Je suis un chercheur en intelligence artificielle, donc l'une des principales choses que je traite, ce sont les données. Beaucoup de celui-ci.
Avec plus de 2,5 exaoctets de données générées chaque jour , il n'est pas surprenant que ces données doivent être stockées quelque part où nous pouvons y accéder quand nous en avons besoin.
Cet article vous guidera à travers une feuille de triche piratable pour vous permettre d'être rapidement opérationnel avec SQL.
Qu'est-ce que SQL ?
SQL signifie langage de requête structuré. C'est un langage pour les systèmes de gestion de bases de données relationnelles. SQL est utilisé aujourd'hui pour stocker, récupérer et manipuler des données dans des bases de données relationnelles.
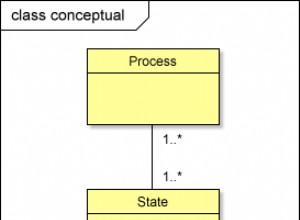
Voici à quoi ressemble une base de données relationnelle de base :
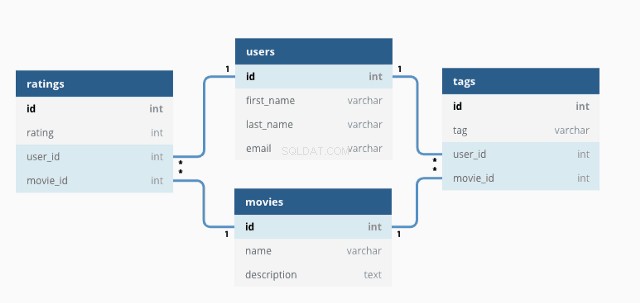
En utilisant SQL, nous pouvons interagir avec la base de données en écrivant des requêtes.
Voici à quoi ressemble un exemple de requête :
SELECT * FROM customers;
Utilisation de ce SELECT déclaration, la requête sélectionne tous les données de toutes les colonnes de la table du client et renvoie des données comme suit :
Le caractère générique astérisque (*) fait référence à "tous ” et sélectionne tous les lignes et les colonnes. Nous pouvons le remplacer par des noms de colonnes spécifiques à la place — ici, seules ces colonnes seront renvoyées par la requête
SELECT FirstName, LastName FROM customers;
Ajout d'un WHERE La clause vous permet de filtrer ce qui est renvoyé :
SELECT * FROM customers WHERE age >= 30 ORDER BY age ASC;Cette requête renvoie toutes les données de la table des produits avec un âge valeur supérieure à 30.
L'utilisation de ORDER BY mot-clé signifie simplement que les résultats seront classés en utilisant la colonne d'âge de la valeur la plus basse à la plus élevée
Utilisation de INSERT INTO déclaration, nous pouvons ajouter de nouvelles données à une table. Voici un exemple simple d'ajout d'un nouvel utilisateur à la table des clients :
INSERT INTO customers(FirstName, LastName, address, email)
VALUES ('Jason', 'Dsouza', 'McLaren Vale, South Australia', 'test@fakeGmail.com');Bien sûr, ces exemples ne montrent qu'une très petite sélection de ce que le langage SQL peut faire. Nous en apprendrons plus à ce sujet dans ce guide.
Pourquoi apprendre SQL ?
Nous vivons à l'ère du Big Data, où les données sont largement utilisées pour trouver des informations et éclairer la stratégie, le marketing, la publicité et une pléthore d'autres opérations.
Les grandes entreprises comme Google, Amazon, AirBnb utilisent de grandes bases de données relationnelles comme base pour améliorer l'expérience client. Comprendre SQL est une grande compétence non seulement pour les data scientists et les analystes, mais pour tout le monde.
Comment pensez-vous que vous avez soudainement reçu une publicité Youtube sur des chaussures alors qu'il y a quelques minutes à peine, vous recherchiez vos chaussures préférées sur Google ? C'est SQL (ou une forme de SQL) au travail !
