
Dans un article précédent, nous avons exploré les exigences d'indexation SQL Server et les considérations relatives aux performances. En ce qui concerne les performances de la base de données, le réglage des performances est sans aucun doute l'une des fonctions les plus importantes et les plus complexes. Il se compose de nombreux domaines différents tels que l'optimisation des requêtes SQL, le réglage de l'index et le réglage des ressources système, qui doivent tous être exécutés correctement afin de réussir à récupérer rapidement les données.
Il existe plusieurs domaines importants à prendre en compte en ce qui concerne les index SQL Server, car ils peuvent avoir un impact significatif à la fois sur vos efforts de réglage des performances et sur les performances globales de la base de données. Vous trouverez ci-dessous quelques détails sur chacun et les rôles essentiels qu'ils jouent.
Bonnes pratiques d'indexation SQL Server
1. Comprendre l'impact de la conception de la base de données sur les index SQL Server
Les exigences d'indexation varient entre les bases de données de traitement des transactions en ligne (OLTP) et de traitement analytique en ligne (OLAP).
Dans une base de données OLTP, les utilisateurs effectuent de fréquentes opérations de lecture-écriture, insèrent de nouvelles données et modifient les données existantes. Ils utilisent des requêtes de langage de manipulation de données (Insert, Update, Delete) ainsi que des instructions Select pour la récupération et les modifications de données. Pour les bases de données OLTP, il est préférable de créer des index sur la colonne Selected d'une table. Plusieurs index peuvent avoir un impact négatif sur les performances et solliciter les ressources système. Au lieu de cela, il est recommandé de créer le nombre minimum d'index pouvant répondre à vos exigences d'indexation. Dans les bases de données OLAP, en revanche, vous utilisez principalement des instructions Select pour récupérer des données à des fins d'analyse ultérieure. Dans ce cas, vous pouvez ajouter d'autres index avec plusieurs colonnes clés par index. Vous pouvez également tirer parti des index columnstore pour une récupération plus rapide des données dans les requêtes d'entrepôt de données
2. Créez des index pour vos exigences de charge de travail
Lors de la création d'une nouvelle table dans votre base de données, ne vous contentez pas d'ajouter des index à l'aveuglette. Parfois, les développeurs placent un index cluster et quelques index non cluster sans rechercher les requêtes qui utilisent ces index. Il se peut qu'un index ne satisfasse pas les exigences de l'optimiseur de requête ; par conséquent, vous devez analyser correctement votre charge de travail et vos requêtes SQL (procédures stockées, fonctions, vues et requêtes ad hoc). Vous pouvez capturer la charge de travail à l'aide du profileur SQL, des événements étendus et des vues de gestion dynamiques, puis créer des index pour optimiser les requêtes gourmandes en ressources.
3. Créez des index pour les requêtes les plus fréquemment utilisées
Il est important de regrouper les charges de travail pour les requêtes les plus utilisées dans votre système. En créant les meilleurs index pour ces requêtes, cela sollicitera le moins votre système.
4. Appliquer les meilleures pratiques de colonne de clé d'index SQL Server
Étant donné que vous pouvez avoir plusieurs colonnes dans une table, voici quelques considérations pour les colonnes de clé d'index.
- Les colonnes contenant text, image, ntext, varchar(max), nvarchar(max) et varbinary(max) ne peuvent pas être utilisées dans les colonnes de clé d'index.
- Il est recommandé d'utiliser un type de données entier dans la colonne de la clé d'index. Il a un faible encombrement et fonctionne efficacement. Pour cette raison, vous souhaiterez créer la colonne de clé primaire, généralement sur un type de données entier.
- Vous ne pouvez utiliser le type de données XML que dans un index XML.
- Vous devriez envisager de créer une clé primaire pour la colonne avec des valeurs uniques. Si une table n'a pas de colonnes de valeurs uniques, vous pouvez définir une colonne d'identité pour un type de données entier. Une clé primaire crée également un index clusterisé pour la distribution des lignes.
