Les sept classes d'implémentation de tri SQL Server sont :
- CQScanSortNouveau
- CQScanTopSortNouveau
- CQScanIndexSortNouveau
- CQScanPartitionSortNew (SQL Server 2014 uniquement)
- CQScanInMemSortNouveau
- Procédure OLTP en mémoire (Hekaton) compilée nativement Top N Sort (SQL Server 2014 uniquement)
- Procédure OLTP en mémoire (Hekaton) compilée nativement Tri général (SQL Server 2014 uniquement)
Les quatre premiers types ont été couverts dans la première partie de cet article.
5. CQScanInMemSortNouveau
Cette classe de tri possède un certain nombre de fonctionnalités intéressantes, dont certaines sont uniques :
- Comme son nom l'indique, il trie toujours entièrement en mémoire ; il ne se renversera jamais sur tempdb
- Le tri est toujours effectué à l'aide de quicksort qsort_s dans la bibliothèque d'exécution C standard MSVCR100
- Il peut effectuer les trois types de tri logique :Général, Top N et Tri distinct.
- Il peut être utilisé pour les tris progressifs par partition clustered columnstore (voir la section 4 de la partie 1)
- La mémoire qu'il utilise peut être mise en cache avec le plan plutôt que d'être réservée juste avant l'exécution
- Il peut être identifié comme un tri en mémoire dans les plans d'exécution
- Un maximum de 500 valeurs peuvent être triées
- Il n'est jamais utilisé pour les tris de création d'index (voir section 3 dans la partie 1)
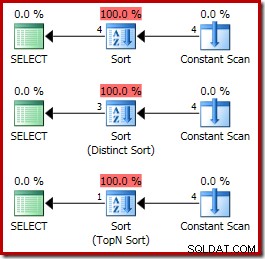
CQScanInMemSortNouveau est une classe de tri que vous ne rencontrerez pas souvent. Puisqu'il trie toujours en mémoire à l'aide d'un algorithme de tri rapide de bibliothèque standard, ce ne serait pas un bon choix pour les tâches générales de tri de base de données. En fait, cette classe de tri n'est utilisée que lorsque toutes ses entrées sont des constantes d'exécution (y compris les références @variable). Du point de vue du plan d'exécution, cela signifie que l'entrée de l'opérateur de tri doit être un Balayage constant opérateur, comme le montrent les exemples ci-dessous :
-- Regular Sort on system scalar functions
SELECT X.i
FROM
(
SELECT @@TIMETICKS UNION ALL
SELECT @@TOTAL_ERRORS UNION ALL
SELECT @@TOTAL_READ UNION ALL
SELECT @@TOTAL_WRITE
) AS X (i)
ORDER BY X.i;
-- Distinct Sort on constant literals
WITH X (i) AS
(
SELECT 3 UNION ALL
SELECT 1 UNION ALL
SELECT 1 UNION ALL
SELECT 2
)
SELECT DISTINCT X.i
FROM X
ORDER BY X.i;
-- Top N Sort on variables, constants, and functions
DECLARE
@x integer = 1,
@y integer = 2;
SELECT TOP (1)
X.i
FROM
(
VALUES
(@x), (@y), (123),
(@@CONNECTIONS)
) AS X (i)
ORDER BY X.i; Les plans d'exécution sont :
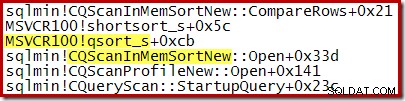
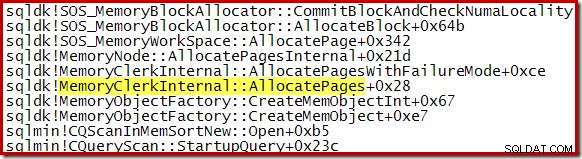
Une pile d'appels typique pendant le tri est illustrée ci-dessous. Notez l'appel à qsort_s dans la bibliothèque MSVCR100 :
Les trois plans d'exécution présentés ci-dessus sont des tris en mémoire utilisant CQScanInMemSortNew avec des entrées suffisamment petites pour que la mémoire de tri soit mise en cache. Ces informations ne sont pas exposées par défaut dans les plans d'exécution, mais elles peuvent être révélées à l'aide de l'indicateur de trace non documenté 8666. Lorsque cet indicateur est actif, des propriétés supplémentaires apparaissent pour l'opérateur de tri :
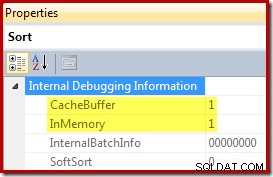
Le tampon de cache est limité à 62 lignes dans cet exemple, comme illustré ci-dessous :
-- Cache buffer limited to 62 rows
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062)--, (063)
) AS X (i)
ORDER BY X.i; Décommentez le dernier élément de ce script pour voir la propriété Sort cache buffer passer de 1 à 0 :
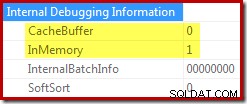
Lorsque le tampon n'est pas mis en cache, le tri en mémoire doit allouer de la mémoire lors de son initialisation et selon les besoins lors de la lecture des lignes à partir de son entrée. Lorsqu'un tampon en cache peut être utilisé, ce travail d'allocation de mémoire est évité.
