Il y a quelques semaines, j'ai écrit à quel point j'étais surpris par les performances d'une nouvelle fonction native dans SQL Server 2016, STRING_SPLIT() :
- Surprises et hypothèses de performances :STRING_SPLIT()
Après la publication de l'article, j'ai reçu quelques commentaires (en public et en privé) avec ces suggestions (ou questions que j'ai transformées en suggestions) :
- Spécifier un type de données de sortie explicite pour l'approche JSON, afin que cette méthode ne souffre pas d'une surcharge de performances potentielle due au repli de
nvarchar(max). - Tester une approche légèrement différente, où quelque chose est réellement fait avec les données, à savoir
SELECT INTO #temp. - Comment comparer le nombre de lignes estimé aux méthodes existantes, en particulier lors de l'imbrication d'opérations de fractionnement.
J'ai répondu à certaines personnes hors ligne, mais j'ai pensé qu'il valait la peine de publier un suivi ici.
Être plus juste envers JSON
La fonction JSON d'origine ressemblait à ceci, sans spécification de type de données de sortie :
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Je l'ai renommé, et j'en ai créé deux autres, avec les définitions suivantes :
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Je pensais que cela améliorerait considérablement les performances, mais hélas, ce n'était pas le cas. J'ai refait les tests et les résultats sont les suivants :
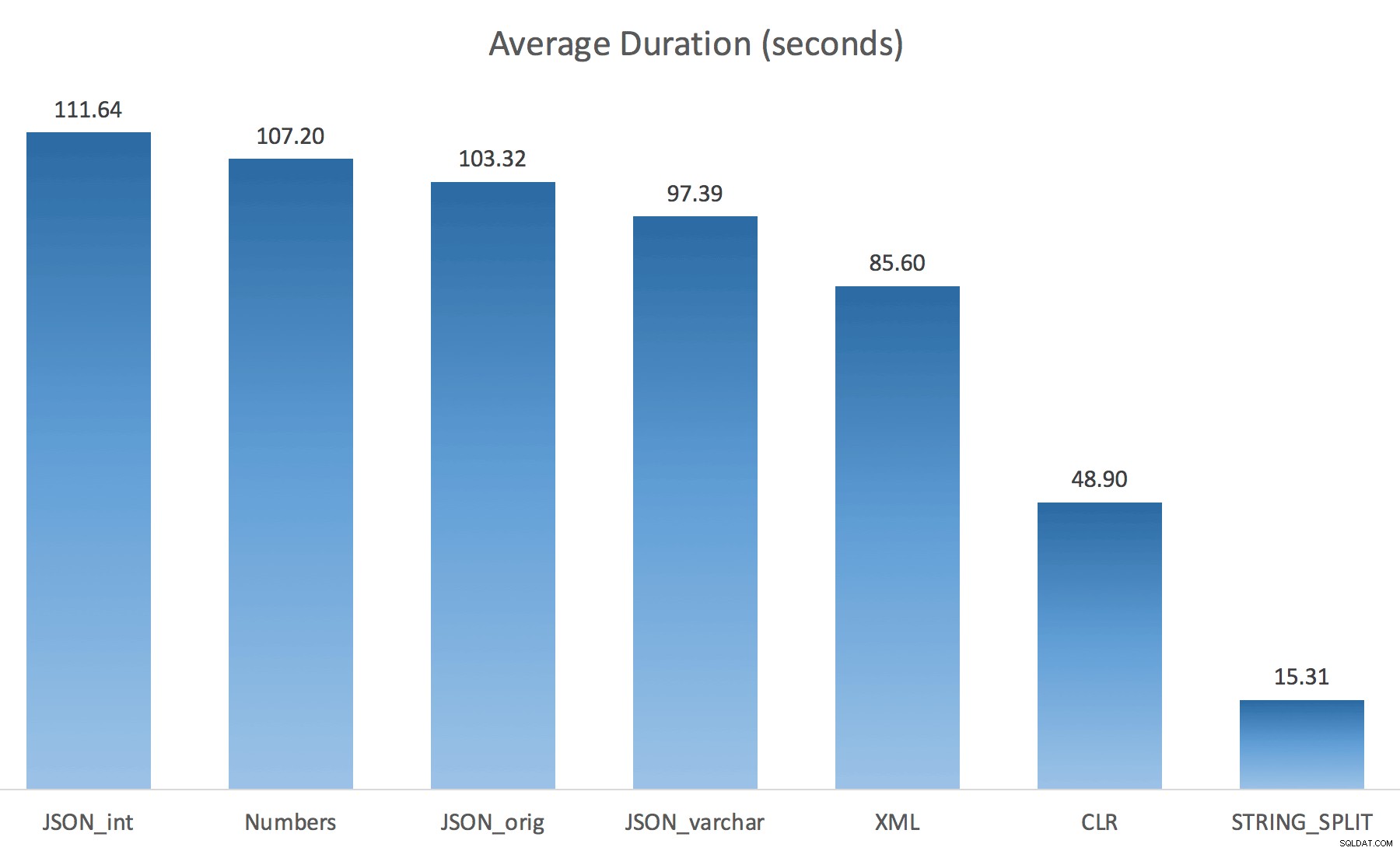
Les temps d'attente observés lors d'une instance aléatoire du test (filtrés à ceux> 25) :
| CLR | IO_COMPLETION | 1 595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6 294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4 307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6 110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Chiffres | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1 917 |
| IO_COMPLETION | 1 616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Attentes observées> 25 (notez qu'il n'y a pas d'entrée pour STRING_SPLIT )
Lors du passage de la valeur par défaut à varchar(100) a amélioré un peu les performances, le gain était négligeable et est passé à int fait pire. Ajoutez à cela que vous devez probablement ajouter STRING_ESCAPE() à la chaîne entrante dans certains scénarios, juste au cas où ils auraient des caractères qui gâcheraient l'analyse JSON. Ma conclusion est toujours qu'il s'agit d'une manière intéressante d'utiliser la nouvelle fonctionnalité JSON, mais surtout d'une nouveauté inappropriée pour une échelle raisonnable.
Matérialiser le résultat
Jonathan Magnan a fait cette observation astucieuse sur mon post précédent :
STRING_SPLIT est en effet très rapide, mais aussi très lent lorsque vous travaillez avec une table temporaire (à moins que cela ne soit corrigé dans une future version).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Sera BEAUCOUP plus lent que la solution SQL CLR (15x et plus !).
