De nos jours, il est courant de voir une grande quantité de données dans la base de données d'une entreprise, mais selon la taille, cela peut être difficile à gérer et les performances peuvent être affectées lors d'un trafic élevé si nous ne le configurons pas ou ne l'implémentons pas correctement . En général, si nous avons une énorme base de données et que nous voulons avoir un temps de réponse faible, nous voudrons la mettre à l'échelle. PostgreSQL n'est pas l'exception à ce point. Il existe de nombreuses approches disponibles pour mettre à l'échelle PostgreSQL, mais d'abord, apprenons ce qu'est la mise à l'échelle.
L'évolutivité est la propriété d'un système/d'une base de données pour gérer un nombre croissant de demandes en ajoutant des ressources.
Les raisons de cette quantité de demandes peuvent être temporelles, par exemple, si nous lançons une remise sur une vente, ou permanentes, pour une augmentation de clients ou d'employés. Dans tous les cas, nous devrions pouvoir ajouter ou supprimer des ressources pour gérer ces changements en fonction des demandes ou de l'augmentation du trafic.
Dans ce blog, nous verrons comment nous pouvons faire évoluer notre base de données PostgreSQL et quand nous devons le faire.
Mise à l'échelle horizontale vs mise à l'échelle verticale
Il existe deux façons principales de faire évoluer notre base de données...
- Mise à l'échelle horizontale (scale-out) :elle est effectuée en ajoutant plus de nœuds de base de données en créant ou en augmentant un cluster de base de données.
- Mise à l'échelle verticale (mise à l'échelle) :elle est effectuée en ajoutant plus de ressources matérielles (processeur, mémoire, disque) à un nœud de base de données existant.
Pour la mise à l'échelle horizontale, nous pouvons ajouter plus de nœuds de base de données en tant que nœuds esclaves. Cela peut nous aider à améliorer les performances de lecture en équilibrant le trafic entre les nœuds. Dans ce cas, nous devrons ajouter un équilibreur de charge pour distribuer le trafic au bon nœud en fonction de la politique et de l'état du nœud.
Pour éviter qu'un seul point de défaillance n'ajoute un seul équilibreur de charge, nous devrions envisager d'ajouter deux nœuds d'équilibreur de charge ou plus et d'utiliser un outil comme "Keepalived", pour assurer la disponibilité.
Comme PostgreSQL n'a pas de support multi-maître natif, si nous voulons l'implémenter pour améliorer les performances d'écriture, nous devrons utiliser un outil externe pour cette tâche.
Pour la mise à l'échelle verticale, il peut être nécessaire de modifier certains paramètres de configuration pour permettre à PostgreSQL d'utiliser une ressource matérielle nouvelle ou meilleure. Voyons certains de ces paramètres dans la documentation de PostgreSQL.
- work_mem :spécifie la quantité de mémoire à utiliser par les opérations de tri internes et les tables de hachage avant d'écrire dans les fichiers de disque temporaires. Plusieurs sessions en cours d'exécution peuvent effectuer de telles opérations simultanément, de sorte que la mémoire totale utilisée peut être plusieurs fois supérieure à la valeur de work_mem.
- maintenance_work_mem :spécifie la quantité maximale de mémoire à utiliser par les opérations de maintenance, telles que VACUUM, CREATE INDEX et ALTER TABLE ADD FOREIGN KEY. Des paramètres plus importants peuvent améliorer les performances de nettoyage et de restauration des vidages de base de données.
- autovacuum_work_mem :spécifie la quantité maximale de mémoire à utiliser par chaque processus de travail autovacuum.
- autovacuum_max_workers :spécifie le nombre maximal de processus d'autovacuum pouvant être exécutés à tout moment.
- max_worker_processes :définit le nombre maximal de processus d'arrière-plan que le système peut prendre en charge. Spécifiez la limite du processus, comme l'aspiration, les points de contrôle et d'autres tâches de maintenance.
