Dans les bases de données relationnelles, nous créons des tables pour stocker des données dans différents formats. SQL Server stocke les données dans un format de ligne et de colonne contenant une valeur associée à chaque type de données. Lorsque nous concevons des tables SQL, nous définissons des types de données tels que entier, flottant, décimal, varchar et bit. Par exemple, une table qui stocke des données client peut avoir des champs tels que le nom du client, l'adresse e-mail, l'adresse, l'état, le pays, etc. Diverses commandes SQL sont exécutées sur une table SQL et peuvent être réparties dans les catégories suivantes :
- Langage de définition de données (DDL) : Ces commandes sont utilisées pour créer et modifier les objets de base de données dans une base de données.
- Créer : Crée des objets
- Modifier : Modifie les objets
- Déposer : Supprime des objets
- Tronquer : Supprime toutes les données d'une table
- Langage de manipulation de données (DML) : Ces commandes insèrent, récupèrent, modifient, suppriment et mettent à jour des données dans la base de données.
- Sélectionnez : Récupère les données d'une seule ou de plusieurs tables
- Insérer : Ajoute de nouvelles données dans un tableau
- Mise à jour : Modifie les données existantes
- Supprimer : Supprime les enregistrements existants dans une table
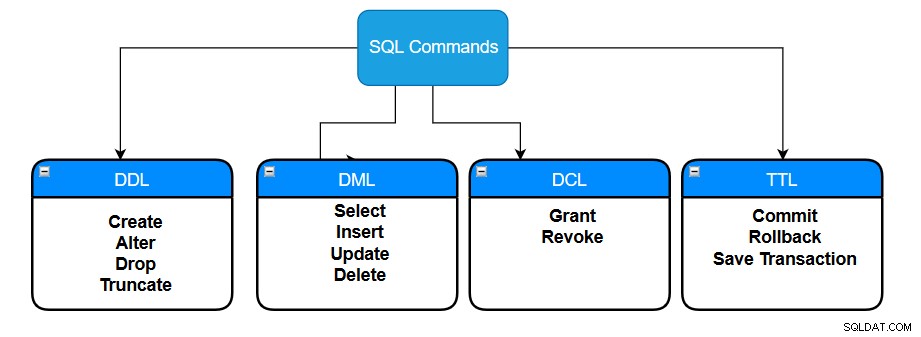
- Langage de contrôle des données (DCL) : Ces commandes sont associées à des contrôles de droits ou d'autorisations dans une base de données.
- Subvention : Attribue des autorisations à un utilisateur
- Révoquer : Révoque les autorisations d'un utilisateur
- Langage de contrôle des transactions (TCL) : Ces commandes contrôlent les transactions dans une base de données.
- Engagement : Enregistre les modifications apportées par la requête
- Annulation : Annule une transaction explicite ou implicite au début de la transaction ou à un point de sauvegarde à l'intérieur de la transaction
- Enregistrer les transactions : Définit un point de sauvegarde ou un marqueur dans une transaction
Supposons que vous ayez des données de commande client stockées dans une table SQL. Si vous continuiez à insérer des données dans cette table en continu, la table pourrait contenir des millions d'enregistrements, ce qui entraînerait des problèmes de performances au sein de vos applications. La maintenance de votre index peut également devenir extrêmement chronophage. Souvent, vous n'avez pas besoin de conserver les commandes datant de plus de trois ans. Dans ces cas, vous pouvez supprimer ces enregistrements de la table. Cela permettrait d'économiser de l'espace de stockage et de réduire vos efforts de maintenance.
Vous pouvez supprimer des données d'une table SQL de deux manières :
- Utiliser une instruction de suppression SQL
- Utiliser une troncature
Nous verrons plus tard la différence entre ces commandes SQL. Explorons d'abord l'instruction de suppression SQL.
Une instruction de suppression SQL sans aucune condition
Dans les instructions en langage de manipulation de données (DML), une instruction de suppression SQL supprime les lignes d'une table. Vous pouvez supprimer une ligne spécifique ou toutes les lignes. Une instruction de suppression de base ne nécessite aucun argument.
Créons une table SQL Orders en utilisant le script ci-dessous. Ce tableau comporte trois colonnes [OrderID], [ProductName] et [ProductQuantity].
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
Insérez quelques enregistrements dans ce tableau.
Insert into Orders values (1,'ABC books',10),(2,'XYZ',100),(3,'SQL book',50)
Supposons maintenant que nous voulions supprimer les données de la table. Vous pouvez spécifier le nom de la table pour supprimer des données à l'aide de l'instruction delete. Les deux instructions SQL sont identiques. Nous pouvons spécifier le nom de la table à partir du mot-clé (facultatif) ou spécifier le nom de la table directement après la suppression.
