Dès que vous commencez à utiliser un serveur de base de données et que votre utilisation augmente, vous êtes exposé à de nombreux types de problèmes techniques, à une dégradation des performances et à des dysfonctionnements de la base de données. Chacun de ces problèmes pourrait entraîner des problèmes beaucoup plus importants, tels qu'une panne catastrophique ou une perte de données. C'est comme une réaction en chaîne, où une chose peut en entraîner une autre, causant de plus en plus de problèmes. Des contre-mesures proactives doivent être prises pour que vous disposiez d'un environnement stable le plus longtemps possible.
Dans cet article de blog, nous allons examiner un ensemble de fonctionnalités intéressantes offertes par ClusterControl qui peuvent grandement nous aider à dépanner et à résoudre nos problèmes de base de données MySQL lorsqu'ils se produisent.
Alarmes et notifications de la base de données
Pour tous les événements indésirables, ClusterControl enregistrera tout sous Alarmes, accessible sur l'activité (menu supérieur) de la page ClusterControl. C'est généralement la première étape pour commencer le dépannage en cas de problème. À partir de cette page, nous pouvons avoir une idée de ce qui se passe réellement avec notre cluster de bases de données :
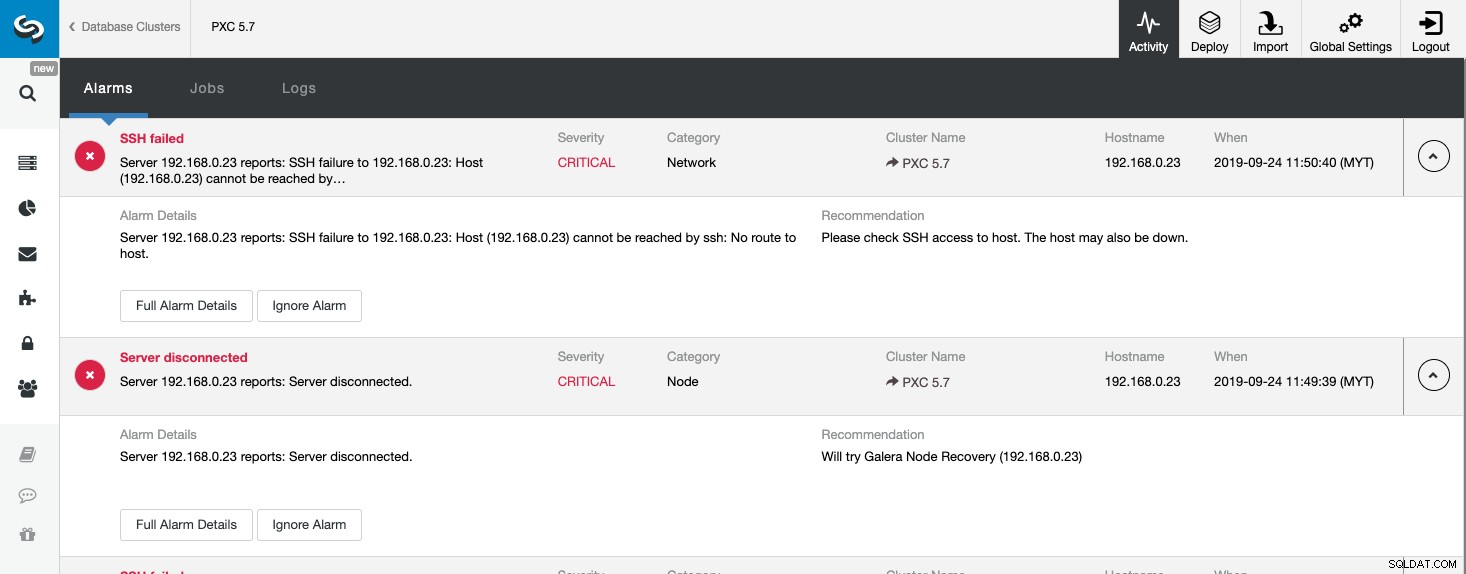
La capture d'écran ci-dessus montre un exemple d'événement de serveur inaccessible, avec une gravité CRITICAL , détecté par deux composants, Network et Node. Si vous avez configuré le paramètre de notifications par e-mail, vous devriez obtenir une copie de ces alarmes dans votre boîte aux lettres.