- max_parallel_workers :définit le nombre maximal de nœuds de calcul que le système peut prendre en charge pour les opérations parallèles. Les travailleurs parallèles sont extraits du pool de processus de travail établi par le paramètre précédent.
- max_parallel_maintenance_workers :définit le nombre maximal de travailleurs parallèles pouvant être démarrés par une seule commande d'utilitaire. Actuellement, la seule commande d'utilitaire parallèle qui prend en charge l'utilisation de travailleurs parallèles est CREATE INDEX, et uniquement lors de la construction d'un index B-tree.
- effective_cache_size :définit l'hypothèse du planificateur concernant la taille effective du cache disque disponible pour une seule requête. Ceci est pris en compte dans les estimations du coût d'utilisation d'un indice; une valeur plus élevée augmente la probabilité d'utiliser des analyses d'index, une valeur inférieure augmente la probabilité d'utiliser des analyses séquentielles.
- shared_buffers :définit la quantité de mémoire utilisée par le serveur de base de données pour les tampons de mémoire partagée. Des paramètres nettement supérieurs au minimum sont généralement nécessaires pour obtenir de bonnes performances.
- temp_buffers :définit le nombre maximal de tampons temporaires utilisés par chaque session de base de données. Ce sont des tampons locaux de session utilisés uniquement pour accéder aux tables temporaires.
- effective_io_concurrency :définit le nombre d'opérations d'E/S de disque simultanées qui, selon PostgreSQL, peuvent être exécutées simultanément. L'augmentation de cette valeur augmentera le nombre d'opérations d'E/S que toute session PostgreSQL individuelle tentera d'initier en parallèle. Actuellement, ce paramètre n'affecte que les analyses de tas bitmap.
- max_connections :détermine le nombre maximal de connexions simultanées au serveur de base de données. L'augmentation de ce paramètre permet à PostgreSQL d'exécuter plus de processus backend simultanément.
À ce stade, il y a une question que nous devons nous poser. Comment pouvons-nous savoir si nous devons faire évoluer notre base de données et comment pouvons-nous connaître la meilleure façon de le faire ?
Surveillance
La mise à l'échelle de notre base de données PostgreSQL est un processus complexe, nous devons donc vérifier certaines métriques pour pouvoir déterminer la meilleure stratégie pour la mettre à l'échelle.
Nous pouvons surveiller l'utilisation du processeur, de la mémoire et du disque pour déterminer s'il y a un problème de configuration ou si, en fait, nous devons mettre à l'échelle notre base de données. Par exemple, si nous constatons une charge de serveur élevée mais que l'activité de la base de données est faible, il n'est probablement pas nécessaire de la mettre à l'échelle, nous n'avons qu'à vérifier les paramètres de configuration pour qu'ils correspondent à nos ressources matérielles.
Vérifier l'espace disque utilisé par le nœud PostgreSQL par base de données peut nous aider à confirmer si nous avons besoin de plus de disque ou même d'un partitionnement de table. Pour vérifier l'espace disque utilisé par une base de données/table, nous pouvons utiliser une fonction PostgreSQL comme pg_database_size ou pg_table_size.
Du côté de la base de données, nous devrions vérifier
- Nombre de connexions
- Exécuter des requêtes
- Utilisation de l'index
- Ballonnage
- Délai de réplication
Il pourrait s'agir de mesures claires pour confirmer si la mise à l'échelle de notre base de données est nécessaire.
ClusterControl en tant que système de mise à l'échelle et de surveillance
ClusterControl peut nous aider à faire face aux deux méthodes de mise à l'échelle que nous avons vues précédemment et à surveiller toutes les métriques nécessaires pour confirmer l'exigence de mise à l'échelle. Voyons comment...
Si vous n'utilisez pas encore ClusterControl, vous pouvez l'installer et déployer ou importer votre base de données PostgreSQL actuelle en sélectionnant l'option "Importer" et suivre les étapes, pour profiter de toutes les fonctionnalités de ClusterControl telles que les sauvegardes, le basculement automatique, les alertes, la surveillance, et plus encore.
