Nous avons tous été gâtés par la capacité des moteurs de recherche à "contourner" des choses comme les fautes d'orthographe, les différences d'orthographe des noms ou toute autre situation où le terme de recherche peut correspondre à des pages dont les auteurs peuvent préférer utiliser une orthographe différente d'un mot. L'ajout de telles fonctionnalités à nos propres applications basées sur des bases de données peut également enrichir et améliorer nos applications, et bien que les offres commerciales de systèmes de gestion de bases de données relationnelles (RDBMS) fournissent leurs propres solutions personnalisées entièrement développées à ce problème, les coûts de licence de ces outils peuvent être hors de prix. atteindre les petits développeurs ou les petites entreprises de développement de logiciels.
On pourrait dire que cela pourrait être fait à l'aide d'un correcteur orthographique à la place. Cependant, un correcteur orthographique n'est généralement d'aucune utilité lorsqu'il s'agit de trouver une orthographe correcte, mais alternative, d'un nom ou d'un autre mot. L'appariement par le son comble ce vide fonctionnel. C'est le sujet du tutoriel de programmation d'aujourd'hui :comment interroger des sons avec Python à l'aide de Metaphones.
Qu'est-ce que Soundex ?
Soundex a été développé au début du 20e siècle comme un moyen pour le recensement américain de faire correspondre les noms en fonction de leur sonorité. Il a ensuite été utilisé par diverses compagnies de téléphone pour faire correspondre les noms des clients. Il continue d'être utilisé pour la correspondance des données phonétiques à ce jour bien qu'il soit limité aux orthographes et aux prononciations de l'anglais américain. Il est également limité aux lettres anglaises. La plupart des SGBDR, tels que SQL Server et Oracle, ainsi que MySQL et ses variantes, implémentent une fonction Soundex et, malgré ses limites, elle continue d'être utilisée pour faire correspondre de nombreux mots non anglais.
Qu'est-ce qu'un double métaphone ?
Le Métaphone L'algorithme a été développé en 1990 et il surmonte certaines des limitations de Soundex. En 2000, une suite améliorée, Double Metaphone , était développé. Double Metaphone renvoie une valeur primaire et secondaire qui correspond à deux manières de prononcer un même mot. À ce jour, cet algorithme reste l'un des meilleurs algorithmes phonétiques open source. Metaphone 3 est sorti en 2009 en tant qu'amélioration de Double Metaphone, mais il s'agit d'un produit commercial.
Malheureusement, bon nombre des principaux SGBDR mentionnés ci-dessus n'implémentent pas Double Metaphone, et la plupart les principaux langages de script ne fournissent pas d'implémentation prise en charge de Double Metaphone. Cependant, Python fournit un module qui implémente Double Metaphone.
Les exemples présentés dans ce tutoriel de programmation Python utilisent MariaDB version 10.5.12 et Python 3.9.2, tous deux fonctionnant sur Kali/Debian Linux.
