L'objectif de temps de récupération (RTO) est la période de temps pendant laquelle un service doit être restauré pour éviter des conséquences inacceptables. En calculant le temps qu'il faut pour se remettre d'une défaillance de la base de données, nous pouvons connaître le niveau de préparation requis. Si le RTO est de quelques minutes, un investissement important dans le basculement est nécessaire. Un RTO de 36 heures nécessite un investissement nettement inférieur. C'est là qu'intervient l'automatisation du basculement.
Dans nos blogs précédents, nous avons discuté du basculement pour MongoDB, MySQL/MariaDB/Percona, PostgreSQL ou TimeScaleDB. Pour résumer, "Basculement " est la capacité d'un système à continuer à fonctionner même en cas de défaillance. Cela suggère que les fonctions du système sont assumées par des composants secondaires si les composants principaux échouent. Le basculement est une partie naturelle de tout système à haute disponibilité et, dans certains cas, , il doit même être automatisé. Les basculements manuels prennent tout simplement trop de temps, mais il y a des cas où l'automatisation ne fonctionnera pas bien - par exemple dans le cas d'un cerveau divisé où la réplication de la base de données est interrompue et les deux "moitiés" continuent de recevoir des mises à jour, efficacement conduisant à des ensembles de données divergents et à des incohérences.
Nous avons précédemment écrit sur les principes directeurs derrière les procédures de basculement automatique de ClusterControl. Dans la mesure du possible, le basculement automatisé offre une efficacité car il permet une récupération rapide après les pannes. Dans ce blog, nous verrons comment réaliser un basculement automatique dans une configuration de réplication maître-esclave (ou primaire-de secours) à l'aide de ClusterControl.
Exigences de la pile technologique
Une pile peut être assemblée à partir de composants logiciels Open Source, et il existe un certain nombre d'options disponibles - certaines plus appropriées que d'autres en fonction des caractéristiques de basculement et également du niveau d'expertise disponible pour la gestion et la maintenance de la solution. Le matériel et la mise en réseau sont également des aspects importants.
Logiciel
Il existe de nombreuses options disponibles dans l'écosystème open source que vous pouvez utiliser pour implémenter le basculement. Pour MySQL, vous pouvez tirer parti de MHA, MMM, Maxscale/MRM, mysqlfailover ou Orchestrator. Ce blog précédent compare MaxScale à MHA à Maxscale/MRM. PostgreSQL a repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II ou stolon. Ces différentes options de haute disponibilité ont été traitées précédemment. MongoDB dispose d'ensembles de réplicas avec prise en charge du basculement automatisé.
ClusterControl fournit une fonctionnalité de basculement automatique pour MySQL, MariaDB, PostgreSQL et MongoDB, que nous aborderons plus loin. Il convient de noter qu'il dispose également d'une fonctionnalité pour récupérer automatiquement les nœuds ou les clusters cassés.
Matériel
Le basculement automatique est généralement effectué par un serveur démon distinct qui est configuré sur son propre matériel - séparé des nœuds de la base de données. Il surveille l'état des bases de données et utilise les informations pour prendre des décisions sur la manière de réagir en cas de panne.
Les serveurs de base peuvent fonctionner correctement, à moins que le serveur ne surveille un grand nombre d'instances. En règle générale, les vérifications du système et l'analyse de la santé sont légères en termes de traitement. Cependant, si vous avez un grand nombre de nœuds à vérifier, un processeur et une mémoire importants sont indispensables, en particulier lorsque les vérifications doivent être mises en file d'attente alors qu'il tente de cingler et de collecter des informations à partir des serveurs. Les nœuds surveillés et supervisés peuvent parfois se bloquer en raison de problèmes de réseau, d'une charge élevée ou, dans le pire des cas, ils peuvent être en panne en raison d'une panne matérielle ou d'une corruption de l'hôte VM. Ainsi, le serveur qui exécute les vérifications de la santé et du système doit être capable de résister à de tels blocages, car il est probable que le traitement des files d'attente puisse augmenter car les réponses à chacun des nœuds surveillés peuvent prendre du temps jusqu'à ce qu'il soit vérifié qu'il n'est plus disponible ou qu'un délai d'attente a été atteint.
Pour les environnements basés sur le cloud, il existe des services qui offrent un basculement automatique. Par exemple, Amazon RDS utilise DRBD pour répliquer le stockage sur un nœud de secours. Ou si vous stockez vos volumes dans EBS, ceux-ci sont répliqués dans plusieurs zones.
Réseau
Le logiciel de basculement automatisé s'appuie souvent sur des agents qui sont configurés sur les nœuds de la base de données. L'agent collecte les informations localement à partir de l'instance de base de données et les envoie au serveur, chaque fois que cela est demandé.
