Avant d'essayer d'effectuer des modifications de schéma sur vos bases de données de production, vous devez vous assurer que vous disposez d'un plan de restauration solide; et que votre procédure de changement a été testée et validée avec succès dans un environnement séparé. Dans le même temps, il est de votre responsabilité de vous assurer que le changement n'entraîne aucun impact acceptable ou le moins possible pour l'entreprise. Ce n'est certainement pas une tâche facile.
Dans cet article, nous verrons comment effectuer des modifications de base de données sur MySQL et MariaDB de manière contrôlée. Nous parlerons de quelques bonnes habitudes dans votre travail quotidien de DBA. Nous nous concentrerons sur les prérequis et les tâches pendant les opérations réelles et les problèmes auxquels vous pourriez être confrontés lorsque vous traitez des modifications de schéma de base de données. Nous parlerons également des outils open source qui peuvent vous aider dans le processus.
Scénarios de test et de restauration
Sauvegarde
Il existe de nombreuses façons de perdre vos données. L'échec de la mise à niveau du schéma en fait partie. Contrairement au code d'application, vous ne pouvez pas déposer un ensemble de fichiers et déclarer qu'une nouvelle version a été déployée avec succès. Vous ne pouvez pas non plus simplement remettre un ancien ensemble de fichiers pour annuler vos modifications. Bien sûr, vous pouvez exécuter un autre script SQL pour modifier à nouveau la base de données, mais il existe des cas où le seul moyen précis d'annuler les modifications consiste à restaurer l'intégralité de la base de données à partir d'une sauvegarde.
Cependant, que se passe-t-il si vous ne pouvez pas vous permettre de restaurer votre base de données à la dernière sauvegarde, ou si votre fenêtre de maintenance n'est pas assez grande (compte tenu des performances du système), vous ne pouvez donc pas effectuer une sauvegarde complète de la base de données avant le changement ?
On peut avoir un environnement sophistiqué et redondant, mais tant que les données sont modifiées à la fois dans les emplacements principaux et de secours, il n'y a pas grand-chose à faire à ce sujet. De nombreux scripts ne peuvent être exécutés qu'une seule fois, ou les modifications sont impossibles à annuler. La majeure partie du code de modification SQL se divise en deux groupes :
- Exécuter une fois :vous ne pouvez pas ajouter deux fois la même colonne au tableau.
- Impossible d'annuler :une fois que vous avez supprimé cette colonne, elle disparaît. Vous pouvez sans aucun doute restaurer votre base de données, mais ce n'est pas précisément une annulation.
Vous pouvez résoudre ce problème d'au moins deux manières possibles. L'une consisterait à activer le journal binaire et à effectuer une sauvegarde compatible avec PITR. Une telle sauvegarde doit être complète, complète et cohérente. Pour xtrabackup, tant qu'il contient un jeu de données complet, il sera compatible PITR. Pour mysqldump, il existe une option pour le rendre également compatible PITR. Pour les changements plus petits, une variante de la sauvegarde mysqldump serait de ne prendre qu'un sous-ensemble de données à modifier. Cela peut être fait avec l'option --where. La sauvegarde doit faire partie de la maintenance planifiée.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlUne autre possibilité consiste à utiliser CREATE TABLE AS SELECT.
Vous pouvez stocker des données ou de simples modifications de structure sous la forme d'une table temporaire fixe. Avec cette approche, vous obtiendrez une source si vous devez annuler vos modifications. Cela peut être très pratique si vous ne modifiez pas beaucoup de données. La restauration peut être effectuée en en extrayant des données. Si des échecs se produisent lors de la copie des données dans la table, elles sont automatiquement supprimées et non créées. Assurez-vous donc que votre instruction crée une copie dont vous avez besoin.
Évidemment, il y a aussi quelques limitations.
Étant donné que l'ordre des lignes dans les instructions SELECT sous-jacentes ne peut pas toujours être déterminé, CREATE TABLE ... IGNORE SELECT et CREATE TABLE ... REPLACE SELECT sont signalés comme dangereux pour la réplication basée sur les instructions. De telles instructions produisent un avertissement dans le journal des erreurs lors de l'utilisation du mode basé sur les instructions et sont écrites dans le journal binaire en utilisant le format basé sur les lignes lors de l'utilisation du mode MIXTE.
Un exemple très simple d'une telle méthode pourrait être :
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Une autre option intéressante peut être la base de données de flashback MariaDB. Lorsqu'une mise à jour ou une suppression erronée se produit et que vous souhaitez revenir à un état de la base de données (ou simplement d'une table) à un certain moment, vous pouvez utiliser la fonction de retour en arrière.