Comment ajouter un double métaphone à Python
Comme tout module Python, l'outil pip peut être utilisé pour installer Double Metaphone. La syntaxe dépend de votre installation Python. Une installation typique de Double Metaphone ressemble à l'exemple suivant :
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Notez que la capitalisation supplémentaire est intentionnelle. Le code suivant est un exemple d'utilisation de Double Metaphone en Python :
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Le script Python ci-dessus donne la sortie suivante lorsqu'il est exécuté dans votre environnement de développement intégré (IDE) ou votre éditeur de code :
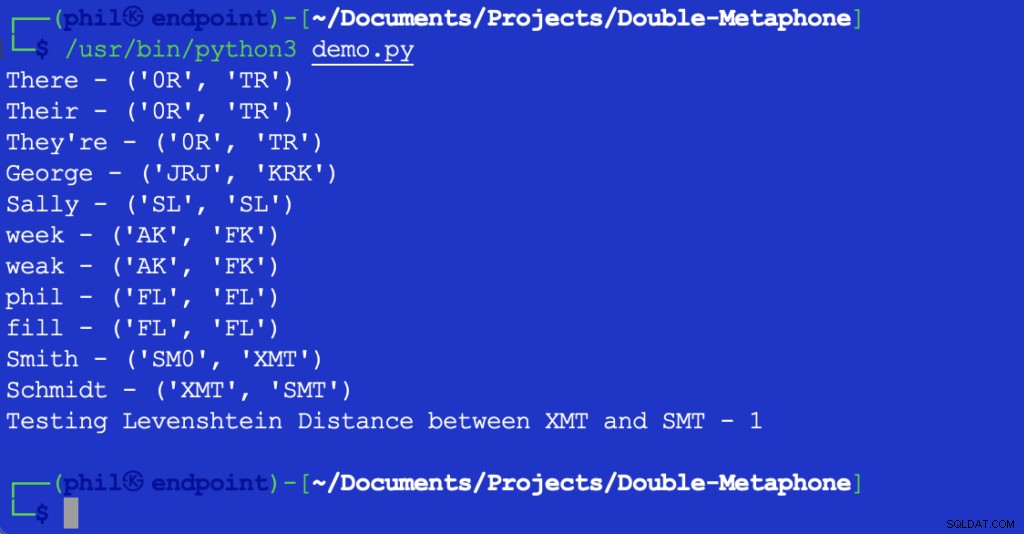
Figure 1 - Sortie du script de démonstration
Comme on peut le voir ici, chaque mot a une valeur phonétique primaire et secondaire. Les mots qui correspondent à la fois aux valeurs primaires ou secondaires sont appelés correspondances phonétiques. Les mots qui partagent au moins une valeur phonétique, ou qui partagent les deux premiers caractères de n'importe quelle valeur phonétique, sont dits phonétiquement proches les uns des autres.
La plupart les lettres affichées correspondent à leurs prononciations anglaises. X peut correspondre à KS , SH , ou C . 0 correspond au ème son dans le ou ici . Les voyelles ne correspondent qu'au début d'un mot. En raison du nombre incalculable de différences dans les accents régionaux, il n'est pas possible de dire que les mots peuvent être une correspondance objectivement exacte, même s'ils ont les mêmes valeurs phonétiques.
Comparer les valeurs phonétiques avec Python
Il existe de nombreuses ressources en ligne qui peuvent décrire le fonctionnement complet de l'algorithme Double Metaphone. cependant, ce n'est pas nécessaire pour l'utiliser car nous sommes plus intéressés à comparer les valeurs calculées, plus que nous sommes intéressés à calculer les valeurs. Comme indiqué précédemment, s'il y a au moins une valeur en commun entre deux mots, on peut dire que ces valeurs sont des correspondances phonétiques , et des valeurs phonétiques similaires sont phonétiquement proches .
Il est facile de comparer des valeurs absolues, mais comment déterminer si des chaînes sont similaires ? Bien qu'aucune limitation technique ne vous empêche de comparer des chaînes de plusieurs mots, ces comparaisons ne sont généralement pas fiables. Contentez-vous de comparer des mots simples.
Que sont les distances de Levenshtein ?
La distance de Levenshtein entre deux chaînes est le nombre de caractères simples qui doivent être modifiés dans une chaîne afin de la faire correspondre à la deuxième chaîne. Une paire de cordes qui ont une distance de Levenshtein inférieure sont plus similaires entre elles qu'une paire de cordes qui ont une distance de Levenshtein plus élevée. La distance de Levenshtein est similaire à la distance de Hamming , mais ce dernier est limité aux chaînes de même longueur, car les valeurs phonétiques Double Metaphone peuvent varier en longueur, il est plus logique de les comparer à l'aide de la distance de Levenshtein.
Bibliothèque de distances Python Levenshtein
Python peut être étendu pour prendre en charge les calculs de distance de Levenshtein via un module Python :
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Notez que, comme pour l'installation du DoubleMetaphone ci-dessus, la syntaxe de l'appel à pip peut varier. Le module python-Levenshtein fournit bien plus de fonctionnalités que de simples calculs de la distance de Levenshtein.