Delete OrdersGoDelete from OrdersGO
Une instruction de suppression SQL avec des données filtrées
Ces instructions de suppression SQL suppriment toutes les données de la table. Habituellement, nous ne supprimons pas toutes les lignes d'une table SQL. Pour supprimer une ligne spécifique, nous pouvons ajouter une clause where avec l'instruction delete. La clause where contient les critères de filtre et détermine éventuellement la ou les lignes à supprimer.
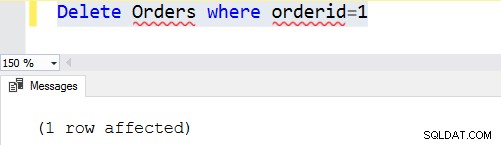
Par exemple, supposons que nous voulions supprimer l'ID de commande 1. Une fois que nous avons ajouté une clause where, SQL Server vérifie d'abord les lignes correspondantes et supprime ces lignes spécifiques.Delete Orders where orderid=1
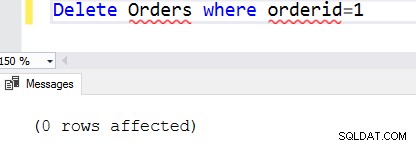
Si la condition de la clause where est fausse, elle ne supprime aucune ligne. Par exemple, nous avons supprimé le 1 commandé du tableau des commandes. Si nous exécutons à nouveau l'instruction, elle ne trouve aucune ligne pour satisfaire la condition de la clause where. Dans ce cas, il renvoie 0 lignes affectées.
Instruction de suppression SQL et clause TOP
Vous pouvez également utiliser l'instruction TOP pour supprimer les lignes. Par exemple, la requête ci-dessous supprime les 100 premières lignes de la table Commandes.
Delete top (100) [OrderID]from Orders
Comme nous n'avons pas spécifié de "ORDER BY", il sélectionne des lignes aléatoires et les supprime. Nous pouvons utiliser la clause Order by pour trier les données et supprimer les premières lignes. Dans la requête ci-dessous, il trie le [OrderID] par ordre décroissant, puis le supprime de la table [Orders].
Delete from Orders where [OrderID] In(Select top 100 [OrderID] FROM Ordersorder by [OrderID] Desc)
Supprimer des lignes basées sur une autre table
Parfois, nous devons supprimer des lignes basées sur une autre table. Cette table peut exister dans la même base de données ou non.
- Recherche de tableau
Nous pouvons utiliser la méthode de recherche de table ou la jointure SQL pour supprimer ces lignes. Par exemple, nous souhaitons supprimer les lignes de la table [Commandes] qui satisfont la condition suivante :
Il doit avoir des lignes correspondantes dans la table [dbo].[Customer].
Regardez la requête ci-dessous, ici nous avons une instruction select dans la clause where de l'instruction delete. SQL Server obtient d'abord les lignes qui satisfont l'instruction select, puis supprime ces lignes de la table [Orders] à l'aide de l'instruction SQL delete.
Delete Orders where orderid in(Select orderidfrom Customer)
- Jointure SQL
Alternativement, nous pouvons utiliser des jointures SQL entre ces tables et supprimer les lignes. Dans la requête ci-dessous, nous joignons les tables [Orders]] avec la table [Customer]. Une jointure SQL fonctionne toujours sur une colonne commune entre les tables. Nous avons une colonne [OrderID] qui joint les deux tables ensemble.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
Pour comprendre l'instruction de suppression ci-dessus, examinons le plan d'exécution réel.
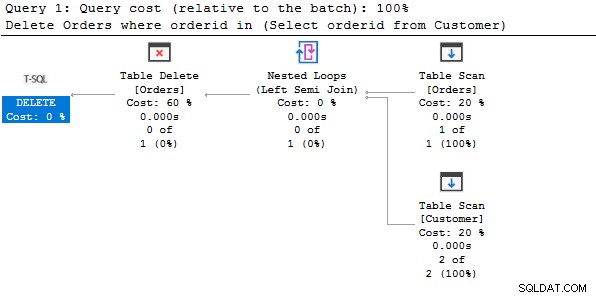
Conformément au plan d'exécution, il effectue une analyse de table sur les deux tables, obtient les données correspondantes et les supprime de la table Orders.
- Expression de table commune (CTE)
Nous pouvons également utiliser une expression de table commune (CTE) pour supprimer les lignes d'une table SQL. Tout d'abord, nous définissons un CTE pour trouver la ligne que nous voulons supprimer.
Ensuite, nous joignons le CTE avec la table SQL Commandes et supprimons les lignes.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Impacts sur la plage d'identité
Les colonnes d'identité dans SQL Server génèrent des valeurs séquentielles uniques pour votre colonne. Ils sont principalement utilisés pour identifier de manière unique une ligne dans la table SQL. Une colonne de clé primaire est également un bon choix pour un index clusterisé dans SQL Server.
Dans le script ci-dessous, nous avons une table [Employee]. Cette table a un identifiant de colonne d'identité.
