Bienvenue dans la troisième – et dernière – partie de cette série de blogs, explorant comment les performances de PostgreSQL ont évolué au fil des ans. La première partie a examiné les charges de travail OLTP, représentées par des tests pgbench. La deuxième partie a examiné les requêtes analytiques/BI, en utilisant un sous-ensemble du benchmark TPC-H traditionnel (essentiellement une partie du test de puissance).
Et cette dernière partie examine la recherche en texte intégral, c'est-à-dire la possibilité d'indexer et de rechercher dans de grandes quantités de données textuelles. La même infrastructure (en particulier les index) peut être utile pour indexer des données semi-structurées telles que des documents JSONB, etc., mais ce n'est pas ce sur quoi se concentre ce benchmark.
Mais d'abord, regardons l'historique de la recherche en texte intégral dans PostgreSQL, qui peut sembler être une fonctionnalité étrange à ajouter à un SGBDR, traditionnellement destiné à stocker des données structurées en lignes et en colonnes.
L'historique de la recherche en texte intégral
Lorsque Postgres a été open-source en 1996, il n'avait rien que nous puissions appeler la recherche en texte intégral. Mais les personnes qui ont commencé à utiliser Postgres voulaient faire des recherches intelligentes dans des documents texte, et les requêtes LIKE n'étaient pas assez bonnes. Ils voulaient pouvoir lemmatiser les termes à l'aide de dictionnaires, ignorer les mots vides, trier les documents correspondants par pertinence, utiliser des index pour exécuter ces requêtes, et bien d'autres choses. Des choses que vous ne pouvez raisonnablement pas faire avec les opérateurs SQL traditionnels.
Heureusement, certaines de ces personnes étaient également des développeurs, elles ont donc commencé à travailler dessus - et elles ont pu, grâce à la disponibilité de PostgreSQL en open source dans le monde entier. Il y a eu de nombreux contributeurs à la recherche en texte intégral au fil des ans, mais au départ, cet effort a été dirigé par Oleg Bartunov et Teodor Sigaev, illustrés sur la photo suivante. Les deux sont toujours des contributeurs majeurs de PostgreSQL, travaillant sur la recherche en texte intégral, l'indexation, la prise en charge de JSON et de nombreuses autres fonctionnalités.

Teodor Sigaev et Oleg Bartunov
Initialement, la fonctionnalité a été développée sous la forme d'un module externe "contrib" (aujourd'hui, nous dirions que c'est une extension) appelé "tsearch", sorti en 2002. Plus tard, cela a été rendu obsolète par tsearch2, améliorant considérablement la fonctionnalité à bien des égards, et dans PostgreSQL 8.3 (publié en 2008), il était entièrement intégré au cœur de PostgreSQL (c'est-à-dire sans qu'il soit nécessaire d'installer la moindre extension, bien que les extensions soient toujours fournies pour la rétrocompatibilité).
Il y a eu de nombreuses améliorations depuis lors (et le travail se poursuit, par exemple pour prendre en charge des types de données comme JSONB, interroger à l'aide de jsonpath, etc.). mais ces plugins ont introduit la plupart des fonctionnalités de texte intégral que nous avons maintenant dans PostgreSQL - dictionnaires, capacités d'indexation et de requête de texte intégral, etc.
La référence
Contrairement aux benchmarks OLTP / TPC-H, je n'ai connaissance d'aucun benchmark de texte intégral qui pourrait être considéré comme "standard de l'industrie" ou conçu pour plusieurs systèmes de bases de données. La plupart des benchmarks que je connais sont destinés à être utilisés avec une seule base de données / produit, et il est difficile de les porter de manière significative, j'ai donc dû emprunter une voie différente et écrire mon propre benchmark en texte intégral.
Il y a des années, j'ai écrit archie - quelques scripts python qui permettent de télécharger des archives de listes de diffusion PostgreSQL et de charger les messages analysés dans une base de données PostgreSQL qui peut ensuite être indexée et recherchée. L'instantané actuel de toutes les archives contient environ 1 million de lignes et, après l'avoir chargé dans une base de données, la table fait environ 9,5 Go (sans compter les index).
