ProxySQL se situe généralement entre les niveaux application et base de données, dans ce que l'on appelle le niveau proxy inverse. Lorsque vos conteneurs d'applications sont orchestrés et gérés par Kubernetes, vous pouvez utiliser ProxySQL devant vos serveurs de base de données.
Dans cet article, nous allons vous montrer comment exécuter ProxySQL sur Kubernetes en tant que conteneur d'assistance dans un pod. Nous allons utiliser Wordpress comme exemple d'application. Le service de données est fourni par notre réplication MySQL à deux nœuds, déployée à l'aide de ClusterControl et située en dehors du réseau Kubernetes sur une infrastructure sans système d'exploitation, comme illustré dans le schéma suivant :
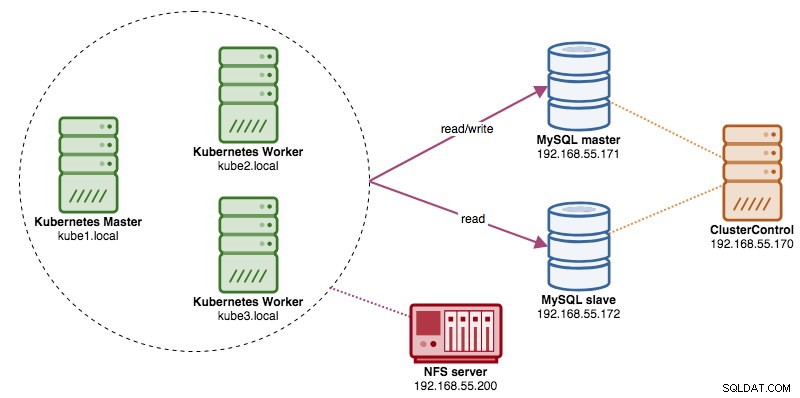
Image Docker ProxySQL
Dans cet exemple, nous allons utiliser l'image ProxySQL Docker maintenue par Manynines, une image grand public conçue pour une utilisation polyvalente. L'image est livrée sans script de point d'entrée et prend en charge Galera Cluster (en plus de la prise en charge intégrée de la réplication MySQL), où un script supplémentaire est requis à des fins de vérification de l'état.
En gros, pour exécuter un conteneur ProxySQL, il suffit d'exécuter la commande suivante :
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlCette image vous recommande de lier un fichier de configuration ProxySQL au point de montage, /etc/proxysql.cnf, bien que vous puissiez ignorer cela et le configurer ultérieurement à l'aide de la console d'administration ProxySQL. Des exemples de configurations sont fournis sur la page Docker Hub ou la page Github.
ProxySQL sur Kubernetes
La conception de l'architecture ProxySQL est un sujet subjectif et dépend fortement du placement des conteneurs d'application et de base de données ainsi que du rôle de ProxySQL lui-même. ProxySQL ne se contente pas d'acheminer les requêtes, il peut également être utilisé pour réécrire et mettre en cache les requêtes. Des accès au cache efficaces peuvent nécessiter une configuration personnalisée spécialement adaptée à la charge de travail de la base de données de l'application.
Idéalement, nous pouvons configurer ProxySQL pour qu'il soit géré par Kubernetes avec deux configurations :
- ProxySQL en tant que service Kubernetes (déploiement centralisé).
- ProxySQL en tant que conteneur d'assistance dans un pod (déploiement distribué).
La première option est assez simple, où nous créons un pod ProxySQL et y attachons un service Kubernetes. Les applications se connecteront ensuite au service ProxySQL via la mise en réseau sur les ports configurés. La valeur par défaut est 6033 pour le port à équilibrage de charge MySQL et 6032 pour le port d'administration ProxySQL. Ce déploiement sera couvert dans le prochain article de blog.
La deuxième option est un peu différente. Kubernetes a un concept appelé "pod". Vous pouvez avoir un ou plusieurs conteneurs par pod, ceux-ci sont relativement étroitement couplés. Le contenu d'un pod est toujours colocalisé et coplanifié, et exécuté dans un contexte partagé. Un pod est la plus petite unité de conteneur gérable dans Kubernetes.
