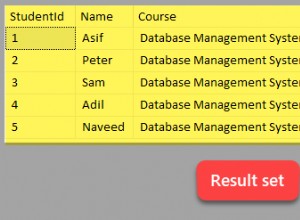
Comptez tous lignes
SELECT date, '1_D' AS time_series, count(DISTINCT user_id) AS cnt
FROM uniques
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W', count(*) OVER (PARTITION BY week_beg ORDER BY date)
FROM uniques
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M', count(*) OVER (PARTITION BY month_beg ORDER BY date)
FROM uniques
ORDER BY 1, time_series
-
Vos colonnes
week_begetmonth_begsont 100 % redondants et peuvent facilement être remplacés pardate_trunc('week', date + 1) - 1etdate_trunc('month', date)respectivement. -
Votre semaine semble commencer le dimanche (off by one), donc le
+ 1 .. - 1. -
Utilisez
UNION ALL, pasUNION. -
Votre choix malheureux pour
time_series(D, W, M) ne trie pas bien, j'ai renommé pour faire le dernierORDER BYplus facile. -
Cette requête peut traiter plusieurs lignes par jour. Les comptes incluent tous les pairs pour une journée.
-
En savoir plus sur
DISTINCT ON:
Utilisateurs DISTINCTS par jour
Pour compter chaque utilisateur une seule fois par jour, utilisez un CTE avec DISTINCT ON :
WITH x AS (SELECT DISTINCT ON (1,2) date, user_id FROM uniques)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM x
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W'
,count(*) OVER (PARTITION BY (date_trunc('week', date + 1)::date - 1)
ORDER BY date)
FROM x
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M'
,count(*) OVER (PARTITION BY date_trunc('month', date) ORDER BY date)
FROM x
ORDER BY 1, 2
Utilisateurs DISTINCTS sur une période dynamique
Vous pouvez toujours recourir à des sous-requêtes corrélées . Tendance à être lent avec les grandes tables !
En s'appuyant sur les requêtes précédentes :
WITH du AS (SELECT date, user_id FROM uniques GROUP BY 1,2)
,d AS (
SELECT date
,(date_trunc('week', date + 1)::date - 1) AS week_beg
,date_trunc('month', date)::date AS month_beg
FROM uniques
GROUP BY 1
)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM du
GROUP BY 1
UNION ALL
SELECT date, '2_W', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.week_beg AND d.date )
FROM d
GROUP BY date, week_beg
UNION ALL
SELECT date, '3_M', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.month_beg AND d.date)
FROM d
GROUP BY date, month_beg
ORDER BY 1,2;
SQL Fiddle pour les trois solutions.
Plus rapide avec dense_rank()
@Clodoaldo
a proposé une amélioration majeure :utilisez la fonction de fenêtre dense_rank()
. Voici une autre idée pour une version optimisée. Il devrait être encore plus rapide d'exclure immédiatement les doublons quotidiens. Le gain de performance augmente avec le nombre de lignes par jour.
S'appuyer sur un modèle de données simplifié et épuré - sans les colonnes redondantes - day comme nom de colonne au lieu de date
date est un mot réservé en SQL standard
et un nom de type de base dans PostgreSQL et ne doit pas être utilisé comme identifiant.
CREATE TABLE uniques(
day date -- instead of "date"
,user_id int
);
Requête améliorée :
WITH du AS (
SELECT DISTINCT ON (1, 2)
day, user_id
,date_trunc('week', day + 1)::date - 1 AS week_beg
,date_trunc('month', day)::date AS month_beg
FROM uniques
)
SELECT day, count(user_id) AS d, max(w) AS w, max(m) AS m
FROM (
SELECT user_id, day
,dense_rank() OVER(PARTITION BY week_beg ORDER BY user_id) AS w
,dense_rank() OVER(PARTITION BY month_beg ORDER BY user_id) AS m
FROM du
) s
GROUP BY day
ORDER BY day;
SQL Fiddle
démontrant les performances de 4 variantes plus rapides. Cela dépend de votre distribution de données qui est la plus rapide pour vous.
Toutes sont environ 10 fois plus rapides que la version des sous-requêtes corrélées (ce qui n'est pas mal pour les sous-requêtes corrélées).