En ce qui concerne les requêtes, je pourrais probablement en générer quelques-unes au hasard, mais je ne sais pas à quel point cela serait réaliste. Heureusement, il y a quelques années, j'ai obtenu un échantillon de 33 000 recherches réelles sur le site Web PostgreSQL (c'est-à-dire des choses que les gens ont réellement recherchées dans les archives de la communauté). Il est peu probable que je puisse obtenir quelque chose de plus réaliste / représentatif.
La combinaison de ces deux parties (ensemble de données + requêtes) semble être une belle référence. Nous pouvons simplement charger les données et exécuter les recherches avec différents types de requêtes en texte intégral avec différents types d'index.
Requêtes
Il existe différentes formes de requêtes en texte intégral - la requête peut simplement sélectionner toutes les lignes correspondantes, elle peut classer les résultats (les trier par pertinence), ne renvoyer qu'un petit nombre ou les résultats les plus pertinents, etc. types de requêtes, mais dans cet article, je présenterai les résultats de deux requêtes simples qui, à mon avis, représentent assez bien le comportement global.
- SELECT id, subject FROM messages WHERE body_tsvector @@ $1
- SELECT id, subject FROM messages WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
La première requête renvoie simplement toutes les lignes correspondantes, tandis que la seconde renvoie les 100 résultats les plus pertinents (c'est quelque chose que vous utiliseriez probablement pour les recherches d'utilisateurs).
J'ai expérimenté divers autres types de requêtes, mais toutes se sont finalement comportées d'une manière similaire à l'un de ces deux types de requêtes.
Index
Chaque message comporte deux parties principales dans lesquelles nous pouvons effectuer une recherche :le sujet et le corps. Chacun d'eux a une colonne tsvector distincte et est indexé séparément. Les sujets des messages sont beaucoup plus courts que les corps, donc les index sont naturellement plus petits.
PostgreSQL possède deux types d'index utiles pour la recherche en texte intégral :GIN et GiST. Les principales différences sont expliquées dans la documentation, mais en bref :
- Les index GIN sont plus rapides pour les recherches
- Les index GiST sont avec perte, c'est-à-dire qu'ils nécessitent une nouvelle vérification pendant les recherches (et sont donc plus lents)
Nous avions l'habitude de prétendre que les index GiST sont moins chers à mettre à jour (en particulier avec de nombreuses sessions simultanées), mais cela a été supprimé de la documentation il y a quelque temps, en raison d'améliorations du code d'indexation.
Ce benchmark ne teste pas le comportement avec les mises à jour - il charge simplement la table sans les index de texte intégral, les construit en une seule fois, puis exécute les requêtes 33k sur les données. Cela signifie que je ne peux rien dire sur la façon dont ces types d'index gèrent les mises à jour simultanées basées sur ce benchmark, mais je pense que les modifications apportées à la documentation reflètent diverses améliorations récentes de GIN.
Cela devrait également correspondre assez bien au cas d'utilisation de l'archive de la liste de diffusion, où nous n'ajoutons de nouveaux e-mails que de temps en temps (peu de mises à jour, presque pas de simultanéité d'écriture). Mais si votre application effectue de nombreuses mises à jour simultanées, vous devrez l'évaluer par vous-même.
Le matériel
J'ai fait le benchmark sur les deux mêmes machines qu'avant, mais les résultats/conclusions sont presque identiques, donc je ne présenterai que les chiffres de la plus petite, c'est-à-dire
- CPU i5-2 500 K (4 cœurs/threads)
- 8 Go de RAM
- 6 disques SSD RAID0 de 100 Go
- noyau 5.6.15, système de fichiers ext4
J'ai déjà mentionné que l'ensemble de données a près de 10 Go lorsqu'il est chargé, il est donc plus grand que la RAM. Mais les index sont toujours plus petits que la RAM, ce qui compte pour le benchmark.