SQL contre MySQL
Avant de continuer, je veux juste clarifier un sujet souvent confus — la différence entre SQL et MySQL. Il s'avère qu'ils ne le sont pas la même chose !
SQL est un langage, tandis que MySQL est un système pour implémenter SQL.
SQL décrit la syntaxe qui vous permet d'écrire des requêtes qui gèrent des bases de données relationnelles.
MySQL est un système de base de données qui s'exécute sur un serveur. Il vous permet d'écrire des requêtes en utilisant la syntaxe SQL pour gérer les bases de données MySQL.
En plus de MySQL, il existe d'autres systèmes qui implémentent SQL. Parmi les plus populaires, citons :
- SQLite
- Base de données Oracle
- PostgreSQL
- Microsoft SQL Server
Comment installer MySQL
Dans la plupart des cas, MySQL est le choix préféré pour un système de gestion de base de données. De nombreux systèmes de gestion de contenu populaires (comme Wordpress) utilisent MySQL par défaut, donc utiliser MySQL pour gérer ces applications peut être une bonne idée.
Pour utiliser MySQL, vous devez l'installer sur votre système :
Installer MySQL sur Windows
La méthode recommandée pour installer MySQL sur Windows consiste à utiliser le programme d'installation MSI du site Web de MySQL.
Cette ressource vous guidera dans le processus d'installation.
Installer MySQL sur macOS
Sur macOS, l'installation de MySQL implique également le téléchargement d'un programme d'installation.
Cette ressource vous guidera tout au long du processus d'installation.
Comment utiliser MySQL
Avec MySQL maintenant installé sur votre système, je vous recommande d'utiliser une sorte d'application de gestion SQL pour faciliter la gestion de vos bases de données.
Il existe de nombreuses applications parmi lesquelles choisir, qui font en grande partie le même travail, c'est donc à vous de décider laquelle utiliser :
- MySQL Workbench développé par Oracle
- phpMyAdmin (fonctionne dans le navigateur Web)
- HeidiSQL (recommandé pour Windows)
- Sequel Pro (recommandé pour macOS)
Lorsque vous êtes prêt à commencer à écrire vos propres requêtes SQL, envisagez d'importer des données factices plutôt que de créer votre propre base de données.
Voici quelques bases de données factices disponibles en téléchargement gratuit.
Cheatsheet SQL – La cerise sur le gâteau
Mots clés SQL
Vous trouverez ici une collection de mots clés utilisés dans les instructions SQL, une description et, le cas échéant, un exemple. Certains des mots-clés les plus avancés ont leur propre section dédiée.
Lorsque MySQL est mentionné à côté d'un exemple, cela signifie que cet exemple ne s'applique qu'aux bases de données MySQL (par opposition à tout autre système de base de données).
ADD -- Adds a new column to an existing table
ADD CONSTRAINT -- Creates a new constraint on an existing table, which is used to specify rules for any data in the table.
ALTER TABLE -- Adds, deletes or edits columns in a table. It can also be used to add and delete constraints in a table, as per the above.
ALTER COLUMN -- Changes the data type of a table’s column.
ALL -- Returns true if all of the subquery values meet the passed condition.
AND -- Used to join separate conditions within a WHERE clause.
ANY -- Returns true if any of the subquery values meet the given condition.
AS -- Renames a table or column with an alias value which only exists for the duration of the query.
ASC -- Used with ORDER BY to return the data in ascending order.
BETWEEN -- Selects values within the given range.
CASE -- Changes query output depending on conditions.
CHECK -- Adds a constraint that limits the value which can be added to a column.
CREATE DATABASE -- Creates a new database.
CREATE TABLE -- Creates a new table.
DEFAULT -- Sets a default value for a column
DELETE -- Delete data from a table.
DESC -- Used with ORDER BY to return the data in descending order.
DROP COLUMN -- Deletes a column from a table.
