Galera Cluster est livré avec de nombreuses fonctionnalités notables qui ne sont pas disponibles dans la réplication MySQL standard (ou la réplication de groupe) ; provisionnement automatique des nœuds, véritable multi-maître avec résolution des conflits et basculement automatique. Il existe également un certain nombre de limitations susceptibles d'avoir un impact sur les performances du cluster. Heureusement, si vous ne les connaissez pas, il existe des solutions de contournement. Et si vous le faites correctement, vous pouvez minimiser l'impact de ces limitations et améliorer les performances globales.
Nous avons déjà couvert de nombreux trucs et astuces liés à Galera Cluster, y compris l'exécution de Galera sur AWS Cloud. Ce billet de blog plonge clairement dans les aspects de performance, avec des exemples sur la façon de tirer le meilleur parti de Galera.
Charge utile de réplication
Un peu d'introduction - Galera réplique les jeux d'écriture pendant l'étape de validation, transférant les jeux d'écriture du nœud d'origine aux nœuds récepteurs de manière synchrone via le plug-in de réplication wsrep. Ce plugin certifiera également les jeux d'écriture sur les nœuds récepteurs. Si le processus de certification réussit, il renvoie OK au client sur le nœud d'origine et sera appliqué sur les nœuds récepteurs ultérieurement de manière asynchrone. Sinon, la transaction sera annulée sur le nœud d'origine (renvoyant l'erreur au client) et les jeux d'écriture qui ont été transférés aux nœuds récepteurs seront supprimés.
Un jeu d'écriture consiste en des opérations d'écriture à l'intérieur d'une transaction qui modifient l'état de la base de données. Dans Galera Cluster, autocommit est par défaut à 1 (activé). Littéralement, toute instruction SQL exécutée dans Galera Cluster sera incluse en tant que transaction, à moins que vous ne commenciez explicitement par BEGIN, START TRANSACTION ou SET autocommit=0. Le schéma suivant illustre l'encapsulation d'une seule instruction DML dans un jeu d'écriture :
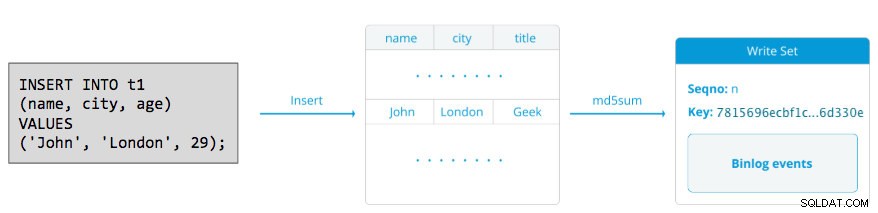
Pour DML (INSERT, UPDATE, DELETE..), la charge utile du jeu d'écriture se compose des événements de journal binaire pour une transaction particulière tandis que pour les DDL (ALTER, GRANT, CREATE..), la charge utile du jeu d'écriture est l'instruction DDL elle-même. Pour les DML, le jeu d'écriture devra être certifié contre les conflits sur le nœud récepteur tandis que pour les DDL (en fonction de wsrep_osu_method , par défaut sur TOI), le cluster cluster exécute l'instruction DDL sur tous les nœuds dans la même séquence de commande totale, empêchant les autres transactions de s'engager pendant que le DDL est en cours (voir aussi RSU). En termes simples, Galera Cluster gère différemment la réplication DDL et DML.
Temps aller-retour
Généralement, les facteurs suivants déterminent la vitesse à laquelle Galera peut répliquer un ensemble d'écritures d'un nœud d'origine vers tous les nœuds récepteurs :
- Temps d'aller-retour (RTT) entre le nœud le plus éloigné du cluster et le nœud d'origine.
- La taille d'un jeu d'écritures à transférer et à certifier en cas de conflit sur le nœud récepteur.
