L'époque où une base de données était déployée en tant que nœud ou instance unique est révolue depuis longtemps - un serveur puissant et autonome chargé de gérer toutes les demandes adressées à la base de données. La mise à l'échelle verticale était la voie à suivre - remplacer le serveur par un autre, encore plus puissant. Pendant ces périodes, on n'avait pas vraiment à se soucier des performances du réseau. Tant que les demandes arrivaient, tout allait bien.
Mais de nos jours, les bases de données sont construites sous forme de clusters avec des nœuds interconnectés sur un réseau. Ce n'est pas toujours un réseau local rapide. Alors que les entreprises atteignent une échelle mondiale, l'infrastructure de base de données doit également s'étendre à travers le monde, pour rester proche des clients et réduire la latence. Cela s'accompagne de défis supplémentaires auxquels nous devons faire face lors de la conception d'un environnement de base de données hautement disponible. Dans cet article de blog, nous examinerons les problèmes de réseau auxquels vous pourriez être confronté et fournirons quelques suggestions sur la façon de les résoudre.
Deux options principales pour MySQL ou MariaDB HA
Nous avons couvert ce sujet en détail dans l'un des livres blancs, mais examinons les deux principales façons de créer une haute disponibilité pour MySQL et MariaDB.
Pôle Galera
Galera Cluster est une technologie de cluster virtuellement synchrone sans partage pour MySQL. Il permet de créer des configurations multi-écrivains pouvant s'étendre à travers le monde. Galera prospère dans les environnements à faible latence, mais il peut également être configuré pour fonctionner avec de longues connexions WAN. Galera dispose d'un mécanisme de quorum intégré qui garantit que les données ne seront pas compromises en cas de partitionnement réseau de certains nœuds.
Réplication MySQL
La réplication MySQL peut être asynchrone ou semi-synchrone. Les deux sont conçus pour créer des clusters de réplication à grande échelle. Comme dans toute autre configuration de réplication maître-esclave ou primaire-secondaire, il ne peut y avoir qu'un seul graveur, le maître. D'autres nœuds, les esclaves, sont utilisés à des fins de basculement car ils contiennent la copie de l'ensemble de données du maser. Les esclaves peuvent également être utilisés pour lire les données et décharger une partie de la charge de travail du maître.
Les deux solutions ont leurs propres limites et caractéristiques, toutes deux souffrent de problèmes différents. Les deux peuvent être affectés par des connexions réseau instables. Examinons ces limitations et comment nous pouvons concevoir l'environnement pour minimiser l'impact d'une infrastructure réseau instable.
Cluster Galera - Problèmes de réseau
Tout d'abord, jetons un coup d'œil à Galera Cluster. Comme nous en avons discuté, cela fonctionne mieux dans un environnement à faible latence. L'un des principaux problèmes liés à la latence dans Galera est la façon dont Galera gère les écritures. Nous n'entrerons pas dans tous les détails dans ce blog, mais lisons plus en détail dans notre tutoriel Galera Cluster for MySQL. L'essentiel est qu'en raison du processus de certification des écritures, où tous les nœuds du cluster doivent s'entendre sur le fait que l'écriture peut être appliquée ou non, vos performances d'écriture pour une seule ligne sont strictement limitées par le temps d'aller-retour du réseau entre l'écrivain nœud et le nœud le plus éloigné. Tant que la latence est acceptable et tant que vous n'avez pas trop de points chauds dans vos données, les configurations WAN peuvent très bien fonctionner. Le problème commence lorsque la latence du réseau augmente de temps en temps. Les écritures prendront alors 3 ou 4 fois plus de temps que d'habitude et, par conséquent, les bases de données peuvent commencer à être surchargées d'écritures de longue durée.
L'une des grandes caractéristiques de Galera Cluster est sa capacité à détecter l'état du cluster et à réagir au partitionnement du réseau. Si un nœud du cluster ne peut pas être atteint, il sera expulsé du cluster et ne pourra effectuer aucune écriture. Ceci est crucial pour maintenir l'intégrité des données pendant le temps où le cluster est divisé - seule la majorité du cluster acceptera les écritures. La minorité va se plaindre. Pour gérer cela, Galera introduit une vaste gamme de vérifications et de délais d'attente configurables pour éviter les fausses alertes sur les problèmes de réseau très transitoires. Malheureusement, si le réseau n'est pas fiable, Galera Cluster ne pourra pas fonctionner correctement - les nœuds commenceront à quitter le cluster, le rejoindront plus tard. Cela sera particulièrement problématique lorsque le cluster Galera s'étendra sur le WAN - des parties séparées du cluster peuvent disparaître de manière aléatoire si le réseau d'interconnexion ne fonctionne pas correctement.
