L'une des fonctionnalités intéressantes de Galera est le provisionnement automatique des nœuds et le contrôle des membres. Si un nœud tombe en panne ou perd la communication, il sera automatiquement expulsé du cluster et restera inopérant. Tant que la majorité des nœuds communiquent encore (Galera appelle ce PC - composant principal), il y a de fortes chances que le nœud défaillant puisse automatiquement rejoindre, resynchroniser et reprendre la réplication une fois la connectivité rétablie.
Généralement, tous les nœuds Galera sont égaux. Ils détiennent le même ensemble de données et le même rôle que les maîtres, capables de gérer la lecture et l'écriture simultanément, grâce à la communication de groupe Galera et au plugin de réplication basé sur la certification. Par conséquent, il n'y a en fait aucun basculement du point de vue de la base de données en raison de cet équilibre. Uniquement du côté de l'application qui nécessiterait un basculement, pour ignorer les nœuds non opérationnels pendant que le cluster est partitionné.
Dans cet article de blog, nous allons chercher à comprendre comment Galera Cluster effectue la récupération des nœuds et des clusters en cas de partition du réseau. En passant, nous avons couvert un sujet similaire dans cet article de blog il y a quelque temps. Codership a expliqué en détail le concept de récupération de Galera dans la page de documentation, Node Failure and Recovery.
Défaillance et expulsion de nœud
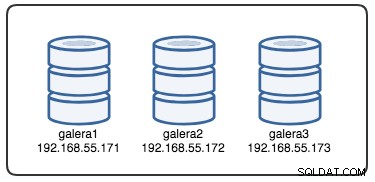
Afin de comprendre la récupération, nous devons d'abord comprendre comment Galera détecte la défaillance du nœud et le processus d'éviction. Mettons cela dans un scénario de test contrôlé afin que nous puissions mieux comprendre le processus d'expulsion. Supposons que nous ayons un cluster Galera à trois nœuds, comme illustré ci-dessous :
La commande suivante peut être utilisée pour récupérer nos options de fournisseur Galera :
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GC'est une longue liste, mais nous devons juste nous concentrer sur certains paramètres pour expliquer le processus :
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Tout d'abord, Galera suit le formatage ISO 8601 pour représenter la durée. P1D signifie que la durée est d'un jour, tandis que PT15S signifie que la durée est de 15 secondes (notez l'indicateur de temps, T, qui précède la valeur de temps). Par exemple si on voulait augmenter evs.view_forget_timeout à 1 jour et demi, on réglerait P1DT12H, ou PT36H.
Étant donné que tous les hôtes n'ont pas été configurés avec des règles de pare-feu, nous utilisons le script suivant appelé block_galera.sh sur galera2 pour simuler une panne de réseau vers/depuis ce nœud :
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateEn exécutant le script, nous obtenons la sortie suivante :
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018L'horodatage rapporté peut être considéré comme le début du partitionnement du cluster, où nous perdons galera2, tandis que galera1 et galera3 sont toujours en ligne et accessibles. À ce stade, notre architecture Galera Cluster ressemble à ceci :
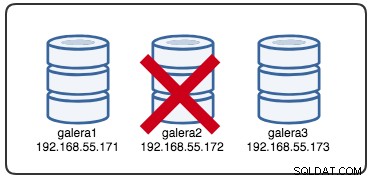
Du point de vue du nœud partitionné
Sur galera2, vous verrez des impressions dans le journal des erreurs MySQL. Décomposons-les en plusieurs parties. Le temps d'arrêt a commencé vers 16:46:02 heure UTC et après gmcast.peer_timeout=PT3S , ce qui suit apparaît :
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Comme il est passé evs.suspect_timeout =PT5S , les deux nœuds galera1 et galera3 sont suspectés morts par galera2 :
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveEnsuite, Galera révisera la vue actuelle du cluster et la position de ce nœud :
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Avec la nouvelle vue de cluster, Galera effectuera un calcul de quorum pour décider si ce nœud fait partie du composant principal. Si le nouveau composant voit "primary =no", Galera rétrogradera l'état du nœud local de SYNCED à OPEN :
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Avec les dernières modifications apportées à la vue du cluster et à l'état du nœud, Galera renvoie la vue du cluster post-expulsion et l'état global comme ci-dessous :
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Vous pouvez voir que le statut global suivant de galera2 a changé pendant cette période :
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+À ce stade, le serveur MySQL/MariaDB sur galera2 est toujours accessible (la base de données écoute sur 3306 et Galera sur 4567) et vous pouvez interroger les tables système mysql et répertorier les bases de données et les tables. Cependant, lorsque vous sautez dans les tables non système et effectuez une requête simple comme celle-ci :
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useVous obtiendrez immédiatement une erreur indiquant que WSREP est chargé mais pas prêt à être utilisé par ce nœud, comme indiqué par wsrep_ready statut. Cela est dû au fait que le nœud perd sa connexion au composant principal et passe à l'état non opérationnel (le statut du nœud local est passé de SYNCED à OPEN). Les données lues à partir de nœuds dans un état non opérationnel sont considérées comme obsolètes, sauf si vous définissez wsrep_dirty_reads=ON pour autoriser les lectures, bien que Galera rejette toujours toute commande modifiant ou mettant à jour la base de données.