Résultats
OK, il est temps pour quelques chiffres et graphiques. Je présenterai les résultats pour les chargements de données et les requêtes, d'abord avec GIN, puis avec les index GiST.
GIN / chargement de données
La charge n'est pas particulièrement intéressante, je trouve. Premièrement, la majeure partie (la partie bleue) n'a rien à voir avec le texte intégral, car cela se produit avant la création des deux index. La majeure partie de ce temps est consacrée à l'analyse des messages, à la reconstruction des fils de discussion, à la maintenance de la liste des réponses, etc. Une partie de ce code est implémentée dans les déclencheurs PL/pgSQL, une partie est implémentée en dehors de la base de données. La seule partie potentiellement pertinente pour le texte intégral est la construction des tsvectors, mais il est impossible d'isoler le temps passé dessus.
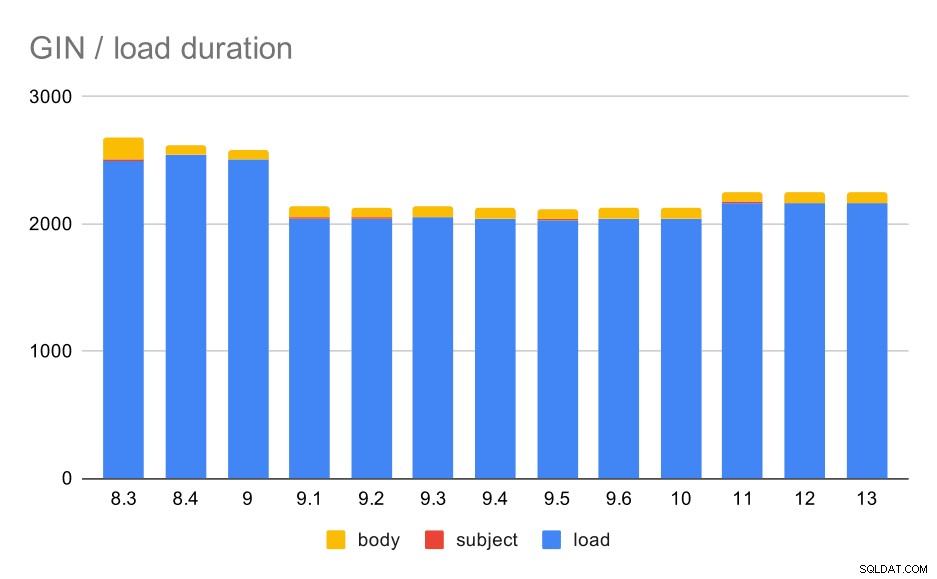
Opérations de chargement de données avec une table et des index GIN.
Le tableau suivant montre les données source de ce graphique - les valeurs sont la durée en secondes. LOAD comprend l'analyse des archives mbox (à partir d'un script Python), l'insertion dans une table et diverses tâches supplémentaires (reconstruction des fils de discussion des e-mails, etc.). L'INDEX SUBJECT/BODY fait référence à la création d'un index GIN en texte intégral sur les colonnes sujet/corps après le chargement des données.
| CHARGER | INDEX DES SUJETS | INDICE CORPOREL | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Clairement, les performances sont assez stables - il y a eu une amélioration assez significative (environ 20%) entre 9.0 et 9.1. Je ne sais pas trop quel changement pourrait être responsable de cette amélioration - rien dans les notes de version 9.1 ne semble clairement pertinent. Il y a aussi une nette amélioration dans la construction des index GIN en 8.4, ce qui réduit le temps de moitié environ. Ce qui est sympa, bien sûr. Chose intéressante, je ne vois aucun élément de note de version manifestement lié à cela non plus.
Mais qu'en est-il de la taille des index GIN ? Il y a beaucoup plus de variabilité, du moins jusqu'à la version 9.4, moment auquel la taille des index passe d'environ 1 Go à seulement 670 Mo environ (environ 30 %).