Le script suivant peut être utilisé pour démontrer que le nombre maximal d'éléments pour un CQScanInMemSortNew le tri rapide en mémoire est de 500 :
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062),(063),(064),(065),(066),(067),(068),(069),(070),
(071),(072),(073),(074),(075),(076),(077),(078),(079),(080),
(081),(082),(083),(084),(085),(086),(087),(088),(089),(090),
(091),(092),(093),(094),(095),(096),(097),(098),(099),(100),
(101),(102),(103),(104),(105),(106),(107),(108),(109),(110),
(111),(112),(113),(114),(115),(116),(117),(118),(119),(120),
(121),(122),(123),(124),(125),(126),(127),(128),(129),(130),
(131),(132),(133),(134),(135),(136),(137),(138),(139),(140),
(141),(142),(143),(144),(145),(146),(147),(148),(149),(150),
(151),(152),(153),(154),(155),(156),(157),(158),(159),(160),
(161),(162),(163),(164),(165),(166),(167),(168),(169),(170),
(171),(172),(173),(174),(175),(176),(177),(178),(179),(180),
(181),(182),(183),(184),(185),(186),(187),(188),(189),(190),
(191),(192),(193),(194),(195),(196),(197),(198),(199),(200),
(201),(202),(203),(204),(205),(206),(207),(208),(209),(210),
(211),(212),(213),(214),(215),(216),(217),(218),(219),(220),
(221),(222),(223),(224),(225),(226),(227),(228),(229),(230),
(231),(232),(233),(234),(235),(236),(237),(238),(239),(240),
(241),(242),(243),(244),(245),(246),(247),(248),(249),(250),
(251),(252),(253),(254),(255),(256),(257),(258),(259),(260),
(261),(262),(263),(264),(265),(266),(267),(268),(269),(270),
(271),(272),(273),(274),(275),(276),(277),(278),(279),(280),
(281),(282),(283),(284),(285),(286),(287),(288),(289),(290),
(291),(292),(293),(294),(295),(296),(297),(298),(299),(300),
(301),(302),(303),(304),(305),(306),(307),(308),(309),(310),
(311),(312),(313),(314),(315),(316),(317),(318),(319),(320),
(321),(322),(323),(324),(325),(326),(327),(328),(329),(330),
(331),(332),(333),(334),(335),(336),(337),(338),(339),(340),
(341),(342),(343),(344),(345),(346),(347),(348),(349),(350),
(351),(352),(353),(354),(355),(356),(357),(358),(359),(360),
(361),(362),(363),(364),(365),(366),(367),(368),(369),(370),
(371),(372),(373),(374),(375),(376),(377),(378),(379),(380),
(381),(382),(383),(384),(385),(386),(387),(388),(389),(390),
(391),(392),(393),(394),(395),(396),(397),(398),(399),(400),
(401),(402),(403),(404),(405),(406),(407),(408),(409),(410),
(411),(412),(413),(414),(415),(416),(417),(418),(419),(420),
(421),(422),(423),(424),(425),(426),(427),(428),(429),(430),
(431),(432),(433),(434),(435),(436),(437),(438),(439),(440),
(441),(442),(443),(444),(445),(446),(447),(448),(449),(450),
(451),(452),(453),(454),(455),(456),(457),(458),(459),(460),
(461),(462),(463),(464),(465),(466),(467),(468),(469),(470),
(471),(472),(473),(474),(475),(476),(477),(478),(479),(480),
(481),(482),(483),(484),(485),(486),(487),(488),(489),(490),
(491),(492),(493),(494),(495),(496),(497),(498),(499),(500)
--, (501)
) AS X (i)
ORDER BY X.i; Encore une fois, décommentez le dernier élément pour voir le InMemory Trier le changement de propriété de 1 à 0. Lorsque cela se produit, CQScanInMemSortNew est remplacé soit par CQScanSortNew (voir section 1) ou CQScanTopSortNew (section 2). Un non-CQScanInMemSortNew le tri peut toujours être effectué en mémoire, bien sûr, il utilise simplement un algorithme différent et est autorisé à se répandre sur tempdb si nécessaire.
