Le terme clé ici est EN LIGNE FONCTIONS VALORISÉES TABLE . Vous disposez de deux types de fonctions à valeur tabulée T-SQL :multi-instructions et inline. Si votre fonction T-SQL commence par une instruction BEGIN, alors ce sera de la merde - scalaire ou autre. Vous ne pouvez pas obtenir une table temporaire dans un inline fonction de table, donc je suppose que vous êtes passé d'une fonction scalaire à une fonction de table multi-instructions, ce qui sera probablement pire.
Votre fonction de table en ligne (iTVF) devrait ressembler à ceci :
CREATE FUNCTION [dbo].[Compute_value]
(
@alpha FLOAT,
@bravo FLOAT,
@charle FLOAT,
@delta FLOAT
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT newValue =
CASE WHEN @alpha IS NULL OR @alpha = 0 OR @delta IS NULL OR @delta = 0 THEN 0
WHEN @bravo IS NULL OR @bravo <= 0 THEN 100
ELSE @alpha * POWER((100 / @delta),
(-2 * POWER(@charle * @bravo, DATEDIFF(<unit of measurement>,GETDATE(),'1/1/2000')/365)))
END
GO;
Notez que, dans le code que vous avez posté, votre DATEDIFF il manque à l'instruction datepart paramètre. Si cela devrait ressembler à :
@x int = DATEDIFF(DAY, GETDATE(),'1/1/2000')
Pour aller un peu plus loin - il est important de comprendre pourquoi les iTVF sont meilleurs que les fonctions définies par l'utilisateur à valeur scalaire T-SQL. Ce n'est pas parce que les fonctions à valeur de table sont plus rapides que les fonctions à valeur scalaire, c'est parce que l'implémentation par Microsoft des fonctions en ligne T-SQL est plus rapide que leur implémentation des fonctions T-SQL qui ne sont pas en ligne. Notez les trois fonctions suivantes qui font la même chose :
-- Scalar version
CREATE FUNCTION dbo.Compute_value_scalar
(
@alpha FLOAT,
@bravo FLOAT,
@charle FLOAT,
@delta FLOAT
)
RETURNS FLOAT
AS
BEGIN
IF @alpha IS NULL OR @alpha = 0 OR @delta IS NULL OR @delta = 0
RETURN 0
IF @bravo IS NULL OR @bravo <= 0
RETURN 100
IF (@charle + @delta) / @bravo <= 0
RETURN 100
DECLARE @x int = DATEDIFF(dd, GETDATE(),'1/1/2000')
RETURN @alpha * POWER((100 / @delta), (-2 * POWER(@charle * @bravo, @x/365)))
END
GO
-- multi-statement table valued function
CREATE FUNCTION dbo.Compute_value_mtvf
(
@alpha FLOAT,
@bravo FLOAT,
@charle FLOAT,
@delta FLOAT
)
RETURNS @sometable TABLE (newValue float) AS
BEGIN
INSERT @sometable VALUES
(
CASE WHEN @alpha IS NULL OR @alpha = 0 OR @delta IS NULL OR @delta = 0 THEN 0
WHEN @bravo IS NULL OR @bravo <= 0 THEN 100
ELSE @alpha * POWER((100 / @delta),
(-2 * POWER(@charle * @bravo, DATEDIFF(DAY,GETDATE(),'1/1/2000')/365)))
END
)
RETURN;
END
GO
-- INLINE table valued function
CREATE FUNCTION dbo.Compute_value_itvf
(
@alpha FLOAT,
@bravo FLOAT,
@charle FLOAT,
@delta FLOAT
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT newValue =
CASE WHEN @alpha IS NULL OR @alpha = 0 OR @delta IS NULL OR @delta = 0 THEN 0
WHEN @bravo IS NULL OR @bravo <= 0 THEN 100
ELSE @alpha * POWER((100 / @delta),
(-2 * POWER(@charle * @bravo, DATEDIFF(DAY,GETDATE(),'1/1/2000')/365)))
END
GO
Maintenant, quelques exemples de données et de test de performances :
SET NOCOUNT ON;
CREATE TABLE #someTable (alpha FLOAT, bravo FLOAT, charle FLOAT, delta FLOAT);
INSERT #someTable
SELECT TOP (100000)
abs(checksum(newid())%10)+1, abs(checksum(newid())%10)+1,
abs(checksum(newid())%10)+1, abs(checksum(newid())%10)+1
FROM sys.all_columns a, sys.all_columns b;
PRINT char(10)+char(13)+'scalar'+char(10)+char(13)+replicate('-',60);
