Les coûts des sous-arbres doivent être pris avec un gros grain de sel (et en particulier lorsque vous avez d'énormes erreurs de cardinalité). SET STATISTICS IO ON; SET STATISTICS TIME ON; la sortie est un meilleur indicateur des performances réelles.
Le tri à zéro ligne ne prend pas 87 % des ressources. Ce problème dans votre plan en est un d'estimation des statistiques. Les coûts indiqués dans le plan réel sont toujours des coûts estimés. Il ne les ajuste pas pour tenir compte de ce qui s'est réellement passé.
Il y a un point dans le plan où un filtre réduit 1 911 721 lignes à 0, mais les lignes estimées à l'avenir sont de 1 860 310. Par la suite, tous les coûts sont faux, aboutissant au coût estimé de 87 % pour le tri de 3 348 560 lignes.
L'erreur d'estimation de cardinalité peut être reproduite en dehors de la Merge déclaration en examinant le plan estimé pour la Full Outer Join avec des prédicats équivalents (donne la même estimation de 1 860 310 lignes).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Cela dit, cependant, le plan jusqu'au filtre lui-même semble assez sous-optimal. Il effectue une analyse complète de l'index cluster lorsque vous souhaitez peut-être un plan avec 2 recherches de plage d'index cluster. L'un pour récupérer la ligne unique correspondant à la clé primaire de la jointure sur la source et l'autre pour récupérer le T.Key1 = @id plage (bien que cela soit peut-être pour éviter d'avoir à trier plus tard dans l'ordre des clés groupées ?)
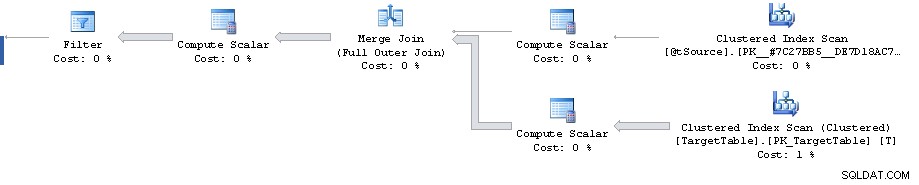
Peut-être pourriez-vous essayer cette réécriture et voir si cela fonctionne mieux ou moins bien
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;