DROP DATABASE -- Deletes the entire database.
DROP DEAFULT -- Removes a default value for a column.
DROP TABLE -- Deletes a table from a database.
EXISTS -- Checks for the existence of any record within the subquery, returning true if one or more records are returned.
FROM -- Specifies which table to select or delete data from.
IN -- Used alongside a WHERE clause as a shorthand for multiple OR conditions.
INSERT INTO -- Adds new rows to a table.
IS NULL -- Tests for empty (NULL) values.
IS NOT NULL -- The reverse of NULL. Tests for values that aren’t empty / NULL.
LIKE -- Returns true if the operand value matches a pattern.
NOT -- Returns true if a record DOESN’T meet the condition.
OR -- Used alongside WHERE to include data when either condition is true.
ORDER BY -- Used to sort the result data in ascending (default) or descending order through the use of ASC or DESC keywords.
ROWNUM -- Returns results where the row number meets the passed condition.
SELECT -- Used to select data from a database, which is then returned in a results set.
SELECT DISTINCT -- Sames as SELECT, except duplicate values are excluded.
SELECT INTO -- Copies data from one table and inserts it into another.
SELECT TOP -- Allows you to return a set number of records to return from a table.
SET -- Used alongside UPDATE to update existing data in a table.
SOME -- Identical to ANY.
TOP -- Used alongside SELECT to return a set number of records from a table.
TRUNCATE TABLE -- Similar to DROP, but instead of deleting the table and its data, this deletes only the data.
UNION -- Combines the results from 2 or more SELECT statements and returns only distinct values.
UNION ALL -- The same as UNION, but includes duplicate values.
UNIQUE -- This constraint ensures all values in a column are unique.
UPDATE -- Updates existing data in a table.
VALUES -- Used alongside the INSERT INTO keyword to add new values to a table.
WHERE -- Filters results to only include data which meets the given condition.
Commentaires en SQL
Les commentaires vous permettent d'expliquer des sections de vos instructions SQL, sans être exécutés directement.
En SQL, il existe 2 types de commentaires, une ligne et plusieurs lignes.
Commentaires sur une seule ligne en SQL
Les commentaires sur une seule ligne commencent par "- -". Tout texte après ces 2 caractères jusqu'à la fin de la ligne sera ignoré.
-- This part is ignored
SELECT * FROM customers;Commentaires multilignes en SQL
Les commentaires multilignes commencent par /* et se terminent par */. Ils s'étendent sur plusieurs lignes jusqu'à ce que les derniers caractères soient trouvés.
/*
This is a multiline comment.
It can span across multiple lines.
*/
SELECT * FROM customers;
/*
This is another comment.
You can even put code within a comment to prevent its execution
SELECT * FROM icecreams;
*/Types de données dans MySQL
Lors de la création d'un nouveau tableau ou de la modification d'un tableau existant, vous devez spécifier le type de données que chaque colonne accepte.
Dans cet exemple, les données transmises au id colonne doit être un int (entier), tandis que le FirstName la colonne a un VARCHAR type de données avec un maximum de 255 caractères.
CREATE TABLE customers(
id int,
FirstName varchar(255)
);1. Types de données de chaîne
CHAR(size) -- Fixed length string which can contain letters, numbers and special characters. The size parameter sets the maximum string length, from 0 – 255 with a default of 1.
VARCHAR(size) -- Variable length string similar to CHAR(), but with a maximum string length range from 0 to 65535.
BINARY(size) -- Similar to CHAR() but stores binary byte strings.
VARBINARY(size) -- Similar to VARCHAR() but for binary byte strings.
TINYBLOB -- Holds Binary Large Objects (BLOBs) with a max length of 255 bytes.
TINYTEXT -- Holds a string with a maximum length of 255 characters. Use VARCHAR() instead, as it’s fetched much faster.
TEXT(size) -- Holds a string with a maximum length of 65535 bytes. Again, better to use VARCHAR().