GO
DECLARE @st datetime = getdate(), @z float;
SELECT @z = dbo.Compute_value_scalar(t.alpha, t.bravo, t.charle, t.delta)
FROM #someTable t;
PRINT DATEDIFF(ms, @st, getdate());
GO
PRINT char(10)+char(13)+'mtvf'+char(10)+char(13)+replicate('-',60);
GO
DECLARE @st datetime = getdate(), @z float;
SELECT @z = f.newValue
FROM #someTable t
CROSS APPLY dbo.Compute_value_mtvf(t.alpha, t.bravo, t.charle, t.delta) f;
PRINT DATEDIFF(ms, @st, getdate());
GO
PRINT char(10)+char(13)+'itvf'+char(10)+char(13)+replicate('-',60);
GO
DECLARE @st datetime = getdate(), @z float;
SELECT @z = f.newValue
FROM #someTable t
CROSS APPLY dbo.Compute_value_itvf(t.alpha, t.bravo, t.charle, t.delta) f;
PRINT DATEDIFF(ms, @st, getdate());
GO
Résultats :
scalar
------------------------------------------------------------
2786
mTVF
------------------------------------------------------------
41536
iTVF
------------------------------------------------------------
153
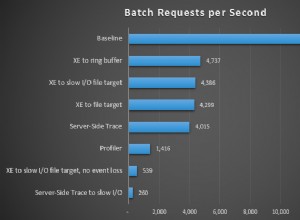
L'udf scalaire a duré 2,7 secondes, 41 secondes pour le mtvf et 0,153 seconde pour l'iTVF. Pour comprendre pourquoi, examinons les plans d'exécution estimés :

Vous ne voyez pas cela lorsque vous regardez le plan d'exécution réel mais, avec les scalaires udf et mtvf, l'optimiseur appelle une sous-routine mal exécutée pour chaque ligne ; l'iTVF ne le fait pas. Citant le changement de carrière de Paul White article sur APPLIQUER Paul écrit :
En d'autres termes, les iTVF permettent à l'optimiseur d'optimiser la requête d'une manière qui n'est tout simplement pas possible lorsque tout ce code doit être exécuté. L'un des nombreux autres exemples de la supériorité des iTVF est qu'ils sont le seul des trois types de fonctions susmentionnés à permettre le parallélisme. Exécutons chaque fonction une fois de plus, cette fois avec le plan d'exécution réel activé et avec le traceflag 8649 (qui force un plan d'exécution parallèle) :
-- don't need so many rows for this test
TRUNCATE TABLE #sometable;
INSERT #someTable
SELECT TOP (10)
abs(checksum(newid())%10)+1, abs(checksum(newid())%10)+1,
abs(checksum(newid())%10)+1, abs(checksum(newid())%10)+1
FROM sys.all_columns a;
DECLARE @x float;
SELECT TOP (10) @x = dbo.Compute_value_scalar(t.alpha, t.bravo, t.charle, t.delta)
FROM #someTable t
ORDER BY dbo.Compute_value_scalar(t.alpha, t.bravo, t.charle, t.delta)
OPTION (QUERYTRACEON 8649);
SELECT TOP (10) @x = f.newValue
FROM #someTable t
CROSS APPLY dbo.Compute_value_mtvf(t.alpha, t.bravo, t.charle, t.delta) f
ORDER BY f.newValue
OPTION (QUERYTRACEON 8649);
SELECT @x = f.newValue
FROM #someTable t
CROSS APPLY dbo.Compute_value_itvf(t.alpha, t.bravo, t.charle, t.delta) f
ORDER BY f.newValue
OPTION (QUERYTRACEON 8649);
Plans d'exécution :

Ces flèches que vous voyez pour le plan d'exécution de l'iTVF sont le parallélisme - tous vos CPU (ou autant que le MAXDOP de votre instance SQL paramètres le permettent) travaillant ensemble. Les UDF scalaires T-SQL et mtvf ne peuvent pas faire cela. Lorsque Microsoft introduit les UDF scalaires en ligne, je suggérerais celles-ci pour ce que vous faites, mais jusque-là :si les performances sont ce que vous recherchez, alors en ligne est la seule solution et, pour cela, les iTVF sont le seul jeu. en ville.
Notez que j'ai continuellement souligné T-SQL quand on parle de fonctions... Les fonctions scalaires et tabulaires CLR peuvent convenir, mais c'est un autre sujet.