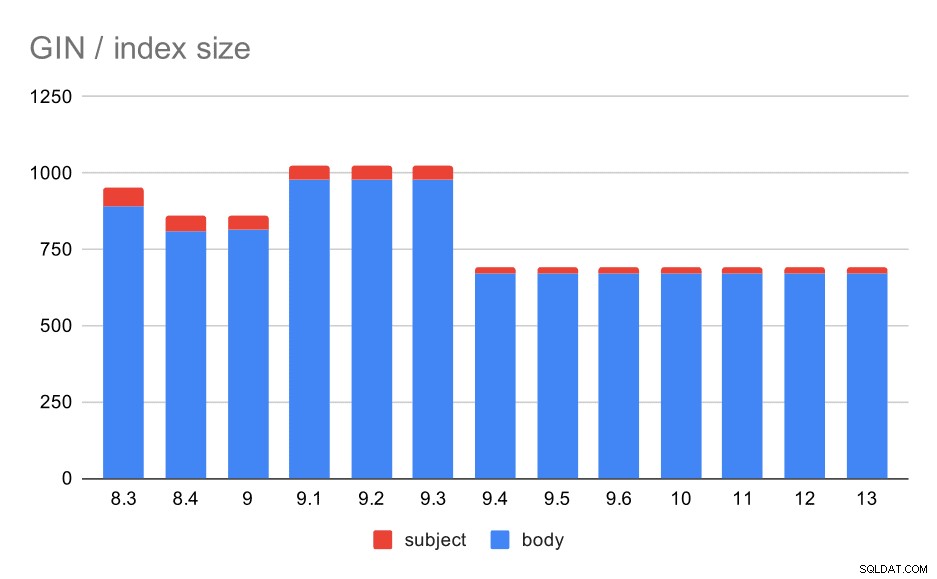
Taille des index GIN sur le sujet/corps du message. Les valeurs sont en mégaoctets.
Le tableau suivant montre les tailles des index GIN sur le corps et l'objet du message. Les valeurs sont en mégaoctets.
| BODY | OBJET | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
Dans ce cas, je pense que nous pouvons supposer en toute sécurité que cette accélération est liée à cet élément dans les notes de version 9.4 :
- Réduire la taille de l'indice GIN (Alexander Korotkov, Heikki Linnakangas)
La variabilité de taille entre 8.3 et 9.1 semble être due à des changements de lemmatisation (comment les mots sont transformés à la forme "de base"). Outre les différences de taille, les requêtes sur ces versions renvoient des nombres de résultats légèrement différents, par exemple.
GIN / requêtes
Maintenant, la partie principale de ce benchmark - les performances des requêtes. Tous les chiffres présentés ici concernent un seul client - nous avons déjà discuté de l'évolutivité du client dans la partie relative aux performances OLTP, les résultats s'appliquent également à ces requêtes. (De plus, cette machine particulière n'a que 4 cœurs, nous n'irions donc pas très loin en termes de tests d'évolutivité de toute façon.)
SELECT id, sujet FROM messages WHERE tsvector @@ $1
Tout d'abord, la requête recherchant tous les documents correspondants. Pour les recherches dans la colonne "sujet", nous pouvons faire environ 800 requêtes par seconde (et cela baisse un peu en 9.1), mais en 9.4, il tire soudainement jusqu'à 3000 requêtes par seconde. Pour la colonne "corps", c'est essentiellement la même histoire :160 requêtes initialement, une baisse à environ 90 requêtes dans la version 9.1, puis une augmentation à 300 dans la version 9.4.