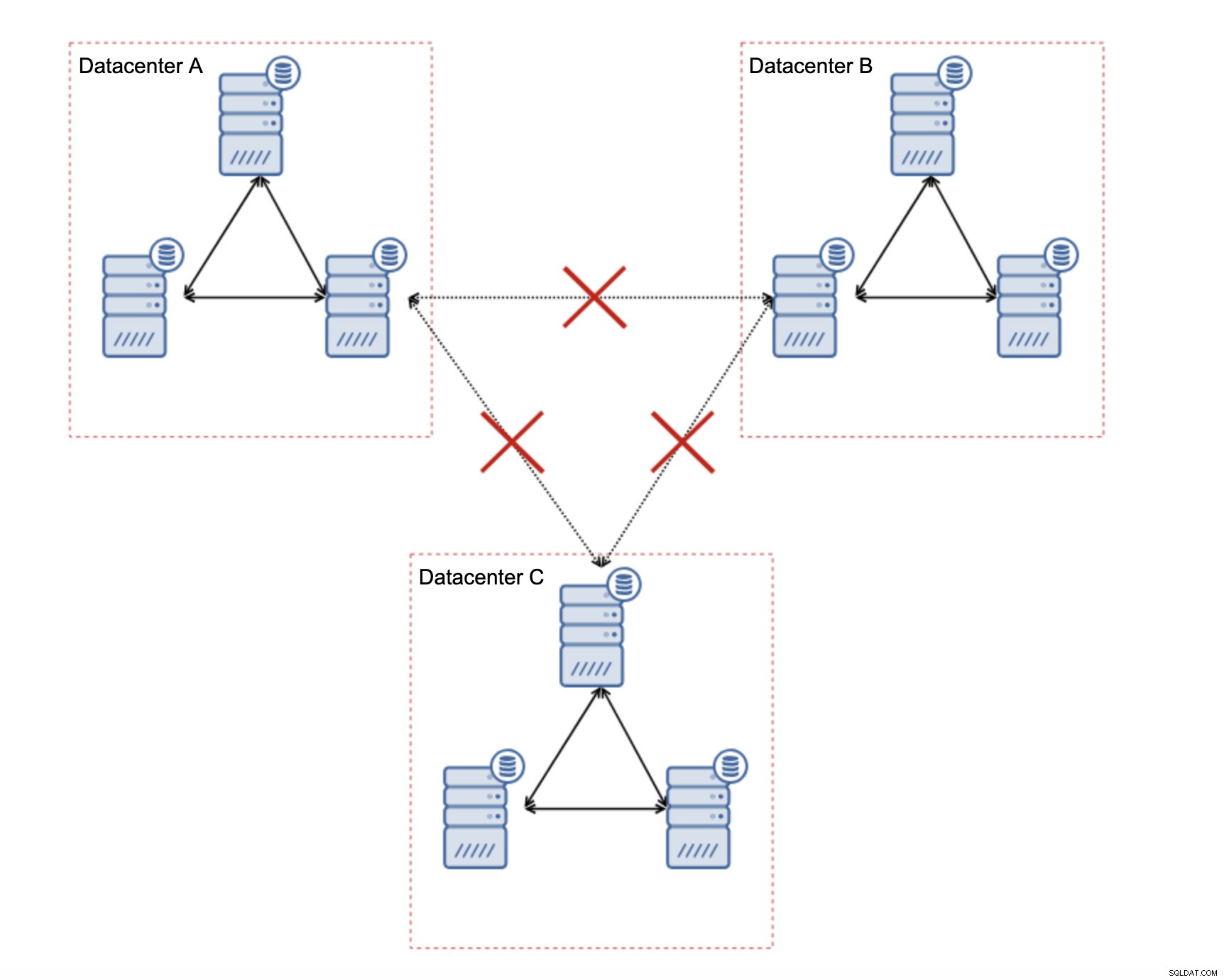
Comment concevoir un cluster Galera pour un réseau instable ?
Tout d'abord, si vous rencontrez des problèmes de réseau au sein d'un centre de données unique, vous ne pouvez pas faire grand-chose à moins de pouvoir résoudre ces problèmes d'une manière ou d'une autre. Un réseau local non fiable est interdit pour Galera Cluster, vous devez reconsidérer l'utilisation d'une autre solution (même si, pour être honnête, un réseau non fiable sera toujours un problème). D'autre part, si les problèmes sont liés aux connexions WAN uniquement (et c'est l'un des cas les plus typiques), il peut être possible de remplacer les liens WAN Galera par une réplication asynchrone régulière (si le réglage WAN Galera n'a pas aidé).