Alors, j'ai creusé. J'ai créé un code qui appellerait chacune de mes fonctions et viderait les résultats dans une table #temp, et les chronométrerait :
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
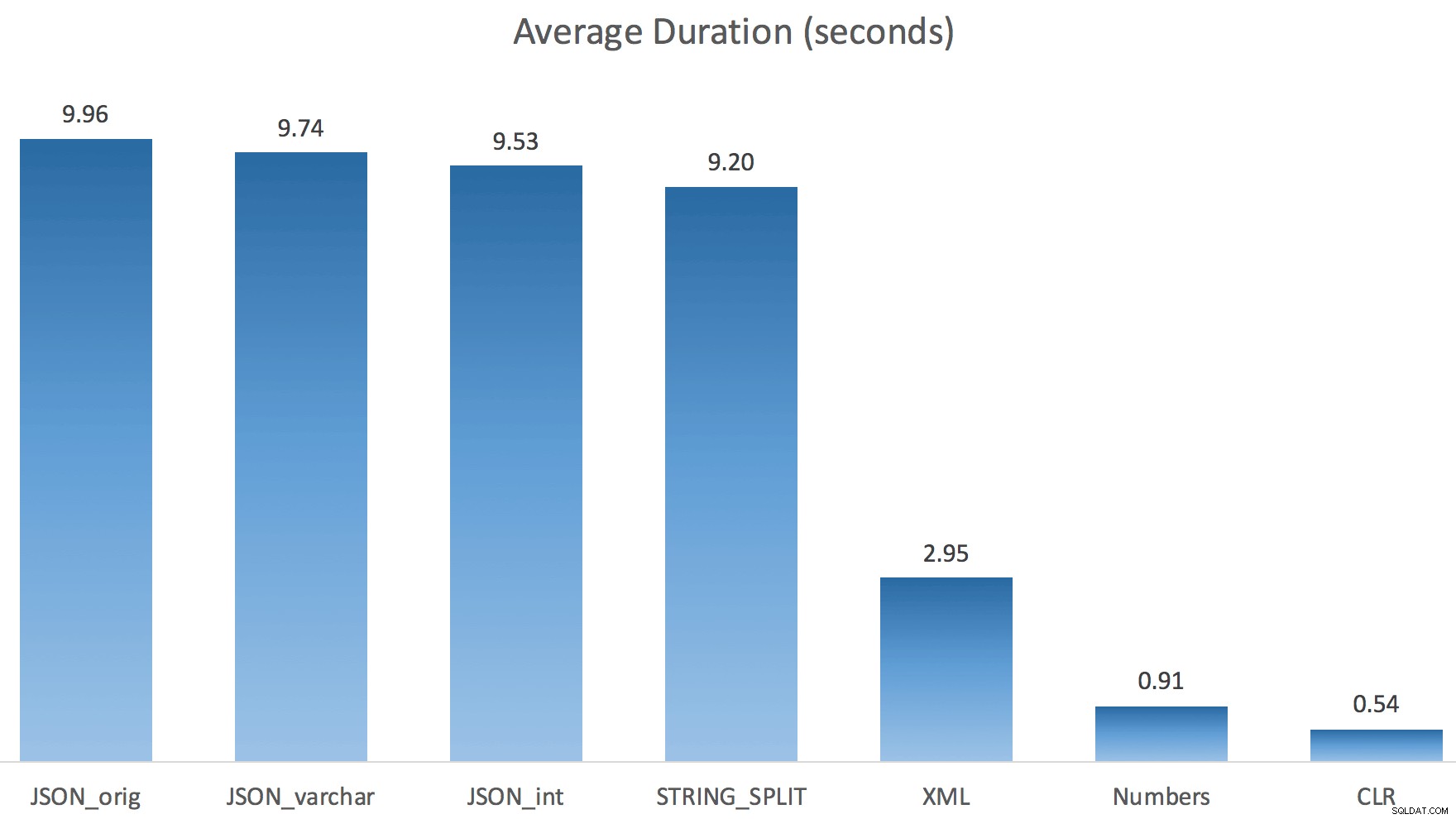
J'ai juste exécuté chaque test une fois (plutôt que de boucler 100 fois), car je ne voulais pas complètement détruire les E/S de mon système. Pourtant, après avoir fait la moyenne de trois essais, Jonathan avait absolument raison à 100 %. Voici les durées de remplissage d'une table #temp avec environ 500 000 lignes en utilisant chaque méthode :
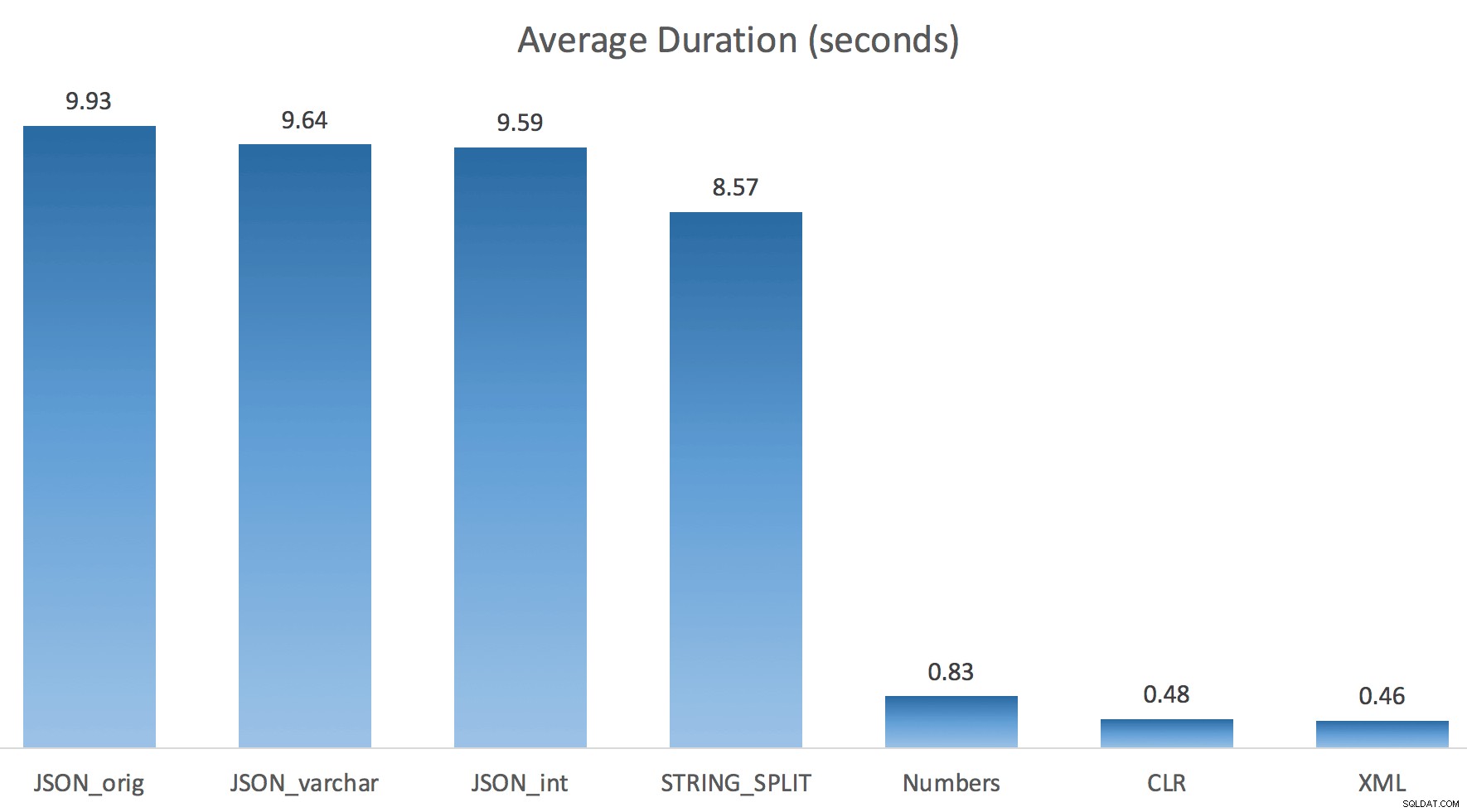
Donc ici, le JSON et STRING_SPLIT Les méthodes ont pris environ 10 secondes chacune, tandis que les approches table de nombres, CLR et XML ont pris moins d'une seconde. Perplexe, j'ai enquêté sur les attentes, et bien sûr, les quatre méthodes sur la gauche ont engagé des LATCH_EX importants attend (environ 25 secondes) pas vu dans les trois autres, et il n'y avait pas d'autres attentes importantes à proprement parler.