La restauration ponctuelle permet aux administrateurs de base de données de récupérer les données plus rapidement en annulant les transactions à un moment antérieur plutôt qu'en effectuant une restauration à partir d'une sauvegarde. Basé sur les événements DML basés sur ROW, le retour en arrière peut transformer le journal binaire et inverser les objectifs. Cela signifie qu'il peut aider à annuler rapidement les changements de ligne donnés. Par exemple, il peut changer les événements DELETE en INSERT et vice versa, et il permutera les parties WHERE et SET des événements UPDATE. Cette idée simple peut considérablement accélérer la récupération de certains types d'erreurs ou de catastrophes. Pour ceux qui connaissent la base de données Oracle, c'est une fonctionnalité bien connue. La limitation du flashback de MariaDB est le manque de support DDL.
Créer un esclave à réplication différée
Depuis la version 5.6, MySQL prend en charge la réplication différée. Un serveur esclave peut être en retard sur le maître d'au moins un laps de temps spécifié. Le délai par défaut est de 0 seconde. Utilisez l'option MASTER_DELAY pour CHANGE MASTER TO pour définir le délai sur N secondes :
CHANGE MASTER TO MASTER_DELAY = N;Ce serait une bonne option si vous n'aviez pas le temps de préparer un scénario de récupération approprié. Vous devez avoir suffisamment de temps pour remarquer le changement problématique. L'avantage de cette approche est que vous n'avez pas besoin de restaurer votre base de données pour extraire les données nécessaires pour corriger votre modification. La base de données de secours est opérationnelle, prête à récupérer les données, ce qui minimise le temps nécessaire.
Créer un esclave asynchrone qui ne fait pas partie du cluster
En ce qui concerne le cluster Galera, tester les changements n'est pas facile. Tous les nœuds exécutent les mêmes données et une charge importante peut nuire au contrôle de flux. Ainsi, vous devez non seulement vérifier si les modifications ont été appliquées avec succès, mais également quel a été l'impact sur l'état du cluster. Pour rendre votre procédure de test aussi proche que