Par exemple, si nous avons un cluster Galera à trois nœuds et que l'un des nœuds est situé à 10 millisecondes (0,01 seconde), il est très peu probable que vous puissiez écrire plus de 100 fois par seconde sur la même ligne sans conflit. Il existe une citation populaire de Mark Callaghan qui décrit assez bien ce comportement :
"[Dans un cluster Galera] une ligne donnée ne peut pas être modifiée plus d'une fois par RTT"
Pour mesurer la valeur RTT, effectuez simplement un ping sur le nœud d'origine vers le nœud le plus éloigné du cluster :
$ ping 192.168.55.173 # the farthest nodeAttendez quelques secondes (ou minutes) et terminez la commande. La dernière ligne de la section des statistiques de ping correspond à ce que nous recherchons :
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msLe maximum la valeur est de 1,340 ms (0,00134 s) et nous devrions prendre cette valeur lors de l'estimation du minimum transactions par seconde (tps) pour ce cluster. La moyenne la valeur est de 0,431 ms (0,000431 s) et nous pouvons l'utiliser pour estimer la moyenne tps pendant min la valeur est de 0,111 ms (0,000111 s) que nous pouvons utiliser pour estimer le maximum tps. Le mdev signifie comment les échantillons RTT ont été distribués à partir de la moyenne. Une valeur inférieure signifie un RTT plus stable.
Par conséquent, les transactions par seconde peuvent être estimées en divisant le RTT (en seconde) en 1 seconde :

Résultat,
- Tps minimum :1 / 0,00134 (RTT max) =746,26 ~ 746 tps
- Tps moyen :1 / 0,000431 (RTT moyen) =2 320,19 ~ 2 320 tps
- Tps maximum :1 / 0,000111 (min RTT) =9009,01 ~ 9009 tps
Notez qu'il ne s'agit que d'une estimation pour anticiper les performances de réplication. Nous ne pouvons pas faire grand-chose pour améliorer cela du côté de la base de données, une fois que tout est déployé et en cours d'exécution. Sauf si vous déplacez ou migrez les serveurs de base de données plus près les uns des autres pour améliorer le RTT entre les nœuds, ou mettez à niveau les périphériques ou l'infrastructure du réseau. Cela nécessiterait une fenêtre de maintenance et une planification appropriée.
Découper les grosses transactions
Un autre facteur est la taille de la transaction. Une fois le jeu d'écriture transféré, un processus de certification aura lieu. La certification est un processus permettant de déterminer si le nœud peut ou non appliquer le jeu d'écriture. Galera génère des pseudo-clés de somme de contrôle MD5 à partir de chaque ligne complète. Le coût de la certification dépend de la taille du jeu d'écritures, qui se traduit par un certain nombre de recherches de clés uniques dans l'index de certification (une table de hachage). Si vous mettez à jour 500 000 lignes en une seule transaction, par exemple :
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Ce qui précède générera un seul ensemble d'écritures contenant 500 000 événements de journal binaire. Cet énorme jeu d'écritures ne dépasse pas wsrep_max_ws_size (par défaut à 2 Go) il sera donc transféré par le plugin de réplication Galera à tous les nœuds du cluster, certifiant ces 500 000 lignes sur les nœuds récepteurs pour toutes les transactions en conflit qui sont toujours dans la file d'attente esclave. Enfin, le statut de certification est renvoyé au plugin de réplication de groupe. Plus la taille de la transaction est importante, plus elle risque d'être en conflit avec d'autres transactions provenant d'un autre maître. Les transactions en conflit gaspillent les ressources du serveur et entraînent un énorme retour en arrière vers le nœud d'origine. Notez qu'une opération de restauration dans MySQL est beaucoup plus lente et moins optimisée qu'une opération de validation.
L'instruction SQL ci-dessus peut être réécrite dans une instruction plus conviviale pour Galera à l'aide d'une boucle simple, comme dans l'exemple ci-dessous :
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneLa commande shell ci-dessus mettrait à jour 1000 lignes par transaction 500 fois et attendrait 2 secondes entre les exécutions. Vous pouvez également utiliser une procédure stockée ou d'autres moyens pour obtenir un résultat similaire. Si la réécriture de la requête SQL n'est pas une option, demandez simplement à l'application d'exécuter la grosse transaction pendant une fenêtre de maintenance pour réduire le risque de conflits.
Pour les suppressions massives, envisagez d'utiliser pt-archiver du Percona Toolkit - une tâche à faible impact, uniquement en avant, pour grignoter les anciennes données de la table sans trop affecter les requêtes OLTP.
Threads esclaves parallèles
Dans Galera, l'applicateur est un processus multithread. Applier est un thread s'exécutant dans Galera pour appliquer les ensembles d'écriture entrants à partir d'un autre nœud. Cela signifie qu'il est possible pour tous les récepteurs d'exécuter simultanément plusieurs opérations DML provenant directement du nœud d'origine (maître). La réplication parallèle Galera n'est appliquée aux transactions que lorsqu'il est sûr de le faire. Cela améliore la probabilité que le nœud se synchronise avec le nœud d'origine. Cependant, la vitesse de réplication est toujours limitée au RTT et à la taille du jeu d'écriture.