BLOB(size) -- Holds Binary Large Objects (BLOBs) with a max length of 65535 bytes.
MEDIUMTEXT -- Holds a string with a maximum length of 16,777,215 characters.
MEDIUMBLOB -- Holds Binary Large Objects (BLOBs) with a max length of 16,777,215 bytes.
LONGTEXT -- Holds a string with a maximum length of 4,294,967,295 characters.
LONGBLOB -- Holds Binary Large Objects (BLOBs) with a max length of 4,294,967,295 bytes.
ENUM(a, b, c, etc…) -- A string object that only has one value, which is chosen from a list of values which you define, up to a maximum of 65535 values. If a value is added which isn’t on this list, it’s replaced with a blank value instead.
SET(a, b, c, etc…) -- A string object that can have 0 or more values, which is chosen from a list of values which you define, up to a maximum of 64 values.
2. Types de données numériques
BIT(size) -- A bit-value type with a default of 1. The allowed number of bits in a value is set via the size parameter, which can hold values from 1 to 64.
TINYINT(size) -- A very small integer with a signed range of -128 to 127, and an unsigned range of 0 to 255. Here, the size parameter specifies the maximum allowed display width, which is 255.
BOOL -- Essentially a quick way of setting the column to TINYINT with a size of 1. 0 is considered false, whilst 1 is considered true.
BOOLEAN -- Same as BOOL.
SMALLINT(size) -- A small integer with a signed range of -32768 to 32767, and an unsigned range from 0 to 65535. Here, the size parameter specifies the maximum allowed display width, which is 255.
MEDIUMINT(size) -- A medium integer with a signed range of -8388608 to 8388607, and an unsigned range from 0 to 16777215. Here, the size parameter specifies the maximum allowed display width, which is 255.
INT(size) -- A medium integer with a signed range of -2147483648 to 2147483647, and an unsigned range from 0 to 4294967295. Here, the size parameter specifies the maximum allowed display width, which is 255.
INTEGER(size) -- Same as INT.
BIGINT(size) -- A medium integer with a signed range of -9223372036854775808 to 9223372036854775807, and an unsigned range from 0 to 18446744073709551615. Here, the size parameter specifies the maximum allowed display width, which is 255.
FLOAT(p) -- A floating point number value. If the precision (p) parameter is between 0 to 24, then the data type is set to FLOAT(), whilst if it's from 25 to 53, the data type is set to DOUBLE(). This behaviour is to make the storage of values more efficient.
DOUBLE(size, d) -- A floating point number value where the total digits are set by the size parameter, and the number of digits after the decimal point is set by the d parameter.
DECIMAL(size, d) -- An exact fixed point number where the total number of digits is set by the size parameters, and the total number of digits after the decimal point is set by the d parameter.
DEC(size, d) -- Same as DECIMAL.3. Types de données de date/heure
DATE -- A simple date in YYYY-MM–DD format, with a supported range from ‘1000-01-01’ to ‘9999-12-31’.
DATETIME(fsp) -- A date time in YYYY-MM-DD hh:mm:ss format, with a supported range from ‘1000-01-01 00:00:00’ to ‘9999-12-31 23:59:59’. By adding DEFAULT and ON UPDATE to the column definition, it automatically sets to the current date/time.
TIMESTAMP(fsp) -- A Unix Timestamp, which is a value relative to the number of seconds since the Unix epoch (‘1970-01-01 00:00:00’ UTC). This has a supported range from ‘1970-01-01 00:00:01’ UTC to ‘2038-01-09 03:14:07’ UTC.
By adding DEFAULT CURRENT_TIMESTAMP and ON UPDATE CURRENT TIMESTAMP to the column definition, it automatically sets to current date/time.
TIME(fsp) -- A time in hh:mm:ss format, with a supported range from ‘-838:59:59’ to ‘838:59:59’.