- Vous pouvez considérer une colonne avec les valeurs Unique et Not NULL comme un candidat de clé d'index utile.
- Vous devez créer un index basé sur les prédicats de la clause Where. Par exemple, vous pouvez prendre en compte les colonnes utilisées dans la clause Where, les jointures SQL, les prédicats like, order by, group by, etc.
- Vous devez joindre les tables de manière à réduire le nombre de lignes pour le reste de la requête. Cela aidera l'optimiseur de requêtes à préparer le plan d'exécution avec un minimum de ressources système.
- Si vous utilisez plusieurs colonnes pour une clé d'index, il est également essentiel de tenir compte de leur position dans la clé d'index.
- Vous devriez également envisager d'utiliser des colonnes incluses dans vos index.
5. Analysez la distribution des données de vos colonnes d'index SQL Server
Vous devez examiner la distribution des données dans les colonnes de clé d'index SQL Server. Une colonne avec des valeurs non uniques peut entraîner un retard dans la récupération des données et entraîner une transaction de longue durée. Vous pouvez analyser la distribution des données à l'aide de l'histogramme dans les statistiques.
6. Utiliser l'ordre de tri des données
Vous devez également tenir compte des exigences de tri des données dans vos requêtes et vos index. Par défaut, SQL Server trie les données par ordre croissant dans un index. Supposons que vous créez un index dans l'ordre croissant, mais que vos requêtes utilisent la clause Order By pour trier les données dans l'ordre décroissant.
Par exemple, regardez le plan d'exécution réel de la requête suivante.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
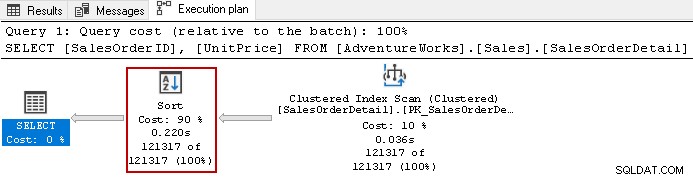
Il utilise l'opérateur de tri coûteux avec un coût global de 90 % dans cette requête. Nous avons décidé de construire un index non clusterisé sur [UnitPrice] et [SalesOrderID]. Il utilise un ordre de tri par défaut pour les deux colonnes de l'index.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Nous avons réexécuté l'instruction Select et l'optimiseur de requête utilise toujours l'opérateur de tri. Il peut utiliser l'index non clusterisé mais trie les données pour préparer le résultat.
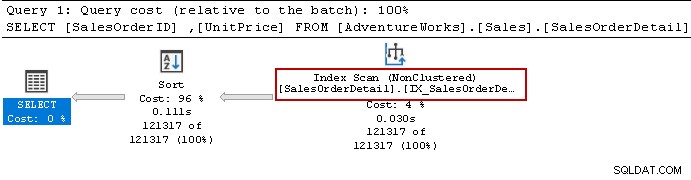
Recréons l'index à l'aide de la requête suivante. Cette fois, il trie les données par ordre décroissant pour [Unitprice] dans la définition de l'index.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
Il ne nécessite aucun opérateur de tri maintenant car l'index satisfait aux exigences de la requête.
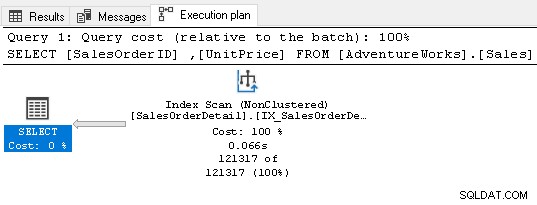
7. Utiliser des clés étrangères pour votre index SQL Server
Vous devez créer un index sur les colonnes de clés étrangères. Il est conseillé de créer un index clusterisé sur la clé étrangère pour améliorer les performances des requêtes.
8. Tenez compte des considérations de stockage d'index SQL Server
Le stockage d'index est également un aspect utile à prendre en compte. SQL Server crée tous les index sur le même groupe de fichiers de la table. Vous pouvez envisager un groupe de fichiers distinct pour les index et séparer le fichier physique sur un disque distinct. Cela augmentera les performances et le débit des E/S.