Et comme les attentes de verrouillage étaient supérieures à la durée totale, cela m'a donné un indice que cela avait à voir avec le parallélisme (cette machine particulière a 4 cœurs). J'ai donc généré à nouveau du code de test, en changeant juste une ligne pour voir ce qui se passerait sans parallélisme :
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Maintenant STRING_SPLIT s'en sont beaucoup mieux sortis (tout comme les méthodes JSON), mais ont tout de même au moins doublé le temps pris par CLR :
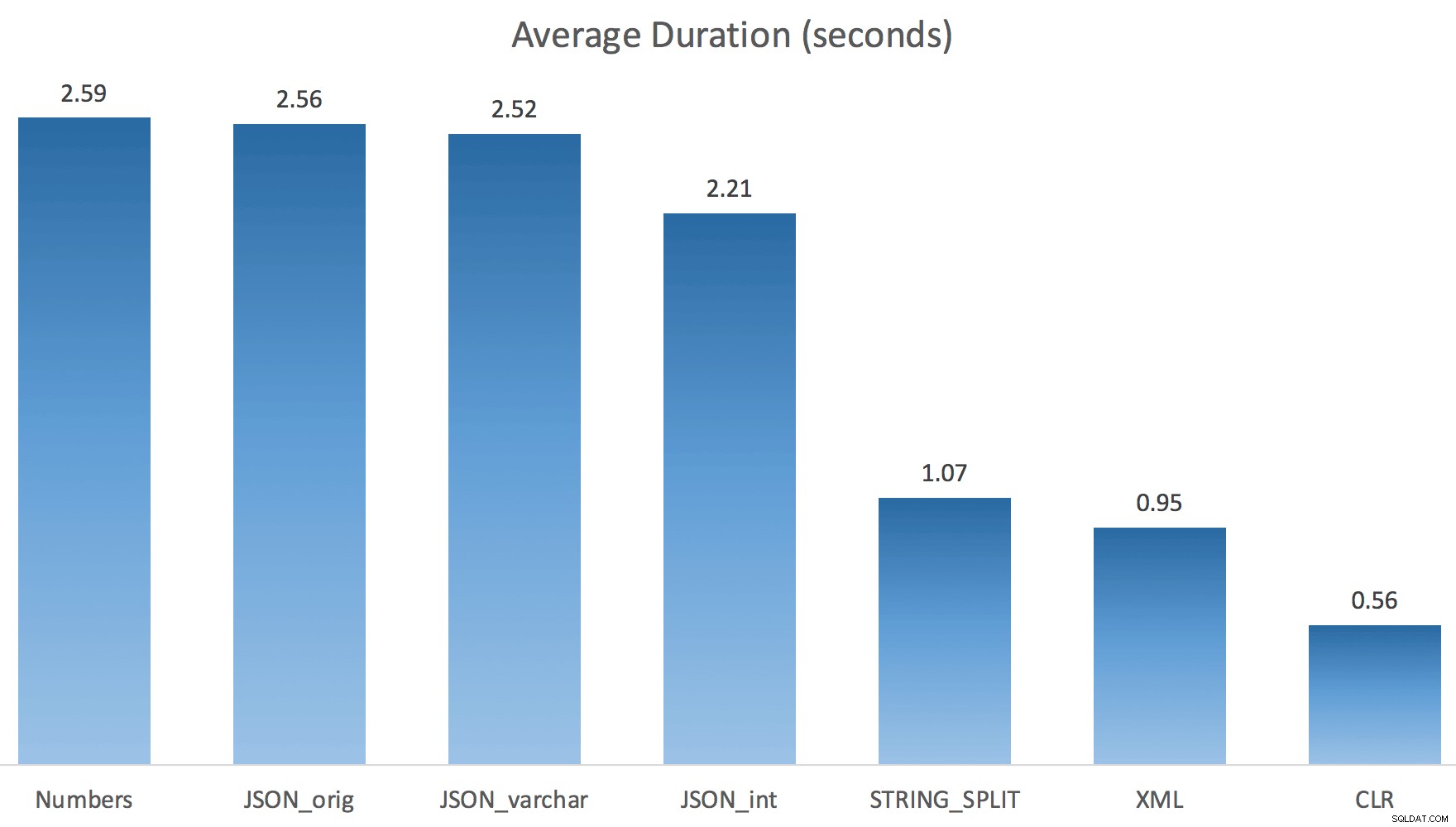
Ainsi, il pourrait y avoir un problème restant dans ces nouvelles méthodes lorsque le parallélisme est impliqué. Ce n'était pas un problème de distribution de threads (j'ai vérifié cela), et CLR avait en fait de pires estimations (100x réel contre seulement 5x pour STRING_SPLIT ); juste un problème sous-jacent avec la coordination des verrous entre les threads, je suppose. Pour l'instant, il peut être intéressant d'utiliser MAXDOP 1 si vous savez que vous écrivez la sortie sur de nouvelles pages.