Lorsque vous cliquez sur "Détails complets de l'alarme", vous pouvez obtenir les détails importants de l'alarme tels que le nom d'hôte, l'horodatage, le nom du cluster, etc. Il fournit également la prochaine étape recommandée à suivre. Vous pouvez également envoyer cette alarme sous forme d'e-mail à d'autres destinataires configurés dans les paramètres de notification par e-mail.
Vous pouvez également choisir de désactiver une alarme en cliquant sur le bouton "Ignorer l'alarme" et elle n'apparaîtra plus dans la liste. Ignorer une alarme peut être utile si vous avez une alarme de faible gravité et savez comment la gérer ou la contourner. Par exemple, si ClusterControl détecte un index en double dans votre base de données, ce qui, dans certains cas, serait nécessaire pour vos applications héritées.
En regardant cette page, nous pouvons obtenir une compréhension immédiate de ce qui se passe avec notre cluster de bases de données et de la prochaine étape à faire pour résoudre le problème. Comme dans ce cas, l'un des nœuds de la base de données est tombé en panne et est devenu inaccessible via SSH à partir de l'hôte ClusterControl. Même un administrateur système débutant saura désormais quoi faire si cette alarme apparaît.
Fichiers journaux de la base de données centralisée
C'est ici que nous pouvons explorer ce qui n'allait pas avec notre serveur de base de données. Sous ClusterControl -> Journaux -> Journaux système, vous pouvez voir tous les fichiers journaux liés au cluster de bases de données. Comme pour le cluster de base de données basé sur MySQL, ClusterControl extrait le journal ProxySQL, le journal des erreurs MySQL et les journaux de sauvegarde :
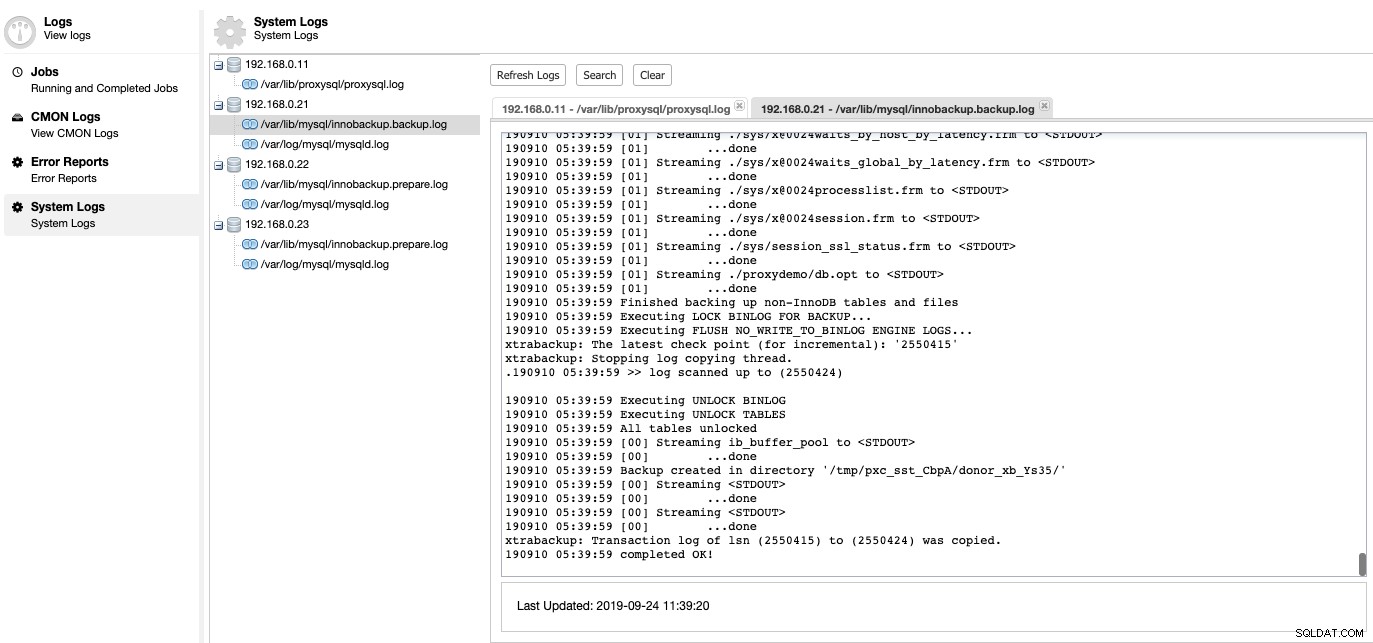
Cliquez sur "Actualiser le journal" pour récupérer le dernier journal de tous les hôtes accessibles à ce moment précis. Si un nœud est inaccessible, ClusterControl affichera toujours la connexion obsolète puisque ces informations sont stockées dans la base de données CMON. Par défaut, ClusterControl continue de récupérer les journaux système toutes les 10 minutes, configurable sous Paramètres -> Intervalle de journal.
