Le principe « Ne vous répétez pas » suggère que vous devriez réduire la répétition. Cette semaine, je suis tombé sur un cas où DRY devrait être jeté par la fenêtre. Il existe également d'autres cas (par exemple, des fonctions scalaires), mais celui-ci était intéressant impliquant la logique Bitwise.
Imaginons le tableau suivant :
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Les bits "WheelFlag" représentent les options suivantes :
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Les combinaisons possibles sont donc :
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Laissons de côté les arguments, du moins pour l'instant, sur la question de savoir si cela devrait être emballé dans un seul TINYINT en premier lieu, ou stocké dans des colonnes séparées, ou utiliser un modèle EAV... la fixation de la conception est un problème distinct. Il s'agit de travailler avec ce que vous avez.
Pour rendre les exemples utiles, remplissons ce tableau avec un tas de données aléatoires. (Et nous supposerons, pour plus de simplicité, que ce tableau ne contient que les commandes qui n'ont pas encore été expédiées.) Cela insèrera 50 000 lignes de distribution à peu près égale entre les six combinaisons d'options :
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Si nous regardons la répartition, nous pouvons voir cette distribution. Notez que vos résultats peuvent différer légèrement des miens en fonction des objets de votre système :
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Résultats :
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Maintenant, disons que c'est mardi, et que nous venons de recevoir une cargaison de roues de 18", qui étaient auparavant en rupture de stock. Cela signifie que nous sommes en mesure de satisfaire toutes les commandes nécessitant des roues de 18", à la fois celles qui ont amélioré les pneus (6), et ceux qui ne l'ont pas fait (2). Donc, nous *pourrions* écrire une requête comme celle-ci :
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Dans la vraie vie, bien sûr, vous ne pouvez pas vraiment faire cela; que se passe-t-il si d'autres options sont ajoutées ultérieurement, comme des verrous de roue, une garantie à vie sur les roues ou plusieurs options de pneus ? Vous ne voulez pas avoir à écrire une série de valeurs IN() pour chaque combinaison possible. Au lieu de cela, nous pouvons écrire une opération AND BITWISE, pour trouver toutes les lignes où le 2ème bit est défini, comme :
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
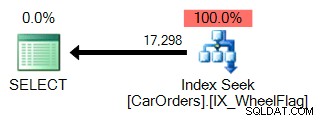
WHERE WheelFlag & @Flag = @Flag; Cela me donne les mêmes résultats que la requête IN(), mais si je les compare à l'aide de SQL Sentry Plan Explorer, les performances sont assez différentes :

Il est facile de voir pourquoi. La première utilise une recherche d'index pour isoler les lignes qui satisfont la requête, avec un filtre sur la colonne WheelFlag :

La seconde utilise un scan, couplé à une conversion implicite, et des statistiques terriblement imprécises. Tout cela grâce à l'opérateur BITWISE AND :
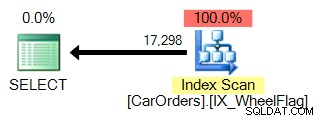


Qu'est-ce que cela signifie? Au cœur de celui-ci, cela nous indique que l'opération BITWISE AND n'est pas sargable .
Mais tout espoir n'est pas perdu.
Si on ignore un instant le principe DRY, on peut écrire une requête un peu plus efficace en étant un peu redondante afin de profiter de l'index sur la colonne WheelFlag. En supposant que nous recherchions une option WheelFlag supérieure à 0 (pas de mise à niveau du tout), nous pouvons réécrire la requête de cette façon, en indiquant à SQL Server que la valeur WheelFlag doit être au moins la même valeur que flag (ce qui élimine 0 et 1 ), puis en ajoutant les informations supplémentaires qu'il doit également contenir cet indicateur (éliminant ainsi 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
La partie>=de cette clause est évidemment couverte par la partie BITWISE, c'est donc là que nous violons DRY. Mais parce que cette clause que nous avons ajoutée est sargable, reléguer l'opération BITWISE AND à une condition de recherche secondaire donne toujours le même résultat, et la requête globale donne de meilleures performances. Nous voyons une recherche d'index similaire à la version codée en dur de la requête ci-dessus, et bien que les estimations soient encore plus éloignées (quelque chose qui peut être traité comme un problème distinct), les lectures sont toujours inférieures à celles de l'opération BITWISE AND seule :

Nous pouvons également voir qu'un filtre est utilisé par rapport à l'index, ce que nous n'avons pas vu lors de l'utilisation de l'opération BITWISE AND seule :

Conclusion
N'ayez pas peur de vous répéter. Il y a des moments où ces informations peuvent aider l'optimiseur; même s'il n'est peut-être pas entièrement intuitif d'*ajouter* des critères afin d'améliorer les performances, il est important de comprendre quand des clauses supplémentaires aident à réduire les données pour le résultat final plutôt que de permettre à l'optimiseur de trouver "facilement" les lignes exactes tout seul.