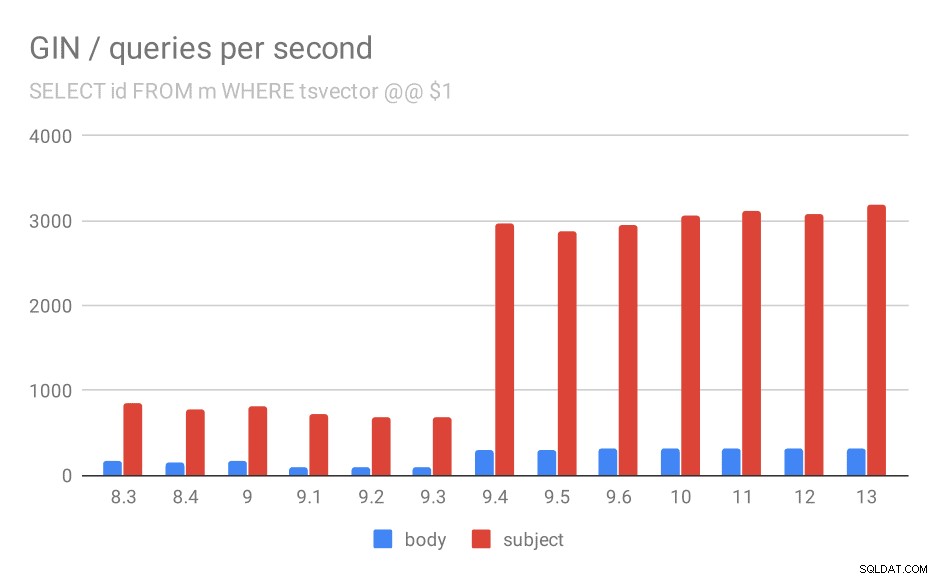
Nombre de requêtes par seconde pour la première requête (récupération de toutes les lignes correspondantes).
Et encore une fois, les données source - les nombres sont le débit (requêtes par seconde).
| BODY | OBJET | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Je pense que nous pouvons supposer en toute sécurité que l'amélioration de la 9.4 est liée à cet élément dans les notes de version :
- Améliorer la vitesse des recherches GIN multi-clés (Alexander Korotkov, Heikki Linnakangas)
Donc, une autre amélioration 9.4 du GIN de la part des deux mêmes développeurs - clairement, Alexander et Heikki ont fait beaucoup de bon travail sur les index GIN dans la version 9.4 😉
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
Pour la requête classant les résultats par pertinence en utilisant ts_rank et LIMIT, le comportement global est presque exactement le même, pas besoin de décrire le graphique en détail, je pense.
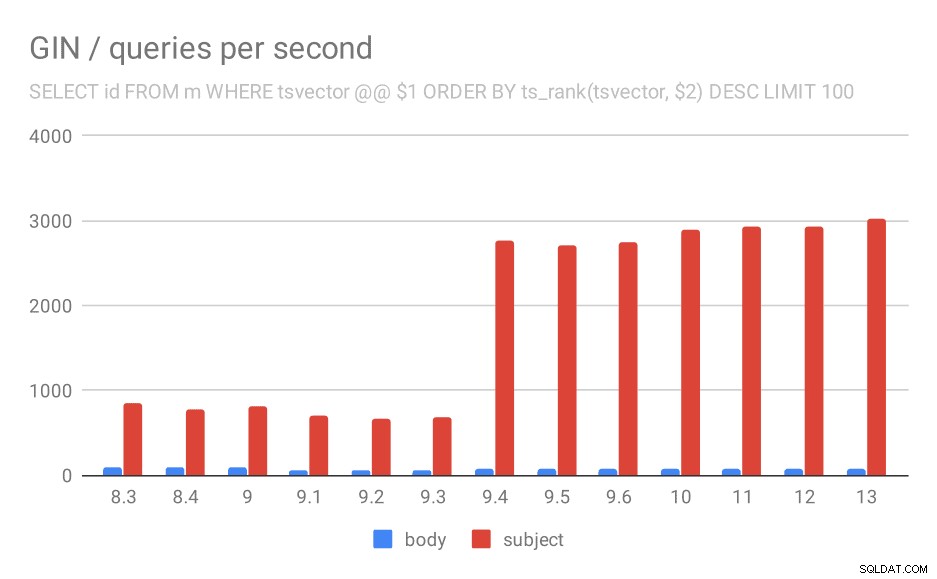
Nombre de requêtes par seconde pour la deuxième requête (récupération des lignes les plus pertinentes).
| BODY | OBJET | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Il y a cependant une question :pourquoi les performances ont-elles chuté entre 9,0 et 9,1 ? Il semble y avoir une baisse assez importante du débit – d'environ 50 % pour les fouilles corporelles et de 20 % pour les recherches dans les sujets des messages. Je n'ai pas d'explication claire sur ce qui s'est passé, mais j'ai deux observations...
