PostgreSQL est l'une des bases de données pouvant être déployées via ClusterControl, avec MySQL, MariaDB et MongoDB. ClusterControl simplifie non seulement le déploiement du cluster de bases de données, mais dispose également d'une fonction d'évolutivité au cas où votre application se développerait et nécessiterait cette fonctionnalité.
En augmentant la taille de votre base de données, votre application fonctionnera beaucoup plus facilement et mieux en cas d'augmentation de la charge de l'application ou du trafic. Dans cet article de blog, nous passerons en revue les étapes de déploiement et de mise à l'échelle de PostgreSQL v13 avec ClusterControl 1.8.2.
Déploiement de l'interface utilisateur (UI)
Il existe deux méthodes de déploiement dans ClusterControl, l'interface utilisateur Web (UI) ainsi que l'interface de ligne de commande (CLI). L'utilisateur a la liberté de choisir l'une des options de déploiement en fonction de ses goûts et de ses besoins. Les deux options sont faciles à suivre et bien documentées dans notre documentation. Dans cette section, nous allons parcourir le processus de déploiement en utilisant la première option - l'interface utilisateur Web.
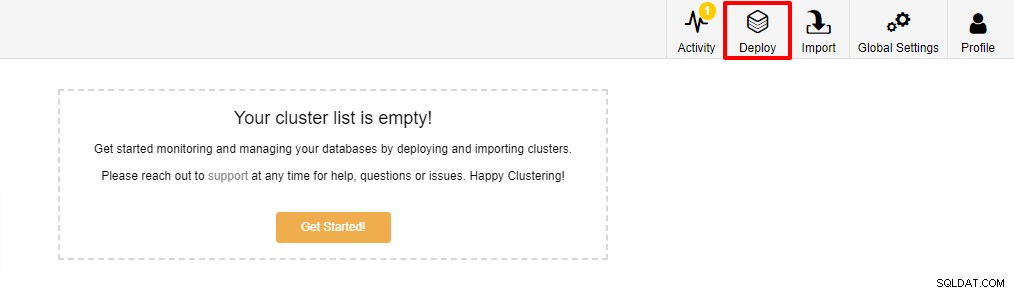
La première étape consiste à vous connecter à votre ClusterControl et à cliquer sur Déployer :
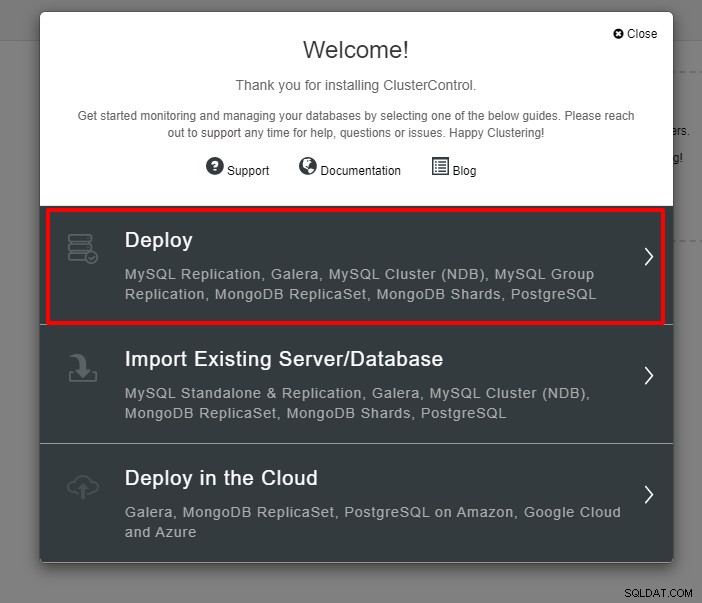
La capture d'écran ci-dessous vous sera présentée pour la prochaine étape du déploiement , choisissez l'onglet PostgreSQL pour continuer :
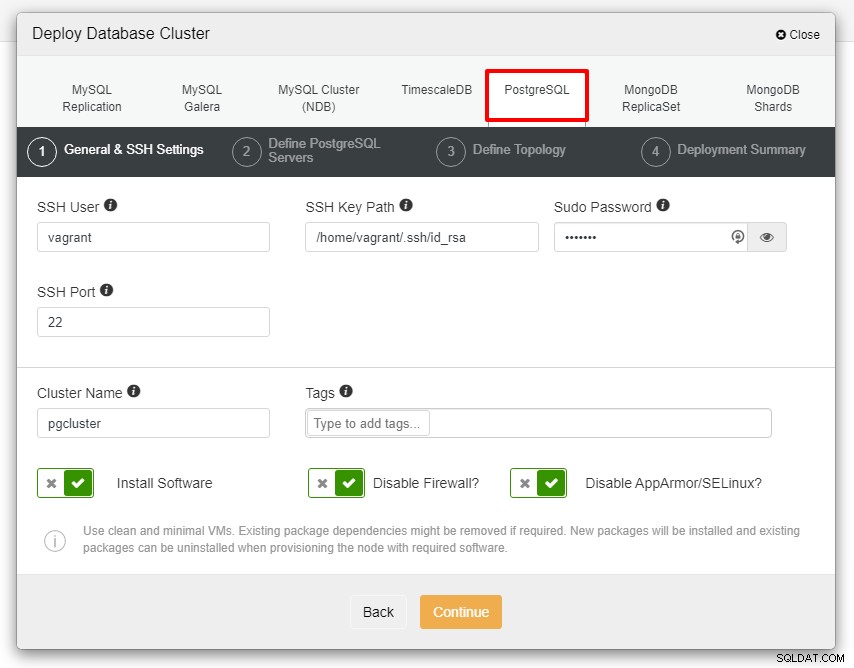
Avant d'aller plus loin, je voudrais vous rappeler que le lien entre le nœud ClusterControl et les nœuds de bases de données doivent être sans mot de passe. Avant le déploiement, tout ce que nous avons à faire est de générer le ssh-keygen à partir du nœud ClusterControl, puis de le copier sur tous les nœuds. Remplissez l'entrée pour l'utilisateur SSH, le mot de passe Sudo ainsi que le nom du cluster selon vos besoins et cliquez sur Continuer.
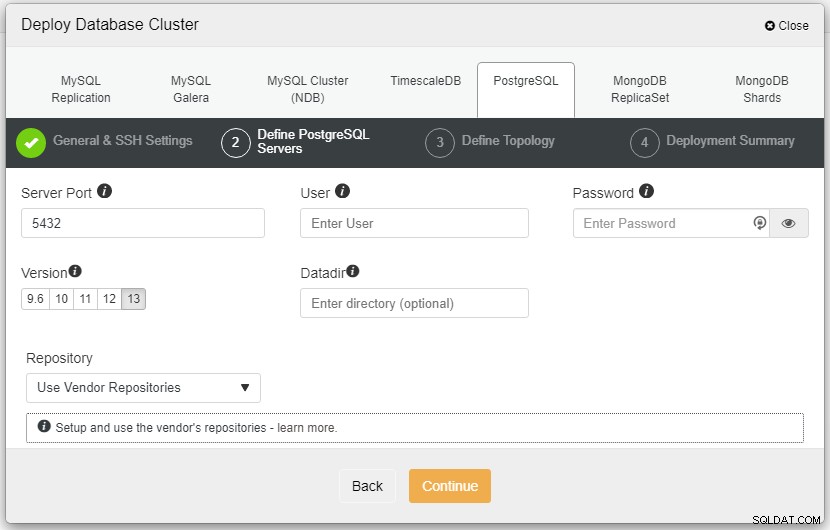
Dans la capture d'écran ci-dessus, vous devrez définir le port du serveur (en si vous souhaitez en utiliser d'autres), l'utilisateur que vous souhaitez ainsi que le mot de passe et assurez-vous de choisir la version 13 que vous souhaitez installer.
