La migration de la base de données Oracle vers l'open source peut apporter un certain nombre d'avantages. Le moindre coût de possession est tentant, et pousse beaucoup d'entreprises à migrer. Dans le même temps, DevOps, SysOps ou DBA doivent respecter des accords de niveau de service stricts pour répondre aux besoins de l'entreprise.
L'une des principales préoccupations lorsque vous planifiez la migration de données vers une autre base de données, en particulier open source, est de savoir comment éviter la perte de données. Il n'est pas trop exagéré que quelqu'un ait accidentellement supprimé une partie de la base de données, quelqu'un ait oublié d'inclure une clause WHERE dans une requête DELETE ou d'exécuter accidentellement DROP TABLE. La question est de savoir comment se remettre de telles situations.
Des choses comme ça peuvent arriver et arriveront, c'est inévitable mais l'impact peut être désastreux. Comme quelqu'un l'a dit, "C'est du plaisir et des jeux jusqu'à ce que la sauvegarde échoue". L'atout le plus précieux ne peut être compromis. Période.
La peur de l'inconnu est naturelle si vous n'êtes pas familier avec les nouvelles technologies. En fait, la connaissance des solutions de base de données Oracle, la fiabilité et les fonctionnalités exceptionnelles offertes par Oracle Recovery Manager (RMAN) peuvent vous décourager, vous ou votre équipe, de migrer vers un nouveau système de base de données. Nous aimons utiliser des choses que nous connaissons, alors pourquoi migrer alors que notre solution actuelle fonctionne. Qui sait combien de projets ont été suspendus parce que l'équipe ou l'individu n'était pas convaincu par la nouvelle technologie ?
Sauvegardes logiques (exp/imp, expdp/impdb)
Selon la documentation MySQL, la sauvegarde logique est "une sauvegarde qui reproduit la structure et les données des tables, sans copier les fichiers de données réels". Cette définition peut s'appliquer aux mondes MySQL et Oracle. Il en va de même pour "pourquoi" et "quand" vous utiliserez la sauvegarde logique.
Les sauvegardes logiques sont une bonne option lorsque nous savons quelles données seront modifiées afin que vous puissiez sauvegarder uniquement la partie dont vous avez besoin. Il simplifie la restauration potentielle en termes de temps et de complexité. C'est également très utile si nous devons déplacer une partie d'un ensemble de données de petite/moyenne taille et les recopier vers un autre système (souvent sur une version de base de données différente). Oracle utilise des utilitaires d'exportation tels que exp et expdp pour lire les données de la base de données, puis les exporter dans un fichier au niveau du système d'exploitation. Vous pouvez ensuite réimporter les données dans une base de données à l'aide des utilitaires d'importation imp ou impdp.
Oracle Export Utilities nous offre de nombreuses options pour choisir les données à exporter. Vous ne trouverez certainement pas le même nombre de fonctionnalités avec mysql, mais la plupart des besoins sont couverts et le reste peut être fait avec des scripts supplémentaires ou des outils externes (consultez mydumper).
MySQL est livré avec un ensemble d'outils qui offrent des fonctionnalités très basiques. Il s'agit de mysqldump, mysqlpump (la version moderne de mysqldump qui prend en charge nativement la parallélisation) et du client MySQL qui peut être utilisé pour extraire des données dans un fichier plat.
Vous trouverez ci-dessous plusieurs exemples d'utilisation :
Sauvegarder uniquement la structure de la base de données
mysqldump --no-data -h localhost -u root -ppassword mydatabase > mydatabase_backup.sqlStructure de la table de sauvegarde
mysqldump --no-data --single- transaction -h localhost -u root -ppassword mydatabase table1 table2 > mydatabase_backup.sqlSauvegarder des lignes spécifiques
mysqldump -h localhost --single- transaction -u root -ppassword mydatabase table_name --where="date_created='2019-05-07'" > table_with_specific_rows_dump.sqlImportation du tableau
mysql -u username -p -D dbname < tableName.sqlLa commande ci-dessus arrêtera le chargement si une erreur se produit.