YEAR -- A year, with a supported range of ‘1901’ to ‘2155’.Opérateurs SQL
1. Opérateurs arithmétiques en SQL
+ -- Add
– -- Subtract
* -- Multiply
/ -- Divide
% -- Modulus2. Opérateurs au niveau du bit en SQL
& -- Bitwise AND
| -- Bitwise OR
^-- Bitwise XOR3. Opérateurs de comparaison en SQL
= -- Equal to
> -- Greater than
< -- Less than
>= -- Greater than or equal to
<= -- Less than or equal to
<> -- Not equal to4. Opérateurs composés en SQL
+= -- Add equals
-= -- Subtract equals
*= -- Multiply equals
/= -- Divide equals
%= -- Modulo equals
&= -- Bitwise AND equals
^-= -- Bitwise exclusive equals
|*= -- Bitwise OR equalsFonctions SQL
1. Fonctions de chaîne en SQL
ASCII -- Returns the equivalent ASCII value for a specific character.
CHAR_LENGTH -- Returns the character length of a string.
CHARACTER_LENGTH -- Same as CHAR_LENGTH.
CONCAT -- Adds expressions together, with a minimum of 2.
CONCAT_WS -- Adds expressions together, but with a separator between each value.
FIELD -- Returns an index value relative to the position of a value within a list of values.
FIND IN SET -- Returns the position of a string in a list of strings.
FORMAT -- When passed a number, returns that number formatted to include commas (eg 3,400,000).
INSERT -- Allows you to insert one string into another at a certain point, for a certain number of characters.
INSTR -- Returns the position of the first time one string appears within another.
LCASE -- Converts a string to lowercase.
LEFT -- Starting from the left, extracts the given number of characters from a string and returns them as another.
LENGTH -- Returns the length of a string, but in bytes.
LOCATE -- Returns the first occurrence of one string within another,
LOWER -- Same as LCASE.
LPAD -- Left pads one string with another, to a specific length.
LTRIM -- Removes any leading spaces from the given string.
MID -- Extracts one string from another, starting from any position.
POSITION -- Returns the position of the first time one substring appears within another.
REPEAT -- Allows you to repeat a string
REPLACE -- Allows you to replace any instances of a substring within a string, with a new substring.
REVERSE -- Reverses the string.
RIGHT -- Starting from the right, extracts the given number of characters from a string and returns them as another.
RPAD -- Right pads one string with another, to a specific length.
RTRIM -- Removes any trailing spaces from the given string.
SPACE -- Returns a string full of spaces equal to the amount you pass it.
STRCMP -- Compares 2 strings for differences
SUBSTR -- Extracts one substring from another, starting from any position.
SUBSTRING -- Same as SUBSTR
SUBSTRING_INDEX -- Returns a substring from a string before the passed substring is found the number of times equals to the passed number.
TRIM -- Removes trailing and leading spaces from the given string. Same as if you were to run LTRIM and RTRIM together.
UCASE -- Converts a string to uppercase.
UPPER -- Same as UCASE.2. Fonctions numériques en SQL
ABS -- Returns the absolute value of the given number.
ACOS -- Returns the arc cosine of the given number.
ASIN -- Returns the arc sine of the given number.
ATAN -- Returns the arc tangent of one or 2 given numbers.
ATAN2 -- Returns the arc tangent of 2 given numbers.
AVG -- Returns the average value of the given expression.
CEIL -- Returns the closest whole number (integer) upwards from a given decimal point number.
CEILING -- Same as CEIL.
COS -- Returns the cosine of a given number.
COT -- Returns the cotangent of a given number.
COUNT -- Returns the amount of records that are returned by a SELECT query.
DEGREES -- Converts a radians value to degrees.
DIV -- Allows you to divide integers.
EXP -- Returns e to the power of the given number.
FLOOR -- Returns the closest whole number (integer) downwards from a given decimal point number.
GREATEST -- Returns the highest value in a list of arguments.