 Auteur de la photoDescription de la photo
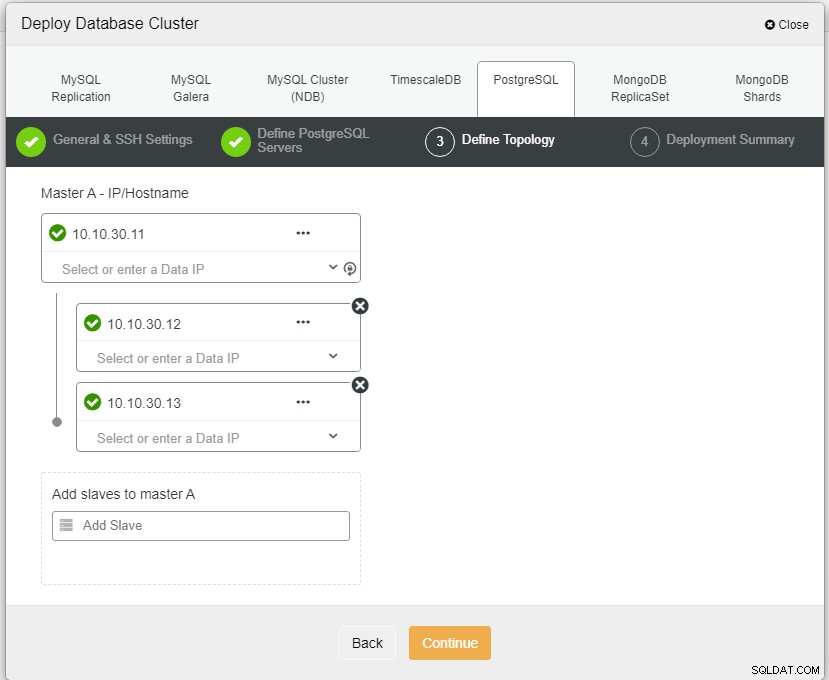
Auteur de la photoDescription de la photoIci, nous devons définir les serveurs soit en utilisant le nom d'hôte ou l'adresse IP, comme dans ce cas 1 maître et 2 esclaves. La dernière étape consiste à choisir le mode de réplication pour notre cluster.
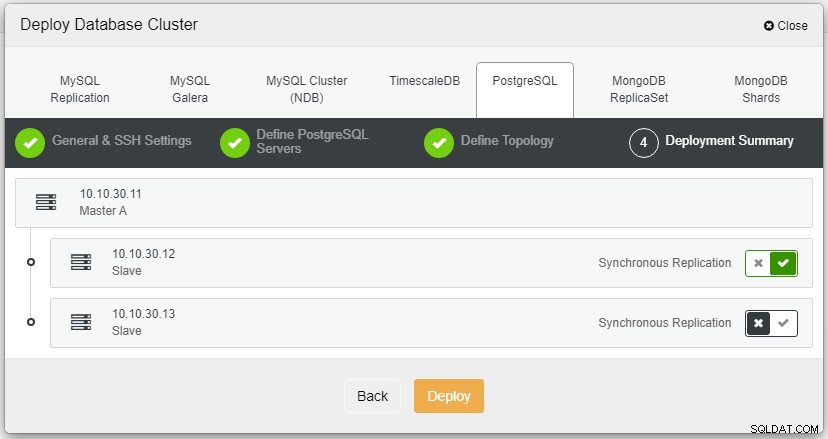
Après avoir cliqué sur Déployer, le processus de déploiement démarre et nous pouvons surveiller le progression dans l'onglet Activité.
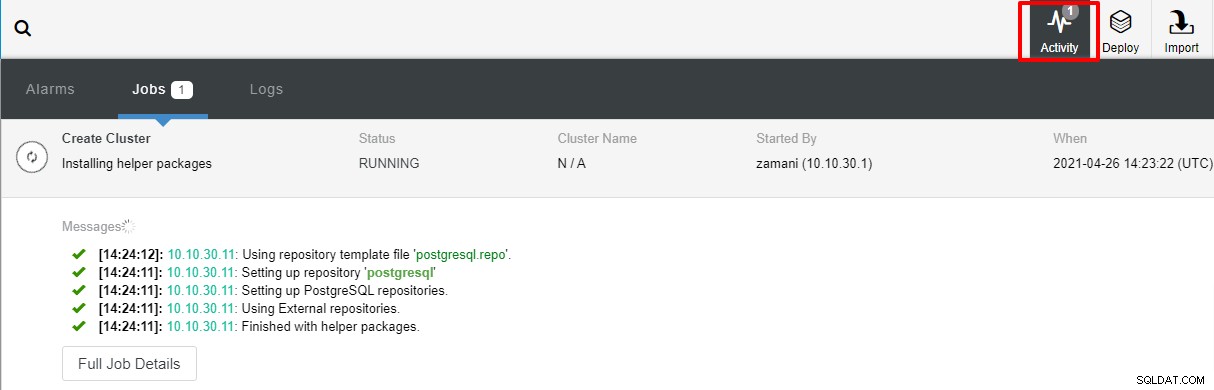
Le déploiement prend normalement quelques minutes, les performances dépendent principalement du réseau et les spécifications du serveur.