Si vous chargez des données directement depuis le client mysql, les erreurs seront ignorées et le client continuera
mysql> source tableName.sqlPour enregistrer la sortie, vous devez utiliser
mysql> tee import_tableName.logVous pouvez trouver tous les drapeaux expliqués sous les liens ci-dessous :
- https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html
- https://dev.mysql.com/doc/refman/8.0/en/mysqlimport.html
- https://dev.mysql.com/doc/refman/8.0/en/mysql.html
Si vous envisagez d'utiliser une sauvegarde logique sur différentes versions de base de données, assurez-vous d'avoir la bonne configuration de classement. L'instruction suivante peut être utilisée pour vérifier le jeu de caractères et le classement par défaut pour une base de données donnée :
USE mydatabase;
SELECT @@character_set_database, @@collation_database;Une autre façon de récupérer la variable système collation_database consiste à utiliser SHOW VARIABLES.
SHOW VARIABLES LIKE 'collation%';En raison des limitations du vidage mysql, nous devons souvent modifier la sortie. Un exemple d'une telle modification peut être la nécessité de supprimer certaines lignes. Heureusement, nous avons la possibilité de visualiser et de modifier la sortie à l'aide d'outils de texte standard avant la restauration. Des outils comme awk, grep, sed peuvent devenir vos amis. Vous trouverez ci-dessous un exemple simple de suppression de la troisième ligne du fichier de vidage.
sed -i '1,3d' file.txtLes possibilités sont infinies. C'est quelque chose que nous ne trouverons pas avec Oracle car les données sont écrites au format binaire.
Il y a quelques éléments que vous devez prendre en compte lorsque vous exécutez mysql logique. L'une des principales limitations est le support pur du parallélisme et du verrouillage d'objet.
Considérations relatives à la sauvegarde logique
Lorsqu'une telle sauvegarde est exécutée, les étapes suivantes seront effectuées.
- TABLE VERROUILLÉE.
- AFFICHER LE tableau CREATE TABLE.
- SELECT * FROM table INTO OUTFILE fichier temporaire.
- Écrivez le contenu du fichier temporaire à la fin du fichier de vidage.
- DÉVERROUILLER DES TABLES
Par défaut, mysqldump n'inclut pas les routines et les événements dans sa sortie - vous devez définir explicitement les indicateurs --routines et --events.
Une autre considération importante est un moteur que vous utilisez pour stocker vos données. Espérons que de nos jours, la plupart des systèmes de production utilisent un moteur compatible ACID appelé InnoDB. L'ancien moteur MyISAM devait verrouiller toutes les tables pour assurer la cohérence. C'est à ce moment que FLUSH TABLES WITH READ LOCK a été exécuté. Malheureusement, c'est le seul moyen de garantir un instantané cohérent des tables MyISAM pendant que le serveur MySQL est en cours d'exécution. Cela rendra le serveur MySQL en lecture seule jusqu'à ce que UNLOCK TABLES soit exécuté.
Pour les tables sur le moteur de stockage InnoDB, il est recommandé d'utiliser l'option --single-transaction. MySQL produit ensuite un point de contrôle qui permet au vidage de capturer toutes les données avant le point de contrôle lors de la réception des modifications entrantes.
L'option --single-transaction de mysqldump ne fait pas FLUSH TABLES WITH READ LOCK. Cela amène mysqldump à configurer une transaction REPEATABLE READ pour toutes les tables en cours de vidage.
Une sauvegarde mysqldump est beaucoup plus lente que les outils Oracle exp, expdp. Mysqldump est un outil à thread unique et c'est son inconvénient le plus important :les performances sont correctes pour les petites bases de données, mais elles deviennent rapidement inacceptables si l'ensemble de données atteint des dizaines de gigaoctets.
- COMMENCER LA TRANSACTION AVEC UN INSTANTANÉ COHÉRENT.
- Pour chaque schéma et table de base de données, un vidage effectue ces étapes :
- AFFICHER LE tableau CREATE TABLE.
- SELECT * FROM table INTO OUTFILE fichier temporaire.
- Écrivez le contenu du fichier temporaire à la fin du fichier de vidage.
- ENGAGEZ-VOUS.