Tout d'abord, la taille de l'index a changé - si vous regardez le premier graphique "GIN / taille de l'index" et le tableau, vous verrez que l'index sur les corps des messages est passé de 813 Mo à environ 977 Mo. C'est une augmentation significative, et cela pourrait expliquer une partie du ralentissement. Le problème cependant est que l'index sur les sujets n'a pas augmenté du tout, mais les requêtes sont également devenues plus lentes.
Deuxièmement, nous pouvons examiner le nombre de résultats renvoyés par les requêtes. L'ensemble de données indexées est exactement le même, il semble donc raisonnable d'attendre le même nombre de résultats dans toutes les versions de PostgreSQL, n'est-ce pas ? Eh bien, en pratique, cela ressemble à ceci :
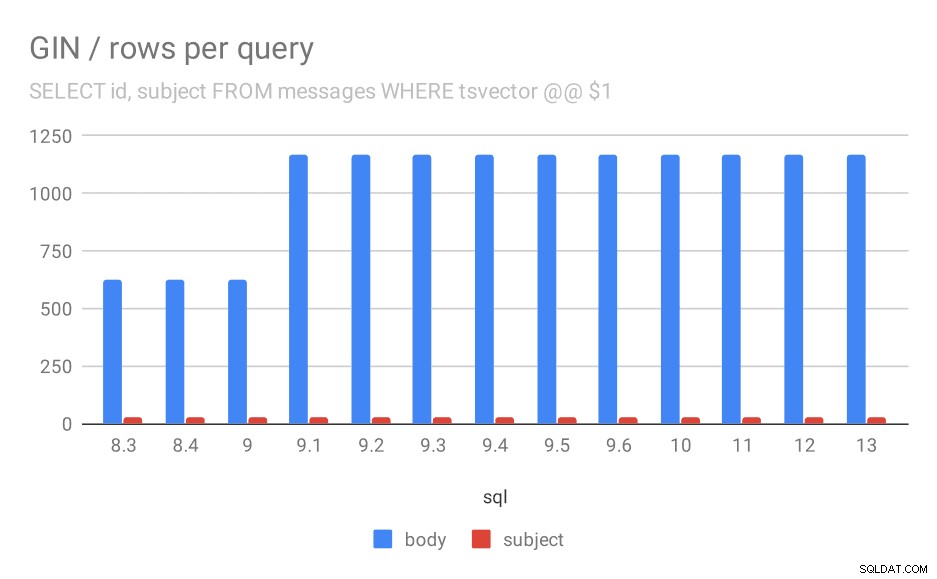
Nombre de lignes renvoyées pour une requête en moyenne.
| BODY | OBJET | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
En clair, en 9.1, le nombre moyen de résultats pour les recherches dans le corps des messages double soudainement, ce qui est presque parfaitement proportionnel au ralentissement. Cependant, le nombre de résultats pour les recherches par sujet reste le même. Je n'ai pas de très bonne explication à cela, sauf que l'indexation a changé d'une manière qui permet de faire correspondre plus de messages, mais en la rendant un peu plus lente. Si vous avez de meilleures explications, j'aimerais les entendre !
GiST / chargement de données
Maintenant, l'autre type d'index de texte intégral - GiST. Ces index sont avec perte, c'est-à-dire qu'ils nécessitent une nouvelle vérification des résultats à l'aide des valeurs de la table. Nous pouvons donc nous attendre à un débit inférieur par rapport aux index GIN, mais sinon, il est raisonnable de s'attendre à peu près au même schéma.
Les temps de chargement correspondent en effet presque parfaitement au GIN - les temps de création d'index sont différents, mais le schéma général est le même. Accélération en 9.1, petit ralentissement en 11.