Maintenant que nous avons PostgreSQL v13 installé à l'aide de l'interface graphique ClusterControl, ce qui est assez simple .
Déploiement PostgreSQL de l'interface de ligne de commande (CLI)
D'après ce qui précède, nous pouvons voir que le déploiement est assez simple à l'aide de l'interface utilisateur Web. La remarque importante est que tous les nœuds doivent avoir des connexions SSH sans mot de passe avant le déploiement. Dans cette section, nous allons voir comment déployer à l'aide de la CLI ClusterControl ou de la ligne de commande des outils "s9s".
Nous avons supposé que ClusterControl avait été installé avant cela, commençons par générer le ssh-keygen. Dans le nœud ClusterControl, exécutez les commandes suivantes :
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Une fois toutes les commandes ci-dessus exécutées avec succès, nous pouvons vérifier la connexion sans mot de passe en utilisant la commande suivante :
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordSi la commande ci-dessus s'exécute avec succès, le déploiement du cluster peut être lancé à partir du serveur ClusterControl à l'aide de la ligne de commande suivante :
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logJuste après avoir exécuté la commande ci-dessus, vous verrez quelque chose comme ceci, ce qui signifie que la tâche a commencé à s'exécuter :
Le cluster sera créé sur 3 nœud(s) de données.
Vérification des paramètres de la tâche.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Vous pouvez également le vérifier en vous connectant à la console Web, en utilisant le nom d'utilisateur que vous avez créé. Nous avons maintenant un cluster PostgreSQL déployé à l'aide de 3 nœuds. Si vous souhaitez en savoir plus sur la commande de déploiement ci-dessus, voici la meilleure référence pour vous.
Mettre à l'échelle PostgreSQL avec l'interface utilisateur ClusterControl
PostgreSQL est une base de données relationnelle et nous savons que la mise à l'échelle de ce type de base de données n'est pas facile par rapport à une base de données non relationnelle. De nos jours, la plupart des applications ont besoin d'évolutivité pour offrir de meilleures performances et une meilleure vitesse. Il existe de nombreuses façons de mettre cela en œuvre en fonction de votre infrastructure et de votre environnement.