Sauvegardes physiques (RMAN)
Heureusement, la plupart des limitations de la sauvegarde logique peuvent être résolues avec l'outil Percona Xtrabackup. Percona XtraBackup est le logiciel de sauvegarde à chaud MySQL/MariaDB open source le plus populaire qui effectue des sauvegardes non bloquantes pour les bases de données InnoDB et XtraDB. Il entre dans la catégorie des sauvegardes physiques, qui consiste en des copies exactes du répertoire de données MySQL et des fichiers en dessous.
C'est la même catégorie d'outils comme Oracle RMAN. RMAN fait partie du logiciel de base de données, XtraBackup doit être téléchargé séparément. Xtrabackup est disponible sous forme de packages rpm et deb et ne prend en charge que les plates-formes Linux. L'installation est très simple :
$ wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-8.0.4/binary/redhat/7/x86_64/percona-XtraBackup-80-8.0.4-1.el7.x86_64.rpm
$ yum localinstall percona-XtraBackup-80-8.0.4-1.el7.x86_64.rpmXtraBackup ne verrouille pas votre base de données pendant le processus de sauvegarde. Pour les grandes bases de données (plus de 100 Go), il offre un temps de restauration bien meilleur par rapport à mysqldump. Le processus de restauration implique de préparer les données MySQL à partir des fichiers de sauvegarde, avant de les remplacer ou de les basculer avec le répertoire de données actuel sur le nœud cible.
Percona XtraBackup fonctionne en mémorisant le numéro de séquence du journal (LSN) lorsqu'il démarre, puis en copiant les fichiers de données vers un autre emplacement. La copie de données prend un certain temps, et si les fichiers changent, ils reflètent l'état de la base de données à différents moments. En même temps, XtraBackup exécute un processus d'arrière-plan qui garde un œil sur les fichiers du journal des transactions (alias redo log) et en copie les modifications. Cela doit être fait en permanence car les journaux de transactions sont écrits à tour de rôle et peuvent être réutilisés après un certain temps. XtraBackup a besoin des enregistrements du journal des transactions pour chaque modification apportée aux fichiers de données depuis le début de son exécution.
Lorsque XtraBackup est installé, vous pouvez enfin effectuer vos premières sauvegardes physiques.
xtrabackup --user=root --password=PASSWORD --backup --target-dir=/u01/backups/Une autre option utile que font les administrateurs MySQL est la diffusion en continu de la sauvegarde sur un autre serveur. Un tel flux peut être effectué à l'aide de l'outil xbstream, comme dans l'exemple ci-dessous :
Démarrez un écouteur sur le serveur externe sur le port préférable (dans cet exemple 1984)
nc -l 1984 | pigz -cd - | pv | xbstream -x -C /u01/backupsExécutez la sauvegarde et le transfert vers un hôte externe
innobackupex --user=root --password=PASSWORD --stream=xbstream /var/tmp | pigz | pv | nc external_host.com 1984Comme vous pouvez le remarquer, le processus de restauration est divisé en deux étapes principales (similaire à Oracle). Les étapes sont restaurées (copier en arrière) et de récupération (appliquer le journal).
XtraBackup --copy-back --target-dir=/var/lib/data
innobackupex --apply-log --use-memory=[values in MB or GB] /var/lib/dataLa différence est que nous ne pouvons effectuer une récupération qu'au moment où la sauvegarde a été effectuée. Pour appliquer les modifications après la sauvegarde, nous devons le faire manuellement.
Restauration ponctuelle (récupération RMAN)
Dans Oracle, RMAN effectue toutes les étapes lorsque nous effectuons la récupération de la base de données. Cela peut être fait soit par SCN, soit par heure, soit sur la base de l'ensemble de données de sauvegarde.
RMAN> run
{
allocate channel dev1 type disk;
set until time "to_date('2019-05-07:00:00:00', 'yyyy-mm-dd:hh24:mi:ss')";
restore database;
recover database; }Dans mysql, nous avons besoin d'un autre outil pour extraire les données des journaux binaires (similaire aux archiveslogs d'Oracle) mysqlbinlog. mysqlbinlog peut lire les journaux binaires et les convertir en fichiers. Ce que nous devons faire, c'est
La procédure de base serait
- Restaurer la sauvegarde complète
- Restaurer des sauvegardes incrémentielles
- Pour identifier les heures de début et de fin de la récupération (cela pourrait être la fin de la sauvegarde et le numéro de position avant malheureusement la suppression de la table).