Les deux déploiements peuvent être distingués facilement en regardant le schéma suivant :
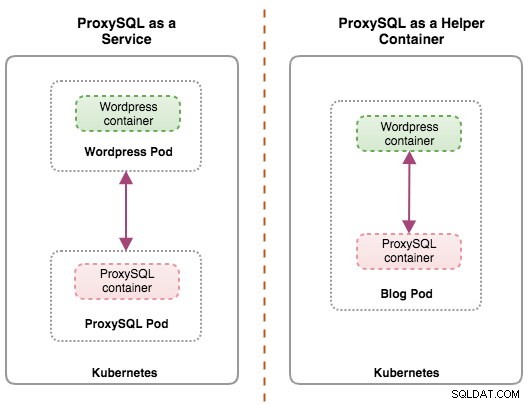
La principale raison pour laquelle les pods peuvent avoir plusieurs conteneurs est de prendre en charge les applications d'assistance qui assistent une application principale. Des exemples typiques d'applications d'assistance sont les extracteurs de données, les poussoirs de données et les proxys. Les applications auxiliaires et principales doivent souvent communiquer entre elles. Cela se fait généralement via un système de fichiers partagé, comme indiqué dans cet exercice, ou via l'interface réseau de bouclage, localhost. Un exemple de ce modèle est un serveur Web avec un programme d'assistance qui interroge un référentiel Git pour de nouvelles mises à jour.
Ce billet de blog couvrira la deuxième configuration :exécuter ProxySQL en tant que conteneur d'assistance dans un pod.
ProxySQL en tant qu'assistant dans un pod
Dans cette configuration, nous exécutons ProxySQL en tant que conteneur d'assistance pour notre conteneur Wordpress. Le schéma suivant illustre notre architecture de haut niveau :
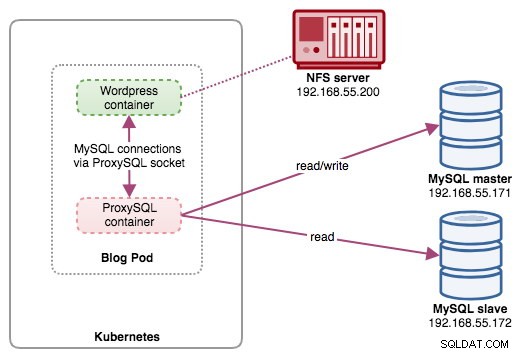
Dans cette configuration, le conteneur ProxySQL est étroitement lié au conteneur Wordpress, et nous l'avons nommé pod "blog". Si la replanification se produit, par exemple, le nœud de travail Kubernetes tombe en panne, ces deux conteneurs seront toujours replanifiés ensemble comme une unité logique sur le prochain hôte disponible. Pour conserver le contenu des conteneurs d'application persistant sur plusieurs nœuds, nous devons utiliser un système de fichiers en cluster ou distant, qui dans ce cas est NFS.
Le rôle de ProxySQL est de fournir une couche d'abstraction de base de données au conteneur d'application. Étant donné que nous exécutons une réplication MySQL à deux nœuds en tant que service de base de données principal, le fractionnement lecture-écriture est essentiel pour maximiser la consommation de ressources sur les deux serveurs MySQL. ProxySQL excelle dans ce domaine et ne nécessite que peu ou pas de modifications de l'application.
L'exécution de ProxySQL dans cette configuration présente un certain nombre d'autres avantages :
- Amenez la capacité de mise en cache des requêtes au plus près de la couche d'application exécutée dans Kubernetes.
- Mise en œuvre sécurisée en se connectant via le fichier de socket ProxySQL UNIX. C'est comme un tuyau que le serveur et les clients peuvent utiliser pour se connecter et échanger des requêtes et des données.
- Niveau de proxy inverse distribué avec architecture sans partage
- Moins de charge réseau grâce à la mise en œuvre du "saut de mise en réseau".
- Approche de déploiement sans état à l'aide de Kubernetes ConfigMaps.
