Dans le monde des technologies de l'information, l'automatisation n'est pas une nouveauté pour la plupart d'entre nous. En fait, la plupart des organisations l'utilisent à diverses fins en fonction de leur type de travail et de leurs objectifs. Par exemple, les analystes de données utilisent l'automatisation pour générer des rapports, les administrateurs système utilisent l'automatisation pour leurs tâches répétitives comme le nettoyage de l'espace disque, et les développeurs utilisent l'automatisation pour automatiser leur processus de développement.
De nos jours, de nombreux outils d'automatisation pour l'informatique sont disponibles et peuvent être choisis, grâce à l'ère DevOps. Quel est le meilleur outil ? La réponse est un "ça dépend" prévisible, car cela dépend de ce que nous essayons de réaliser ainsi que de la configuration de notre environnement. Certains des outils d'automatisation sont Terraform, Bolt, Chef, SaltStack et un très à la mode est Ansible. Ansible est un moteur informatique open source sans agent capable d'automatiser le déploiement d'applications, la gestion de la configuration et l'orchestration informatique. Ansible a été fondé en 2012 et a été écrit dans le langage le plus populaire, Python. Il utilise un playbook pour implémenter toute l'automatisation, où toutes les configurations sont écrites dans un langage lisible par l'homme, YAML.
Dans l'article d'aujourd'hui, nous allons apprendre à utiliser Ansible pour déployer une base de données Postgresql.
Qu'est-ce qui rend Ansible spécial ?
La raison pour laquelle ansible est utilisé principalement en raison de ses fonctionnalités. Ces fonctionnalités sont :
-
Tout peut être automatisé en utilisant un langage YAML simple et lisible par l'homme
-
Aucun agent ne sera installé sur la machine distante (architecture sans agent)
-
La configuration sera poussée de votre machine locale vers le serveur depuis votre machine locale (modèle push)
-
Développé en Python (l'un des langages populaires actuellement utilisés) et de nombreuses bibliothèques peuvent être choisies parmi
-
Collection de modules Ansible soigneusement sélectionnés par l'équipe d'ingénierie de Red Had
Le fonctionnement d'Ansible
Avant qu'Ansible puisse exécuter des tâches opérationnelles sur les hôtes distants, nous devons l'installer sur un hôte qui deviendra le nœud de contrôleur. Dans ce nœud de contrôleur, nous orchestrerons toutes les tâches que nous aimerions effectuer dans les hôtes distants également appelés nœuds gérés.
Le nœud contrôleur doit disposer de l'inventaire des nœuds gérés et du logiciel Ansible pour le gérer. Les données requises à utiliser par Ansible, comme le nom d'hôte ou l'adresse IP du nœud géré, seront placées dans cet inventaire. Sans un inventaire approprié, Ansible ne pouvait pas effectuer l'automatisation correctement. Cliquez ici pour en savoir plus sur l'inventaire.
Ansible est sans agent et utilise SSH pour pousser les modifications, ce qui signifie que nous n'avons pas besoin d'installer Ansible dans tous les nœuds, mais tous les nœuds gérés doivent avoir python et toutes les bibliothèques python nécessaires installées. Le nœud de contrôleur et les nœuds gérés doivent être définis comme sans mot de passe. Il convient de mentionner que la connexion entre tous les nœuds de contrôleur et les nœuds gérés est bonne et testée correctement.
Pour cette démo, j'ai provisionné 4 machines virtuelles Centos 8 en utilisant vagrant. L'un agira en tant que nœud de contrôleur et les 2 autres VM agiront en tant que nœuds de base de données à déployer. Nous n'entrerons pas dans les détails sur l'installation d'Ansible dans cet article de blog, mais si vous souhaitez voir le guide, n'hésitez pas à visiter ce lien. Notez que nous utilisons 3 nœuds pour configurer une topologie de réplication en continu, avec un nœud principal et 2 nœuds de secours. De nos jours, de nombreuses bases de données de production sont dans une configuration à haute disponibilité et une configuration à 3 nœuds est courante.