- Convertir les binglogs nécessaires en SQL et appliquer les fichiers SQL nouvellement créés dans le bon ordre - assurez-vous d'exécuter une seule commande mysqlbinlog.
> mysqlbinlog binlog.000001 binlog.000002 | mysql -u root -p
Crypter les sauvegardes (portefeuille Oracle)
Percona XtraBackup peut être utilisé pour chiffrer ou déchiffrer les sauvegardes locales ou en streaming avec l'option xbstream pour ajouter une autre couche de protection aux sauvegardes. Les options --encrypt-key et --encryptkey-file peuvent être utilisées pour spécifier la clé de chiffrement. Les clés de chiffrement peuvent être générées avec des commandes telles que
$ openssl rand -base64 24
$ bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1Cette valeur peut ensuite être utilisée comme clé de cryptage. Exemple de la commande innobackupex utilisant --encrypt-key :
$ innobackupex --encrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1” /storage/backups/encryptedPour déchiffrer, utilisez simplement l'option --decrypt avec --encrypt-key appropriée :
$ innobackupex --decrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1”
/storage/backups/encrypted/2019-05-08_11-10-09/Politiques de sauvegarde
Il n'y a pas de fonctionnalité de politique de sauvegarde intégrée dans MySQL/MariaDB ou même dans l'outil de Percona. Si vous souhaitez gérer vos sauvegardes MySQL logiques ou physiques, vous pouvez utiliser ClusterControl pour cela.
ClusterControl est le système de gestion de base de données open source tout compris pour les utilisateurs d'environnements mixtes. Il fournit une fonctionnalité de gestion de sauvegarde avancée pour MySQL ou MariaDB.
Avec ClusterControl, vous pouvez :
- Créer des politiques de sauvegarde
- Surveiller l'état des sauvegardes, les exécutions et les serveurs sans sauvegarde
- Exécuter des sauvegardes et des restaurations (y compris une restauration ponctuelle)
- Contrôler la conservation des sauvegardes
- Enregistrer les sauvegardes dans le stockage cloud