J'ai inclus les plans graphiques comparant l'approche CLR à l'approche native, pour l'exécution en parallèle et en série (j'ai également téléchargé un fichier d'analyse de requête que vous pouvez ouvrir dans SQL Sentry Plan Explorer pour fouiner par vous-même) :
STRING_SPLIT
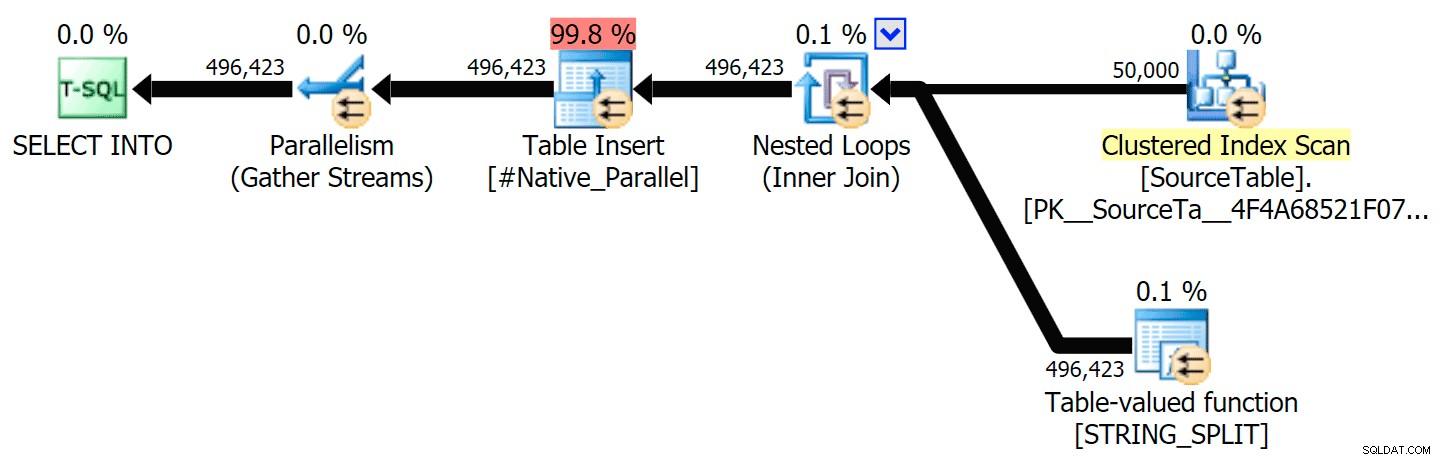
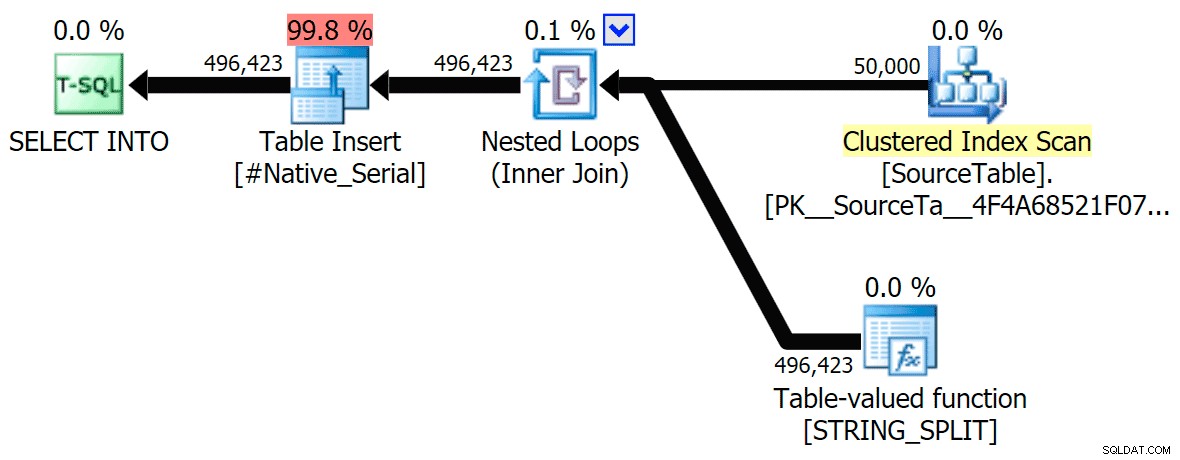
CLR
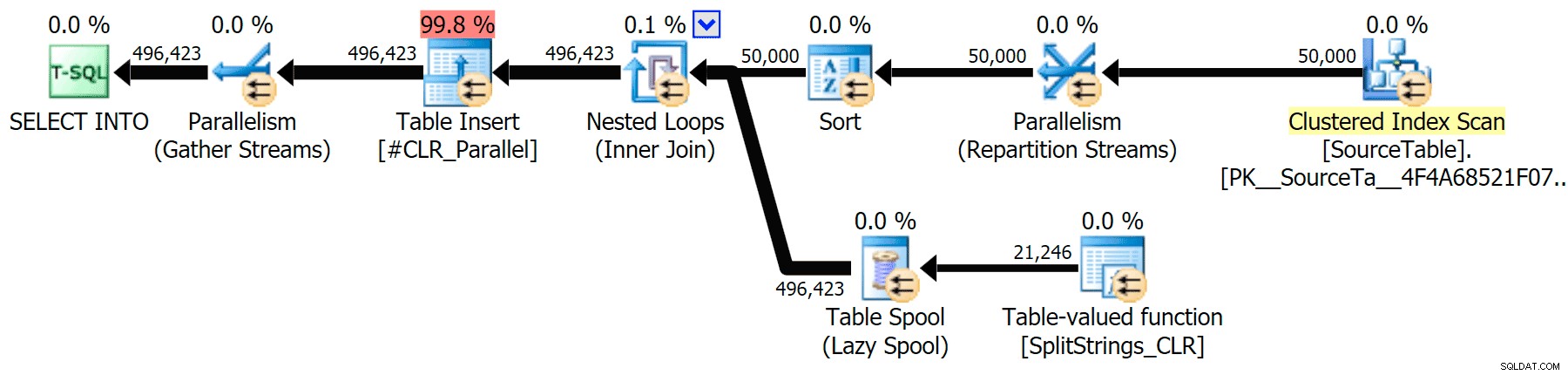
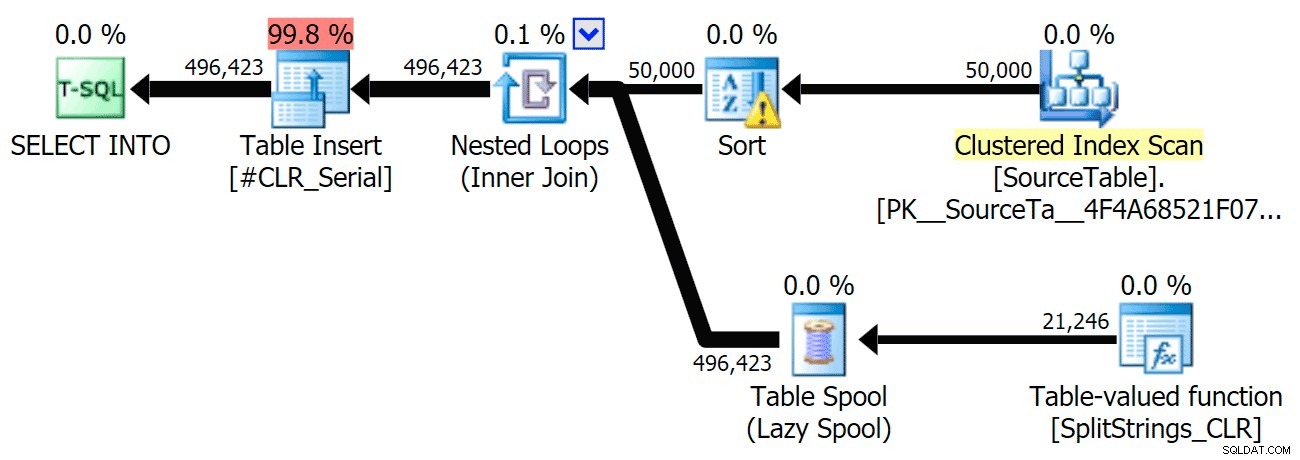
L'avertissement de tri, pour votre information, n'avait rien de trop choquant et n'avait évidemment pas beaucoup d'effet tangible sur la durée de la requête :