Mise à l'échelle horizontale
Pour la mise à l'échelle horizontale, si nous allons dans les actions de cluster et sélectionnons "Ajouter un esclave de réplication", nous pouvons soit créer un nouveau réplica à partir de zéro, soit ajouter une base de données PostgreSQL existante en tant que réplica.
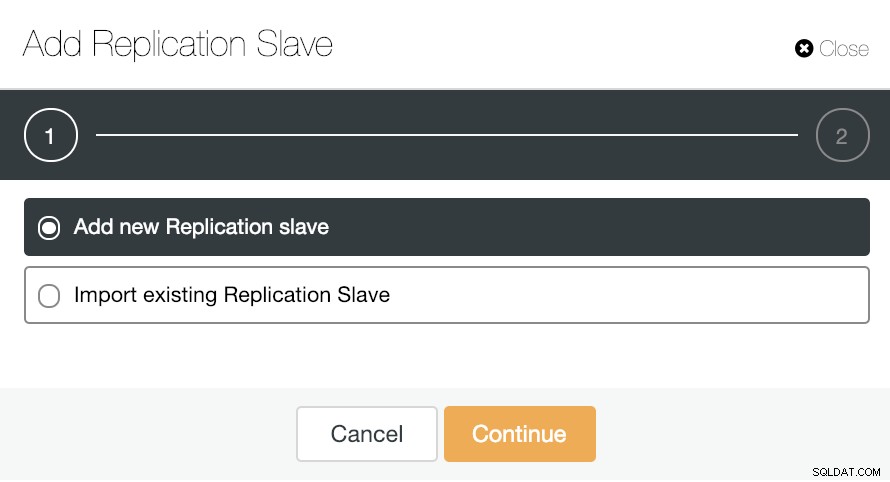
Voyons comment l'ajout d'un nouvel esclave de réplication peut être une tâche vraiment facile.
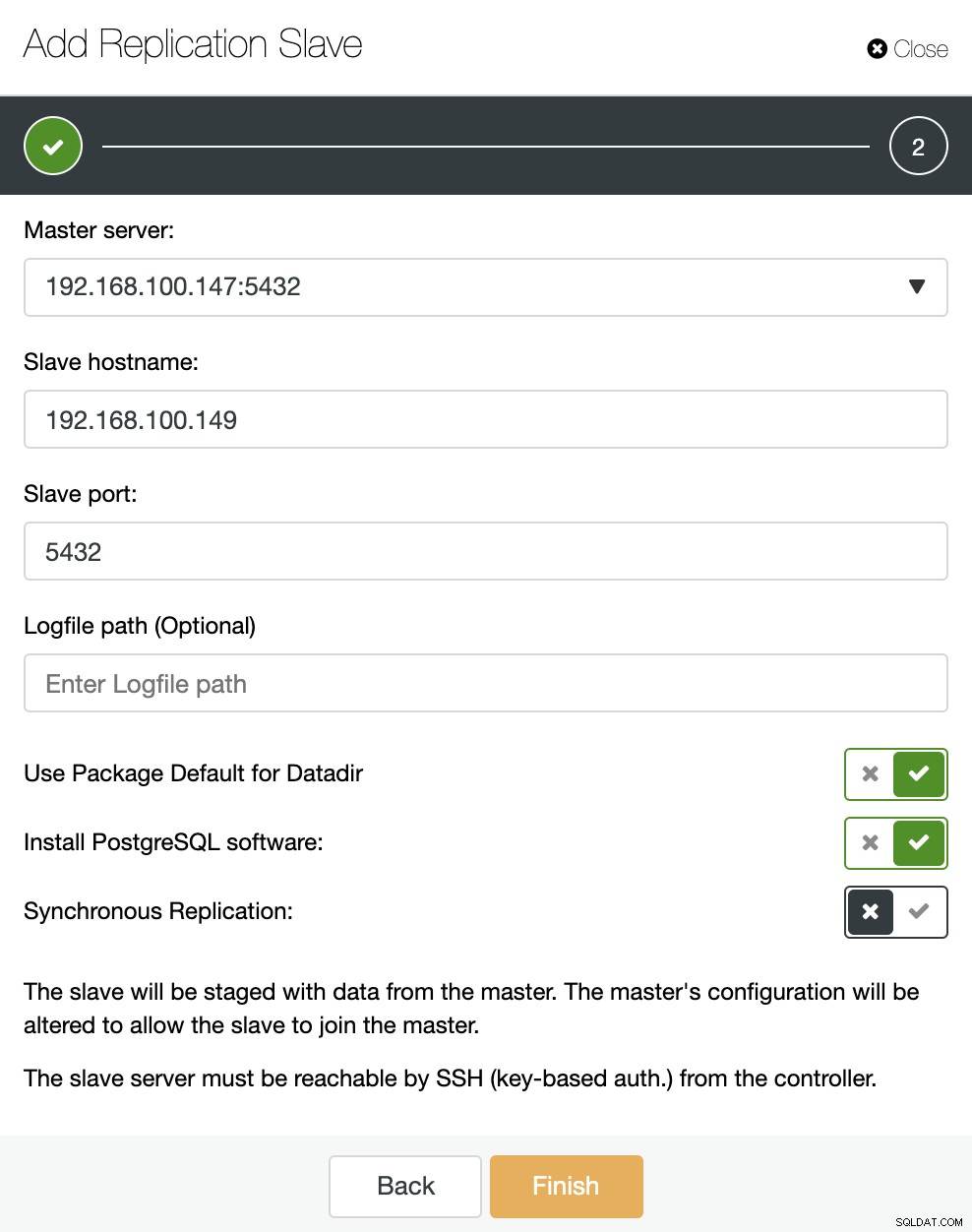