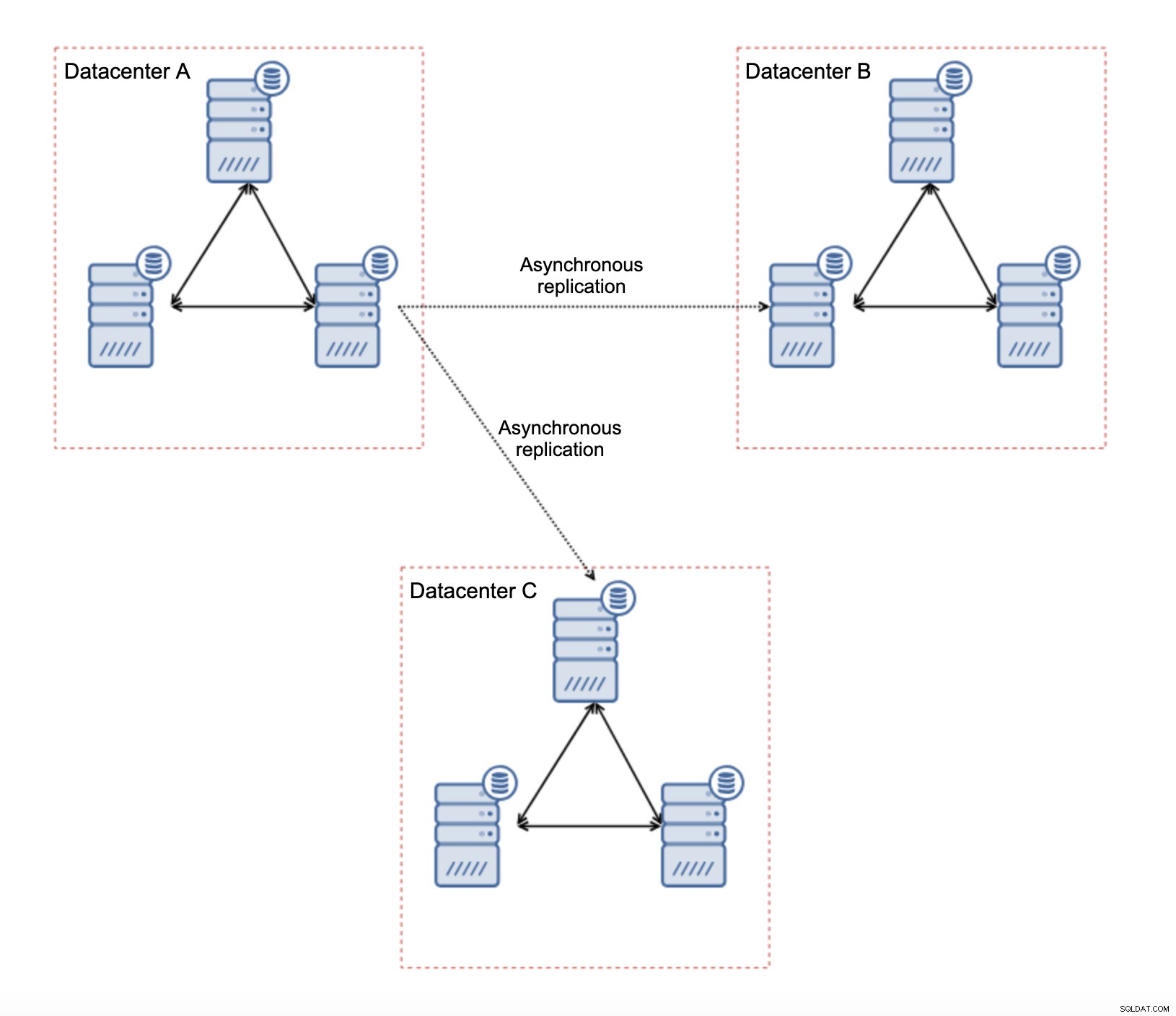
Il existe plusieurs limitations inhérentes à cette configuration - le principal problème est que les écritures se produisaient auparavant localement. Désormais, toutes les écritures devront se diriger vers le centre de données "maître" (DC A dans notre cas). Ce n'est pas aussi mauvais qu'il y paraît. Veuillez garder à l'esprit que dans un environnement entièrement Galera, les écritures seront ralenties par la latence entre les nœuds situés dans différents centres de données. Même les écritures locales seront affectées. Ce sera plus ou moins le même ralentissement qu'avec une configuration asynchrone dans laquelle vous enverriez les écritures via le WAN au centre de données "maître".
L'utilisation de la réplication asynchrone s'accompagne de tous les problèmes typiques de la réplication asynchrone. Le décalage de réplication peut devenir un problème - non pas que Galera serait plus performant, c'est juste que Galera ralentirait le trafic via le contrôle de flux alors que la réplication n'a aucun mécanisme pour limiter le trafic sur le maître.