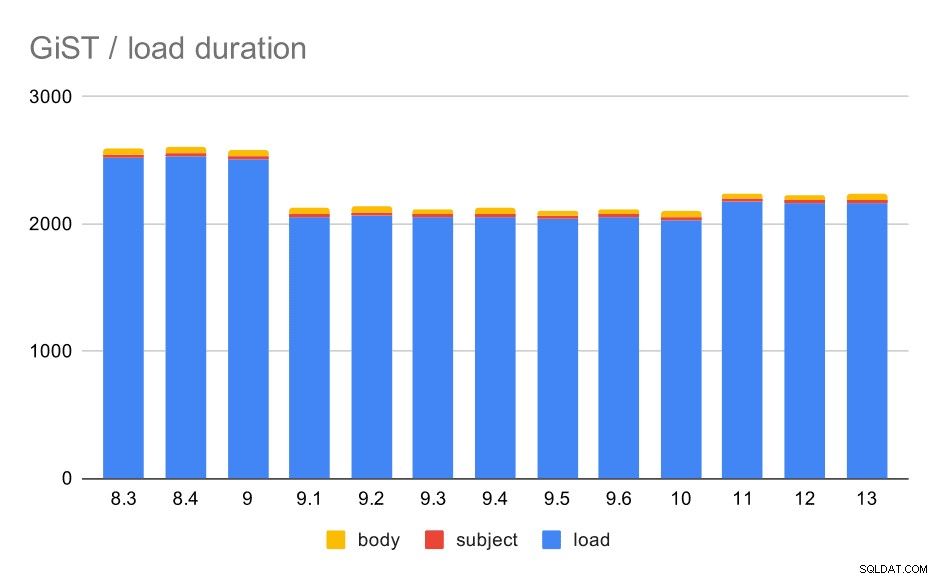
Opérations de chargement de données avec une table et des index GiST.
| CHARGER | OBJET | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
La taille de l'index est cependant restée presque constante - il n'y a pas eu d'améliorations GiST similaires à GIN dans 9.4, ce qui a réduit la taille d'environ 30 %. Il y a une augmentation dans 9.1, ce qui est un autre signe que l'indexation de texte intégral a changé dans cette version pour indexer plus de mots.
Ceci est en outre confirmé par le nombre moyen de résultats, GiST étant exactement le même que pour GIN (avec une augmentation de 9,1).
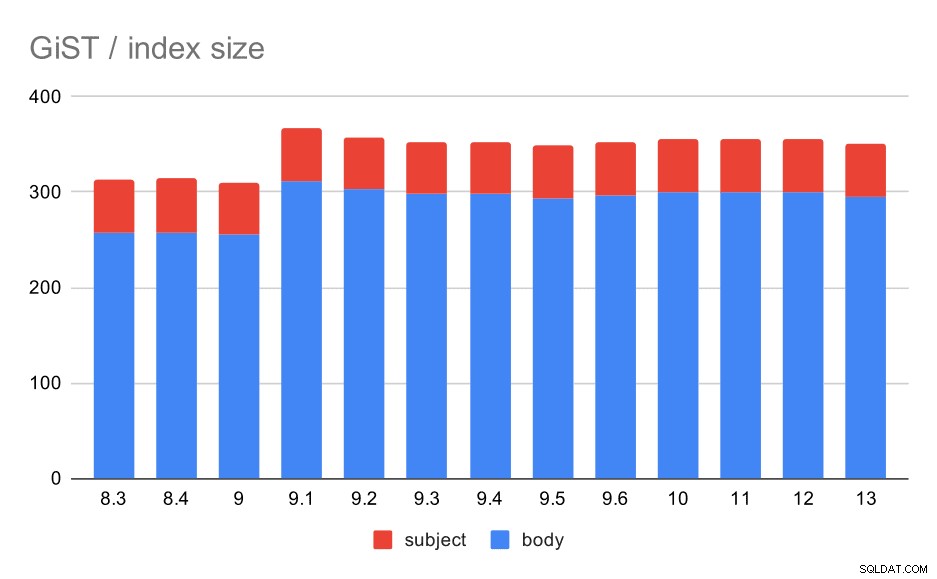
Taille des index GiST sur le sujet/corps du message. Les valeurs sont en mégaoctets.