6. Procédure stockée compilée nativement OLTP en mémoire Top N Sort
L'implémentation actuelle des procédures stockées nativement compilées OLTP en mémoire (anciennement Hekaton) utilise une file d'attente prioritaire suivie de qsort_s pour les N premiers tris, lorsque les conditions suivantes sont remplies :
- La requête contient TOP (N) avec une clause ORDER BY
- La valeur de N est un littéral constant (pas une variable)
- N a une valeur maximale de 8192 ; même si
- La présence de jointures ou d'agrégations peut réduire la valeur 8192, comme documenté ici
Le code suivant crée une table Hekaton contenant 4 000 lignes :
CREATE DATABASE InMemoryOLTP;
GO
-- Add memory optimized filegroup
ALTER DATABASE InMemoryOLTP
ADD FILEGROUP InMemoryOLTPFileGroup
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
-- Add file (adjust path if necessary)
ALTER DATABASE InMemoryOLTP
ADD FILE
(
NAME = N'IMOLTP',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\IMOLTP.hkf'
)
TO FILEGROUP InMemoryOLTPFileGroup;
GO
USE InMemoryOLTP;
GO
CREATE TABLE dbo.Test
(
col1 integer NOT NULL,
col2 integer NOT NULL,
col3 integer NOT NULL,
CONSTRAINT PK_dbo_Test
PRIMARY KEY NONCLUSTERED HASH (col1)
WITH (BUCKET_COUNT = 8192)
)
WITH
(
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY
);
GO
-- Add numbers from 1-4000 using
-- Itzik Ben-Gan's number generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 1 AND 4000; Le script suivant crée un Top N Sort approprié dans une procédure stockée compilée nativement :
-- Natively-compiled Top N Sort stored procedure
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT TOP (2) T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; Le plan d'exécution estimé est :

Une pile d'appels capturée lors de l'exécution montre l'insertion dans la file d'attente prioritaire en cours :

Une fois la construction de la file d'attente prioritaire terminée, la pile d'appels suivante affiche une dernière passe dans le tri rapide de la bibliothèque standard :
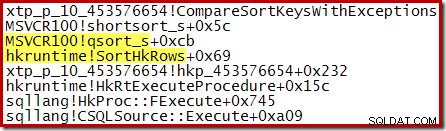
Le xtp_p_* La bibliothèque affichée dans ces piles d'appels est la dll compilée en mode natif pour la procédure stockée, avec le code source enregistré sur l'instance locale de SQL Server. Le code source est généré automatiquement à partir de la définition de la procédure stockée. Par exemple, le fichier C de cette procédure stockée native contient le fragment suivant :
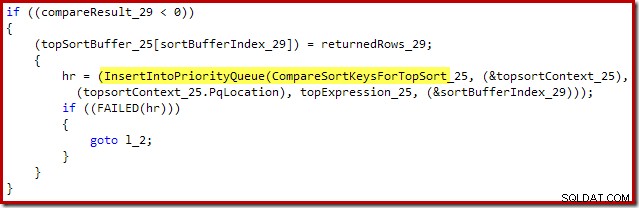
C'est aussi proche que possible d'avoir accès au code source de SQL Server.
7. Procédure stockée compilée nativement OLTP en mémoire Sort
Les procédures compilées en mode natif ne prennent actuellement pas en charge le tri distinct, mais le tri général non distinct est pris en charge, sans aucune restriction sur la taille de l'ensemble. Pour illustrer, nous allons d'abord ajouter 6 000 lignes à la table de test, ce qui donne un total de 10 000 lignes :
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 4001 AND 10000; Nous pouvons maintenant supprimer la procédure de test précédente (les procédures compilées en mode natif ne peuvent actuellement pas être modifiées) et en créer une nouvelle qui effectue un tri ordinaire (pas top-n) des 10 000 lignes :
DROP PROCEDURE dbo.TestP;
GO
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; Le plan d'exécution estimé est :

Le suivi de l'exécution de ce tri montre qu'il commence par générer plusieurs petites exécutions triées en utilisant à nouveau le tri rapide de la bibliothèque standard :
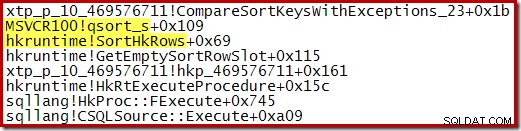
Une fois ce processus terminé, les exécutions triées sont fusionnées, en utilisant un schéma de file d'attente prioritaire :
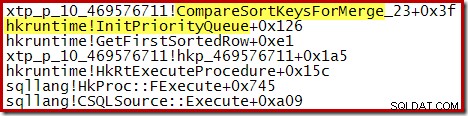
Encore une fois, le code source C de la procédure montre certains détails :
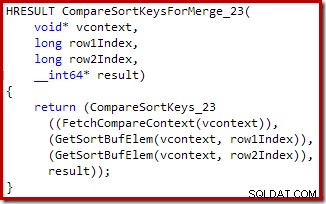
Résumé de la partie 2
- CQScanInMemSortNouveau est toujours un tri rapide en mémoire. Il est limité à 500 lignes à partir d'un balayage constant et peut mettre en cache sa mémoire de tri pour les petites entrées. Un tri peut être identifié comme un CQScanInMemSortNew trier en utilisant les propriétés du plan d'exécution exposées par l'indicateur de trace 8666.
- Le tri Top N compilé natif Hekaton nécessite une valeur littérale constante pour N <=8192 et trie en utilisant une file d'attente prioritaire suivie d'un tri rapide standard
- Le tri général compilé natif Hekaton peut trier n'importe quel nombre de lignes, en utilisant le tri rapide de la bibliothèque standard pour générer des exécutions de tri, et un tri de fusion de file d'attente prioritaire pour combiner les exécutions. Il ne prend pas en charge le tri distinct.