En termes de configuration réseau, assurez-vous que vous disposez d'une bonne bande passante et d'une connexion réseau stable. Les vérifications doivent être effectuées fréquemment, et les pulsations manquées en raison d'un réseau instable peuvent amener le logiciel de basculement à déduire (à tort) qu'un nœud est en panne.
ClusterControl ne nécessite aucun agent installé sur les nœuds de la base de données, car il se connectera en SSH à chaque nœud de la base de données à intervalles réguliers et effectuera un certain nombre de vérifications.
Basculement automatisé avec ClusterControl
ClusterControl offre la possibilité d'effectuer des basculements manuels et automatisés. Voyons comment cela peut être fait.
Le basculement dans ClusterControl peut être configuré pour être automatique ou non. Si vous préférez vous occuper du basculement manuellement, vous pouvez désactiver la récupération automatique du cluster. Lors d'un basculement manuel, vous pouvez accéder à Cluster → Topologie dans Cluster Control. Voir la capture d'écran ci-dessous :
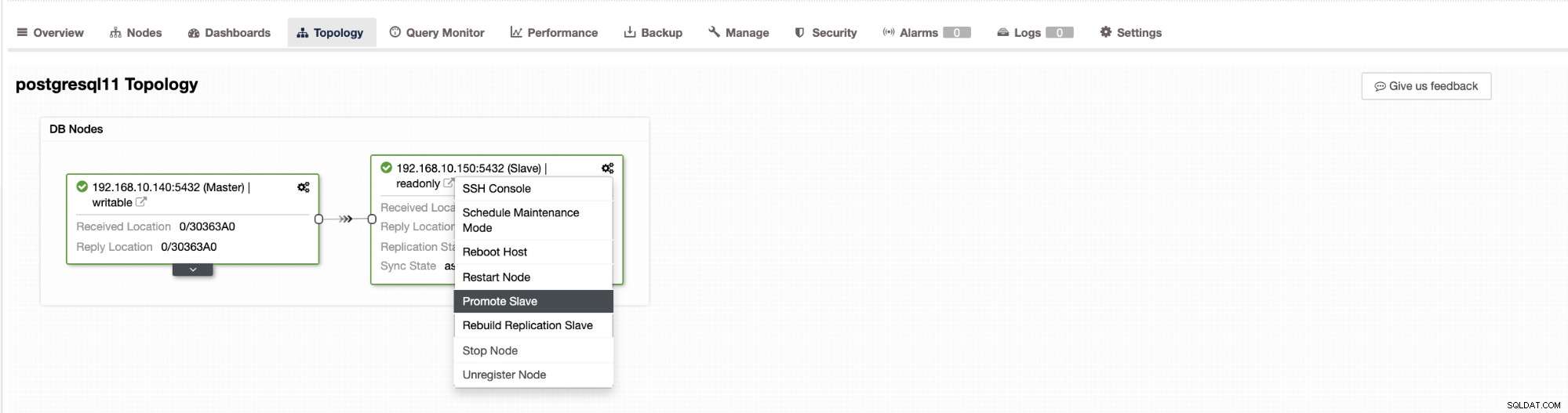
Par défaut, la récupération de cluster est activée et le basculement automatique est utilisé. Une fois que vous avez apporté des modifications à l'interface utilisateur, la configuration d'exécution est modifiée. Si vous souhaitez que le paramètre survive à un redémarrage du contrôleur, assurez-vous d'effectuer également la modification dans la configuration cmon, c'est-à-dire /etc/cmon.d/cmon_

Dans le serveur MySQL/MariaDB/Percona, le basculement automatique est initié par ClusterControl lorsqu'il détecte qu'il n'y a pas d'hôte avec lecture seule drapeau désactivé. Cela peut arriver parce que master (qui a lecture_seule défini sur 0) n'est pas disponible ou peut être déclenché par un utilisateur ou un logiciel externe qui a modifié cet indicateur sur le maître. Si vous apportez des modifications manuelles aux nœuds de la base de données ou si vous disposez d'un logiciel susceptible de modifier les paramètres read_only, vous devez désactiver le basculement automatique. Le basculement automatisé de ClusterControl n'est tenté qu'une seule fois, par conséquent, un basculement ayant échoué ne sera pas suivi d'un basculement ultérieur - pas tant que cmon n'aura pas été redémarré.
Pour PostgreSQL, ClusterControl choisira l'esclave le plus avancé, en utilisant à cet effet pg_current_xlog_location (PostgreSQL 9+) ou pg_current_wal_lsn (PostgreSQL 10+) selon la version de notre base de données. ClusterControl effectue également plusieurs vérifications sur le processus de basculement, afin d'éviter certaines erreurs courantes. Un exemple est que si nous parvenons à récupérer notre ancien maître défaillant, il ne sera "pas " sera réintroduit automatiquement dans le cluster, ni en tant que maître ni en tant qu'esclave. Nous devons le faire manuellement. Cela évitera la possibilité de perte de données ou d'incohérence dans le cas où notre esclave (que nous avons promu) a été retardé à l'époque de l'échec. Nous pourrions également vouloir analyser le problème en détail avant de le réintroduire dans la configuration de la réplication, afin de conserver les informations de diagnostic.