| BODY | OBJET | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
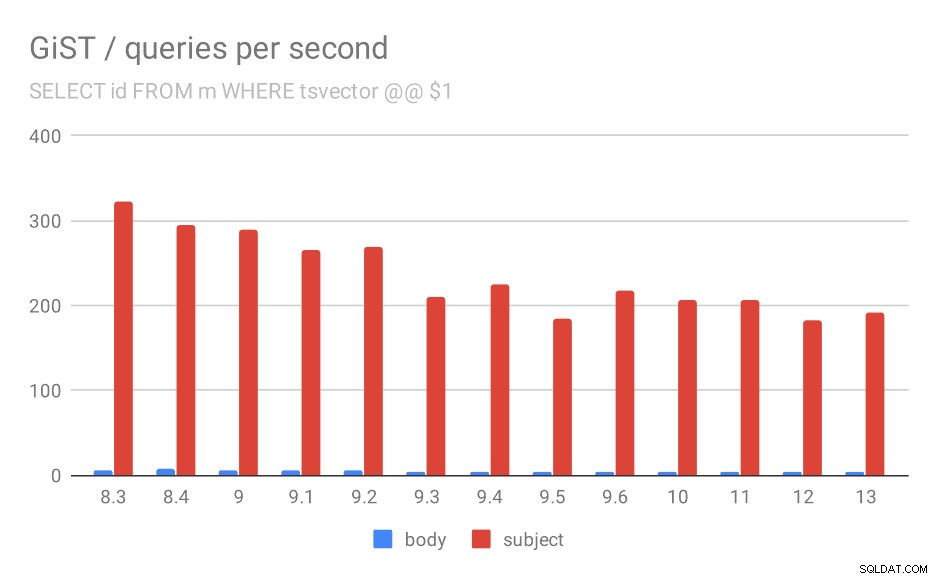
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
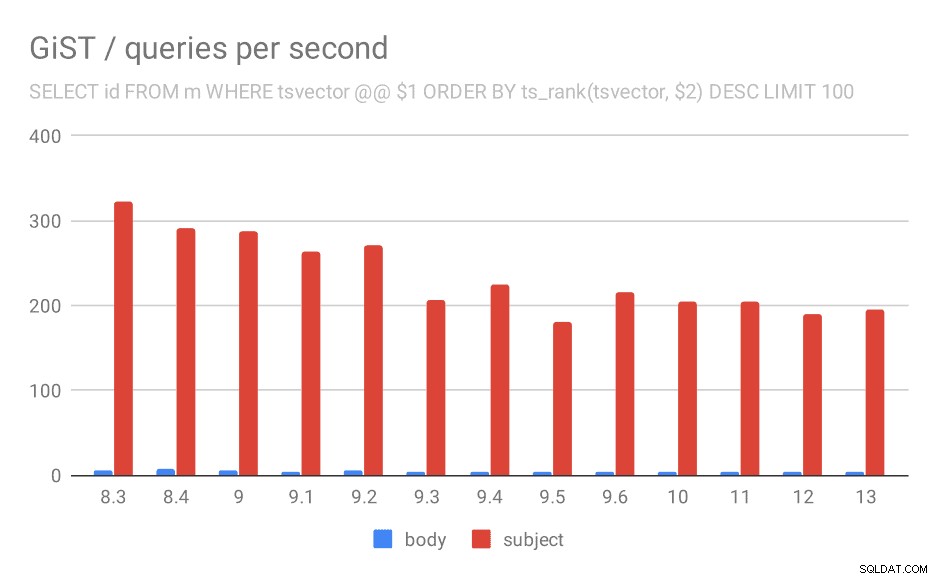
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).