possible de la charge de travail de production, vous pouvez ajouter un esclave asynchrone à votre cluster et y exécuter votre test. Le test n'aura pas d'impact sur la synchronisation entre les nœuds du cluster, car techniquement, il ne fait pas partie du cluster, mais vous aurez la possibilité de le vérifier avec des données réelles. Un tel esclave peut être facilement ajouté à partir de ClusterControl.
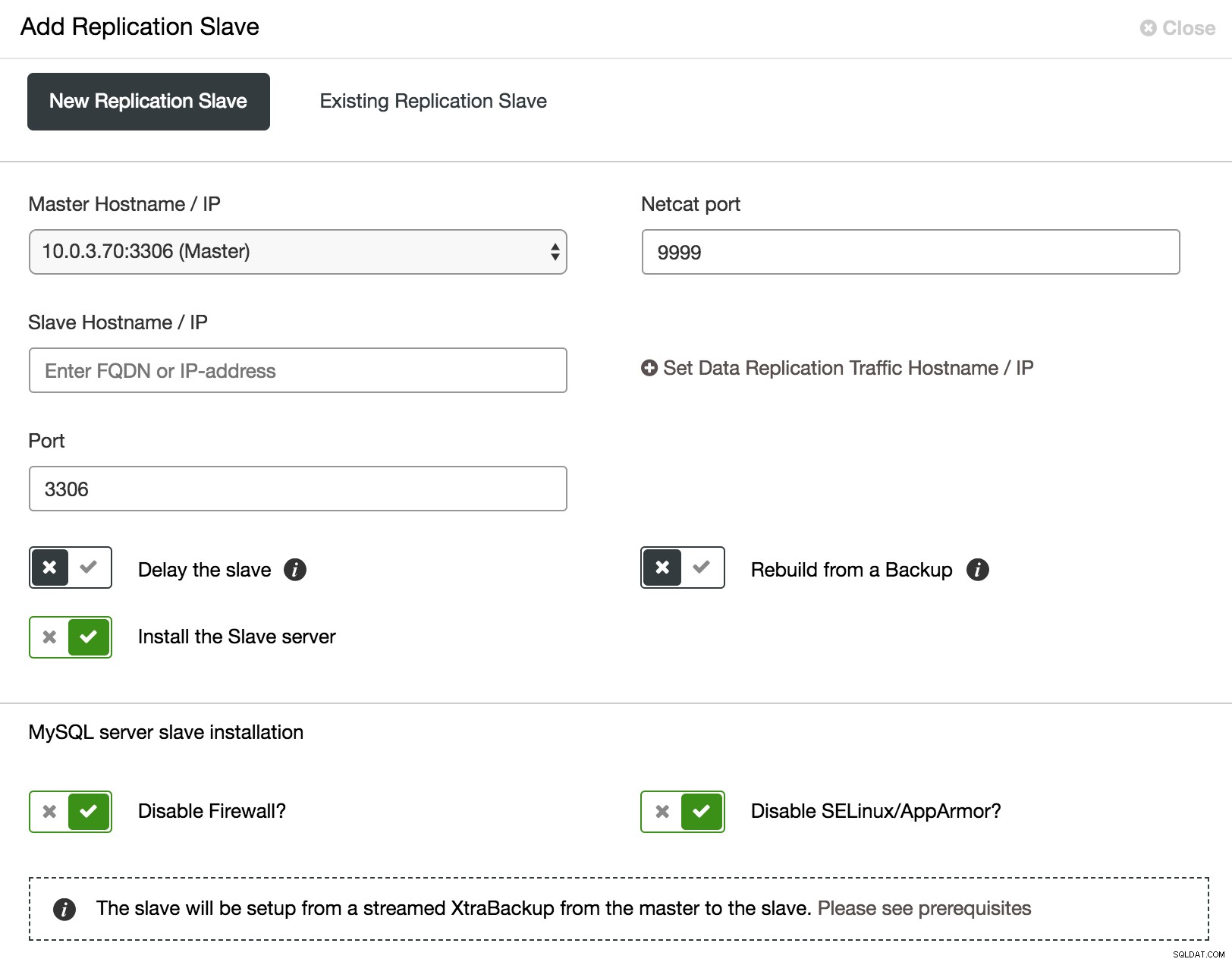 ClusterControl ajoute un esclave asynchrone
ClusterControl ajoute un esclave asynchrone Comme le montre la capture d'écran ci-dessus, ClusterControl peut automatiser le processus d'ajout d'un esclave asynchrone de plusieurs manières. Vous pouvez ajouter le nœud au cluster, retarder l'esclave. Pour réduire l'impact sur le maître, vous pouvez utiliser une sauvegarde existante au lieu du maître comme source de données lors de la création de l'esclave.
Cloner la base de données et mesurer le temps
Un bon test doit être aussi proche que possible du changement de production. La meilleure façon de le faire est de cloner votre environnement existant.
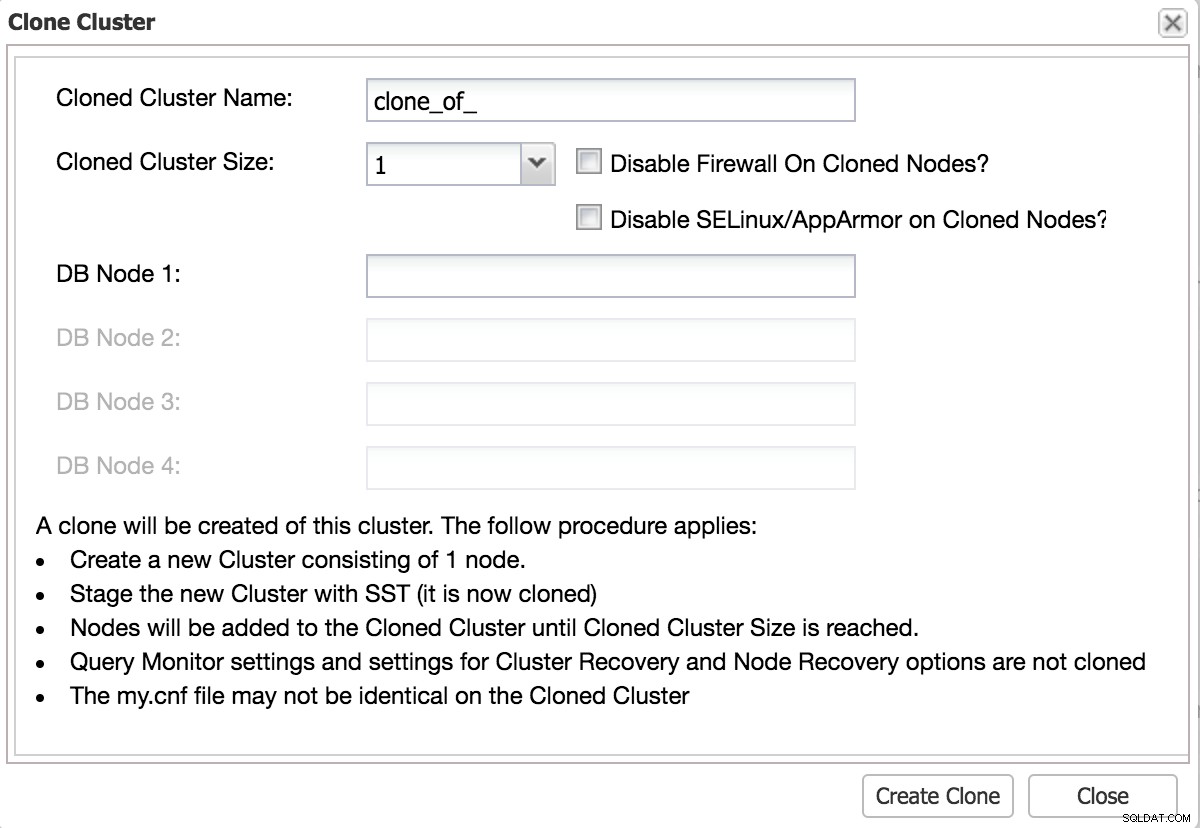 ClusterControl Clone Cluster pour le test
ClusterControl Clone Cluster pour le test Effectuer des modifications via la réplication
Pour avoir un meilleur contrôle sur vos modifications, vous pouvez les appliquer sur un serveur esclave à l'avance, puis effectuer le basculement. Pour la réplication basée sur les instructions, cela fonctionne bien, mais pour la réplication basée sur les lignes, cela peut fonctionner jusqu'à un certain degré. La réplication basée sur les lignes permet à des colonnes supplémentaires d'exister à la fin de la table, donc tant qu'elle peut écrire les premières colonnes, tout ira bien. Appliquez d'abord ces paramètres à tous les esclaves, puis basculez vers l'un des esclaves, puis appliquez la modification au maître et attachez-le en tant qu'esclave. Si votre modification implique l'insertion ou la suppression d'une colonne au milieu de la table, cela fonctionnera avec la réplication basée sur les lignes.
Fonctionnement