Comme vous pouvez le voir sur l'image, nous n'avons qu'à choisir notre serveur maître, entrer l'adresse IP de notre nouveau serveur esclave et le port de la base de données. Ensuite, nous pouvons choisir si nous voulons que ClusterControl installe le logiciel pour nous et si l'esclave de réplication doit être synchrone ou asynchrone.
De cette façon, nous pouvons ajouter autant de répliques que nous le souhaitons et répartir le trafic de lecture entre elles à l'aide d'un équilibreur de charge, que nous pouvons également implémenter avec ClusterControl.
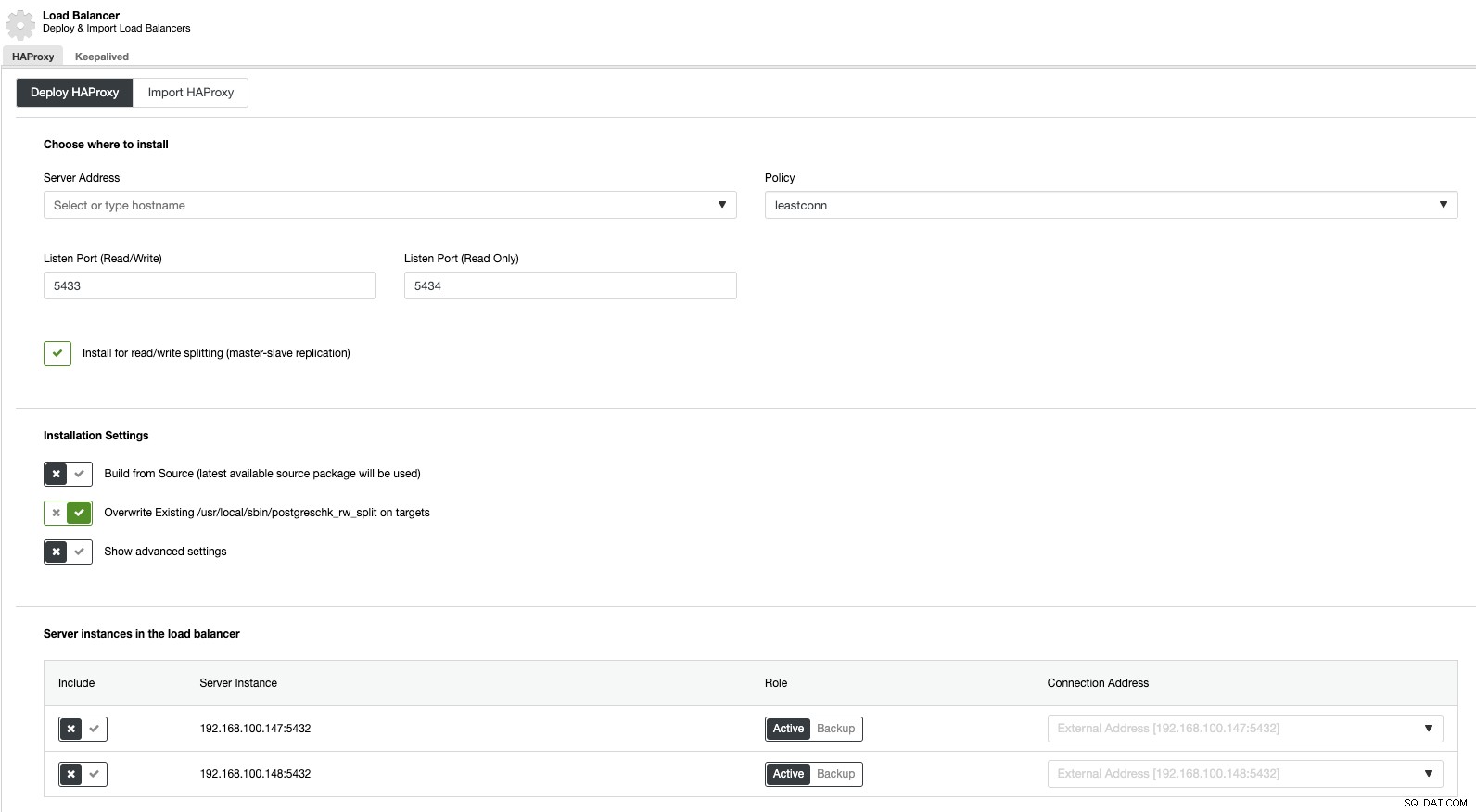