Create Table Employee(id int identity(1,1),[Name] varchar(50))
Nous avons inséré 50 enregistrements dans cette table qui ont généré les valeurs d'identité pour la colonne id.
Declare @id int=1While(@id<=50)BEGINInsert into Employee([Name]) values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
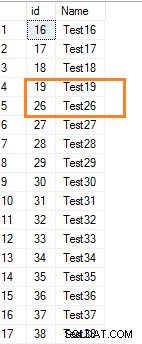
Si nous supprimons quelques lignes de la table SQL, cela ne réinitialise pas les valeurs d'identité pour les valeurs suivantes. Par exemple, supprimons quelques lignes qui ont des valeurs d'identité de 20 à 25.
Delete from employeewhere id between 20 and 25
Maintenant, affichez les enregistrements de la table.
Select * from employee where id>15Il montre l'écart dans la plage de valeurs d'identité.
Instruction de suppression SQL et journal des transactions
La suppression SQL enregistre chaque suppression de ligne dans le journal des transactions. Supposons que vous deviez supprimer des millions d'enregistrements d'une table SQL. Vous ne souhaitez pas supprimer un grand nombre d'enregistrements en une seule transaction, car cela pourrait entraîner une croissance exponentielle de votre fichier journal et votre base de données pourrait également être indisponible. Si vous annulez une transaction au milieu, l'annulation d'une instruction de suppression peut prendre des heures.
Dans ce cas, vous devez toujours supprimer les lignes par petits morceaux et valider ces morceaux régulièrement. Par exemple, vous pouvez supprimer un lot de 10 000 lignes à la fois, le valider et passer au lot suivant. Lorsque SQL Server valide le bloc, la croissance du journal des transactions peut être contrôlée.
Bonnes pratiques
- Vous devez toujours effectuer une sauvegarde avant de supprimer des données.
- Par défaut, SQL Server utilise des transactions implicites et valide les enregistrements sans demander à l'utilisateur. La meilleure pratique consiste à démarrer une transaction explicite à l'aide de Begin Transaction. Il vous donne le contrôle pour valider ou annuler la transaction. Vous devez également exécuter des sauvegardes fréquentes du journal des transactions si votre base de données est en mode de récupération complète.
- Vous souhaitez supprimer des données en petits morceaux pour éviter une utilisation excessive du journal des transactions. Cela évite également les blocages pour d'autres transactions SQL.
- Vous devez limiter les autorisations afin que les utilisateurs ne puissent pas supprimer de données. Seuls les utilisateurs autorisés doivent avoir accès pour supprimer des données d'une table SQL.
- Vous souhaitez exécuter l'instruction delete avec une clause where. Il supprime les données filtrées d'une table SQL. Si votre application nécessite une suppression fréquente des données, il est judicieux de réinitialiser périodiquement les valeurs d'identité. Sinon, vous risquez de rencontrer des problèmes d'épuisement de la valeur d'identité.
- Si vous souhaitez vider la table, il est conseillé d'utiliser l'instruction truncate. L'instruction truncate supprime toutes les données d'une table, utilise une journalisation minimale des transactions, réinitialise la plage de valeurs d'identité et est plus rapide que l'instruction SQL delete car elle libère immédiatement toutes les pages de la table.
- Si vous utilisez des contraintes de clé étrangère (relation parent-enfant) pour vos tables, vous devez supprimer la ligne d'une ligne enfant, puis de la table parent. Si vous supprimez la ligne de la ligne parent, vous pouvez également utiliser l'option cascade lors de la suppression pour supprimer automatiquement la ligne d'une table enfant. Vous pouvez vous référer à l'article : Supprimer la cascade et mettre à jour la cascade dans la clé étrangère SQL Server pour plus d'informations.
- Si vous utilisez l'instruction top pour supprimer les lignes, SQL Server supprime les lignes de manière aléatoire. Vous devez toujours utiliser la clause supérieure avec les clauses Order by et Group by correspondantes.
- Une instruction de suppression acquiert un verrou d'intention exclusif sur la table de référence ; par conséquent, pendant ce temps, aucune autre transaction ne peut modifier les données. Vous pouvez utiliser l'indice NOLOCK pour lire les données.
- Vous devez éviter d'utiliser l'indicateur de table pour remplacer le comportement de verrouillage par défaut de l'instruction de suppression SQL ; il ne doit être utilisé que par des DBA et des développeurs expérimentés.
Considérations importantes
L'utilisation d'instructions de suppression SQL pour supprimer des données d'une table SQL présente de nombreux avantages, mais comme vous pouvez le constater, cela nécessite une approche méthodique. Il est important de toujours supprimer les données par petits lots et de procéder avec prudence lors de la suppression des données d'une instance de production. Avoir une stratégie de sauvegarde pour récupérer les données en un minimum de temps est indispensable pour éviter les temps d'arrêt ou les impacts futurs sur les performances.