Le code ci-dessous montre un test pour le calcul de la distance de Levenshtein en Python :
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
L'exécution de ce script donne le résultat suivant :
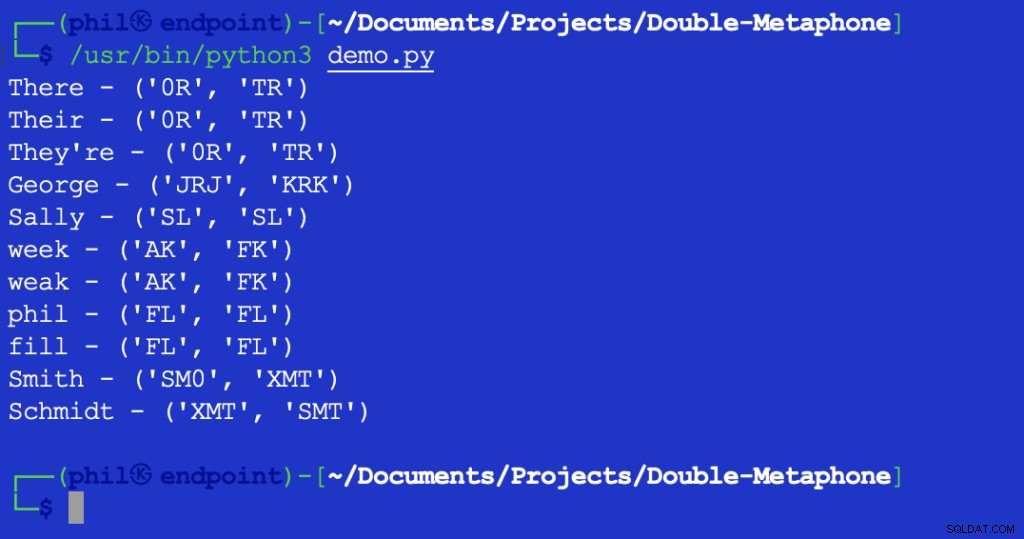
Figure 2 – Résultat du test de distance de Levenshtein
La valeur renvoyée de 1 indique qu'il y a un caractère entre XMT et SMT c'est différent. Dans ce cas, il s'agit du premier caractère des deux chaînes.
Comparer les doubles métaphones en Python
Ce qui suit n'est pas l'alpha et l'oméga des comparaisons phonétiques. C'est simplement l'une des nombreuses façons d'effectuer une telle comparaison. Pour comparer efficacement la proximité phonétique de deux chaînes données, chaque valeur phonétique Double Metaphone d'une chaîne doit être comparée à la valeur phonétique Double Metaphone correspondante d'une autre chaîne. Étant donné que les deux valeurs phonétiques d'une chaîne donnée ont le même poids, la moyenne de ces valeurs de comparaison donnera une approximation raisonnablement bonne de la proximité phonétique :
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Où :
- DM1(1) :première valeur de double métaphone de la chaîne 1,
- DM1(2) :Deuxième valeur de double métaphone de la chaîne 1
- DM2(1) : Première valeur de double métaphone de la chaîne 2
- DM2(2) :deuxième valeur de métaphone double de la chaîne 2
- PN :Proximité phonétique, les valeurs inférieures étant plus proches que les valeurs supérieures. Une valeur nulle indique une similarité phonétique. La valeur la plus élevée correspond au nombre de lettres dans la chaîne la plus courte.
Cette formule se décompose dans des cas comme Schmidt (XMT, SMT) et Smith (SM0, XMT) où la première valeur phonétique de la première chaîne correspond à la deuxième valeur phonétique de la deuxième chaîne. Dans de telles situations, à la fois Schmidt et Smith peuvent être considérés comme phonétiquement similaires en raison de la valeur partagée. Le code de la fonction de proximité doit appliquer la formule ci-dessus uniquement lorsque les quatre valeurs phonétiques sont différentes. La formule présente également des faiblesses lors de la comparaison de chaînes de longueurs différentes.
Notez qu'il n'existe aucun moyen singulièrement efficace de comparer des chaînes de longueurs différentes, même si le calcul de la distance de Levenshtein entre deux chaînes tient compte des différences de longueur de chaîne. Une solution de contournement possible serait de comparer les deux chaînes jusqu'à la longueur de la plus courte des deux chaînes.