LEAST -- Returns the smallest value in a list of arguments.
LN -- Returns the natural logarithm of the given number.
LOG -- Returns the natural logarithm of the given number, or the logarithm of the given number to the given base.
LOG10 -- Does the same as LOG, but to base 10.
LOG2 -- Does the same as LOG, but to base 2.
MAX -- Returns the highest value from a set of values.
MIN -- Returns the lowest value from a set of values.
MOD -- Returns the remainder of the given number divided by the other given number.
PI -- Returns PI.
POW -- Returns the value of the given number raised to the power of the other given number.
POWER -- Same as POW.
RADIANS -- Converts a degrees value to radians.
RAND -- Returns a random number.
ROUND -- Rounds the given number to the given amount of decimal places.
SIGN -- Returns the sign of the given number.
SIN -- Returns the sine of the given number.
SQRT -- Returns the square root of the given number.
SUM -- Returns the value of the given set of values combined.
TAN -- Returns the tangent of the given number.
TRUNCATE -- Returns a number truncated to the given number of decimal places.3. Fonctions de date en SQL
ADDDATE -- Adds a date interval (eg: 10 DAY) to a date (eg: 20/01/20) and returns the result (eg: 20/01/30).
ADDTIME -- Adds a time interval (eg: 02:00) to a time or datetime (05:00) and returns the result (07:00).
CURDATE -- Gets the current date.
CURRENT_DATE -- Same as CURDATE.
CURRENT_TIME -- Gest the current time.
CURRENT_TIMESTAMP -- Gets the current date and time.
CURTIME -- Same as CURRENT_TIME.
DATE -- Extracts the date from a datetime expression.
DATEDIFF -- Returns the number of days between the 2 given dates.
DATE_ADD -- Same as ADDDATE.
DATE_FORMAT -- Formats the date to the given pattern.
DATE_SUB -- Subtracts a date interval (eg: 10 DAY) to a date (eg: 20/01/20) and returns the result (eg: 20/01/10).
DAY -- Returns the day for the given date.
DAYNAME -- Returns the weekday name for the given date.
DAYOFWEEK -- Returns the index for the weekday for the given date.
DAYOFYEAR -- Returns the day of the year for the given date.
EXTRACT -- Extracts from the date the given part (eg MONTH for 20/01/20 = 01).
FROM DAYS -- Returns the date from the given numeric date value.
HOUR -- Returns the hour from the given date.
LAST DAY -- Gets the last day of the month for the given date.
LOCALTIME -- Gets the current local date and time.
LOCALTIMESTAMP -- Same as LOCALTIME.
MAKEDATE -- Creates a date and returns it, based on the given year and number of days values.
MAKETIME -- Creates a time and returns it, based on the given hour, minute and second values.
MICROSECOND -- Returns the microsecond of a given time or datetime.
MINUTE -- Returns the minute of the given time or datetime.
MONTH -- Returns the month of the given date.
MONTHNAME -- Returns the name of the month of the given date.
NOW -- Same as LOCALTIME.
PERIOD_ADD -- Adds the given number of months to the given period.
PERIOD_DIFF -- Returns the difference between 2 given periods.
QUARTER -- Returns the year quarter for the given date.
SECOND -- Returns the second of a given time or datetime.
SEC_TO_TIME -- Returns a time based on the given seconds.
STR_TO_DATE -- Creates a date and returns it based on the given string and format.
SUBDATE -- Same as DATE_SUB.
SUBTIME -- Subtracts a time interval (eg: 02:00) to a time or datetime (05:00) and returns the result (03:00).
SYSDATE -- Same as LOCALTIME.
TIME -- Returns the time from a given time or datetime.
TIME_FORMAT -- Returns the given time in the given format.
TIME_TO_SEC -- Converts and returns a time into seconds.
TIMEDIFF -- Returns the difference between 2 given time/datetime expressions.