Pour en tirer le meilleur parti, nous devons savoir deux choses :
- Le nombre de cœurs dont dispose le serveur.
- La valeur de wsrep_cert_deps_distance statut.
Le statut wsrep_cert_deps_distance nous indique le degré potentiel de parallélisation. C'est la valeur de la distance moyenne entre les valeurs de seqno les plus hautes et les plus basses qui peuvent être éventuellement appliquées en parallèle. Vous pouvez utiliser la wsrep_cert_deps_distance variable d'état pour déterminer le nombre maximum de threads esclaves possibles. Notez qu'il s'agit d'une valeur moyenne dans le temps. Par conséquent, pour obtenir une bonne valeur, vous devez frapper le cluster avec des opérations d'écriture via une charge de travail de test ou un benchmark jusqu'à ce que vous voyiez une valeur stable sortir.
Pour obtenir le nombre de cœurs, vous pouvez simplement utiliser la commande suivante :
$ grep -c processor /proc/cpuinfo
4Idéalement, 2, 3 ou 4 threads d'applicateur esclave par cœur de CPU est un bon début. Ainsi, la valeur minimale pour les threads esclaves doit être de 4 x le nombre de cœurs de processeur et ne doit pas dépasser la wsrep_cert_deps_distance valeur :
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Vous pouvez contrôler le nombre de threads d'applicateur esclave à l'aide de wsrep_slave_thread variable. Même s'il s'agit d'une variable dynamique, seule une augmentation du nombre aurait un effet immédiat. Si vous réduisez la valeur dynamiquement, cela prendrait un certain temps, jusqu'à ce que le thread de l'applicateur se ferme après avoir fini de s'appliquer. Une valeur recommandée est comprise entre 16 et 48 :
mysql> SET GLOBAL wsrep_slave_threads = 48;Notez que pour que les threads esclaves parallèles fonctionnent, les éléments suivants doivent être définis (ce qui est généralement préconfiguré pour Galera Cluster) :
innodb_autoinc_lock_mode=2Cache Galera (gcache)
Galera utilise un fichier préalloué avec une taille spécifique appelée gcache, où un nœud Galera conserve une copie des jeux d'écriture dans un style de tampon circulaire. Par défaut, sa taille est de 128 Mo, ce qui est plutôt petit. Le transfert d'état incrémentiel (IST) est une méthode pour préparer un jointeur en envoyant uniquement les jeux d'écritures manquants disponibles dans le gcache du donateur. IST est plus rapide que le transfert d'instantané d'état (SST), il est non bloquant et n'a pas d'impact significatif sur les performances du donneur. Cela devrait être l'option préférée dans la mesure du possible.
IST ne peut être réalisé que si toutes les modifications manquées par le jointeur sont toujours dans le fichier gcache du donateur. Le paramètre recommandé pour cela est d'être aussi grand que l'ensemble de données MySQL. Si l'espace disque est limité ou coûteux, il est crucial de déterminer la bonne taille de la taille du gcache, car cela peut influencer les performances de synchronisation des données entre les nœuds Galera.
La déclaration ci-dessous nous donnera une idée de la quantité de données répliquées par Galera. Exécutez l'instruction suivante sur l'un des nœuds Galera pendant les heures de pointe (testé sur MariaDB >10.0 et PXC >5.6, galera >3.x) :
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Nous pouvons estimer que le nœud Galera peut avoir environ 16 minutes d'indisponibilité, sans que SST soit obligé de se joindre (à moins que Galera ne puisse pas déterminer l'état du jointeur). Si ce délai est trop court et que vous disposez de suffisamment d'espace disque sur vos nœuds, vous pouvez modifier le wsrep_provider_options="gcache.size=
Il est également recommandé d'utiliser gcache.recover=yes dans wsrep_provider_options (Galera> 3.19), où Galera tentera de récupérer le fichier gcache dans un état utilisable au démarrage plutôt que de le supprimer, préservant ainsi la possibilité d'avoir IST et évitant autant que possible SST. Codership et Percona ont couvert cela en détail dans leurs blogs. IST est toujours la meilleure méthode pour se synchroniser après qu'un nœud a rejoint le cluster. Il est 50 % plus rapide que xtrabackup ou mariabackup et 5 x plus rapide que mysqldump.