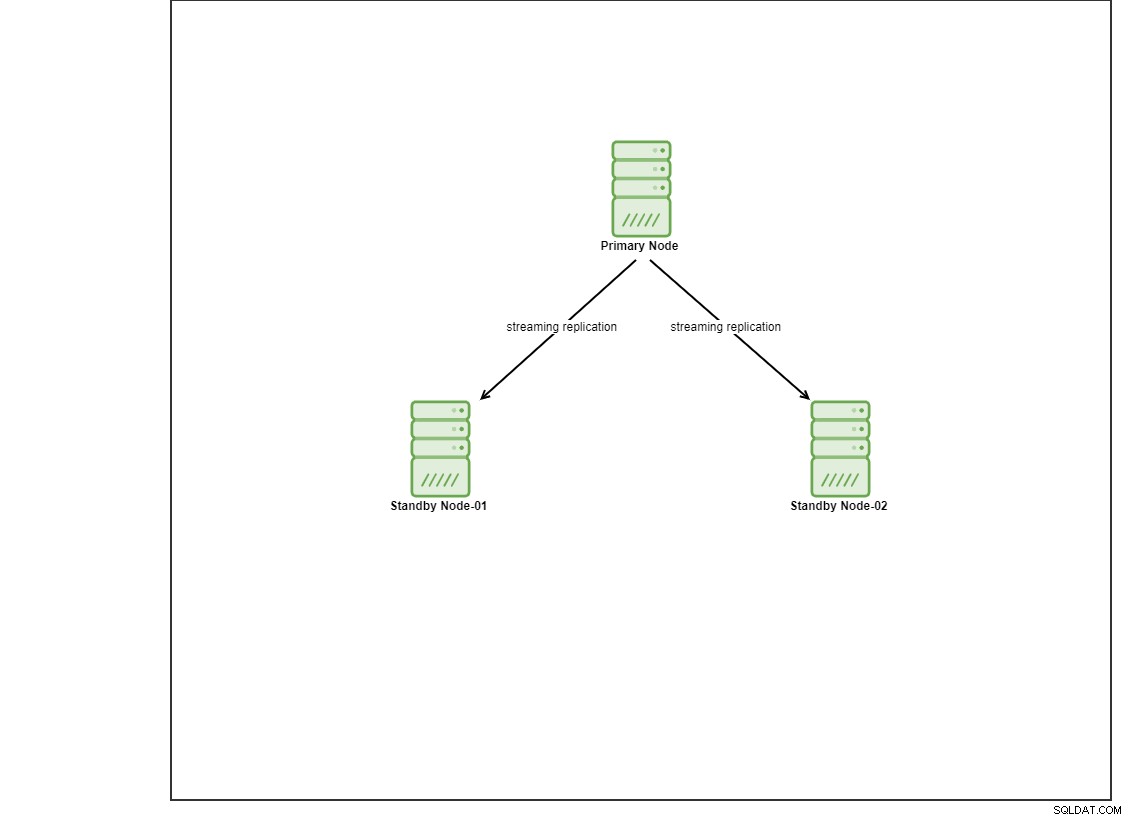
Installer PostgreSQL
Il existe plusieurs façons d'installer PostgreSQL en utilisant Ansible. Aujourd'hui, j'utiliserai Ansible Roles pour atteindre cet objectif. Les rôles ansibles en bref sont un ensemble de tâches permettant de configurer un hôte pour qu'il remplisse un certain objectif, comme la configuration d'un service. Les rôles Ansible sont définis à l'aide de fichiers YAML avec une structure de répertoire prédéfinie disponible en téléchargement sur le portail Ansible Galaxy.
Ansible Galaxy, d'autre part, est un référentiel pour les rôles Ansible qui peuvent être déposés directement dans vos Playbooks pour rationaliser vos projets d'automatisation.
Pour cette démo, j'ai choisi les rôles qui ont été maintenus par dudefellah. Pour que nous puissions utiliser ce rôle, nous devons le télécharger et l'installer sur le nœud du contrôleur. La tâche est assez simple et peut être effectuée en exécutant la commande suivante à condition qu'Ansible ait été installé sur votre nœud de contrôleur :
$ ansible-galaxy install dudefellah.postgresqlVous devriez voir le résultat suivant une fois le rôle installé avec succès dans votre nœud de contrôleur :
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Pour que nous puissions installer PostgreSQL en utilisant ce rôle, il y a quelques étapes à suivre. Voici le Playbook Ansible. Ansible Playbook est l'endroit où nous pouvons écrire du code Ansible ou une collection de scripts que nous aimerions exécuter sur les nœuds gérés. Ansible Playbook utilise YAML et consiste en une ou plusieurs lectures exécutées dans un ordre particulier. Vous pouvez définir des hôtes ainsi qu'un ensemble de tâches que vous souhaitez exécuter sur les hôtes affectés ou les nœuds gérés.