Enfin, Galera continuera à écouter et à se reconnecter aux autres membres en arrière-plan à l'infini :
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Le déroulement du processus d'éviction par la communication de groupe Galera pour le nœud partitionné lors d'un problème de réseau peut être résumé comme suit :
- Se déconnecte du cluster après gmcast.peer_timeout .
- Suspecte d'autres nœuds après evs.suspect_timeout .
- Récupère la nouvelle vue de cluster.
- Effectue un calcul de quorum pour déterminer l'état du nœud.
- Rétrograde le nœud de SYNCED à OPEN.
- Tentative de reconnexion au composant principal (autres nœuds Galera) en arrière-plan.
Du point de vue du composant principal
Sur galera1 et galera3 respectivement, après gmcast.peer_timeout=PT3S , ce qui suit apparaît dans le journal des erreurs MySQL :
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Après avoir passé evs.suspect_timeout =PT5S , galera2 est suspectée morte par galera3 (et galera1) :
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera vérifie si les autres nœuds répondent à la communication de groupe sur galera3, il trouve que galera1 est dans un état primaire et stable :
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera révise la vue cluster de ce nœud (galera3) :
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera supprime ensuite le nœud partitionné du composant principal :
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Le nouveau composant principal est désormais composé de deux nœuds, galera1 et galera3 :
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Le composant principal échangera l'état entre eux pour convenir de la nouvelle vue du cluster et de l'état global :
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera calcule et vérifie le quorum de l'échange d'état entre les membres en ligne :
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera met à jour la nouvelle vue du cluster et l'état global après l'éviction de galera2 :
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)À ce stade, galera1 et galera3 signaleront un statut global similaire :
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Ils répertorient le membre problématique dans le wsrep_evs_delayed statut. Puisque l'état local est "Synced", ces nœuds sont opérationnels et vous pouvez rediriger les connexions client de galera2 vers n'importe lequel d'entre eux. Si cette étape n'est pas pratique, envisagez d'utiliser un équilibreur de charge placé devant la base de données pour simplifier le point de terminaison de connexion des clients.
Récupération et jonction de nœud
Un nœud Galera partitionné continuera à tenter d'établir une connexion avec le composant principal à l'infini. Vidons les règles iptables sur galera2 pour le laisser se connecter avec les nœuds restants :
# on galera2
$ iptables -FUne fois que le nœud est capable de se connecter à l'un des nœuds, Galera commencera à rétablir automatiquement la communication de groupe :
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableLe nœud galera2 se connectera ensuite à l'un des composants principaux (dans ce cas, galera1, ID de nœud 737422d6) pour obtenir la vue actuelle du cluster et l'état des nœuds :
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera effectuera ensuite un échange d'état avec le reste des membres pouvant former le composant principal :
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)L'échange d'état permet à galera2 de calculer le quorum et de produire le résultat suivant :
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera fera alors passer l'état du nœud local de OPEN à PRIMARY, pour démarrer et établir la connexion du nœud au composant principal :
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Comme indiqué par la ligne ci-dessus, Galera calcule l'écart sur la distance entre le nœud et le cluster. Ce nœud nécessite un transfert d'état pour rattraper le jeu d'écriture numéro 2836958 à partir de 2761994 :
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera prépare l'écouteur IST sur le port 4568 de ce nœud et demande à tout nœud synchronisé du cluster de devenir un donneur. Dans ce cas, Galera sélectionne automatiquement galera3 (192.168.55.173), ou il peut également sélectionner un donateur dans la liste sous wsrep_sst_donor (si défini) pour l'opération de synchronisation :
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Il changera alors l'état du nœud local de PRIMARY à JOINER. À ce stade, galera2 reçoit une demande de transfert d'état et commence à mettre en cache les jeux d'écriture :
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetLe nœud galera2 commence à recevoir les jeux d'écriture manquants du gcache du donateur sélectionné (galera3) :
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Une fois tous les jeux d'écriture manquants reçus et appliqués, Galera promouvra galera2 comme JOINED jusqu'au seqno 2837012 :
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Le nœud applique tous les jeux d'écriture mis en cache dans sa file d'attente esclave et finit de rattraper le cluster. Sa file d'attente d'esclaves est maintenant vide. Galera fera la promotion de galera2 en SYNCED, indiquant que le nœud est maintenant opérationnel et prêt à servir les clients :
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsÀ ce stade, tous les nœuds sont de nouveau opérationnels. Vous pouvez vérifier en utilisant les déclarations suivantes sur galera2 :
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+Le wsrep_cluster_size signalé comme 3 et le statut du cluster est Primaire, indiquant que galera2 fait partie du Composant Primaire. Le wsrep_evs_delayed a également été effacé et l'état local est maintenant synchronisé.