TIMESTAMP -- Returns the datetime value of the given date or datetime.
TO_DAYS -- Returns the total number of days that have passed from ‘00-00-0000’ to the given date.
WEEK -- Returns the week number for the given date.
WEEKDAY -- Returns the weekday number for the given date.
WEEKOFYEAR -- Returns the week number for the given date.
YEAR -- Returns the year from the given date.
YEARWEEK -- Returns the year and week number for the given date.4. Fonctions diverses en SQL
BIN -- Returns the given number in binary.
BINARY -- Returns the given value as a binary string.
CAST -- Converst one type into another.
COALESCE -- From a list of values, returns the first non-null value.
CONNECTION_ID -- For the current connection, returns the unique connection ID.
CONV -- Converts the given number from one numeric base system into another.
CONVERT -- Converts the given value into the given datatype or character set.
CURRENT_USER -- Returns the user and hostname which was used to authenticate with the server.
DATABASE -- Gets the name of the current database.
GROUP BY -- Used alongside aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the results.
HAVING -- Used in the place of WHERE with aggregate functions.
IF -- If the condition is true it returns a value, otherwise it returns another value.
IFNULL -- If the given expression equates to null, it returns the given value.
ISNULL -- If the expression is null, it returns 1, otherwise returns 0.
LAST_INSERT_ID -- For the last row which was added or updated in a table, returns the auto increment ID.
NULLIF -- Compares the 2 given expressions. If they are equal, NULL is returned, otherwise the first expression is returned.
SESSION_USER -- Returns the current user and hostnames.
SYSTEM_USER -- Same as SESSION_USER.
USER -- Same as SESSION_USER.
VERSION -- Returns the current version of the MySQL powering the database.Caractères génériques en SQL
En SQL, les Wildcards sont des caractères spéciaux utilisés avec le LIKE et NOT LIKE mots clés. Cela nous permet de rechercher des données avec des modèles sophistiqués assez efficacement.
% -- Equates to zero or more characters.
-- Example: Find all customers with surnames ending in ‘ory’.
SELECT * FROM customers
WHERE surname LIKE '%ory';
_ -- Equates to any single character.
-- Example: Find all customers living in cities beginning with any 3 characters, followed by ‘vale’.
SELECT * FROM customers
WHERE city LIKE '_ _ _vale';
[charlist] -- Equates to any single character in the list.
-- Example: Find all customers with first names beginning with J, K or T.
SELECT * FROM customers
WHERE first_name LIKE '[jkt]%';Clés SQL
Dans les bases de données relationnelles, il existe un concept de primaire et étranger clés. Dans les tables SQL, celles-ci sont incluses en tant que contraintes, où une table peut avoir une clé primaire, une clé étrangère ou les deux.
1. Clés primaires en SQL
Un primaire permet à chaque enregistrement d'une table d'être identifié de manière unique. Vous ne pouvez avoir qu'une seule clé primaire par table et vous pouvez affecter cette contrainte à n'importe quelle colonne ou combinaison de colonnes. Cependant, cela signifie que chaque valeur de cette ou ces colonnes doit être unique.
Généralement dans une table, la colonne ID est une clé primaire et est généralement associée à AUTO_INCREMENT mot-clé. Cela signifie que la valeur augmente automatiquement au fur et à mesure que de nouveaux enregistrements sont créés.
Exemple (MySQL)
Créez une nouvelle table et définissez la clé primaire sur la colonne ID.
CREATE TABLE customers (
id int NOT NULL AUTO_INCREMENT,
FirstName varchar(255),
Last Name varchar(255) NOT NULL,
address varchar(255),
email varchar(255),
PRIMARY KEY (id)
);2. Clés étrangères en SQL
Vous pouvez appliquer une clé étrangère à une ou plusieurs colonnes. Vous l'utilisez pour lier 2 tables ensemble dans une base de données relationnelle.