De plus, si le basculement échoue, aucune autre tentative n'est effectuée (ceci s'applique à la fois aux clusters PostgreSQL et MySQL), une intervention manuelle est nécessaire pour analyser le problème et effectuer les actions correspondantes. Ceci afin d'éviter la situation où ClusterControl, qui gère le basculement automatique, essaie de promouvoir l'esclave suivant et le suivant. Il peut y avoir un problème, et nous ne voulons pas aggraver les choses en tentant plusieurs basculements.
ClusterControl propose une liste blanche et une liste noire d'un ensemble de serveurs que vous souhaitez faire participer au basculement ou exclure en tant que candidats.
Pour les clusters de type MySQL, ClusterControl construit une liste d'esclaves qui peuvent être promus maître. La plupart du temps, il contiendra tous les esclaves de la topologie, mais l'utilisateur dispose d'un contrôle supplémentaire sur celui-ci. Il existe deux variables que vous pouvez définir dans la configuration cmon :
replication_failover_whitelistet
replication_failover_blacklistPour la variable de configuration replication_failover_whitelist, elle contient une liste d'adresses IP ou de noms d'hôtes d'esclaves qui doivent être utilisés comme candidats maîtres potentiels. Si cette variable est définie, seuls ces hôtes seront pris en compte. Pour la variable replication_failover_blacklist, elle contient la liste des hôtes qui ne seront jamais considérés comme candidats maîtres. Vous pouvez l'utiliser pour répertorier les esclaves utilisés pour les sauvegardes ou les requêtes analytiques. Si le matériel varie entre les esclaves, vous pouvez mettre ici les esclaves qui utilisent un matériel plus lent.
replication_failover_whitelist est prioritaire, ce qui signifie que replication_failover_blacklist est ignoré si replication_failover_whitelist est défini.
Une fois que la liste des esclaves pouvant être promus maître est prête, ClusterControl commence à comparer leur état, en recherchant l'esclave le plus à jour. Ici, la gestion des configurations basées sur MariaDB et MySQL diffère. Pour les configurations MariaDB, ClusterControl sélectionne un esclave qui a le plus faible retard de réplication de tous les esclaves disponibles. Pour les configurations MySQL, ClusterControl sélectionne également un tel esclave, mais il vérifie ensuite les transactions manquantes supplémentaires qui auraient pu être exécutées sur certains des esclaves restants. Si une telle transaction est trouvée, ClusterControl asservit le candidat maître de cet hôte afin de récupérer toutes les transactions manquantes. Vous pouvez ignorer ce processus et utiliser simplement l'esclave le plus avancé en définissant la variable replication_skip_apply_missing_txs dans votre configuration CMON :
ex.
replication_skip_apply_missing_txs=1Consultez notre documentation ici pour plus d'informations sur les variables.
La mise en garde est que vous ne devez définir cela que si vous savez ce que vous faites, car il pourrait y avoir des transactions errantes. Ceux-ci peuvent entraîner l'interruption de la réplication, ainsi que l'incohérence des données dans le cluster. Si la transaction errante s'est produite dans le passé, elle peut ne plus être disponible dans les journaux binaires. Dans ce cas, la réplication échouera car les esclaves ne pourront pas récupérer les données manquantes. Par conséquent, ClusterControl, par défaut, vérifie toutes les transactions errantes avant de promouvoir un candidat maître pour qu'il devienne maître. Si un tel problème est détecté, le commutateur principal est interrompu et ClusterControl permet à l'utilisateur de résoudre le problème manuellement.
Si vous voulez être sûr à 100 % que ClusterControl promouvra un nouveau maître même si certains problèmes sont détectés, vous pouvez le faire en utilisant la variable replication_stop_on_error. Voir ci-dessous :
ex.
replication_stop_on_error=0Définissez cette variable dans votre fichier de configuration cmon. Comme mentionné précédemment, cela peut entraîner des problèmes de réplication car les esclaves peuvent commencer à demander un événement de journal binaire qui n'est plus disponible. Pour gérer de tels cas, nous avons ajouté un support expérimental pour la reconstruction d'esclaves. Si vous définissez la variable
replication_auto_rebuild_slave=1dans la configuration cmon et si votre esclave est marqué comme down avec l'erreur suivante dans MySQL :
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl tentera de reconstruire l'esclave en utilisant les données du maître. Un tel paramètre peut ne pas toujours être approprié car le processus de reconstruction induira une charge accrue sur le maître. Il se peut également que votre ensemble de données soit très volumineux et qu'une reconstruction régulière ne soit pas une option - c'est pourquoi ce comportement est désactivé par défaut.
