La performance est toujours importante dans n'importe quel système. Vous devrez faire bon usage des ressources disponibles pour assurer le meilleur temps de réponse possible et il existe différentes façons de le faire. Chaque connexion à une base de données consomme des ressources. L'un de ces moyens consiste donc à disposer d'un bon gestionnaire de connexions entre votre application et la base de données. Dans ce blog, nous parlerons de pgBouncer, un pooleur de connexions pour PostgreSQL, et nous montrerons comment l'implémenter pour améliorer vos performances PostgreSQL.
Groupeurs de connexion
En fonction du trafic de vos systèmes, il peut être utile d'ajouter un outil externe pour réduire la charge sur votre base de données ce qui améliorera les performances. Ce n'est peut-être pas suffisant, mais c'est un bon point de départ. Pour cela, il est judicieux d'implémenter un pooler de connexion
Un regroupement de connexions est une méthode pour créer un pool de connexions et les réutiliser, en évitant d'ouvrir constamment de nouvelles connexions à la base de données, ce qui augmentera considérablement les performances de vos applications. PgBouncer est un pooleur de connexions populaire conçu pour PostgreSQL.
Comment fonctionne PgBouncer
PgBouncer agit comme un serveur PostgreSQL, il vous suffit donc d'accéder à votre base de données en utilisant les informations PgBouncer (adresse IP/nom d'hôte et port), et PgBouncer créera une connexion au serveur PostgreSQL, ou il réutilisez-en un s'il existe.
Lorsque PgBouncer reçoit une connexion, il effectue l'authentification, qui dépend de la méthode spécifiée dans le fichier de configuration. PgBouncer prend en charge tous les mécanismes d'authentification pris en charge par le serveur PostgreSQL. Après cela, PgBouncer recherche une connexion en cache, avec la même combinaison nom d'utilisateur + base de données. Si une connexion en cache est trouvée, il renvoie la connexion au client, sinon, il crée une nouvelle connexion. En fonction de la configuration de PgBouncer et du nombre de connexions actives, il est possible que la nouvelle connexion soit mise en file d'attente jusqu'à ce qu'elle puisse être créée, voire abandonnée.
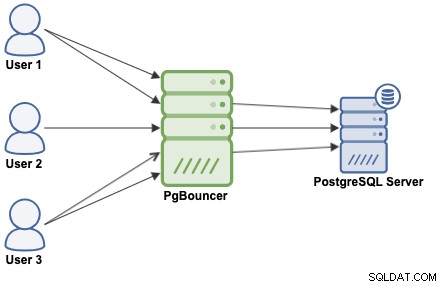
Le comportement de PgBouncer dépend du mode de regroupement configuré :
-
session pooling (par défaut) :Lorsqu'un client se connecte, une connexion serveur lui sera attribuée pour l'ensemble durée pendant laquelle le client reste connecté. Lorsque le client se déconnecte, la connexion au serveur est remise dans le pool.
-
transaction pooling :une connexion serveur est attribuée à un client uniquement lors d'une transaction. Lorsque PgBouncer remarque que la transaction est terminée, la connexion au serveur sera remise dans le pool.
-
regroupement d'instructions :la connexion au serveur sera remise dans le pool immédiatement après la fin d'une requête. Les transactions multi-relevés ne sont pas autorisées dans ce mode car elles casseraient.
Comment implémenter PgBouncer à l'aide de ClusterControl
Pour cela, nous supposerons que votre cluster PostgreSQL est opérationnel et que vous utilisez ClusterControl pour le gérer, sinon, vous pouvez suivre ce billet de blog pour déployer facilement PostgreSQL pour la haute disponibilité.
Allez dans ClusterControl -> Sélectionnez PostgreSQL Cluster -> Actions de cluster -> Ajouter un équilibreur de charge -> PgBouncer. Là, vous pouvez déployer un nouveau nœud PgBouncer qui sera déployé dans le nœud de base de données sélectionné, ou même importer un nœud PgBouncer existant.
