce code doit être simplement maintenu par d'autres développeurs et respecter certaines règles.
Créez une base de données séparée et une table à l'intérieur :
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY) Ensuite, écrivez la requête :
sélectionner l'identifiant de l'employé à partir de l'employé
Maintenant, remplacez COLLATE par n'importe quel élément sensible à la casse :
Test ALTER DATABASE COLLATE Latin1_General_CS_AI
Ensuite, essayez à nouveau d'exécuter la requête :
Msg 208, Niveau 16, État 1, Ligne 19Nom d'objet non valide 'employé'.
Un optimiseur utilise des règles pour le COLLATE actuel à l'étape de liaison lorsqu'il vérifie les tables, les colonnes et d'autres objets ainsi qu'il compare chaque objet de l'arbre de syntaxe avec un objet réel d'un catalogue système.
Si vous souhaitez générer des requêtes manuellement, vous devez toujours utiliser la casse correcte dans les noms d'objets.
Comme pour les variables, les COLLATE sont héritées de la base de données master. Ainsi, vous devez également utiliser la casse correcte pour les utiliser :
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid Dans ce cas, vous n'obtiendrez pas d'erreur :
----------------------Cyrillic_General_CI_AS-----------1
Néanmoins, une erreur de casse peut apparaître sur un autre serveur :
---------------------Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4Doit déclarer la variable scalaire "@empid".[var]char
Comme vous le savez, il existe des correctifs (CHAR , NCHAR ) et variable (VARCHAR , NVARCHAR ) types de données :
DECLARE @a CHAR(20) ='texte' , @b VARCHAR(20) ='texte'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE') , [b =a] =IIF(@b =@a, 'VRAI', 'FAUX') , [a COMME b] =IIF(@a COMME @b, 'VRAI', 'FAUX') , [b COMME a] =IIF(@ b COMME @a, 'VRAI', 'FAUX')Si une ligne a une longueur fixe, disons 20 symboles, mais que vous n'avez écrit que 4 symboles, alors SQL Server ajoutera 16 blancs à droite par défaut :
--- --- ---- ---- ---------------------- ----------- -----------4 4 20 4 "texte " "texte"In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSEAs for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'Data length
It is always necessary to specify type length.
Prenons l'exemple suivant :
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLineAs we have OR in the statement, we will receive IndexScan:
Table 'Address'. Scan count 1, logical reads 90, ...Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) tWhen the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
Table 'Table de travail'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityIDThe fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...SubQuery
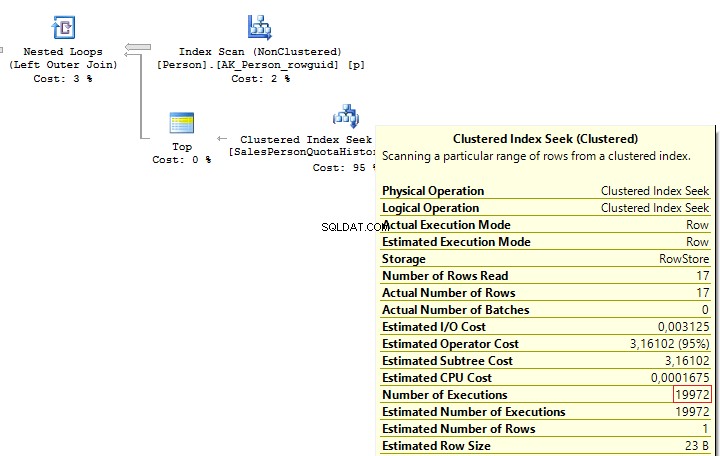
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
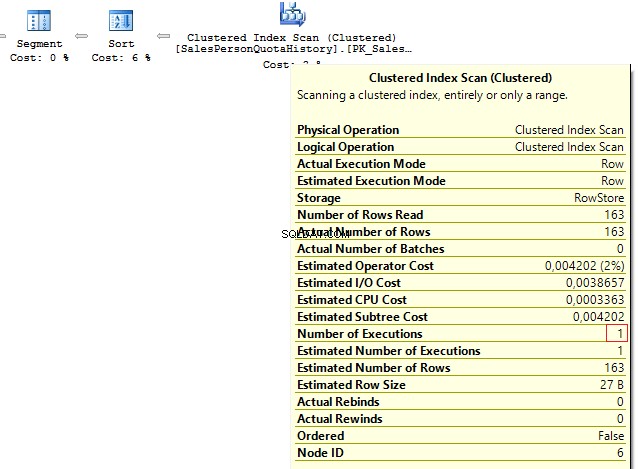
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person pHowever, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) tWhen executing these queries, we will get the same issue – multiple IndexSeek operators:
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1We get the following result:
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.EmployeeSQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.EmployeeThus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))ENDThen, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddressThe function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddressIn this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) tIn this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.EmployeeThough statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) ENDScalar func
It is not recommended to use scalar functions in T-SQL queries.
Prenons l'exemple suivant :
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDENDThe queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFFHowever, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.CurrencyIn this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tblAs you can see, we get the correct result:
a b----------- -----------0 1Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tblWe receive the same result:
a b----------- -----------0 1Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tblResult:
a b c----------- ----------- -----------0 1 2When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityIDWhat should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )Look at the execution plan in the case of using a view:
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...Now, we will compare it with the query we have written manually:
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE curThough, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTimeIn addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1If we add any additional value to the property,
SET @param ='1; select ''hack'''Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@paramIt is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...}Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.