Préparer la base de données
Créez la base de données wordpress et l'utilisateur sur le maître et attribuez-leur le privilège correct :
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Créez également l'utilisateur de surveillance ProxySQL :
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Ensuite, rechargez le tableau des subventions :
mysql-master> FLUSH PRIVILEGES;Préparer le pod
Maintenant, copiez-collez les lignes suivantes dans un fichier appelé blog-deployment.yml sur l'hôte où kubectl est configuré :
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Le fichier YAML comporte de nombreuses lignes et ne regardons que la partie intéressante. La première section :
apiVersion: apps/v1
kind: DeploymentLa première ligne est l'apiVersion. Notre cluster Kubernetes s'exécute sur la v1.12, nous devons donc nous référer à la documentation de l'API Kubernetes v1.12 et suivre la déclaration des ressources en fonction de cette API. Le suivant est le genre, qui indique quel type de ressource que nous voulons déployer. Déploiement, Service, ReplicaSet, DaemonSet, PersistentVolume en sont quelques exemples.
La prochaine section importante est la section "conteneurs". Ici, nous définissons tous les conteneurs que nous aimerions exécuter ensemble dans ce pod. La première partie est le conteneur Wordpress :
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpDans cette section, nous disons à Kubernetes de déployer Wordpress 4.9 à l'aide du serveur Web Apache et nous avons donné au conteneur le nom "wordpress". Nous souhaitons également que Kubernetes transmette un certain nombre de variables d'environnement :
- WORDPRESS_DB_HOST - L'hébergeur de la base de données. Étant donné que notre conteneur ProxySQL réside dans le même pod que le conteneur Wordpress, il est plus sûr d'utiliser un fichier de socket ProxySQL à la place. Le format pour utiliser le fichier socket dans Wordpress est "localhost :{chemin vers le fichier socket}". Par défaut, il se trouve sous le répertoire /tmp du conteneur ProxySQL. Ce chemin /tmp est partagé entre les conteneurs Wordpress et ProxySQL en utilisant des volumesMounts "partagés" comme indiqué plus bas. Les deux conteneurs doivent monter ce volume pour partager le même contenu sous le répertoire /tmp.
- WORDPRESS_DB_USER - Spécifiez l'utilisateur de la base de données wordpress.
- WORDPRESS_DB_PASSWORD - Le mot de passe pour WORDPRESS_DB_USER . Puisque nous ne voulons pas exposer le mot de passe dans ce fichier, nous pouvons le cacher en utilisant Kubernetes Secrets. Ici, nous demandons à Kubernetes de lire la ressource secrète "mysql-pass" à la place. Les secrets doivent être créés à l'avance avant le déploiement du pod, comme expliqué plus bas.
Nous souhaitons également publier le port 80 du conteneur pour l'utilisateur final. Le contenu Wordpress stocké dans /var/www/html dans le conteneur sera monté dans notre stockage persistant fonctionnant sur NFS.
Ensuite, nous définissons le conteneur ProxySQL :
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlDans la section ci-dessus, nous disons à Kubernetes de déployer un ProxySQL en utilisant plusieurs neufs/proxysql image version 1.4.12. Nous souhaitons également que Kubernetes monte notre fichier de configuration préconfiguré personnalisé et le mappe sur /etc/proxysql.cnf à l'intérieur du conteneur. Il y aura un volume appelé "shared-data" qui sera mappé au répertoire /tmp à partager avec l'image Wordpress - un répertoire temporaire qui partage la durée de vie d'un pod. Cela permet au fichier de socket ProxySQL (/tmp/proxysql.sock) d'être utilisé par le conteneur Wordpress lors de la connexion à la base de données, en contournant le réseau TCP/IP.
La dernière partie est la section "volumes" :
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes devra créer trois volumes pour ce pod :
- wordpress-persistent-storage - Utilisez PersistentVolumeClaim ressource pour mapper l'exportation NFS dans le conteneur pour le stockage de données persistant pour le contenu Wordpress.
- proxysql-config - Utiliser le ConfigMap ressource pour mapper le fichier de configuration ProxySQL.