Esclave asynchrone
Les nœuds Galera sont étroitement couplés, où les performances de réplication sont aussi rapides que le nœud le plus lent. Galera utilise un mécanisme de contrôle de flux pour contrôler le flux de réplication entre les membres et éliminer tout décalage d'esclave. La réplication peut être entièrement rapide ou entièrement lente sur chaque nœud et est ajustée automatiquement par Galera. Si vous voulez en savoir plus sur le contrôle de flux, lisez ce billet de blog de Jay Janssen de Percona.
Dans la plupart des cas, les opérations lourdes telles que les longues analyses (lecture intensive) et les sauvegardes (lecture intensive, verrouillage) sont souvent inévitables, ce qui pourrait dégrader les performances du cluster. La meilleure façon d'exécuter ce type de requêtes est de les envoyer à un serveur répliqué faiblement couplé, par exemple, un esclave asynchrone.
Un esclave asynchrone réplique à partir d'un nœud Galera en utilisant le protocole de réplication asynchrone MySQL standard. Il n'y a pas de limite au nombre d'esclaves pouvant être connectés à un nœud Galera, et le chaînage avec un maître intermédiaire est également possible. Les opérations MySQL qui s'exécutent sur ce serveur n'affecteront pas les performances du cluster, à l'exception de la phase de synchronisation initiale où une sauvegarde complète doit être effectuée sur le nœud Galera pour mettre en scène l'esclave avant d'établir le lien de réplication (bien que ClusterControl vous permette de construire le nœud asynchrone esclave d'une sauvegarde existante avant de la connecter au cluster).
GTID (Global Transaction Identifier) fournit un meilleur mappage des transactions entre les nœuds et est pris en charge dans MySQL 5.6 et MariaDB 10.0. Avec GTID, l'opération de basculement d'un esclave vers un autre maître (un autre nœud Galera) est simplifiée, sans qu'il soit nécessaire de déterminer le fichier journal exact et sa position. Galera est également livré avec sa propre implémentation GTID, mais ces deux éléments sont indépendants l'un de l'autre.
La mise à l'échelle d'un esclave asynchrone se fait en un clic si vous utilisez la fonctionnalité ClusterControl -> Ajouter un esclave de réplication :
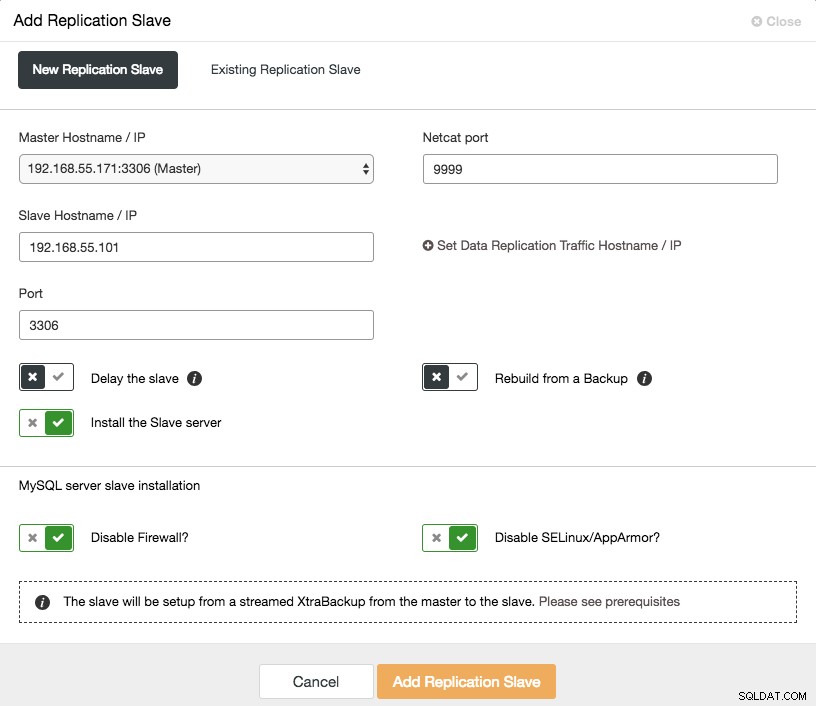
Notez que les journaux binaires doivent être activés sur le maître (le nœud Galera choisi) avant de pouvoir procéder à cette configuration. Nous avons également couvert la méthode manuelle dans ce post précédent.