- StringSplit.queryanalysis.zip (25kb)
S'enroule pour l'été
Quand j'ai regardé d'un peu plus près ces plans, j'ai remarqué que dans le plan CLR, il y a une bobine paresseuse. Ceci est introduit pour s'assurer que les doublons sont traités ensemble (pour économiser du travail en faisant moins de fractionnement réel), mais ce spool n'est pas toujours possible dans toutes les formes de plan, et il peut donner un petit avantage à ceux qui peuvent l'utiliser ( ex. plan CLR), en fonction des estimations. Pour comparer sans bobines, j'ai activé l'indicateur de trace 8690 et j'ai réexécuté les tests. Tout d'abord, voici le plan CLR parallèle sans le spool :
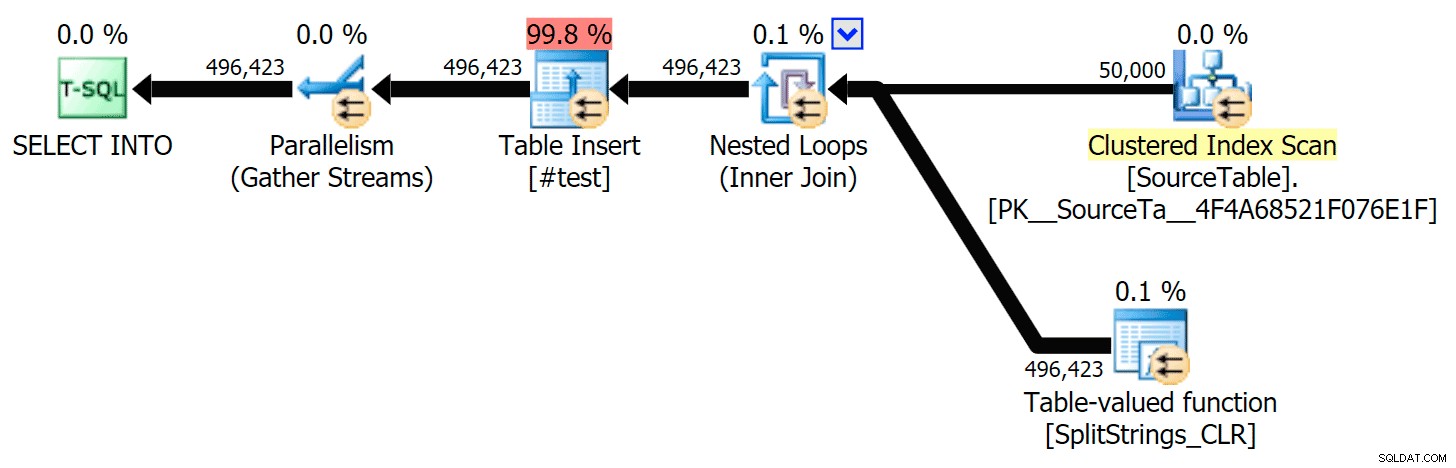
Et voici les nouvelles durées pour toutes les requêtes parallèles avec TF 8690 activé :
Maintenant, voici le plan CLR série sans le spool :
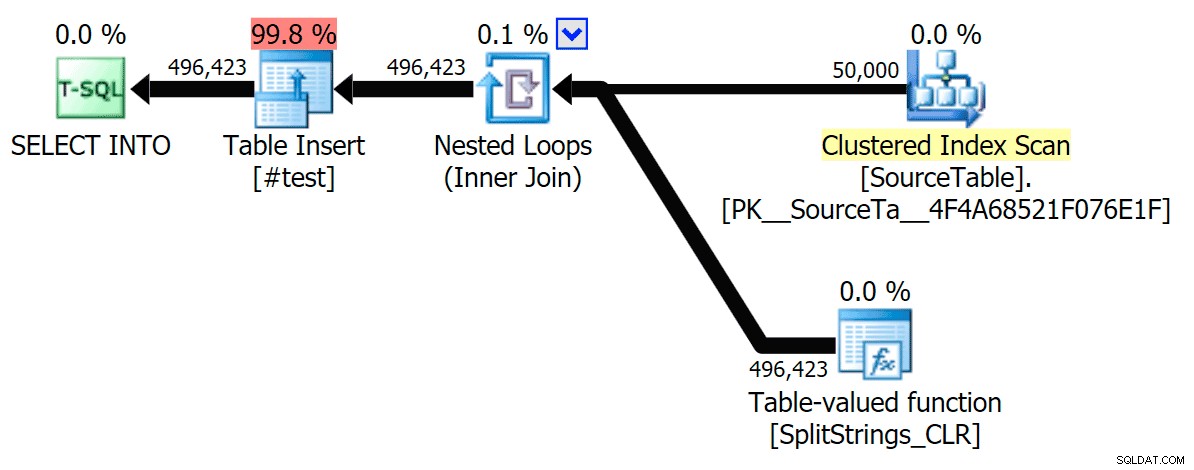
Et voici les résultats de synchronisation pour les requêtes utilisant à la fois TF 8690 et MAXDOP 1 :
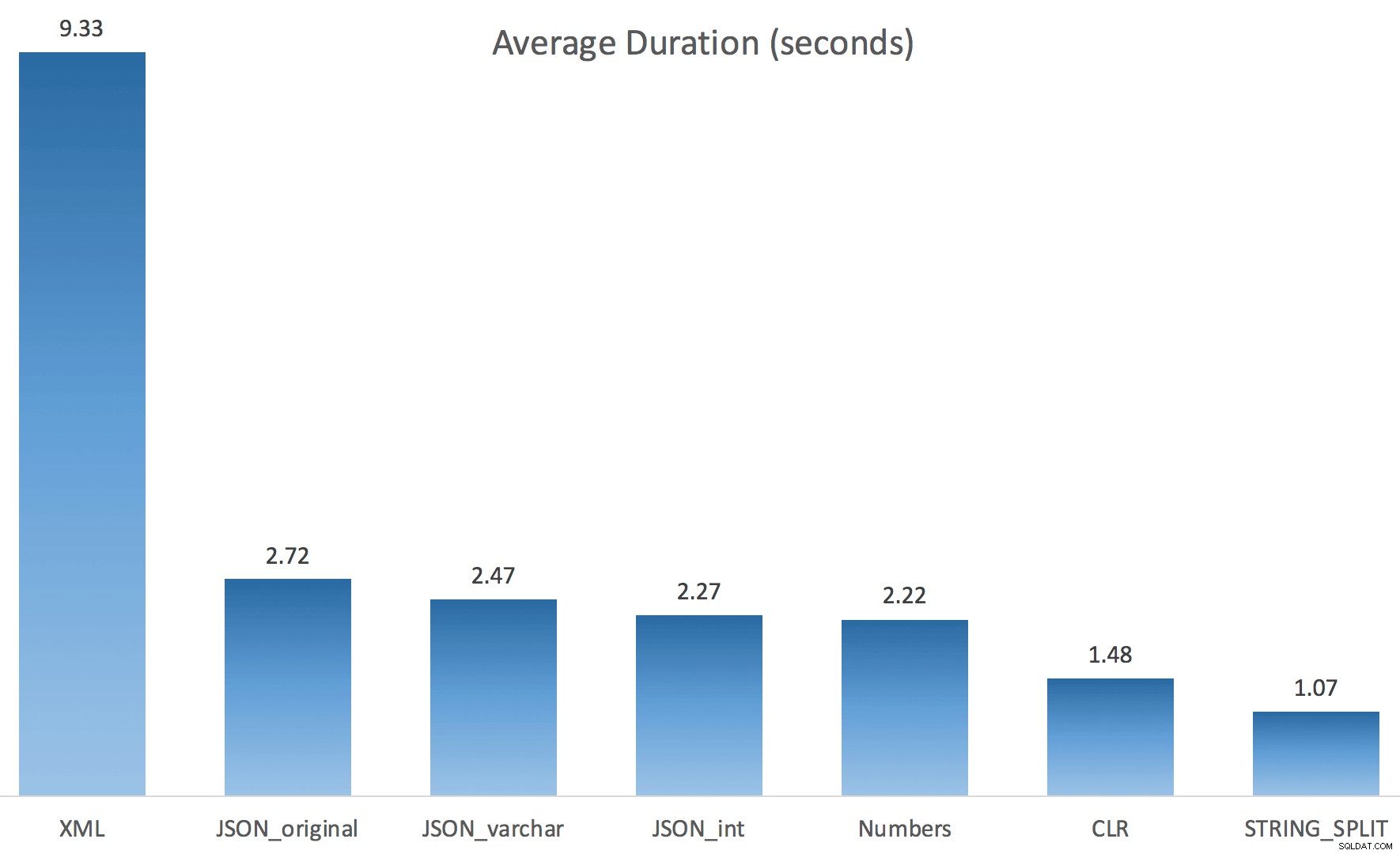
(Notez qu'à part le plan XML, la plupart des autres n'ont pas changé du tout, avec ou sans l'indicateur de trace.)