Un autre problème est le basculement :si le nœud Galera "maître" (celui qui agit en tant que maître pour les esclaves dans d'autres centres de données) échoue, un mécanisme doit être créé pour rediriger les esclaves vers un autre nœud maître fonctionnel. Il peut s'agir d'une sorte de script, il est également possible d'essayer quelque chose avec VIP où le cluster Galera "esclave" est esclave de l'IP virtuelle qui est toujours attribuée au nœud Galera actif dans le cluster "maître".
Le principal avantage d'une telle configuration est que nous supprimons le lien WAN Galera, ce qui signifie que notre cluster "maître" ne sera pas ralenti par le fait que certains nœuds sont séparés géographiquement. Comme nous l'avons mentionné, nous perdons la capacité d'écrire dans tous les centres de données, mais l'écriture en termes de latence sur le WAN est la même que l'écriture locale sur le cluster Galera qui s'étend sur le WAN. En conséquence, la latence globale devrait s'améliorer. La réplication asynchrone est également moins vulnérable aux réseaux instables. Dans le pire des cas, le lien de réplication sera rompu et il sera recréé lorsque les réseaux convergeront.
Comment concevoir la réplication MySQL pour un réseau instable ?
Dans la section précédente, nous avons couvert le cluster Galera et une solution consistait à utiliser la réplication asynchrone. À quoi cela ressemble-t-il dans une configuration de réplication asynchrone simple ? Voyons comment un réseau instable peut provoquer les plus grandes perturbations dans la configuration de la réplication.
Tout d'abord, la latence - l'un des principaux problèmes de Galera Cluster. En cas de réplication, c'est presque un non-problème. À moins que vous n'utilisiez une réplication semi-synchrone, dans ce cas, une latence accrue ralentira les écritures. Dans la réplication asynchrone, la latence n'a aucun impact sur les performances d'écriture. Cela peut cependant avoir un impact sur le délai de réplication. Ce n'est pas aussi important que pour Galera, mais vous pouvez vous attendre à plus de pics de décalage et à des performances de réplication globales moins stables si le réseau entre les nœuds souffre d'une latence élevée. Cela est principalement dû au fait que le maître peut également servir plusieurs écritures avant que le transfert de données vers l'esclave puisse être lancé sur un réseau à latence élevée.
L'instabilité du réseau peut certainement avoir un impact sur les liens de réplication, mais ce n'est, encore une fois, pas si critique. Les esclaves MySQL tenteront de se reconnecter à leurs maîtres et la réplication commencera.
Le principal problème de la réplication MySQL est en fait quelque chose que Galera Cluster résout en interne :le partitionnement du réseau. Nous parlons du partitionnement du réseau comme la condition dans laquelle les segments du réseau sont séparés les uns des autres. La réplication MySQL utilise un seul nœud d'écriture - maître. Quelle que soit la manière dont vous concevez votre environnement, vous devez envoyer vos écritures au maître. Si le maître n'est pas disponible (pour quelque raison que ce soit), l'application ne peut pas faire son travail à moins qu'elle ne s'exécute dans une sorte de mode lecture seule. Par conséquent, il est nécessaire de choisir le nouveau maître dès que possible. C'est là que les problèmes apparaissent.
Tout d'abord, comment savoir quel hôte est maître et lequel ne l'est pas. L'un des moyens habituels consiste à utiliser la variable "read_only" pour distinguer les esclaves du maître. Si le nœud a read_only activé (set read_only=1), il s'agit d'un esclave (car les esclaves ne doivent pas gérer les écritures directes). Si le nœud a read_only désactivé (set read_only=0), il s'agit d'un maître. Pour rendre les choses plus sûres, une approche courante consiste à définir read_only=1 dans la configuration MySQL - en cas de redémarrage, il est plus sûr que le nœud apparaisse en tant qu'esclave. Un tel "langage" peut être compris par des proxies comme ProxySQL ou MaxScale.
Prenons un exemple.