Pendant la fenêtre de maintenance, nous ne souhaitons pas avoir de trafic applicatif sur la base de données. Parfois, il est difficile de fermer toutes les applications réparties dans toute l'entreprise. Alternativement, nous souhaitons autoriser uniquement certains hôtes spécifiques à accéder à MySQL à distance (par exemple, le système de surveillance ou le serveur de sauvegarde). Pour cela, nous pouvons utiliser le filtrage de paquets Linux. Pour voir quelles règles de filtrage de paquets sont disponibles, nous pouvons exécuter la commande suivante :
iptables -L INPUT -vPour fermer le port MySQL sur toutes les interfaces que nous utilisons :
iptables -A INPUT -p tcp --dport mysql -j DROPet pour ouvrir à nouveau le port MySQL après la fenêtre de maintenance :
iptables -D INPUT -p tcp --dport mysql -j DROPPour ceux qui n'ont pas d'accès root, vous pouvez changer max_connection en 1 ou 'ignorer la mise en réseau'.
Journalisation
Pour lancer le processus de journalisation, utilisez la commande tee à l'invite du client MySQL, comme ceci :
mysql> tee /tmp/my.out;Cette commande indique à MySQL de consigner à la fois l'entrée et la sortie de votre session de connexion MySQL actuelle dans un fichier nommé /tmp/my.out . Ensuite, exécutez votre fichier de script avec la commande source.
Pour avoir une meilleure idée de vos temps d'exécution, vous pouvez le combiner avec la fonction de profileur. Démarrez le profileur avec
SET profiling = 1;Exécutez ensuite votre requête avec
SHOW PROFILES;vous voyez une liste de requêtes pour lesquelles le profileur dispose de statistiques. Donc, finalement, vous choisissez la requête à examiner avec
SHOW PROFILE FOR QUERY 1;Outils de migration de schéma
Souvent, un ALTER direct sur le maître n'est pas possible - la plupart du temps, cela provoque un décalage sur l'esclave, ce qui peut ne pas être acceptable pour les applications. Ce qui peut être fait, cependant, est d'exécuter le changement en mode continu. Vous pouvez commencer avec des esclaves et, une fois la modification appliquée à l'esclave, migrer l'un des esclaves en tant que nouveau maître, rétrograder l'ancien maître en esclave et exécuter la modification sur celui-ci.