Comparaison des nombres de lignes estimés
Dan Holmes a posé la question suivante :
Comment estime-t-il la taille des données lorsqu'elles sont jointes à une autre (ou plusieurs) fonction de fractionnement ? Le lien ci-dessous est une description d'une implémentation fractionnée basée sur le CLR. Le 2016 fait-il un « meilleur » travail avec les estimations de données ? (Malheureusement, je n'ai pas encore la possibilité d'installer le RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
J'ai donc glissé le code du message de Dan, l'ai modifié pour utiliser mes fonctions et l'ai exécuté via Plan Explorer :
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
Le SPLIT_STRING L'approche propose certainement des estimations * meilleures * que CLR, mais toujours grossièrement supérieures (dans ce cas, lorsque la chaîne est vide, cela peut ne pas toujours être le cas). La fonction a une valeur par défaut intégrée qui estime que la chaîne entrante aura 50 éléments, donc lorsque vous les imbriquez, vous obtenez 50 x 50 (2 500); si vous les imbriquez à nouveau, 50 x 2 500 (125 000); et enfin, 50 x 125 000 (6 250 000) :
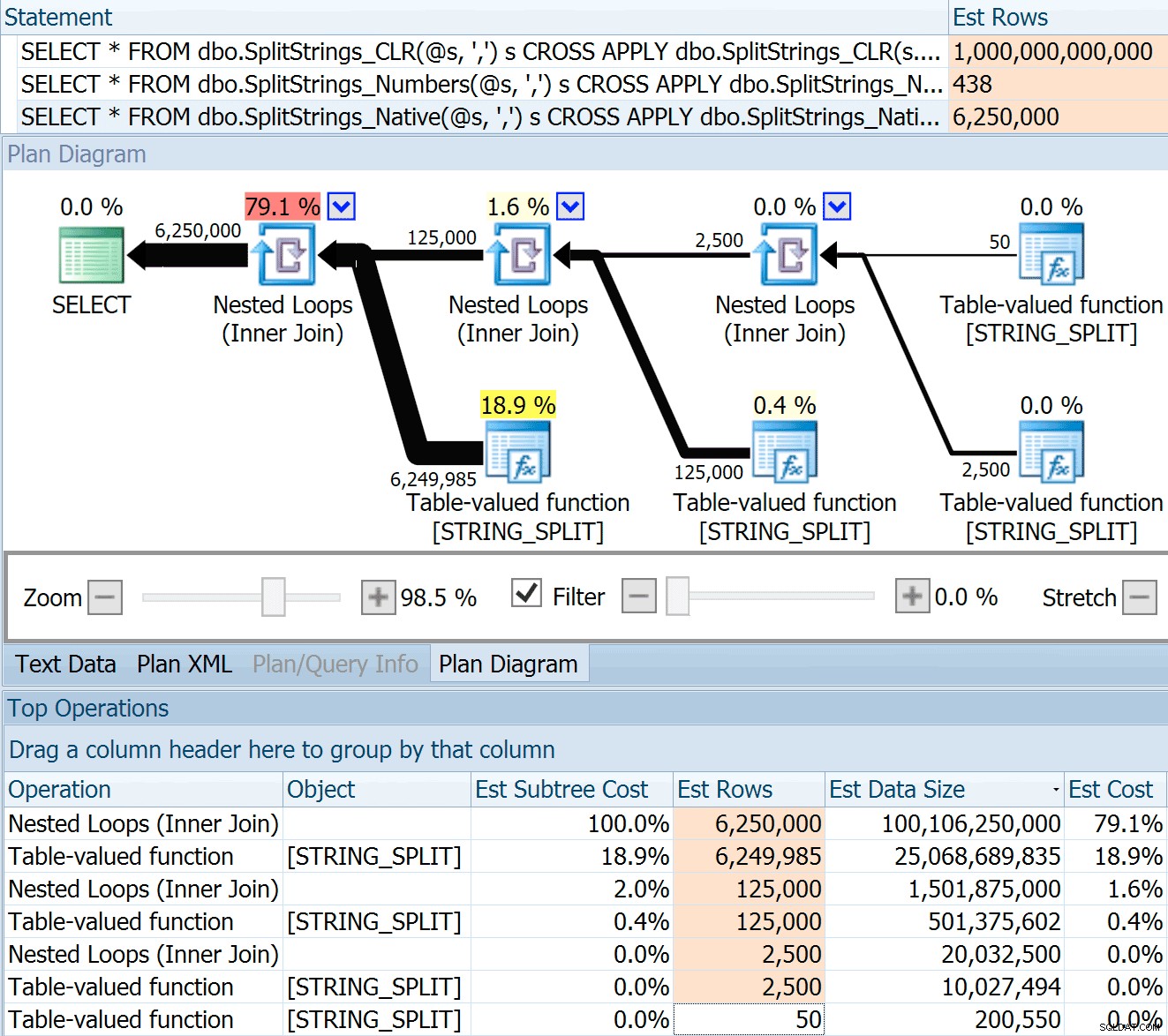
Remarque :OPENJSON() se comporte exactement de la même manière que STRING_SPLIT - il suppose également que 50 lignes sortiront d'une opération de fractionnement donnée. Je pense qu'il pourrait être utile d'avoir un moyen d'indiquer la cardinalité pour des fonctions comme celle-ci, en plus des drapeaux de trace comme 4137 (avant 2014), 9471 et 9472 (2014+), et bien sûr 9481…
Cette estimation de 6,25 millions de lignes n'est pas excellente, mais elle est bien meilleure que l'approche CLR dont parlait Dan, qui estime UN TRILLION DE LIGNES , et j'ai perdu le compte des virgules pour déterminer la taille des données - 16 pétaoctets ? exaoctets ?