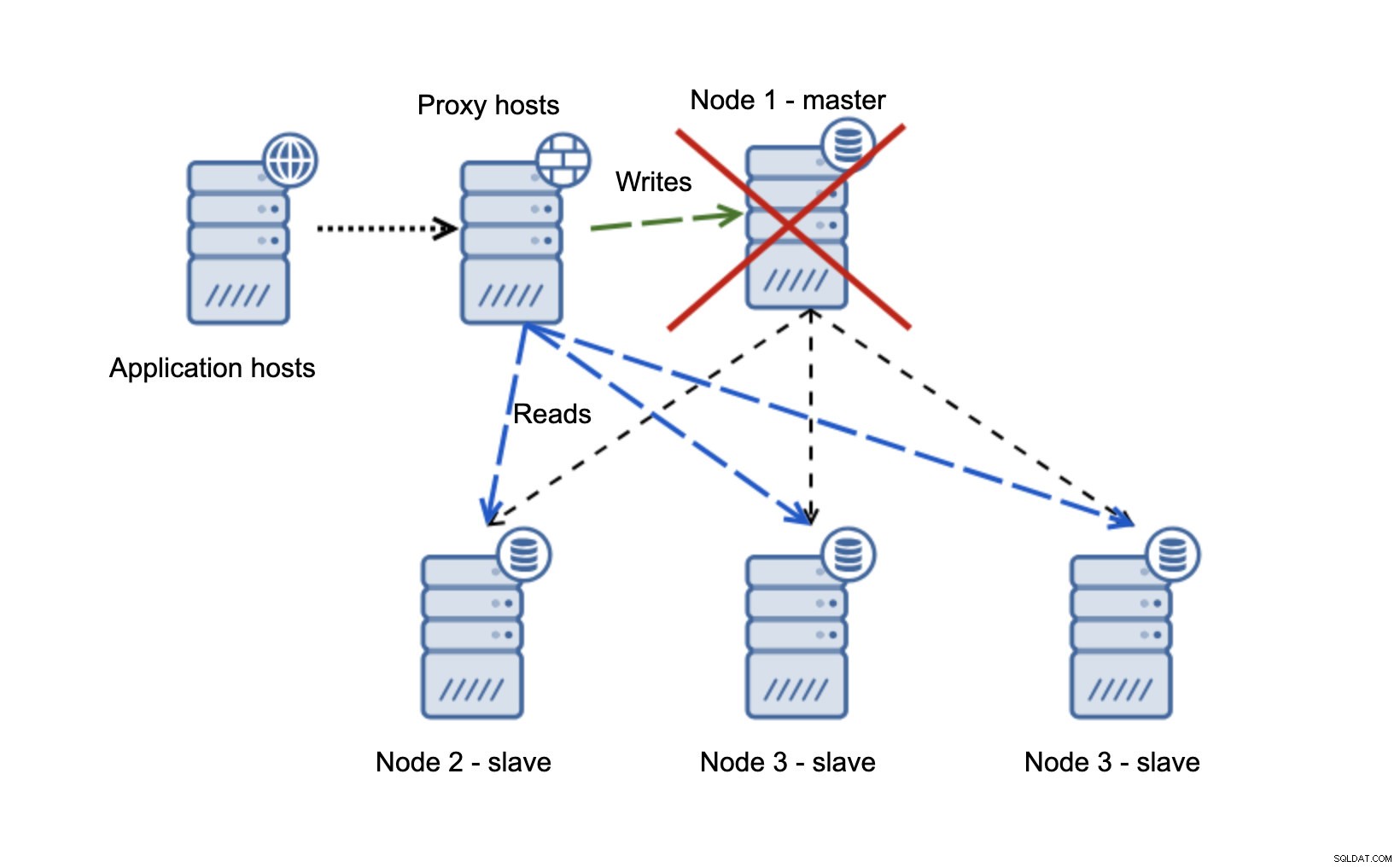
Nous avons des hôtes d'application qui se connectent à la couche proxy. Les mandataires effectuent la séparation lecture/écriture en envoyant des SELECT aux esclaves et en écrivant au maître. Si le maître est en panne, le basculement est effectué, un nouveau maître est promu, la couche proxy le détecte et commence à envoyer des écritures à un autre nœud.