La table contenant la clé étrangère est appelée enfant clé,
La table contenant la clé référencée (ou candidate) est appelée parent tableau.
Cela signifie essentiellement que les données de la colonne sont partagées entre 2 tables, car une clé étrangère empêche également l'insertion de données invalides qui ne sont pas également présentes dans la table parent.
Exemple (MySQL)
Créez une nouvelle table et transformez toute colonne faisant référence à des ID dans d'autres tables en clés étrangères.
CREATE TABLE orders (
id int NOT NULL,
user_id int,
product_id int,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (product_id) REFERENCES products(id)
);Index en SQL
Les index sont des attributs qui peuvent être attribués aux colonnes fréquemment recherchées pour rendre la récupération des données plus rapide et plus efficace.
CREATE INDEX -- Creates an index named ‘idx_test’ on the first_name and surname columns of the users table. In this instance, duplicate values are allowed.
CREATE INDEX idx_test
ON users (first_name, surname);
CREATE UNIQUE INDEX -- The same as the above, but no duplicate values.
CREATE UNIQUE INDEX idx_test
ON users (first_name, surname);
DROP INDEX -- Removes an index.
ALTER TABLE users
DROP INDEX idx_test;Jointures SQL
En SQL, un JOIN La clause est utilisée pour renvoyer un résultat qui combine les données de plusieurs tables, sur la base d'une colonne commune qui figure dans les deux.
Il existe un certain nombre de jointures différentes que vous pouvez utiliser :
- Jointure interne (par défaut) : Renvoie tous les enregistrements dont les valeurs correspondent dans les deux tables.
- Joindre à gauche : Renvoie tous les enregistrements de la première table, ainsi que tous les enregistrements correspondants de la seconde table.
- Rejoindre à droite : Renvoie tous les enregistrements de la deuxième table, ainsi que tous les enregistrements correspondants de la première.
- Joindre complet : Renvoie tous les enregistrements des deux tables lorsqu'il y a une correspondance.
Voici une façon courante de visualiser le fonctionnement des jointures :

SELECT orders.id, users.FirstName, users.Surname, products.name as ‘product name’
FROM orders
INNER JOIN users on orders.user_id = users.id
INNER JOIN products on orders.product_id = products.id;Vues en SQL
Une vue est essentiellement un ensemble de résultats SQL qui est stocké dans la base de données sous une étiquette, de sorte que vous pouvez y revenir ultérieurement sans avoir à réexécuter la requête.
Celles-ci sont particulièrement utiles lorsque vous avez une requête SQL coûteuse dont vous pourriez avoir besoin plusieurs fois. Ainsi, au lieu de l'exécuter encore et encore pour générer le même ensemble de résultats, vous pouvez le faire une seule fois et l'enregistrer en tant que vue.
Comment créer des vues en SQL
Pour créer une vue, vous pouvez procéder comme ceci :
CREATE VIEW priority_users AS
SELECT * FROM users
WHERE country = ‘United Kingdom’;Ensuite, à l'avenir, si vous avez besoin d'accéder à l'ensemble de résultats stocké, vous pouvez le faire comme ceci :
SELECT * FROM [priority_users];Comment remplacer des vues en SQL
Avec le CREATE OR REPLACE commande, vous pouvez mettre à jour une vue comme celle-ci :
CREATE OR REPLACE VIEW [priority_users] AS
SELECT * FROM users
WHERE country = ‘United Kingdom’ OR country=’USA’;Comment supprimer des vues en SQL
Pour supprimer une vue, il suffit d'utiliser le DROP VIEW commande.
DROP VIEW priority_users;Conclusion
La majorité des sites Web et des applications utilisent des bases de données relationnelles d'une manière ou d'une autre. Cela rend SQL extrêmement précieux à connaître car il vous permet de créer des systèmes fonctionnels plus complexes.
Assurez-vous de me suivre sur Twitter pour des mises à jour sur les futurs articles. Bon apprentissage !