Vous trouverez ci-dessous un exemple d'extrait de code qui implémente le code ci-dessus, ainsi que quelques exemples de test :
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
L'exemple de code Python donne le résultat suivant :
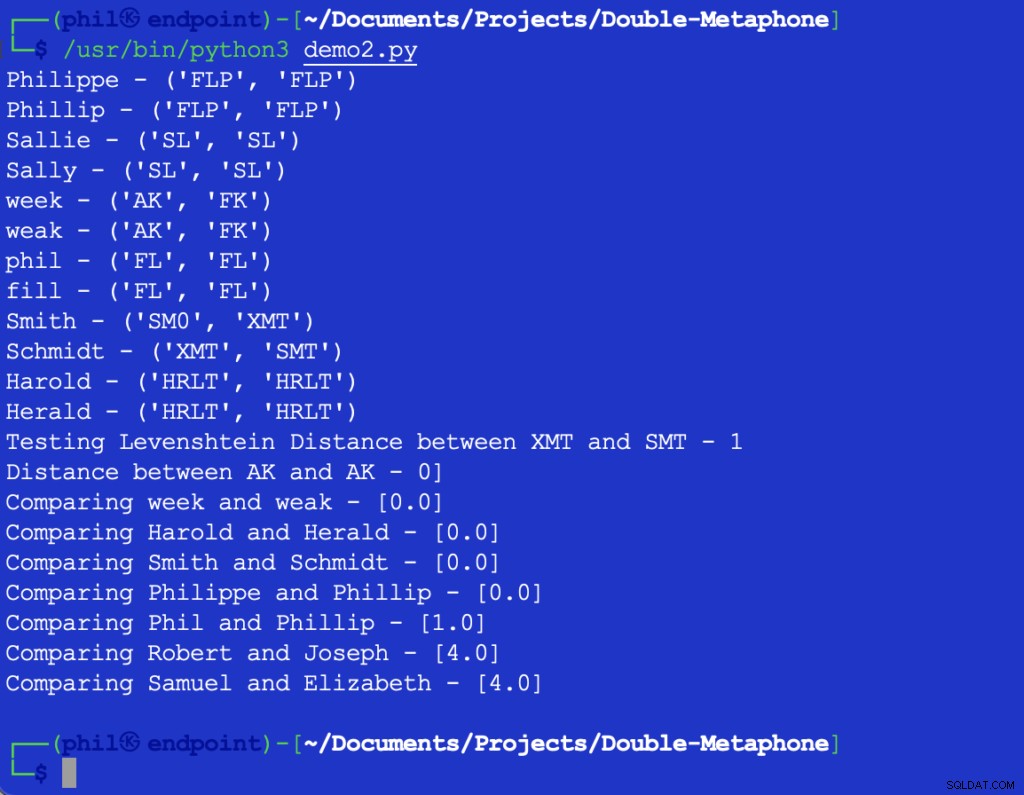
Figure 3 - Sortie de l'algorithme de proximité
L'ensemble d'échantillons confirme la tendance générale selon laquelle plus les différences de mots sont importantes, plus la sortie de la proximité est élevée. fonction.
Intégration de base de données en Python
Le code ci-dessus rompt l'écart fonctionnel entre un RDBMS donné et une implémentation Double Metaphone. De plus, en mettant en œuvre la proximité fonction en Python, il devient facile de la remplacer si un algorithme de comparaison différent est préféré.