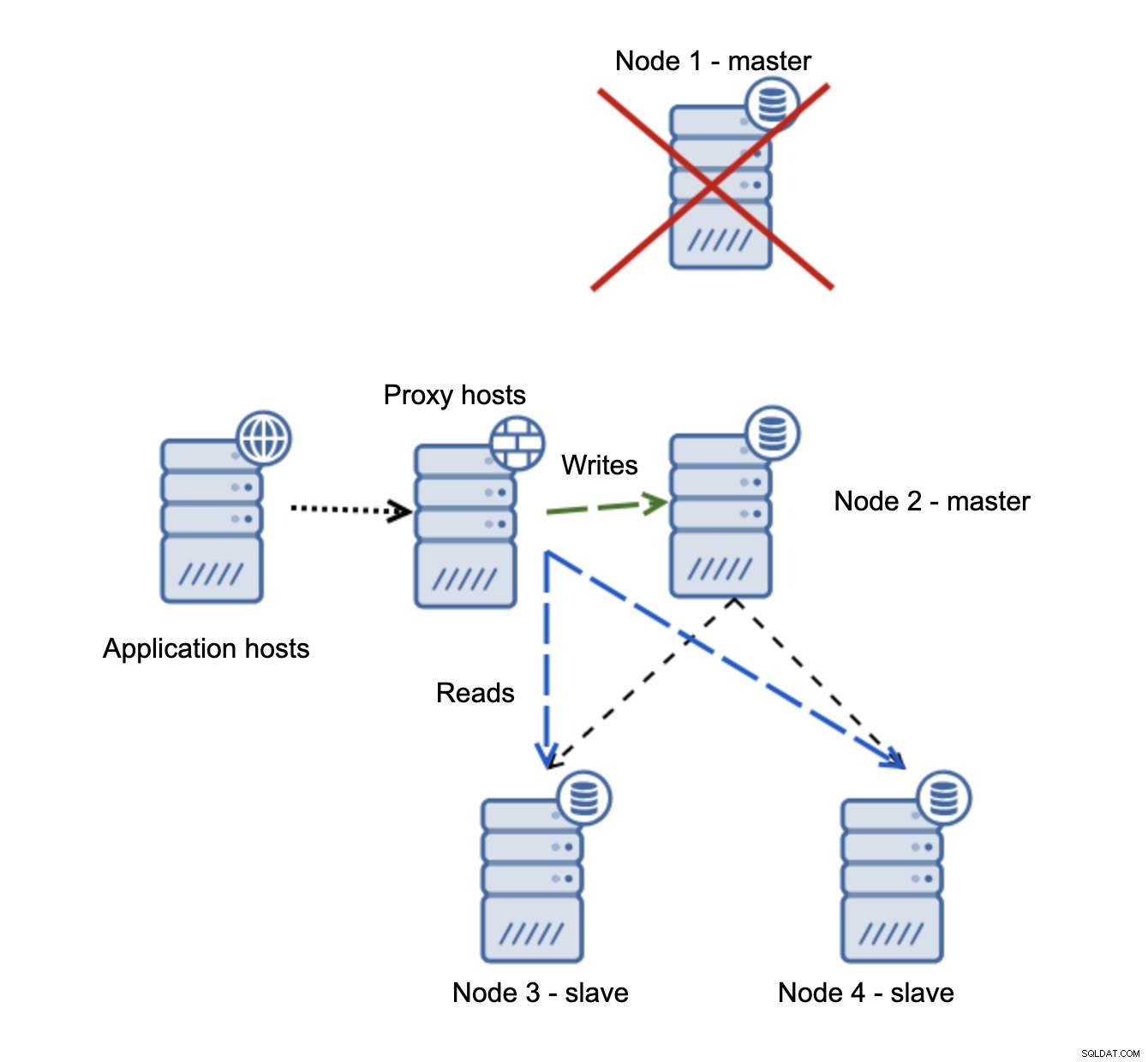
Si node1 redémarre, il affichera read_only=1 et il sera détecté comme esclave. Ce n'est pas idéal car il ne se reproduit pas mais c'est acceptable. Idéalement, l'ancien maître ne devrait pas apparaître du tout jusqu'à ce qu'il soit reconstruit et asservi au nouveau maître.
Une situation bien plus problématique est si nous devons gérer le partitionnement du réseau. Considérons la même configuration :niveau application, niveau proxy et bases de données.