Un outil qui peut aider à une telle tâche est le pt-online-schema-change de Percona. Pt-online-schema-change est simple - il crée une table temporaire avec le nouveau schéma souhaité (par exemple, si nous avons ajouté un index ou supprimé une colonne d'une table). Ensuite, il crée des déclencheurs sur l'ancienne table. Ces déclencheurs sont là pour refléter les changements qui se produisent sur la table d'origine vers la nouvelle table. Les changements sont mis en miroir pendant le processus de changement de schéma. Si une ligne est ajoutée au tableau d'origine, elle est également ajoutée au nouveau. Il émule la façon dont MySQL modifie les tables en interne, mais il fonctionne sur une copie de la table que vous souhaitez modifier. Cela signifie que la table d'origine n'est pas verrouillée et que les clients peuvent continuer à lire et à modifier les données qu'elle contient.
De même, si une ligne est modifiée ou supprimée sur l'ancienne table, elle est également appliquée dans la nouvelle table. Ensuite, un processus en arrière-plan de copie de données (à l'aide de LOW_PRIORITY INSERT) entre l'ancienne et la nouvelle table commence. Une fois les données copiées, RENAME TABLE est exécuté.
Un autre outil intéressant est gh-ost. Gh-ost crée une table temporaire avec le schéma modifié, tout comme le fait pt-online-schema-change. Il exécute des requêtes INSERT, qui utilisent le modèle suivant pour copier les données de l'ancienne vers la nouvelle table. Néanmoins, il n'utilise pas de déclencheurs. Malheureusement, les déclencheurs peuvent être à l'origine de nombreuses limitations. gh-ost utilise le flux de journal binaire pour capturer les modifications de table et les applique de manière asynchrone sur la table fantôme. Une fois que nous avons vérifié que gh-ost peut exécuter correctement notre changement de schéma, il est temps de l'exécuter réellement. Gardez à l'esprit que vous devrez peut-être supprimer manuellement les anciennes tables créées par gh-ost lors du processus de test de la migration. Vous pouvez également utiliser les drapeaux --initially-drop-ghost-table et --initially-drop-old-table pour demander à gh-ost de le faire pour vous. La commande finale à exécuter est exactement la même que celle que nous avons utilisée pour tester notre modification, nous y avons juste ajouté --execute.
pt-online-schema-change et gh-ost sont très populaires parmi les utilisateurs de Galera. Néanmoins, Galera propose des options supplémentaires. Les deux méthodes Total Order Isolation (TOI) et Rolling Schema Upgrade (RSU) ont leurs avantages et leurs inconvénients.
TOI - Il s'agit de la méthode de réplication DDL par défaut. Le nœud à l'origine du jeu d'écriture détecte DDL au moment de l'analyse et envoie un événement de réplication pour l'instruction SQL avant même de démarrer le traitement DDL. Les mises à niveau de schéma s'exécutent sur tous les nœuds de cluster dans la même séquence de commande totale, empêchant les autres transactions de s'engager pendant la durée de l'opération. Cette méthode est utile lorsque vous souhaitez que vos mises à niveau de schéma en ligne soient répliquées via le cluster et que cela ne vous dérange pas de verrouiller l'intégralité de la table (similaire à la façon dont les modifications de schéma par défaut se sont produites dans MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU - effectue les mises à niveau de schéma localement. Dans cette méthode, vos écritures n'affectent que le nœud sur lequel elles sont exécutées. Les modifications ne sont pas répliquées sur le reste du cluster. Cette méthode convient aux opérations non conflictuelles et ne ralentit pas le cluster.
SET GLOBAL wsrep_OSU_method='RSU';Pendant que le nœud traite la mise à niveau du schéma, il se désynchronise avec le cluster. Lorsqu'il termine le traitement de la mise à niveau du schéma, il applique les événements de réplication différée et se synchronise avec le cluster. Cela pourrait être une bonne option pour exécuter des créations d'index lourdes.
Conclusion
Nous avons présenté ici plusieurs méthodes différentes qui peuvent vous aider à planifier vos modifications de schéma. Bien sûr, tout dépend de votre application et des exigences de votre entreprise. Vous pouvez concevoir votre plan de changement, effectuer les tests nécessaires, mais il y a toujours une petite chance que quelque chose se passe mal. Selon la loi de Murphy - "les choses iront mal dans une situation donnée, si vous leur donnez une chance". Assurez-vous donc d'essayer différentes façons d'effectuer ces modifications et choisissez celle avec laquelle vous êtes le plus à l'aise.