- shared-data - Utilisez le emptyDir ressource pour monter un répertoire partagé pour nos conteneurs à l'intérieur du pod. emptyDir ressource est un répertoire temporaire qui partage la durée de vie d'un pod.
Par conséquent, sur la base de notre définition YAML ci-dessus, nous devons préparer un certain nombre de ressources Kubernetes avant de pouvoir commencer à déployer le module "blog" :
- Volume persistant et PersistentVolumeClaim - Pour stocker le contenu Web de notre application Wordpress, ainsi, lorsque le pod est reprogrammé vers un autre nœud de travail, nous ne perdrons pas les dernières modifications.
- Secrets - Pour masquer le mot de passe de l'utilisateur de la base de données Wordpress dans le fichier YAML.
- ConfigMap - Pour mapper le fichier de configuration sur le conteneur ProxySQL, afin qu'en cas de replanification vers un autre nœud, Kubernetes puisse le remonter automatiquement.
PersistentVolume et PersistentVolumeClaim
Un bon stockage persistant pour Kubernetes doit être accessible par tous les nœuds Kubernetes du cluster. Pour les besoins de cet article de blog, nous avons utilisé NFS comme fournisseur PersistentVolume (PV) car il est simple et pris en charge immédiatement. Le serveur NFS est situé quelque part en dehors de notre réseau Kubernetes et nous l'avons configuré pour autoriser tous les nœuds Kubernetes avec la ligne suivante dans /etc/exports :
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Notez que le package client NFS doit être installé sur tous les nœuds Kubernetes. Sinon, Kubernetes ne pourrait pas monter correctement le NFS. Sur tous les nœuds :
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSAssurez-vous également que sur le serveur NFS, le répertoire cible existe :
(nfs-server)$ mkdir /nfs/kubernetes/wordpressEnsuite, créez un fichier appelé wordpress-pv-pvc.yml et ajoutez les lignes suivantes :
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendDans la définition ci-dessus, nous aimerions que Kubernetes alloue 3 Go d'espace de volume sur le serveur NFS pour notre conteneur Wordpress. Notez que pour une utilisation en production, NFS doit être configuré avec un provisionneur automatique et une classe de stockage.
Créez les ressources PV et PVC :
$ kubectl create -f wordpress-pv-pvc.ymlVérifiez si ces ressources sont créées et que le statut doit être "Lié" :
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hSecrets
La première consiste à créer un secret à utiliser par le conteneur Wordpress pour WORDPRESS_DB_PASSWORD variables d'environnement. La raison est simplement parce que nous ne voulons pas exposer le mot de passe en texte clair dans le fichier YAML.
Créez une ressource secrète appelée mysql-pass et transmettez le mot de passe en conséquence :
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVérifiez que notre secret est créé :
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mConfigMap
Nous devons également créer une ressource ConfigMap pour notre conteneur ProxySQL. Un fichier Kubernetes ConfigMap contient des paires clé-valeur de données de configuration qui peuvent être consommées dans des pods ou utilisées pour stocker des données de configuration. ConfigMaps vous permet de dissocier les artefacts de configuration du contenu de l'image pour conserver la portabilité des applications conteneurisées.
Étant donné que notre serveur de base de données fonctionne déjà sur des serveurs bare metal avec un nom d'hôte et une adresse IP statiques ainsi qu'un nom d'utilisateur et un mot de passe de surveillance statique, dans ce cas d'utilisation, le fichier ConfigMap stockera des informations de configuration préconfigurées sur le service ProxySQL que nous voulons utiliser.