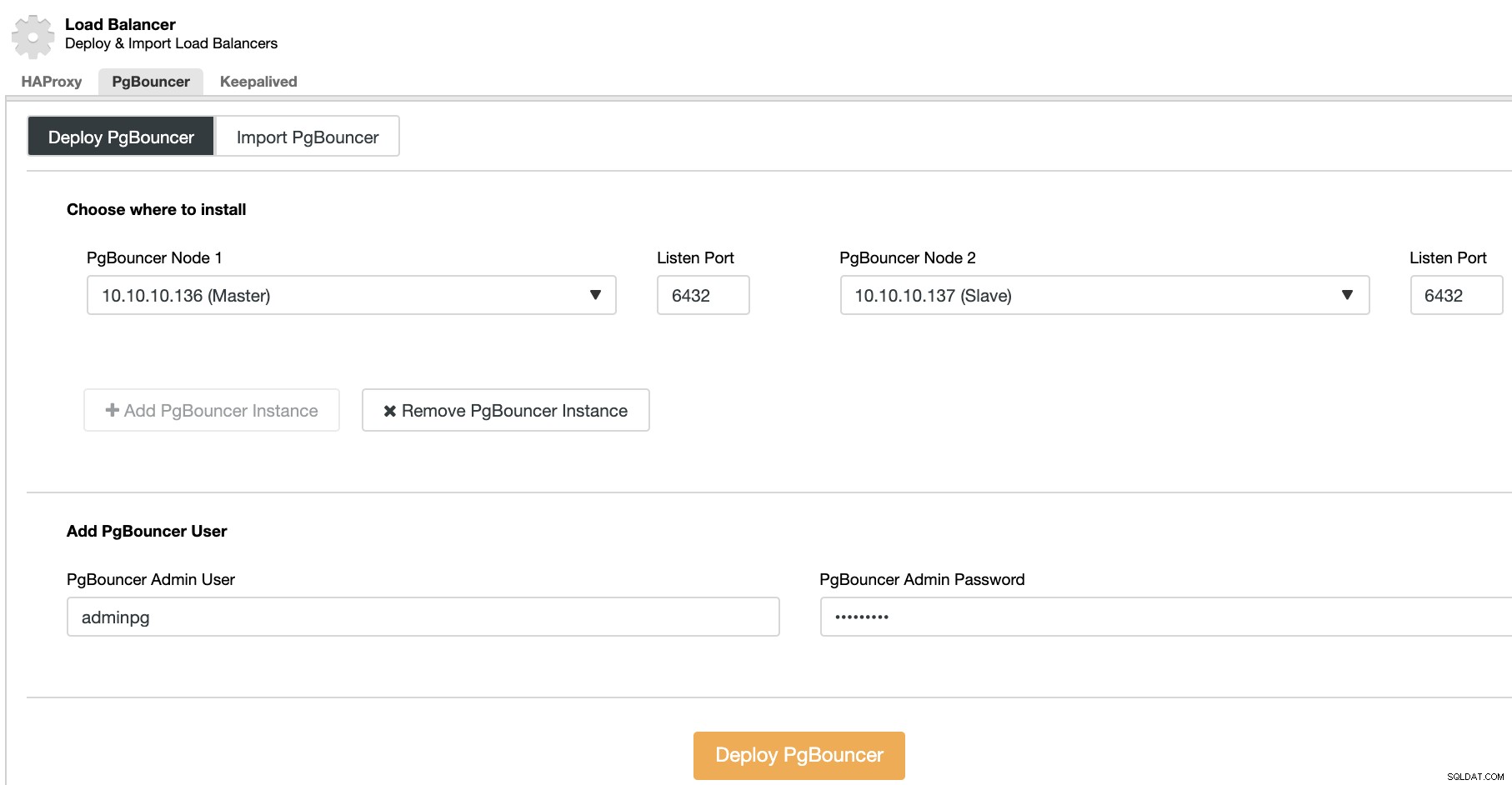
Vous devrez spécifier l'adresse IP ou le nom d'hôte, le port d'écoute et le PgBouncer crédits. Lorsque vous appuyez sur Deploy PgBouncer, ClusterControl accède au nœud, installe et configure tout sans aucune intervention manuelle.