Le flux de processus de récupération pour le nœud partitionné lors d'un problème de réseau peut être résumé comme suit :
- Rétablit la communication de groupe avec d'autres nœuds.
- Récupère la vue du cluster à partir de l'un des composants principaux.
- Effectue un échange d'état avec le composant principal et calcule le quorum.
- Change l'état du nœud local de OPEN à PRIMARY.
- Calcule l'écart entre le nœud local et le cluster.
- Change l'état du nœud local de PRIMARY à JOINER.
- Prépare l'écouteur/récepteur IST sur le port 4568.
- Demande un transfert d'État via IST et choisit un donneur.
- Commence à recevoir et à appliquer le jeu d'écritures manquant à partir du gcache du donateur choisi.
- Change l'état du nœud local de JOINER à JOINED.
- Rattrape le cluster en appliquant les jeux d'écriture mis en cache dans la file d'attente esclave.
- Change l'état du nœud local de JOINED à SYNCED.
Échec du cluster
Un cluster Galera est considéré comme défaillant si aucun composant principal (PC) n'est disponible. Considérez un cluster Galera à trois nœuds similaire, comme illustré dans le diagramme ci-dessous :
Un cluster est considéré comme opérationnel si tous les nœuds ou la majorité des nœuds sont en ligne. En ligne signifie qu'ils peuvent se voir via le trafic de réplication ou la communication de groupe de Galera. Si aucun trafic n'entre et ne sort du nœud, le cluster enverra une balise de pulsation pour que le nœud réponde en temps opportun. Sinon, il sera placé dans la liste des retards ou suspects en fonction de la réponse du nœud.
Si un nœud tombe en panne, disons le nœud C, le cluster restera opérationnel car les nœuds A et B sont toujours en quorum avec 2 votes sur 3 pour former un composant primaire. Vous devriez obtenir l'état de cluster suivant sur A et B :
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Si disons qu'un interrupteur principal est tombé en panne, comme illustré dans le schéma suivant :
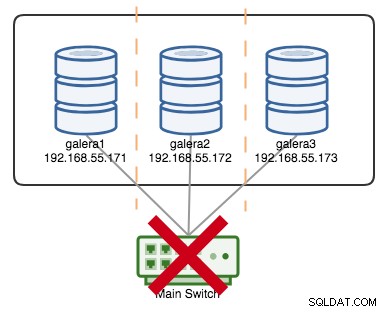
À ce stade, chaque nœud perd la communication entre eux et l'état du cluster sera signalé comme non primaire sur tous les nœuds (comme ce qui est arrivé à galera2 dans le cas précédent). Chaque nœud calculerait le quorum et découvrirait qu'il est minoritaire (1 vote sur 3) perdant ainsi le quorum, ce qui signifie qu'aucun composant principal n'est formé et par conséquent tous les nœuds refusent de servir des données. Ceci est considéré comme un échec de cluster.
Une fois le problème de réseau résolu, Galera rétablira automatiquement la communication entre les membres, échangera les états du nœud et déterminera la possibilité de réformer le composant principal en comparant l'état du nœud, les UUID et les seqnos. Si la probabilité est là, Galera fusionnera les composants principaux comme indiqué dans les lignes suivantes :
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

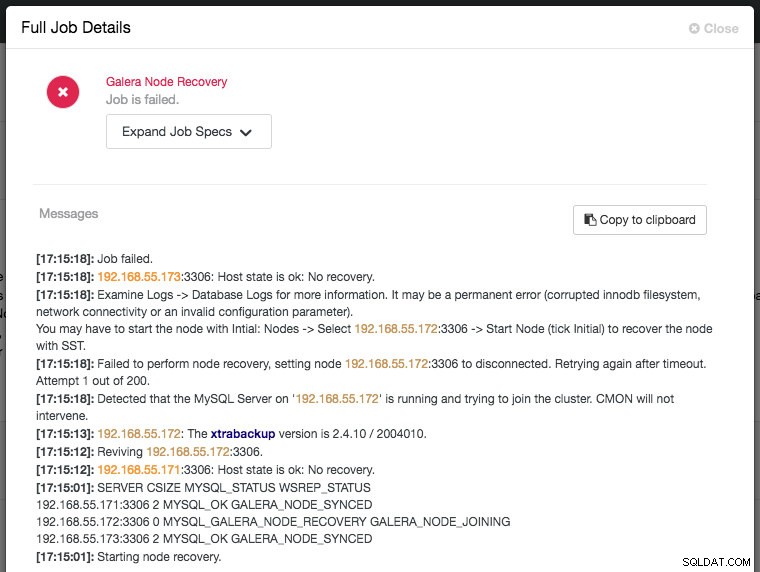
Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Conclusion
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.