Créez d'abord un fichier texte appelé proxysql.cnf et ajoutez les lignes suivantes :
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Portez une attention particulière aux sections "mysql_servers" et "mysql_users", où vous devrez peut-être modifier les valeurs en fonction de la configuration de votre cluster de base de données. Dans ce cas, nous avons deux serveurs de base de données exécutés dans la réplication MySQL, comme résumé dans la capture d'écran de la topologie suivante prise à partir de ClusterControl :
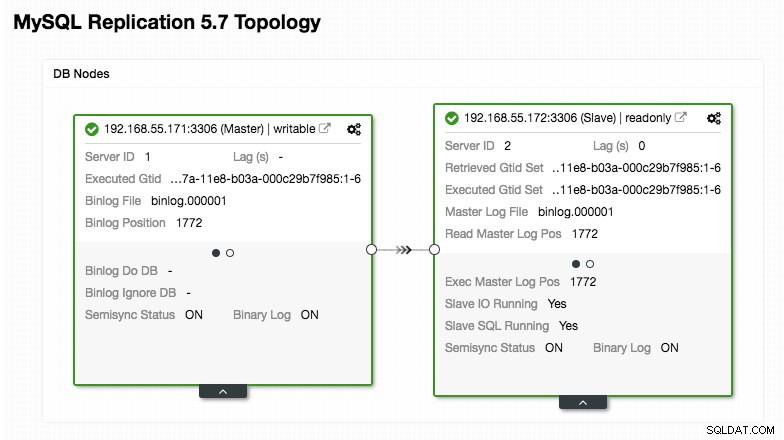
Toutes les écritures doivent aller au nœud maître tandis que les lectures sont transmises au groupe d'hôtes 20, comme défini dans la section "mysql_query_rules". C'est la base du fractionnement lecture/écriture et nous voulons les utiliser ensemble.
Ensuite, importez le fichier de configuration dans ConfigMap :
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVérifiez si le ConfigMap est chargé dans Kubernetes :
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sDéploiement du pod
Maintenant, nous devrions être prêts à déployer le module de blog. Envoyez la tâche de déploiement à Kubernetes :
$ kubectl create -f blog-deployment.ymlVérifiez l'état du pod :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sIl doit afficher 2/2 sous la colonne READY, indiquant qu'il y a deux conteneurs en cours d'exécution à l'intérieur du pod. Utilisez l'indicateur d'option -c pour vérifier les conteneurs Wordpress et ProxySQL dans le module de blog :
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlDans le journal du conteneur ProxySQL, vous devriez voir les lignes suivantes :
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (groupe d'hôtes d'écriture) ne doit avoir qu'un seul nœud EN LIGNE (indiquant un seul maître) et l'autre hôte doit être au moins dans l'état OFFLINE_HARD. Pour HID 20, il devrait être EN LIGNE pour tous les nœuds (indiquant plusieurs réplicas en lecture).
Pour obtenir un résumé du déploiement, utilisez le drapeau describe :
$ kubectl describe deployments blogNotre blog est maintenant en cours d'exécution, mais nous ne pouvons pas y accéder depuis l'extérieur du réseau Kubernetes sans configurer le service, comme expliqué dans la section suivante.
Création du service de blog
La dernière étape consiste à créer un service attaché à notre pod. Ceci pour garantir que notre module de blog Wordpress est accessible depuis le monde extérieur. Créez un fichier appelé blog-svc.yml et collez la ligne suivante :
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendCréez le service :