Une fois que nous nous sommes assurés qu'aucune transaction errante n'existe et que nous sommes prêts à partir, il reste encore un problème que nous devons résoudre d'une manière ou d'une autre - il peut arriver que tous les esclaves soient en retard sur le maître.
Comme vous le savez probablement, la réplication dans MySQL fonctionne de manière assez simple. Le maître stocke les écritures dans des journaux binaires. Le thread d'E/S de l'esclave se connecte au maître et extrait tous les événements de journal binaire qui lui manquent. Il les stocke ensuite sous forme de journaux de relais. Le thread SQL les analyse et applique des événements. Le décalage esclave est une condition dans laquelle le thread (ou les threads) SQL ne peut pas faire face au nombre d'événements et est incapable de les appliquer dès qu'ils sont extraits du maître par le thread d'E/S. Une telle situation peut se produire quel que soit le type de réplication que vous utilisez. Même si vous utilisez la réplication semi-synchrone, elle ne peut que garantir que tous les événements du maître sont stockés sur l'un des esclaves dans le journal de relais. Cela ne dit rien sur l'application de ces événements à un esclave.
Le problème ici est que, si un esclave est promu maître, les journaux de relais seront effacés. Si un esclave est en retard et n'a pas appliqué toutes les transactions, il perdra des données - les événements qui ne sont pas encore appliqués à partir des journaux de relais seront perdus à jamais.
Il n'y a pas de solution unique pour résoudre cette situation. ClusterControl donne aux utilisateurs le contrôle sur la façon dont cela doit être fait, en maintenant des valeurs par défaut sûres. Cela se fait dans la configuration cmon en utilisant le paramètre suivant :
replication_failover_wait_to_apply_timeout=-1Par défaut, il prend une valeur de '-1', ce qui signifie que le basculement ne se produira pas immédiatement si un candidat maître est en retard, il est donc configuré pour attendre indéfiniment à moins que le candidat n'ait rattrapé son retard. ClusterControl attendra indéfiniment qu'il applique toutes les transactions manquantes à partir de ses journaux de relais. C'est sûr, mais si pour une raison quelconque, l'esclave le plus à jour est en retard, le basculement peut prendre des heures. De l'autre côté du spectre, il est réglé sur "0" - cela signifie que le basculement se produit immédiatement, que le candidat maître soit en retard ou non. Vous pouvez également aller au milieu et le régler sur une certaine valeur. Cela définira un temps en secondes, par exemple 30 secondes, alors définissez la variable sur,
replication_failover_wait_to_apply_timeout=30Lorsqu'il est défini sur> 0, ClusterControl attendra qu'un candidat maître applique les transactions manquantes à partir de ses journaux de relais jusqu'à ce que la valeur soit atteinte (qui est de 30 secondes dans l'exemple). Le basculement se produit après l'heure définie ou lorsque le candidat maître rattrape la réplication, selon la première éventualité. Cela peut être un bon choix si votre application a des exigences spécifiques concernant les temps d'arrêt et que vous devez élire un nouveau maître dans un court laps de temps.
Pour plus de détails sur le fonctionnement de ClusterControl avec le basculement automatique dans PostgreSQL et MySQL, consultez nos blogs précédents intitulés "Basculement pour la réplication PostgreSQL 101" et "Basculement automatique de la réplication MySQL - Nouveau dans ClusterControl 1.4".
Conclusion
Le basculement automatisé est une fonctionnalité précieuse, en particulier pour les entreprises qui nécessitent des opérations 24h/24 et 7j/7 avec un temps d'arrêt minimal. L'entreprise doit définir le degré de contrôle accordé au processus d'automatisation lors d'interruptions imprévues. Une solution à haute disponibilité telle que ClusterControl offre un niveau d'interaction personnalisable dans le traitement du basculement. Pour certaines organisations, le basculement automatisé peut ne pas être une option, même si l'interaction de l'utilisateur pendant le basculement peut prendre du temps et avoir un impact sur le RTO. L'hypothèse est qu'il est trop risqué si le basculement automatisé ne fonctionne pas correctement ou, pire encore, s'il entraîne des données erronées et partiellement manquantes (bien que l'on puisse affirmer qu'un humain peut également commettre des erreurs désastreuses entraînant des conséquences similaires). Ceux qui préfèrent garder un contrôle étroit sur leur base de données peuvent choisir d'ignorer le basculement automatisé et d'utiliser un processus manuel à la place. Un tel processus prend plus de temps, mais il permet à un administrateur expérimenté d'évaluer l'état d'un système et de prendre des mesures correctives en fonction de ce qui s'est passé.