ClusterControl déclenchera la tâche pour extraire le dernier journal de chaque serveur, comme indiqué dans la tâche "Collect Logs" suivante :
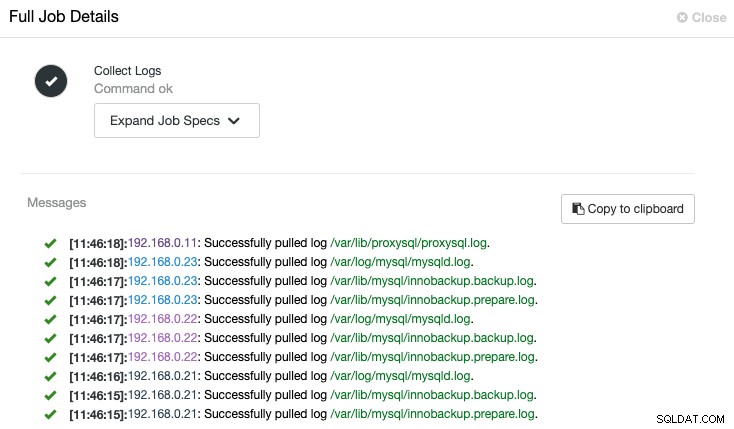
Une vue centralisée du fichier journal nous permet d'avoir une compréhension plus rapide de ce qui s'est passé mauvais. Pour un cluster de bases de données qui implique généralement plusieurs nœuds et niveaux, cette fonctionnalité améliorera considérablement la lecture des journaux où un administrateur système peut comparer ces journaux côte à côte et identifier les événements critiques, réduisant ainsi le temps total de dépannage.
Console SSH Web
ClusterControl fournit une console SSH basée sur le Web afin que vous puissiez accéder au serveur de base de données directement via l'interface utilisateur de ClusterControl (car l'utilisateur SSH est configuré pour se connecter aux hôtes de la base de données). À partir de là, nous pouvons recueillir beaucoup plus d'informations, ce qui nous permet de résoudre le problème encore plus rapidement. Tout le monde sait qu'en cas de problème de base de données sur le système de production, chaque seconde d'indisponibilité compte.
Pour accéder à la console SSH via le Web, sélectionnez simplement les nœuds sous Nœuds -> Actions de nœud -> Console SSH, ou cliquez simplement sur l'icône d'engrenage pour un raccourci :
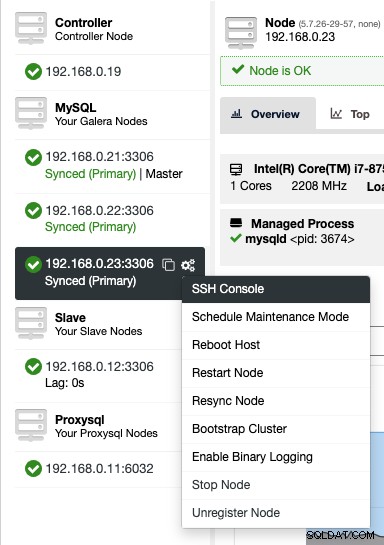
En raison de problèmes de sécurité pouvant être imposés avec cette fonctionnalité, en particulier pour plusieurs -utilisateur ou environnement multi-locataire, on peut le désactiver en allant sur /var/www/html/clustercontrol/bootstrap.php sur le serveur ClusterControl et définir la constante suivante sur false :
define('SSH_ENABLED', false);Actualisez la page de l'interface utilisateur de ClusterControl pour charger les nouvelles modifications.