De même, vous pouvez utiliser le partitionnement de table pour séparer les données sur plusieurs disques et groupes de fichiers. Vous pouvez concevoir des index partitionnés pour ces partitions de table afin d'améliorer l'accès simultané aux données.
Une autre option consiste à définir le FILLFACTOR lors de la création ou de la reconstruction d'un index. Un FILLFACTOR définit l'espace libre dans les pages de données du nœud feuille. Il est utile pour d'autres insertions de données. Si vos données sont statiques et ne changent pas fréquemment, vous pouvez envisager une valeur élevée de FILLFACTOR. D'autre part, pour les données qui changent fréquemment, vous pouvez laisser suffisamment de place pour de nouvelles insertions de données.
9. Rechercher les index manquants
Parfois, vous obtenez des informations sur un index SQL Server manquant dans le plan d'exécution de la requête. Vous pouvez également exécuter les vues de gestion dynamique pour trouver ces index manquants. Vous ne devez pas créer aveuglément ces index. Il s'agit simplement d'une suggestion d'optimiseur de requête, mais elle ne tient pas compte de l'index existant ni des exigences de votre charge de travail. Il peut également inclure plusieurs colonnes dans la définition de l'index, alors passez en revue ces suggestions avant de l'implémenter.
10. Créez toujours un index clusterisé avant un index non clusterisé
En règle générale, vous devez créer un index clusterisé avant de créer des index non clusterisés. Si une table n'a pas d'index, un index non clusterisé se compose d'identificateurs de ligne. Une fois que vous avez créé un index clusterisé, SQL Server doit reconstruire ces index non clusterisés afin qu'ils puissent pointer vers la clé d'index clusterisé au lieu des identificateurs de ligne.
11. Surveiller la maintenance de l'index et mettre à jour les statistiques
Vous trouverez ci-dessous plusieurs domaines de maintenance à surveiller en ce qui concerne les index SQL Server.
- Supprimer la fragmentation de l'index : vous devez examiner régulièrement les fragmentations internes et externes, en particulier pour les tables de transactions élevées. Vos requêtes peuvent répondre lentement même si vous disposez d'index appropriés pour vos charges de travail. Un index fortement fragmenté peut dégrader les performances car il nécessite des E/S supplémentaires. Vous pouvez effectuer une réorganisation ou reconstruire un index en fonction de ses valeurs de fragmentation. En règle générale, vous devez reconstruire l'index s'il présente une fragmentation supérieure à 30 % et le réorganiser s'il présente une fragmentation inférieure à 30 %.
- Supprimer les index inutilisés : Vous devez toujours passer en revue les index inutilisés (inactifs) de votre base de données, car l'optimiseur de requête doit les prendre en compte pour chaque requête. Un index inutilisé consomme également de l'espace de stockage et augmente les frais de maintenance.
- Mettre à jour les statistiques : Vous devez régulièrement mettre à jour les statistiques même si vous avez défini les statistiques de mise à jour automatique dans la configuration de votre base de données. L'optimiseur de requête peut préparer un mauvais plan d'exécution si les statistiques d'index ne sont pas mises à jour. Vous pouvez planifier une tâche d'agent pour mettre à jour les statistiques SQL Server avec une analyse complète après les heures de bureau.
Vous pouvez vous référer à la maintenance de l'index SQL pour plus d'informations sur ce sujet.
Application des bonnes pratiques d'indexation SQL Server
Bien qu'il n'existe pas toujours de moyen simple de concevoir un index SQL Server optimal, l'application des recommandations spécifiées dans cet article vous aidera à naviguer dans les différentes exigences d'indexation que vous rencontrerez avec chaque type de base de données et ses charges de travail. Ces bonnes pratiques vous aideront à optimiser vos index afin d'améliorer les performances de la base de données et de garantir un processus de réglage des performances plus fluide en cours de route.