$ kubectl create -f blog-svc.ymlVérifiez si le service est créé correctement :
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hLe port 80 publié par le module de blog est désormais mappé vers le monde extérieur via le port 30080. Nous pouvons accéder à notre article de blog à l'adresse https://{any_kubernetes_host}:30080/ et devons être redirigés vers la page d'installation de Wordpress. Si nous poursuivons l'installation, cela sauterait la partie de connexion à la base de données et afficherait directement cette page :
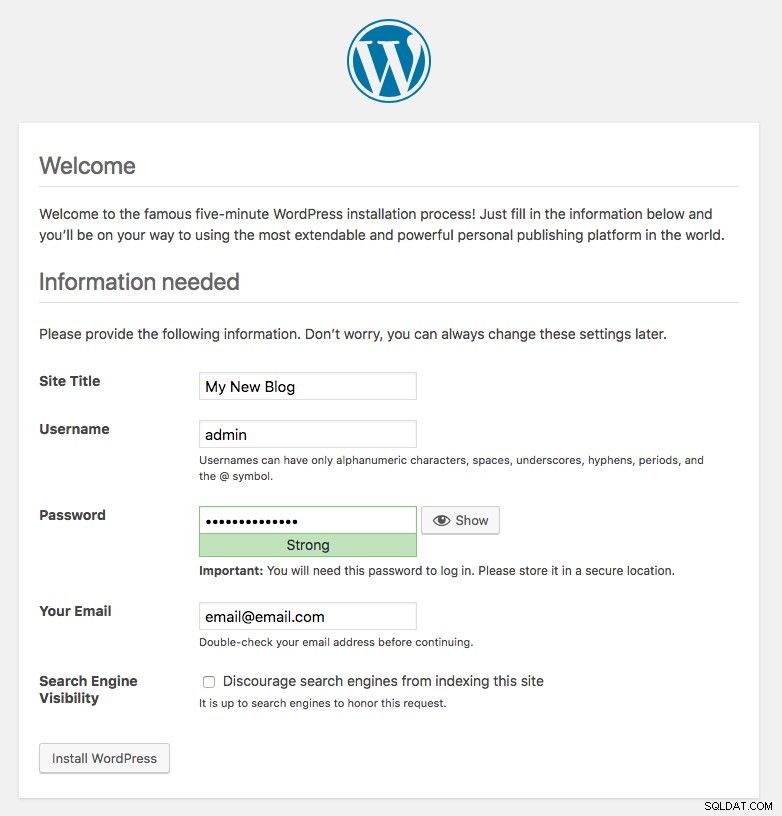
Cela indique que notre configuration MySQL et ProxySQL est correctement configurée dans le fichier wp-config.php. Sinon, vous seriez redirigé vers la page de configuration de la base de données.
Notre déploiement est maintenant terminé.
Gestion du conteneur ProxySQL dans un pod
Le basculement et la récupération devraient être gérés automatiquement par Kubernetes. Par exemple, si le travailleur Kubernetes tombe en panne, le pod sera recréé dans le prochain nœud disponible après --pod-eviction-timeout (par défaut à 5 minutes). Si le conteneur tombe en panne ou est tué, Kubernetes le remplacera presque instantanément.
Certaines tâches de gestion courantes sont censées être différentes lorsqu'elles sont exécutées dans Kubernetes, comme indiqué dans les sections suivantes.
Mise à l'échelle vers le haut et vers le bas
Dans la configuration ci-dessus, nous déployions une réplique dans notre déploiement. Pour passer à l'échelle, modifiez simplement les spec.replicas valeur en conséquence en utilisant la commande kubectl edit :
$ kubectl edit deployment blogIl ouvrira la définition de déploiement dans un fichier texte par défaut et changera simplement le spec.replicas valeur à quelque chose de plus élevé, par exemple, "réplicas :3". Ensuite, enregistrez le fichier et vérifiez immédiatement l'état du déploiement à l'aide de la commande suivante :
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outÀ ce stade, nous avons trois modules de blog (Wordpress + ProxySQL) exécutés simultanément dans Kubernetes :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mÀ ce stade, notre architecture ressemble à ceci :
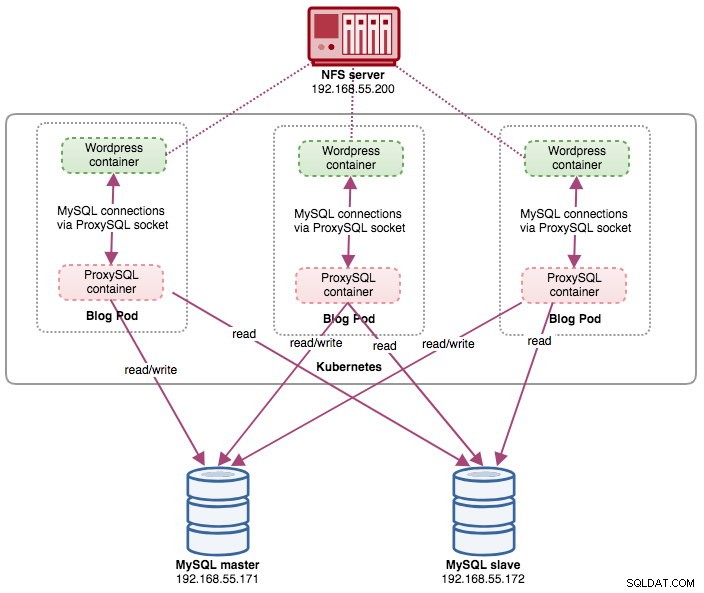
Notez qu'il peut nécessiter plus de personnalisation que notre configuration actuelle pour exécuter Wordpress en douceur dans un environnement de production à l'échelle horizontale (pensez au contenu statique, à la gestion de session et autres). Ce sont en fait au-delà de la portée de cet article de blog.