Problèmes de performances de la base de données
Outre les fonctionnalités de surveillance et de tendance, ClusterControl vous envoie de manière proactive diverses alarmes et conseils liés aux performances de la base de données, par exemple :
- Utilisation excessive :ressource qui dépasse certains seuils tels que le processeur, la mémoire, l'utilisation de l'échange et l'espace disque.
- Dégradation du cluster :partitionnement du cluster et du réseau.
- Dérive de l'heure du système :différence d'heure entre tous les nœuds du cluster (y compris le nœud ClusterControl).
- Divers autres conseillers liés à MySQL :
- Réplication :délai de réplication, expiration du journal binaire, emplacement et croissance
- Galera - Méthode SST, analyse du fichier journal GRA, vérificateur d'adresse de cluster
- Vérification du schéma :existence de la table non transactionnelle sur Galera Cluster.
- Connexions - Rapport de fils connectés
- InnoDB - Taux de pages sales, croissance du fichier journal InnoDB
- Requêtes lentes :par défaut, ClusterControl déclenche une alarme s'il trouve une requête en cours d'exécution pendant plus de 30 secondes. Ceci est bien sûr configurable sous Paramètres -> Configuration d'exécution -> Requête longue.
- Interblocages :impasse des transactions InnoDB et impasse Galera.
- Index :clés en double, table sans clés primaires.
Consultez la page Conseillers sous Performance -> Conseillers pour obtenir les détails des choses qui peuvent être améliorées comme suggéré par ClusterControl. Pour chaque conseiller, il fournit des justifications et des conseils comme indiqué dans l'exemple suivant pour le conseiller "Vérification de l'utilisation de l'espace disque" :
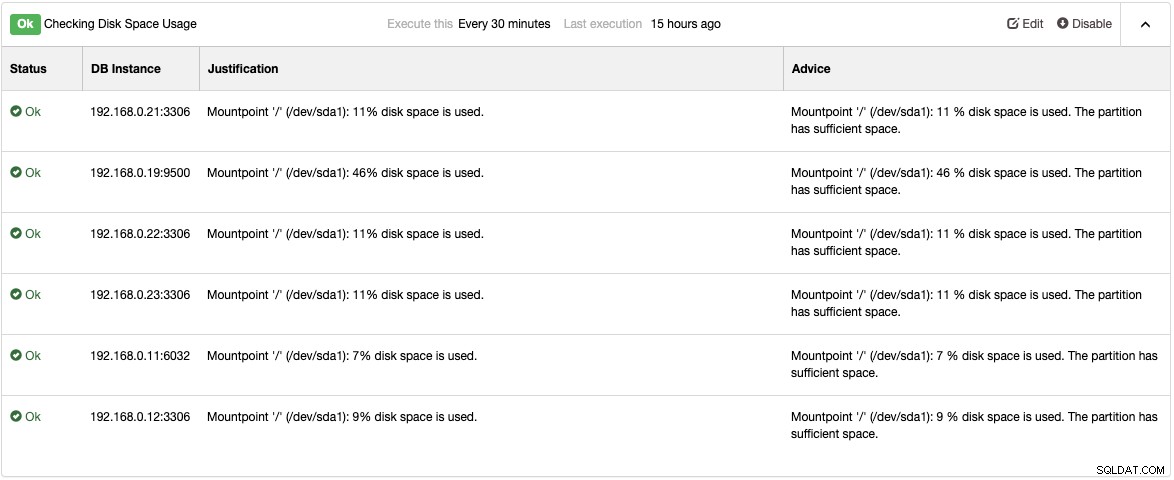
Lorsqu'un problème de performances survient, vous obtenez un "avertissement" (jaune) ou Statut "Critique" (rouge) sur ces conseillers. Un réglage supplémentaire est généralement nécessaire pour résoudre le problème. Les conseillers déclenchent des alarmes, ce qui signifie que les utilisateurs recevront une copie de ces alarmes dans la boîte aux lettres si les notifications par e-mail sont configurées en conséquence. Pour chaque alarme déclenchée par ClusterControl ou ses conseillers, les utilisateurs recevront également un e-mail si l'alarme a été effacée. Ceux-ci sont préconfigurés dans ClusterControl et ne nécessitent aucune configuration initiale. Une personnalisation plus poussée est toujours possible sous Gérer -> Developer Studio. Vous pouvez consulter cet article de blog sur la façon d'écrire votre propre conseiller.