La capture d'écran suivante de ClusterControl montre la topologie du cluster, elle illustre notre architecture Galera Cluster avec un esclave asynchrone :
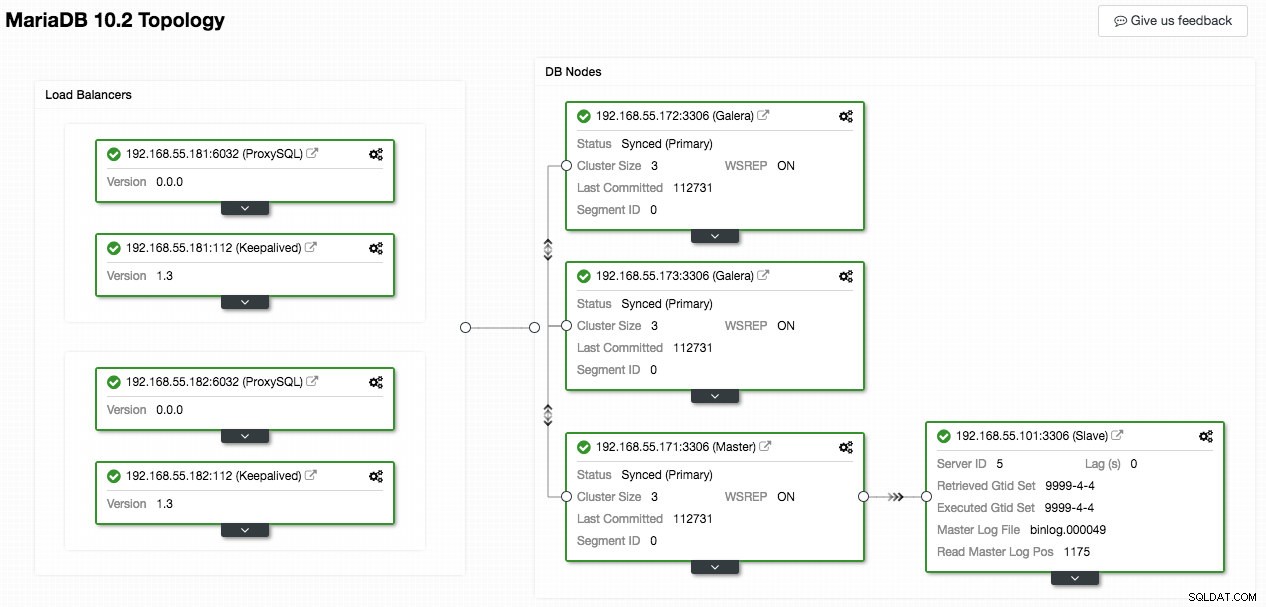
ClusterControl découvre automatiquement la topologie et génère le diagramme super cool comme ci-dessus. Vous pouvez également effectuer des tâches d'administration directement à partir de cette page en cliquant sur l'icône d'engrenage en haut à droite de chaque boîte.
Proxy inverse compatible SQL
ProxySQL et MariaDB MaxScale sont des proxys inverses intelligents qui comprennent le protocole MySQL et sont capables d'agir comme une passerelle, un routeur, un équilibreur de charge et un pare-feu devant vos nœuds Galera. Avec l'aide d'un fournisseur d'adresses IP virtuelles comme LVS ou Keepalived, et en combinant cela avec la technologie de réplication multi-maître Galera, nous pouvons avoir un service de base de données hautement disponible, éliminant tous les points de défaillance uniques (SPOF) possibles du point d'application -de vue. Cela améliorera sûrement la disponibilité et la fiabilité de l'architecture dans son ensemble.
Un autre avantage de cette approche est que vous aurez la possibilité de surveiller, réécrire ou réacheminer les requêtes SQL entrantes en fonction d'un ensemble de règles avant qu'elles n'atteignent le serveur de base de données réel, en minimisant les modifications côté application ou côté client et en acheminant les requêtes vers un nœud plus approprié pour des performances optimales. Les requêtes risquées pour Galera telles que LOCK TABLES et FLUSH TABLES WITH READ LOCK peuvent être évitées bien avant qu'elles ne causent des ravages au système, tout en ayant un impact sur les requêtes telles que les requêtes "hotspot" (une ligne à laquelle différentes requêtes veulent accéder en même temps) peut être réécrit ou être redirigé vers un seul nœud Galera pour réduire le risque de conflits de transaction. Pour les requêtes lourdes en lecture seule comme OLAP ou la sauvegarde, vous pouvez les acheminer vers un esclave asynchrone si vous en avez.