- Valider les sauvegardes (test complet avec la restauration sur le serveur autonome)
- Chiffrer les sauvegardes
- Compresser les sauvegardes
- Et bien d'autres
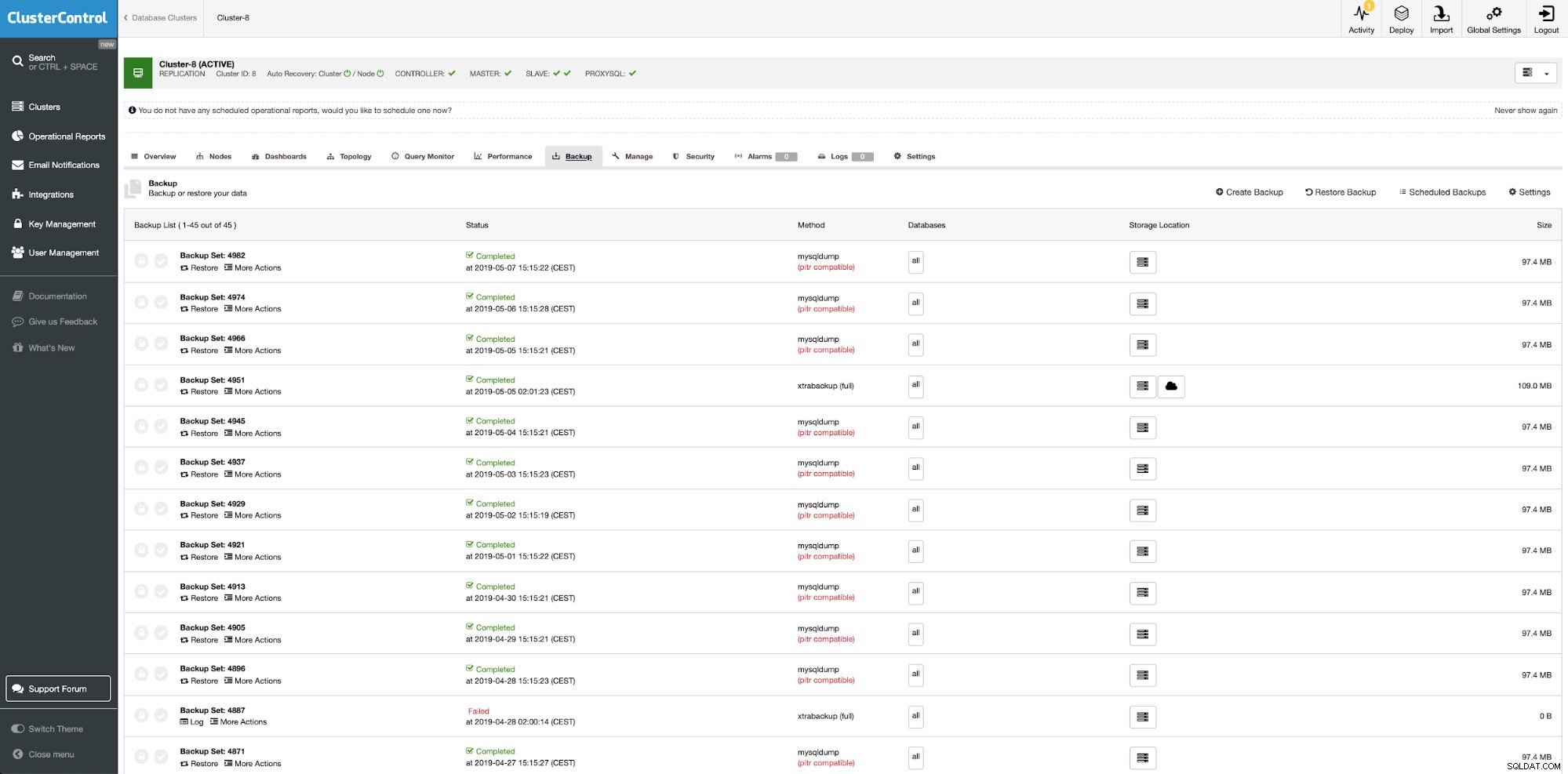 ClusterControl :gestion des sauvegardes
ClusterControl :gestion des sauvegardes Conserver les sauvegardes dans le cloud
Les entreprises ont toujours déployé des solutions de sauvegarde sur bande pour protéger
les données contre les pannes. Cependant, l'émergence du cloud computing public a également permis de nouveaux modèles avec un TCO inférieur à ce qui était traditionnellement disponible. Cela n'a aucun sens commercial d'abstraire le coût d'une solution de reprise après sinistre de sa conception. Les entreprises doivent donc mettre en œuvre le bon niveau de protection au coût le plus bas possible.
Le cloud a changé l'industrie de la sauvegarde des données. En raison de son prix abordable, les petites entreprises disposent d'une solution hors site qui sauvegarde toutes leurs données (et oui, assurez-vous qu'elles sont cryptées). Oracle et MySQL n'offrent pas de solutions de stockage en nuage intégrées. Au lieu de cela, vous pouvez utiliser les outils fournis par les fournisseurs de Cloud. Un exemple ici pourrait être s3.
aws s3 cp severalnines.sql s3://severalnine-sbucket/mysql_backupsConclusion

Il existe plusieurs façons de sauvegarder votre base de données, mais il est important d'examiner les besoins de l'entreprise avant de décider d'une stratégie de sauvegarde. Comme vous pouvez le constater, il existe de nombreuses similitudes entre les sauvegardes MySQL et Oracle qui, espérons-le, pourront répondre à vos SLA.
Assurez-vous toujours de pratiquer ces commandes. Non seulement lorsque vous êtes nouveau dans la technologie, mais chaque fois que le SGBD devient inutilisable, vous savez quoi faire.
Si vous souhaitez en savoir plus sur MySQL, veuillez consulter notre livre blanc The DevOps Guide to Database Backups for MySQL and MariaDB.