Considérez la table MySQL/MariaDB suivante :
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
Dans la plupart des applications basées sur des bases de données, le middleware compose des instructions SQL pour gérer les données, y compris leur insertion. Le code suivant insère quelques exemples de noms dans ce tableau, mais en pratique, tout code d'une application Web ou de bureau qui collecte de telles données pourrait faire la même chose.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
L'exécution de ce code n'imprime rien, mais il remplit la table de test dans la base de données pour la prochaine liste à utiliser. Interroger la table directement dans le client MySQL peut vérifier que le code ci-dessus a fonctionné :
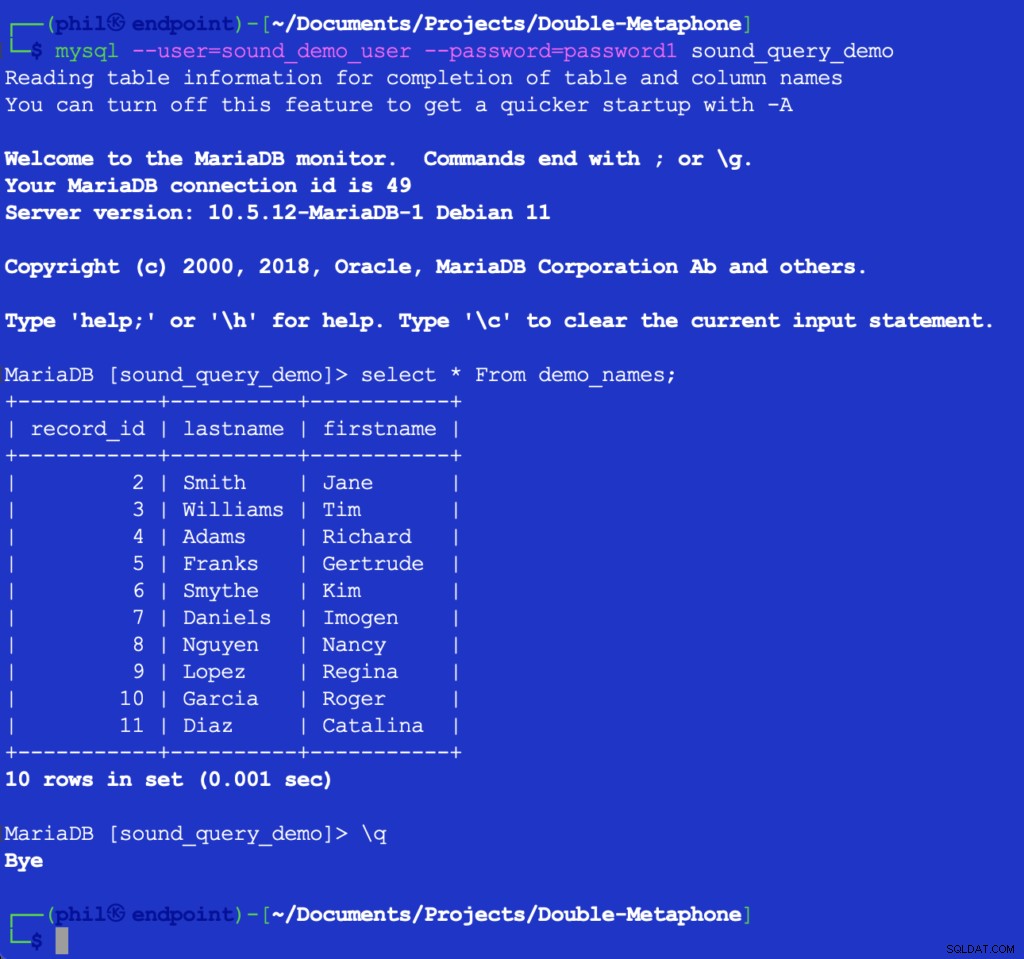
Figure 4- Les données du tableau inséré
Le code ci-dessous introduira des données de comparaison dans les données du tableau ci-dessus et effectuera une comparaison de proximité :
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
L'exécution de ce code nous donne le résultat ci-dessous :
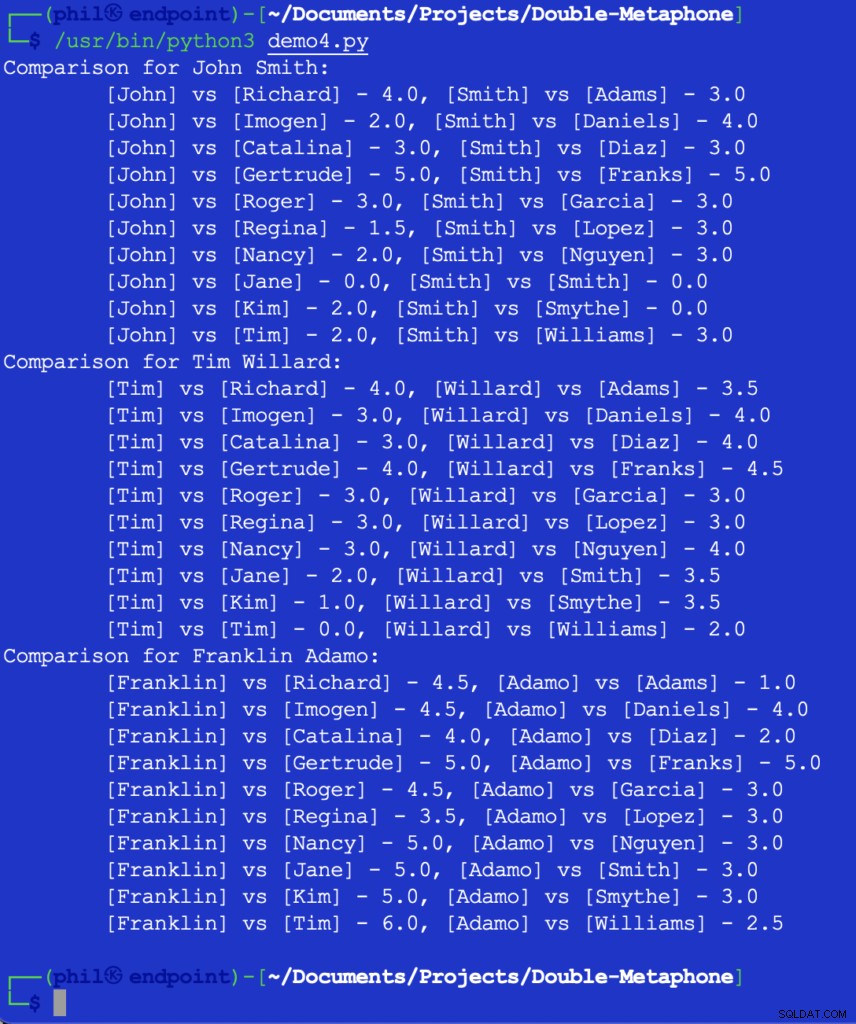
Figure 5 - Résultats de la comparaison de proximité
À ce stade, il appartiendrait au développeur de décider quel serait le seuil pour ce qui constitue une comparaison utile. Certains des chiffres ci-dessus peuvent sembler inattendus ou surprenants, mais un ajout possible au code pourrait être un IF instruction pour filtrer toute valeur de comparaison supérieure à 2 .