Vous pouvez surveiller la progression dans la section d'activité ClusterControl. Une fois terminé, vous devez créer le nouveau pool. Pour cela, allez dans ClusterControl -> Sélectionnez le cluster PostgreSQL -> Nœuds -> Nœud PgBouncer.
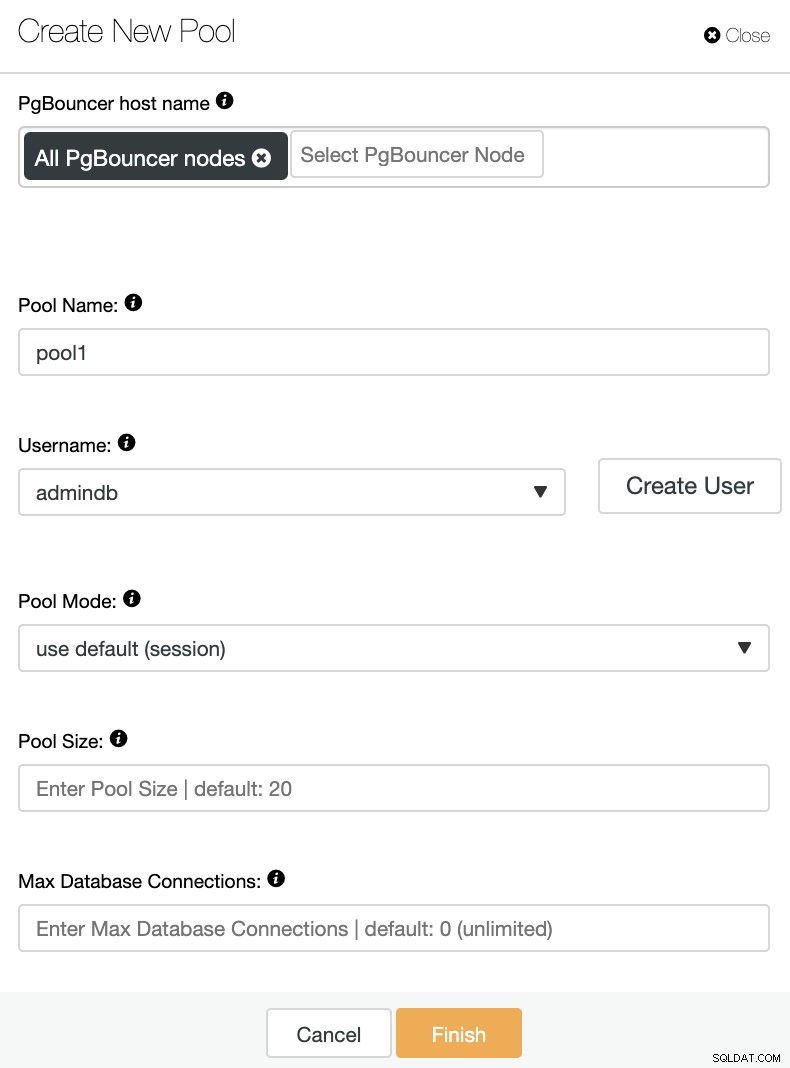
Ici, vous devrez ajouter les informations suivantes :
-
Nom d'hôte PgBouncer :sélectionnez les hôtes de nœud pour créer le pool de connexion.
-
Nom du pool :les noms du pool et de la base de données doivent être identiques.
-
Nom d'utilisateur : Sélectionnez un utilisateur dans le nœud principal PostgreSQL ou créez-en un nouveau.
-
Mode pool :il peut s'agir de l'un des modes que nous avons mentionnés précédemment :session (par défaut), transaction, ou la mise en commun des déclarations.
-
Taille du pool :taille maximale des pools pour cette base de données. La valeur par défaut est 20.
-
Nombre maximal de connexions à la base de données :configurez un maximum à l'échelle de la base de données. La valeur par défaut est 0, ce qui signifie illimité.