Le proxy inverse surveille également l'état de la base de données, les requêtes et les variables pour comprendre les changements de topologie et produire une décision de routage précise vers les serveurs principaux. Indirectement, il centralise la surveillance des nœuds et la vue d'ensemble du cluster sans qu'il soit nécessaire de vérifier régulièrement chaque nœud Galera. La capture d'écran suivante montre le tableau de bord de surveillance ProxySQL dans ClusterControl :
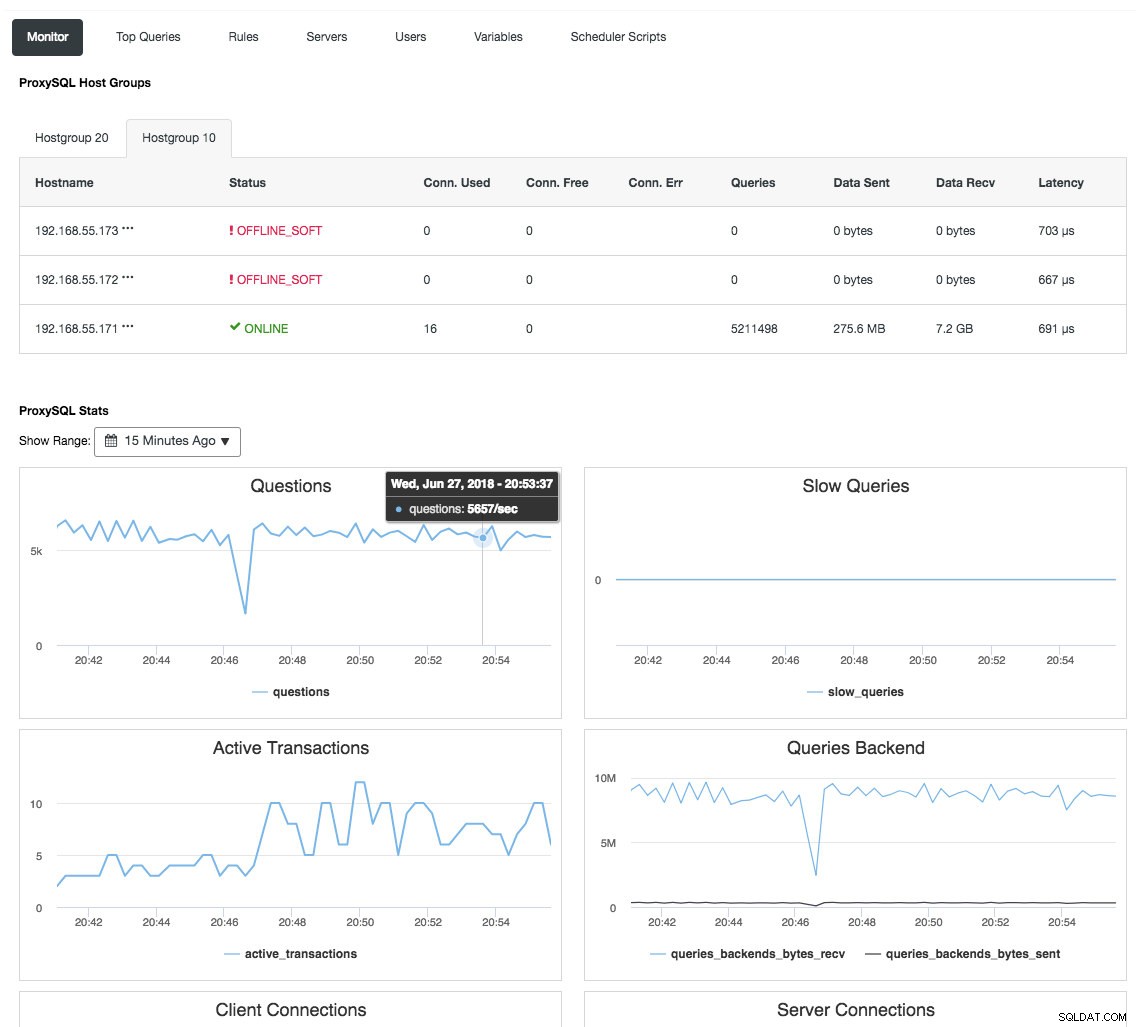
Il existe également de nombreux autres avantages qu'un équilibreur de charge peut apporter pour améliorer considérablement Galera Cluster, comme expliqué en détail dans cet article de blog, Devenez un administrateur de base de données ClusterControl :Rendre vos composants de base de données HA via des équilibreurs de charge.
Réflexions finales
Avec une bonne compréhension du fonctionnement interne de Galera Cluster, nous pouvons contourner certaines des limitations et améliorer le service de base de données. Bon regroupement !