Il peut être intéressant de noter que les valeurs phonétiques elles-mêmes ne sont pas stockées dans la base de données. C'est parce qu'ils sont calculés dans le cadre du code Python et qu'il n'est pas vraiment nécessaire de les stocker n'importe où car ils sont supprimés lorsque le programme se termine, cependant, un développeur peut trouver de la valeur en les stockant dans la base de données, puis en implémentant la comparaison fonction dans la base de données une procédure stockée. Cependant, le seul inconvénient majeur de cela est une perte de portabilité du code.
Réflexions finales sur l'interrogation des données par son avec Python
La comparaison de données par son ne semble pas susciter l'"amour" ou l'attention que peut procurer la comparaison de données par analyse d'image, mais si une application doit traiter plusieurs variantes de mots similaires dans plusieurs langues, cela peut être un outil extrêmement utile. outil. Une caractéristique utile de ce type d'analyse est qu'un développeur n'a pas besoin d'être un expert en linguistique ou en phonétique pour utiliser ces outils. Le développeur dispose également d'une grande flexibilité pour définir comment ces données peuvent être comparées; les comparaisons peuvent être modifiées en fonction des besoins de l'application ou de la logique métier.
Espérons que ce domaine d'étude retiendra davantage l'attention dans le domaine de la recherche et qu'il y aura des outils d'analyse plus performants et plus robustes à l'avenir.