Maintenant, si nous allons dans les actions de cluster et sélectionnons "Ajouter un équilibreur de charge", nous pouvons déployer un nouvel équilibreur de charge HAProxy ou en ajouter un existant.
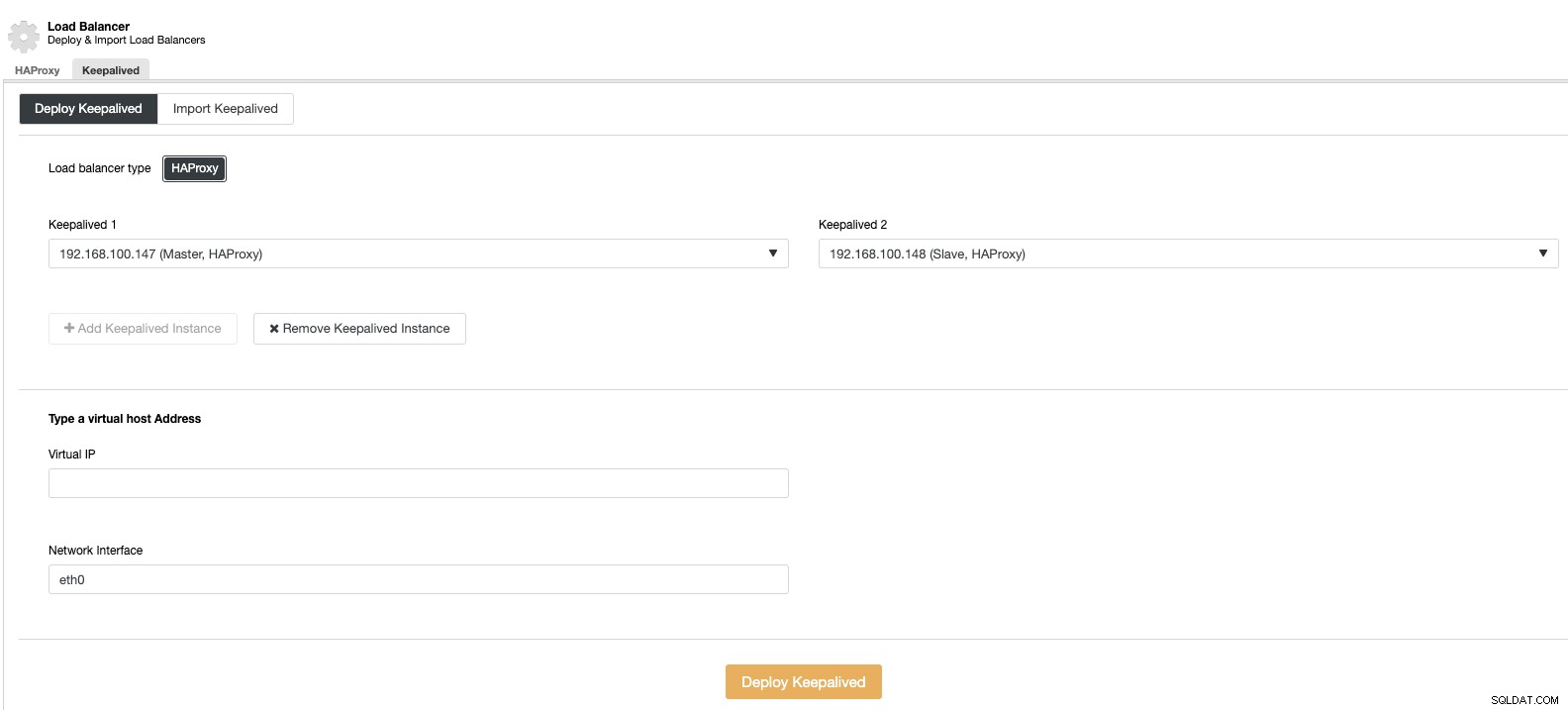
Et puis, dans la même section d'équilibrage de charge, nous pouvons ajouter un service Keepalived exécuté sur les nœuds d'équilibrage de charge pour améliorer notre environnement de haute disponibilité.
Échelle verticale
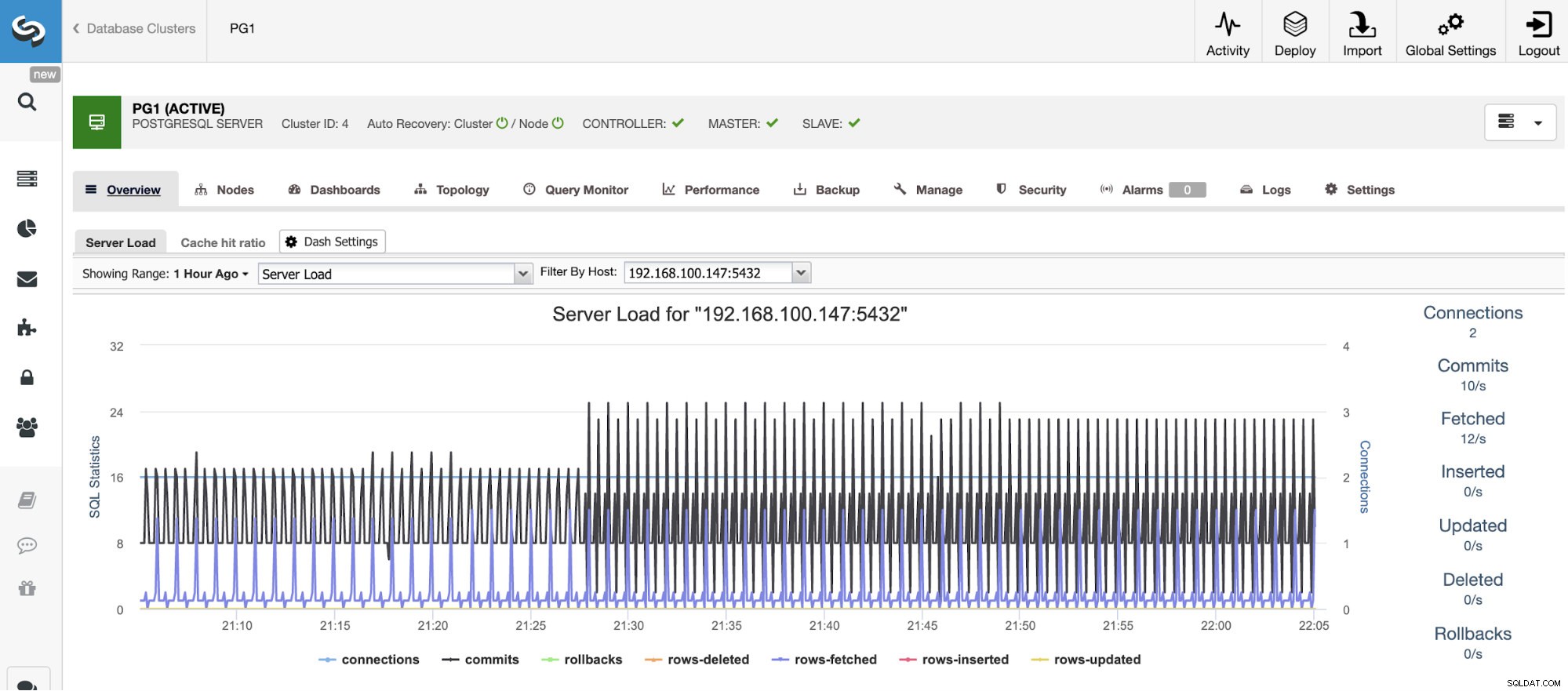
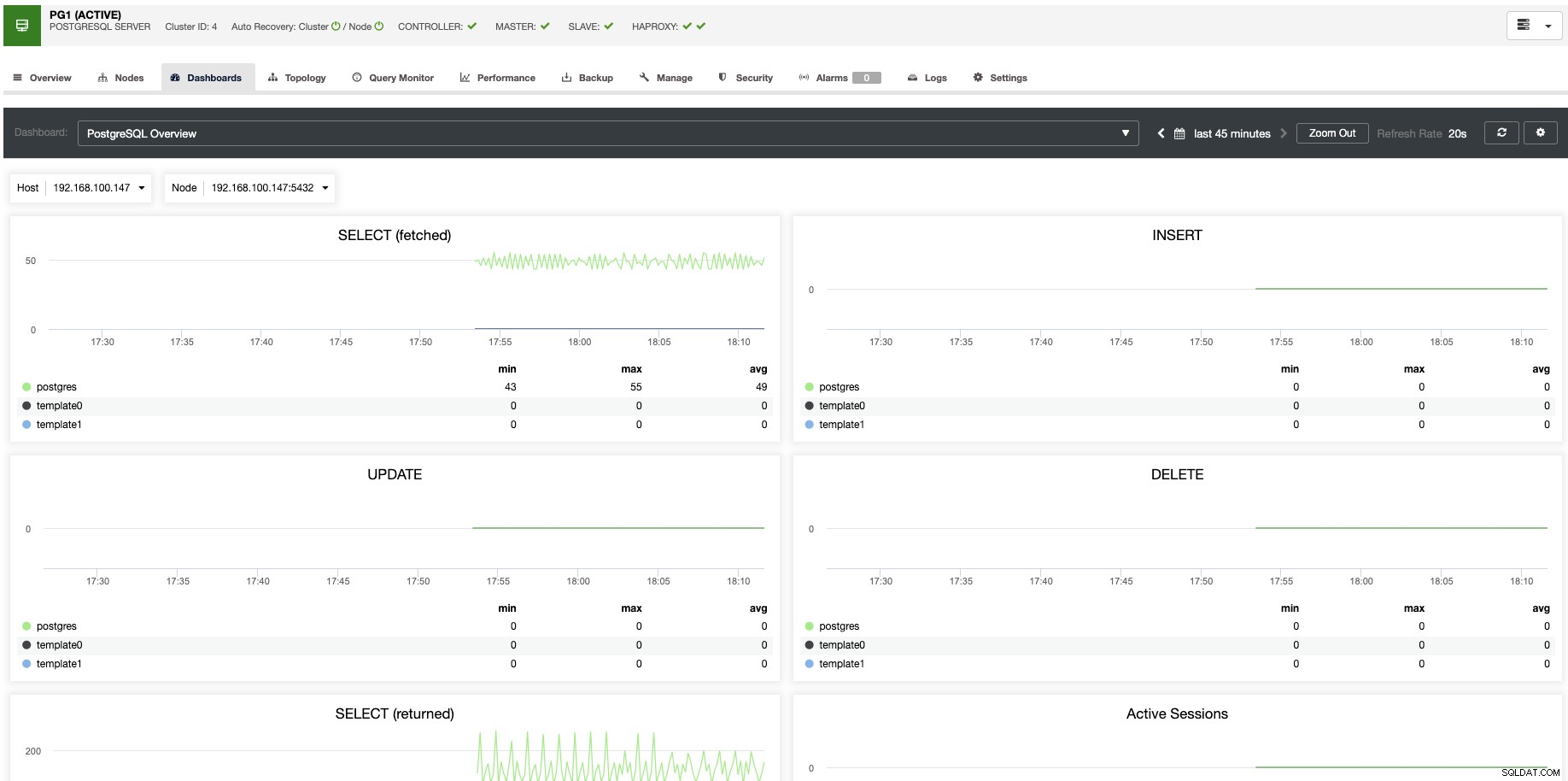