L'évolutivité est l'une des fonctionnalités qui peuvent être facilitées par ClusterControl et peuvent être réalisées à la fois à l'aide de l'interface utilisateur et de la CLI. Dans cette section, nous allons voir comment nous pouvons faire évoluer PostgreSQL à l'aide de l'interface utilisateur de ClusterControl. La première étape consiste à vous connecter à votre interface utilisateur et à choisir le cluster. Une fois le cluster choisi, vous pouvez cliquer sur l'option selon la capture d'écran ci-dessous :
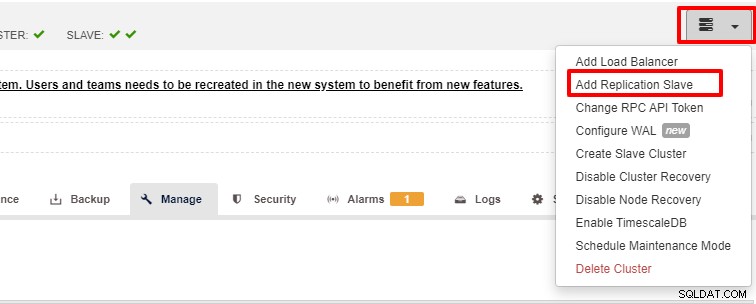
Une fois le bouton "Ajouter un esclave de réplication" cliqué, vous verrez la page suivante . Vous pouvez choisir « Ajouter un nouveau… » ou « Importer… » selon votre situation. Dans cet exemple, nous choisirons la première option :
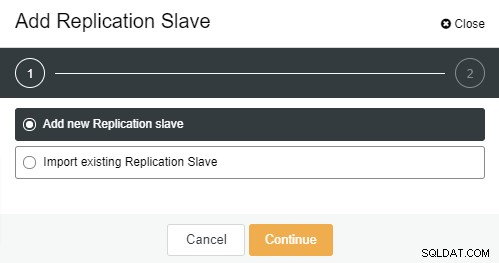
L'écran suivant s'affichera une fois que vous aurez cliqué dessus :
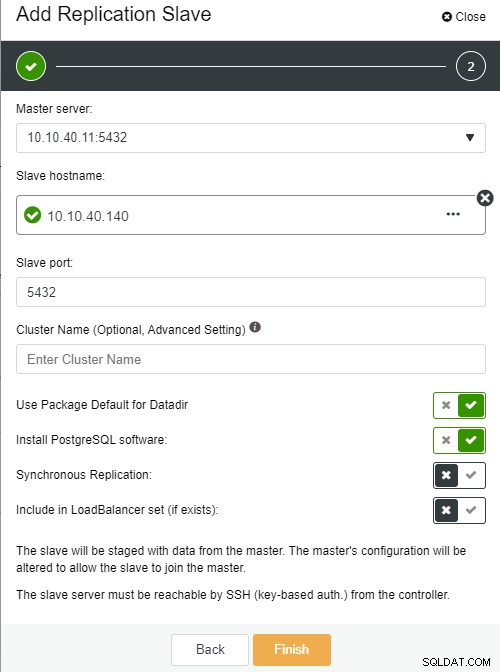 Auteur de la photoDescription de la photo
Auteur de la photoDescription de la photo-
Nom d'hôte esclave :le nom d'hôte/l'adresse IP du nouvel esclave ou nœud
-
Port esclave :le port PostgreSQL de l'esclave, la valeur par défaut est 5432
-
Nom du cluster :le nom du cluster, vous pouvez soit l'ajouter, soit le laisser vide
-
Utiliser le package par défaut pour Datadir :vous pouvez cocher cette option si vous souhaitez avoir un emplacement différent pour Datadir
-
Installer le logiciel PostgreSQL :vous pouvez laisser cette option cochée
-
Réplication synchrone :vous pouvez choisir le type de réplication que vous souhaitez dans celui-ci
-
Inclure dans l'ensemble LoadBalancer (si existant) :cette option à cocher si vous avez configuré LoadBalancer pour le cluster
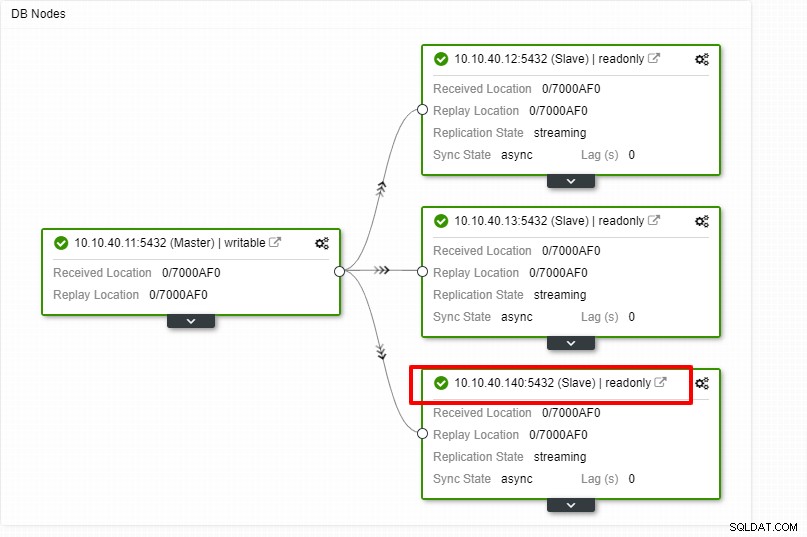
La remarque importante ici est que vous devez configurer le nouvel hôte esclave sans mot de passe avant de pouvoir exécuter cette configuration. Une fois que tout est confirmé, nous pouvons cliquer sur le bouton "Terminer" pour terminer la configuration. Dans cet exemple, j'ai ajouté l'IP "10.10.40.140".