Les procédures de réduction sont similaires.
Gestion des configurations
La gestion de la configuration est importante dans ProxySQL. C'est là que la magie opère lorsque vous pouvez définir votre propre ensemble de règles de requête pour effectuer la mise en cache des requêtes, le pare-feu et la réécriture. Contrairement à la pratique courante, où ProxySQL serait configuré via la console d'administration et passerait à la persistance en utilisant "SAVE .. TO DISK", nous nous en tiendrons aux fichiers de configuration uniquement pour rendre les choses plus portables dans Kubernetes. C'est la raison pour laquelle nous utilisons ConfigMaps.
Étant donné que nous nous appuyons sur notre configuration centralisée stockée par Kubernetes ConfigMaps, il existe plusieurs façons d'effectuer des modifications de configuration. Tout d'abord, en utilisant la commande kubectl edit :
$ kubectl edit configmap proxysql-configmapIl ouvrira la configuration dans un éditeur de texte par défaut et vous pourrez directement y apporter des modifications et enregistrer le fichier texte une fois terminé. Sinon, recréez les configmaps devrait également faire :
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfUne fois la configuration poussée dans ConfigMap, redémarrez le pod ou le conteneur comme indiqué dans la section Service Control. La configuration du conteneur via l'interface d'administration ProxySQL (port 6032) ne le rendra pas persistant après la replanification du pod par Kubernetes.
Contrôle des services
Étant donné que les deux conteneurs à l'intérieur d'un pod sont étroitement couplés, la meilleure façon d'appliquer les modifications de configuration ProxySQL est de forcer Kubernetes à effectuer le remplacement du pod. Considérez que nous avons maintenant trois modules de blog après notre mise à l'échelle :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mUtilisez la commande suivante pour remplacer un pod à la fois :
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnEnsuite, vérifiez avec ce qui suit :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sVous remarquerez que le pod le plus récent a été redémarré en regardant la colonne AGE et RESTART, il est venu avec un nom de pod différent. Répétez les mêmes étapes pour les pods restants. Sinon, vous pouvez également utiliser la commande "docker kill" pour tuer manuellement le conteneur ProxySQL dans le nœud de travail Kubernetes. Par exemple :
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes remplacera alors le conteneur ProxySQL tué par un nouveau.
Surveillance
Utilisez la commande kubectl exec pour exécuter l'instruction SQL via le client mysql. Par exemple, pour surveiller la digestion des requêtes :
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;Ou avec un one-liner :
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'En modifiant l'instruction SQL, vous pouvez surveiller d'autres composants ProxySQL ou effectuer des tâches d'administration via cette console d'administration. Encore une fois, il ne persistera que pendant la durée de vie du conteneur ProxySQL et ne sera pas persistant si le pod est replanifié.
Réflexions finales
ProxySQL joue un rôle clé si vous souhaitez faire évoluer vos conteneurs d'applications et disposer d'un moyen intelligent d'accéder à un backend de base de données distribuée. Il existe plusieurs façons de déployer ProxySQL sur Kubernetes pour soutenir la croissance de nos applications lors d'une exécution à grande échelle. Ce billet de blog ne couvre que l'un d'entre eux.
Dans un prochain article de blog, nous verrons comment exécuter ProxySQL dans une approche centralisée en l'utilisant comme service Kubernetes.