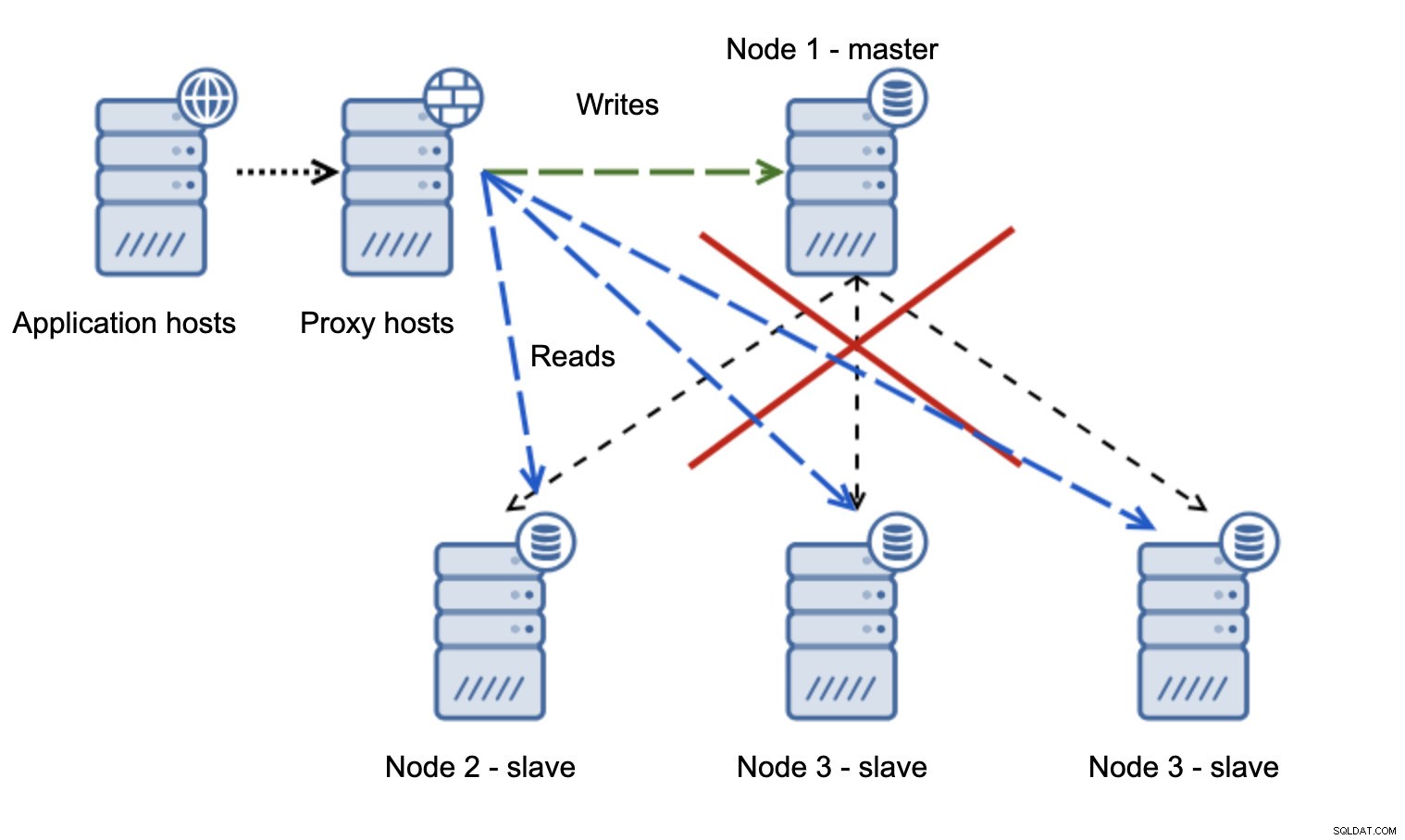
Lorsque le réseau rend le maître inaccessible, l'application n'est pas utilisable car aucune écriture n'atteint sa destination. Le nouveau maître est promu, les écritures y sont redirigées. Que se passera-t-il alors si les problèmes de réseau cessent et que l'ancien maître devient accessible ? Il n'a pas été arrêté, il utilise donc toujours read_only=0 :
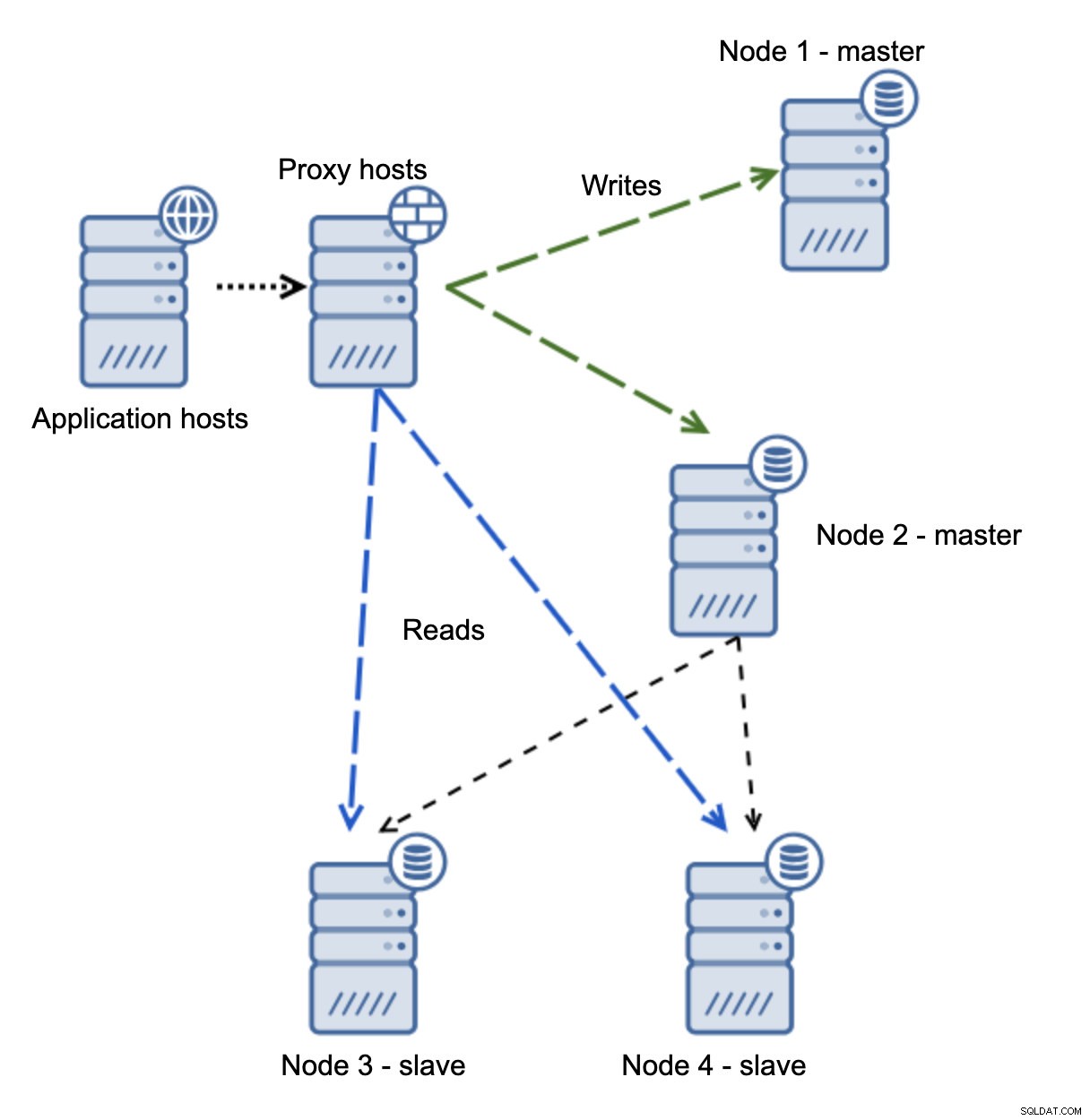
Vous vous êtes maintenant retrouvé dans un cerveau divisé, lorsque les écritures étaient dirigées vers deux nœuds. Cette situation est assez mauvaise car la fusion d'ensembles de données divergents peut prendre un certain temps et c'est un processus assez complexe.
Que peut-on faire pour éviter ce problème ? Il n'y a pas de solution miracle, mais certaines mesures peuvent être prises pour minimiser la probabilité qu'un cerveau divisé se produise.
Tout d'abord, vous pouvez être plus intelligent dans la détection de l'état du maître. Comment les esclaves le voient-ils ? Peuvent-ils répliquer à partir de celui-ci ? Peut-être que certains des esclaves peuvent encore se connecter au maître, ce qui signifie que le maître est opérationnel ou, du moins, qu'il est possible de l'arrêter si cela s'avère nécessaire. Qu'en est-il de la couche proxy ? Tous les nœuds proxy voient-ils le maître comme indisponible ? Si certains peuvent encore se connecter, vous pouvez essayer d'utiliser ces nœuds pour vous connecter en ssh au maître et l'arrêter avant le basculement ?