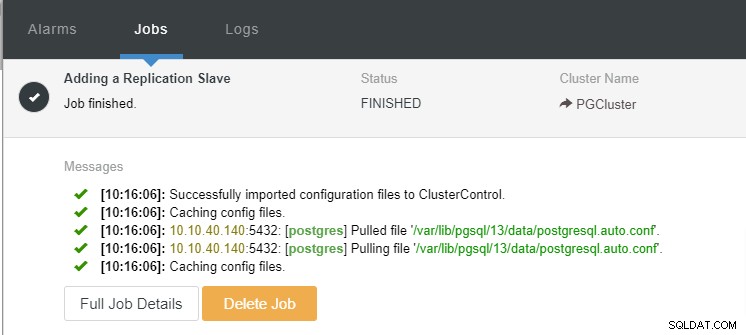
Nous pouvons maintenant surveiller l'activité du travail et laisser la configuration se terminer. Pour confirmer la configuration, nous pouvons aller dans l'onglet "Topologie" pour voir le nouvel esclave :
Scaler PostgreSQL avec ClusterControl CLI
Ajouter les nouveaux nœuds dans le cluster existant est très simple à l'aide de la CLI. À partir du nœud de contrôleur, vous exécutez la commande suivante. La première commande consiste à identifier le cluster auquel nous souhaitons ajouter le nouveau nœud :
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.Dans cet exemple, nous pouvons voir que l'ID de nœud est "1" pour le nom de cluster "PGCluster". Voyons la première option de commande sur la façon d'ajouter un nouveau nœud au cluster PostgreSQL existant :
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logLe raccourci "--log" à la fin de la ligne nous permettra de voir quelle est la tâche en cours d'exécution après la commande exécutée comme ci-dessous :
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…La prochaine commande disponible que vous pouvez utiliser est la suivante :
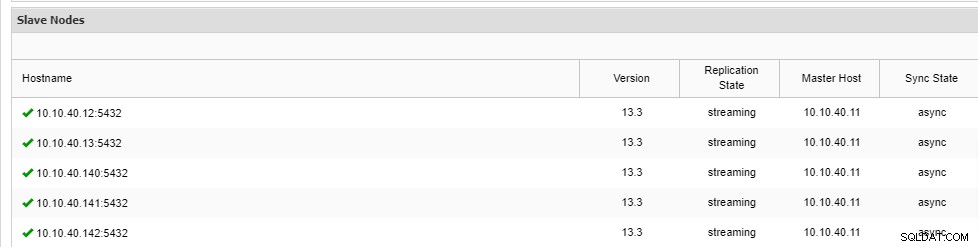
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitAjouter un nœud au cluster
\ Job 9 RUNNING [▋ ] 5% Installing packagesNotez qu'il y a un raccourci "--wait" dans la ligne et la sortie que vous verrez sera affichée comme ci-dessus. Une fois le processus terminé, nous pouvons confirmer les nouveaux nœuds dans l'onglet "Aperçu" du cluster depuis l'interface utilisateur :
Conclusion
Dans cet article de blog, nous avons passé en revue deux options de mise à l'échelle de PostgreSQL dans ClusterControl. Comme vous pouvez le constater, la mise à l'échelle de PostgreSQL est facile avec ClusterControl. ClusterControl peut non seulement assurer l'évolutivité, mais vous pouvez également obtenir une configuration haute disponibilité pour votre cluster de base de données. Des fonctionnalités telles que HAProxy, PgBouncer ainsi que Keepalived sont disponibles et prêtes à être implémentées pour votre cluster chaque fois que vous en ressentez le besoin. Avec ClusterControl, votre cluster de bases de données est facile à gérer et surveillé en même temps.
Nous espérons que cet article de blog vous aidera à faire évoluer votre configuration PostgreSQL.