ClusterControl fournit également une page dédiée aux performances de la base de données sous ClusterControl -> Performance. Il fournit toutes sortes d'informations sur la base de données en suivant les meilleures pratiques telles que la vue centralisée de l'état de la base de données, des variables, de l'état InnoDB, de l'analyseur de schéma et des journaux de transactions. Celles-ci sont assez explicites et simples à comprendre.
Pour les performances des requêtes, vous pouvez inspecter les principales requêtes et les requêtes aberrantes, où ClusterControl met en évidence les requêtes dont les performances diffèrent considérablement de leur requête moyenne. Nous avons couvert ce sujet en détail dans cet article de blog, MySQL Query Performance Tuning.
Rapports d'erreurs de base de données
ClusterControl est livré avec un outil de génération de rapport d'erreurs, pour collecter des informations de débogage sur votre cluster de base de données afin d'aider à comprendre la situation et l'état actuels. Pour générer un rapport d'erreur, allez simplement dans ClusterControl -> Logs -> Error Reports -> Create Error Report :
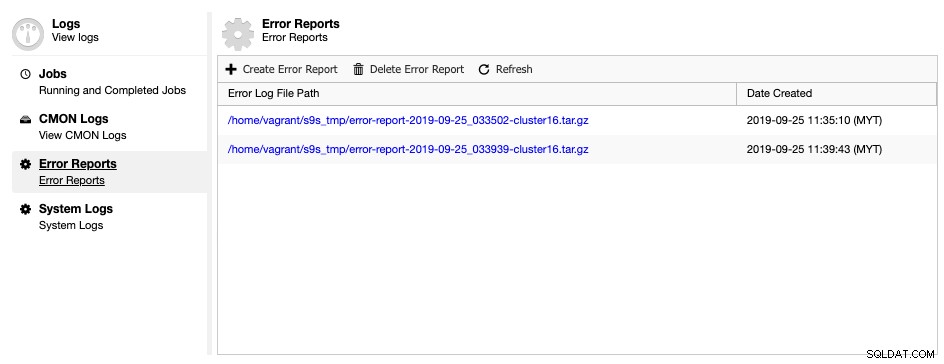
Le rapport d'erreur généré peut être téléchargé à partir de cette page une fois prêt. Ce rapport généré sera au format TAR ball (tar.gz) et vous pourrez le joindre à une demande d'assistance. Étant donné que le ticket d'assistance est limité à 10 Mo de taille de fichier, si la taille de l'archive tar est supérieure à cela, vous pouvez la télécharger sur un lecteur cloud et ne partager avec nous le lien de téléchargement qu'avec l'autorisation appropriée. Vous pouvez le supprimer plus tard une fois que nous aurons déjà reçu le fichier. Vous pouvez également générer le rapport d'erreur via la ligne de commande comme expliqué dans la page de documentation du rapport d'erreur.
En cas de panne, nous vous recommandons vivement de générer plusieurs rapports d'erreur pendant et juste après la panne. Ces rapports seront très utiles pour essayer de comprendre ce qui s'est passé, les conséquences de la panne, et pour vérifier que le cluster est en fait de retour à l'état opérationnel après un événement désastreux.
Conclusion
La surveillance proactive de ClusterControl, associée à un ensemble de fonctionnalités de dépannage, fournit une plate-forme efficace permettant aux utilisateurs de résoudre tout type de problème de base de données MySQL. L'ancienne méthode de dépannage où l'on doit ouvrir plusieurs sessions SSH pour accéder à plusieurs hôtes et exécuter plusieurs commandes à plusieurs reprises afin d'identifier la cause première est révolue depuis longtemps.
Si les fonctionnalités mentionnées ci-dessus ne vous aident pas à résoudre le problème ou à résoudre le problème de la base de données, vous contactez toujours l'équipe d'assistance de Manynines pour vous aider. Nos experts techniques dédiés 24/7/365 sont disponibles pour répondre à votre demande à tout moment. Notre délai moyen de première réponse est généralement inférieur à 30 minutes.