Le logiciel de gestion du basculement peut également être plus intelligent pour détecter l'état du réseau. Peut-être utilise-t-il RAFT ou un autre protocole de clustering pour créer un cluster sensible au quorum. Si un logiciel de gestion de basculement peut détecter le split brain, il peut également prendre certaines mesures en fonction de cela, comme, par exemple, définir tous les nœuds du segment partitionné sur read_only garantissant que l'ancien maître ne s'affichera pas en écriture lorsque les réseaux convergent.
Vous pouvez également inclure des outils tels que Consul ou Etcd pour stocker l'état du cluster. La couche proxy peut être configurée pour utiliser les données de Consul, et non l'état de la variable read_only. Il appartiendra alors au logiciel de gestion du basculement d'apporter les modifications nécessaires dans Consul afin que tous les proxys envoient le trafic vers un nouveau maître correct.
Certains de ces conseils peuvent même être combinés pour rendre la détection des pannes encore plus fiable. Dans l'ensemble, il est possible de minimiser les risques que le cluster de réplication souffre de réseaux non fiables.
Comme vous pouvez le constater, qu'il s'agisse de Galera ou de réplication MySQL, les réseaux instables peuvent devenir un problème sérieux. D'un autre côté, si vous concevez correctement l'environnement, vous pouvez toujours le faire fonctionner. Nous espérons que cet article de blog vous aidera à créer des environnements qui fonctionneront de manière stable même si les réseaux ne le sont pas.