Maintenant, vous devriez pouvoir voir le Pool dans la section Node.
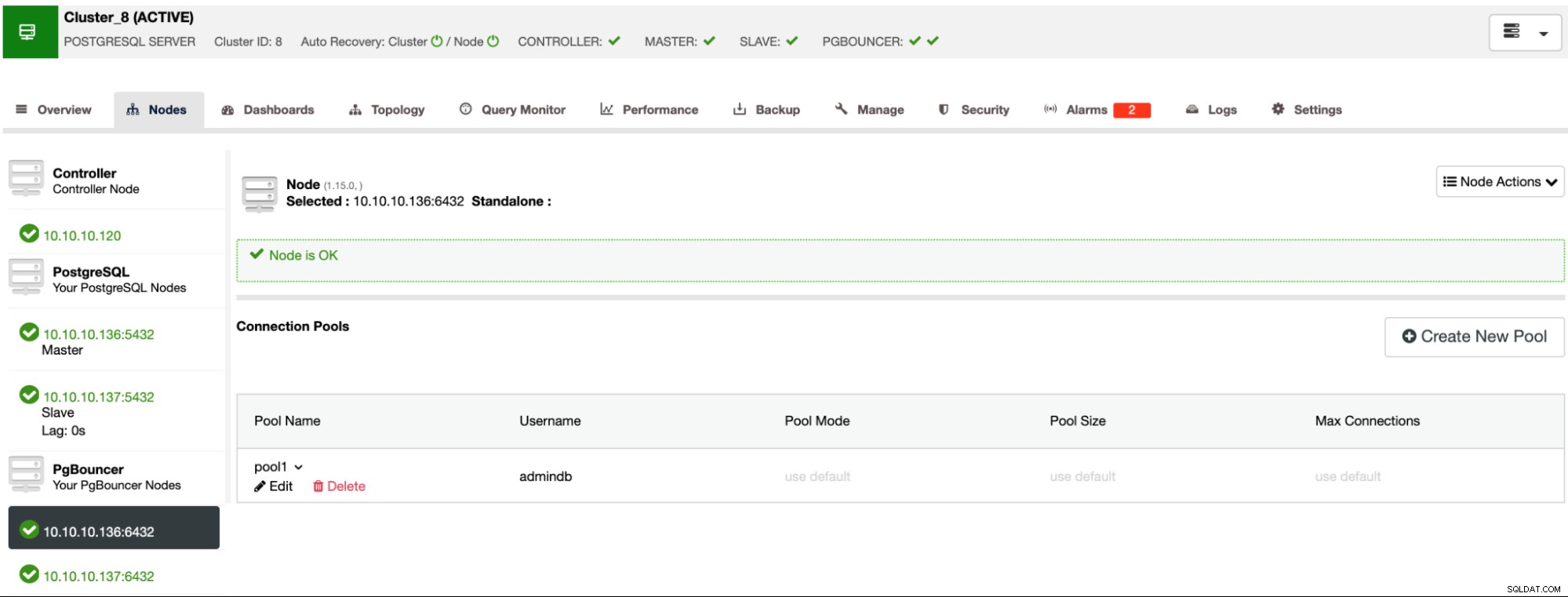
Il s'agit d'une topologie de base. Vous pouvez l'améliorer, par exemple, en ajoutant des nœuds d'équilibrage de charge, plus d'un pour éviter un seul point de défaillance, et en utilisant un outil comme "Keepalived", pour assurer la disponibilité. Cela peut également être fait en utilisant ClusterControl.
Conclusion
L'utilisation de PgBouncer comme pooleur de connexions est un bon moyen d'améliorer les performances de la base de données en faisant bon usage des ressources disponibles sur le serveur.
Vous pouvez également améliorer cette topologie en utilisant une combinaison de PgBouncer + HAProxy pour obtenir une haute disponibilité pour votre cluster PostgreSQL. Toutes ces choses peuvent être faites à partir de la même interface utilisateur ClusterControl.