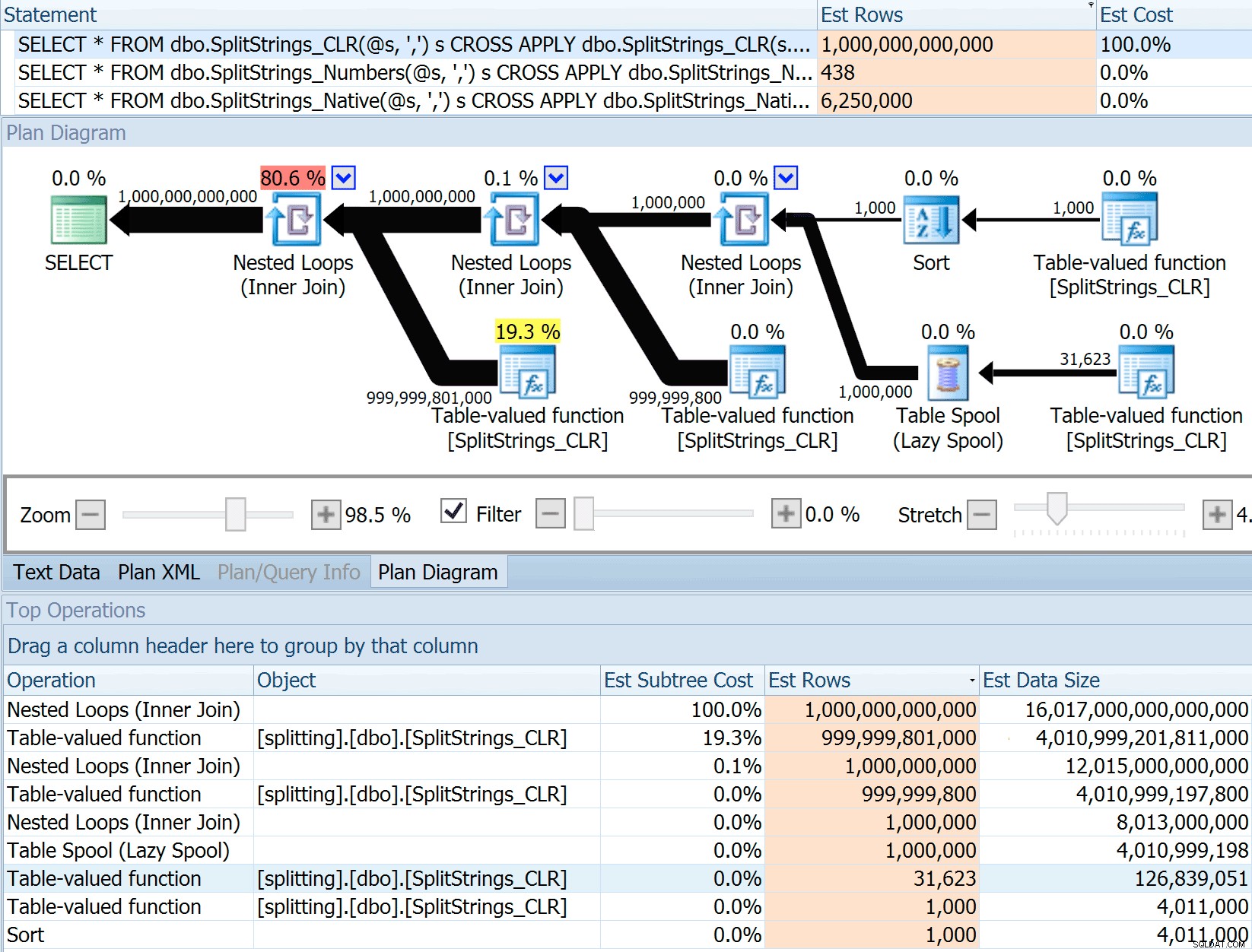
Certaines des autres approches s'en sortent évidemment mieux en termes d'estimations. La table Numbers, par exemple, a estimé un nombre beaucoup plus raisonnable de 438 lignes (dans SQL Server 2016 RC2). D'où vient ce numéro ? Eh bien, il y a 8 000 lignes dans la table, et si vous vous en souvenez, la fonction a à la fois un prédicat d'égalité et un prédicat d'inégalité :
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Ainsi, SQL Server multiplie le nombre de lignes dans la table par 10 % (comme une supposition) pour le filtre d'égalité, puis la racine carrée de 30 % (encore une fois, une supposition) pour le filtre d'inégalité. La racine carrée est due à un backoff exponentiel, ce que Paul White explique ici. Cela nous donne :
8000 * 0,1 * SQRT(0,3) =438,178La variante XML estimait un peu plus d'un milliard de lignes (en raison d'un spool de table estimé être exécuté 5,8 millions de fois), mais son plan était bien trop complexe pour tenter de l'illustrer ici. Dans tous les cas, n'oubliez pas qu'il est clair que les estimations ne disent pas tout. Ce n'est pas parce qu'une requête a des estimations plus précises qu'elle sera plus performante.
Il y avait quelques autres façons de modifier un peu les estimations :à savoir, forcer l'ancien modèle d'estimation de cardinalité (qui affectait à la fois les variations de la table XML et des nombres), et utiliser les TF 9471 et 9472 (qui n'affectaient que la variation de la table des nombres, puisque ils contrôlent tous deux la cardinalité autour de plusieurs prédicats). Voici les façons dont je pouvais modifier les estimations juste un peu (ou BEAUCOUP , en cas de retour à l'ancien modèle CE) :

L'ancien modèle CE a fait chuter les estimations XML d'un ordre de grandeur, mais pour le tableau des nombres, il l'a complètement fait exploser. Les indicateurs de prédicat ont modifié les estimations de la table des nombres, mais ces changements sont beaucoup moins intéressants.
Aucun de ces indicateurs de trace n'a eu d'effet sur les estimations pour le CLR, JSON ou STRING_SPLIT variantes.
Conclusion
Alors qu'est-ce que j'ai appris ici ? Tout un tas, en fait :
- Le parallélisme peut aider dans certains cas, mais lorsqu'il n'aide pas, il vraiment n'aide pas. Les méthodes JSON étaient ~5x plus rapides sans parallélisme, et
STRING_SPLITétait presque 10 fois plus rapide. - Le spool a en fait aidé l'approche CLR à mieux fonctionner dans ce cas, mais TF 8690 peut être utile pour expérimenter dans d'autres cas où vous voyez des spools et essayez d'améliorer les performances. Je suis certain qu'il y a des situations où l'élimination de la bobine finira par être meilleure dans l'ensemble.
- L'élimination du spool a vraiment nui à l'approche XML (mais seulement de manière drastique lorsqu'il a été forcé d'être monothread).
- Beaucoup de choses bizarres peuvent se produire avec les estimations en fonction de l'approche, ainsi que les statistiques, la distribution et les indicateurs de suivi habituels. Eh bien, je suppose que je le savais déjà, mais il y a certainement quelques bons exemples concrets ici.
Merci aux personnes qui ont posé des questions ou m'ont poussé à inclure plus d'informations. Et comme vous l'avez peut-être deviné d'après le titre, j'aborde encore une autre question dans un deuxième suivi, celle-ci sur les TVP :
- STRING_SPLIT() dans SQL Server 2016 :suivi 2