Pour la mise à l'échelle verticale, avec ClusterControl, nous pouvons surveiller nos nœuds de base de données à la fois du système d'exploitation et du côté de la base de données. Nous pouvons vérifier certaines mesures telles que l'utilisation du processeur, la mémoire, les connexions, les principales requêtes, les requêtes en cours d'exécution, etc. Nous pouvons également activer la section Tableau de bord, ce qui nous permet de voir les métriques de manière plus détaillée et plus conviviale nos métriques.
Depuis ClusterControl, vous pouvez également effectuer différentes tâches de gestion comme Redémarrer l'hôte, Reconstruire l'esclave de réplication ou Promouvoir l'esclave, en un seul clic.
Conclusion
La mise à l'échelle des bases de données PostgreSQL peut être une tâche fastidieuse. Nous devons savoir ce dont nous avons besoin pour évoluer et quelle est la meilleure façon de le faire. En fin de compte, la gestion et la mise à l'échelle manuelles des clusters deviennent assez lourdes au-delà d'un certain point, donc la plupart se tournent vers des outils comme les nôtres.
Si vous choisissez la route manuelle, vérifiez quand envisager d'ajouter un nœud supplémentaire à votre cluster. Vous voulez éviter les tracas ? Évaluez ClusterControl gratuitement pendant 30 jours pour voir comment ses fonctionnalités rendent la gestion de l'open source à grande échelle simple et efficace.
Quelle que soit la manière dont vous souhaitez gérer et faire évoluer vos bases de données, suivez-nous sur Twitter ou LinkedIn, ou abonnez-vous à notre newsletter pour obtenir les dernières nouvelles et les meilleures pratiques en matière de gestion d'infrastructure de base de données open source, et à bientôt !