Toutes les tâches seront exécutées en tant qu'utilisateur ansible qui s'est connecté. Pour que nous puissions exécuter les tâches avec un autre utilisateur, y compris "root", nous pouvons utiliser devenu. Jetons un coup d'œil à pg-play.yml ci-dessous :
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Comme vous pouvez le voir, j'ai défini les hôtes comme pgcluster et j'utilise devenu pour qu'Ansible exécute les tâches avec le privilège sudo. L'utilisateur vagrant est déjà dans le groupe sudoer. J'ai également défini le rôle que j'ai installé dudefellah.postgresql. pgcluster a été défini dans le fichier hosts que j'ai créé. Au cas où vous vous demanderiez à quoi cela ressemble, vous pouvez jeter un œil ci-dessous :
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleEn plus de cela, j'ai créé un autre fichier personnalisé (custom_var.yml) dans lequel j'ai inclus toute la configuration et les paramètres pour PostgreSQL que je voudrais implémenter. Les détails du fichier personnalisé sont les suivants :
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Pour lancer l'installation, il suffit d'exécuter la commande suivante. Vous ne pourrez pas exécuter la commande ansible-playbook sans le fichier playbook créé (dans mon cas, c'est pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostAprès avoir exécuté cette commande, elle exécutera quelques tâches définies par le rôle et affichera ce message si la commande s'est exécutée avec succès :
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Une fois que l'ansible a terminé les tâches, je me suis connecté à l'esclave (n2), j'ai arrêté le service PostgreSQL, j'ai supprimé le contenu du répertoire de données (/var/lib/pgsql/13/data/) et exécutez la commande suivante pour lancer la tâche de sauvegarde :
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Nous pouvons également vérifier l'état de la réplication en veille à l'aide de la commande suivante après avoir redémarré le service PostgreSQL :
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyComme vous pouvez le voir, il y a beaucoup de travail à faire pour que nous puissions configurer la réplication pour PostgreSQL même si nous avons automatisé certaines tâches. Voyons comment cela peut être accompli avec ClusterControl.
Déploiement PostgreSQL à l'aide de l'interface graphique ClusterControl
Maintenant que nous savons comment déployer PostgreSQL en utilisant Ansible, voyons comment nous pouvons déployer en utilisant ClusterControl. ClusterControl est un logiciel de gestion et d'automatisation pour les clusters de bases de données, notamment MySQL, MariaDB, MongoDB ainsi que TimescaleDB. Il aide à déployer, surveiller, gérer et mettre à l'échelle votre cluster de bases de données. Il existe deux manières de déployer la base de données. Dans cet article de blog, nous vous montrerons comment la déployer à l'aide de l'interface utilisateur graphique (GUI) en supposant que ClusterControl est déjà installé sur votre environnement.
La première étape consiste à vous connecter à votre ClusterControl et à cliquer sur Déployer :
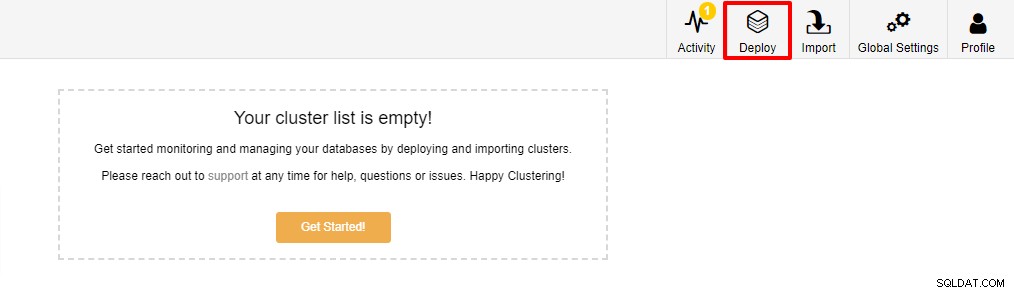
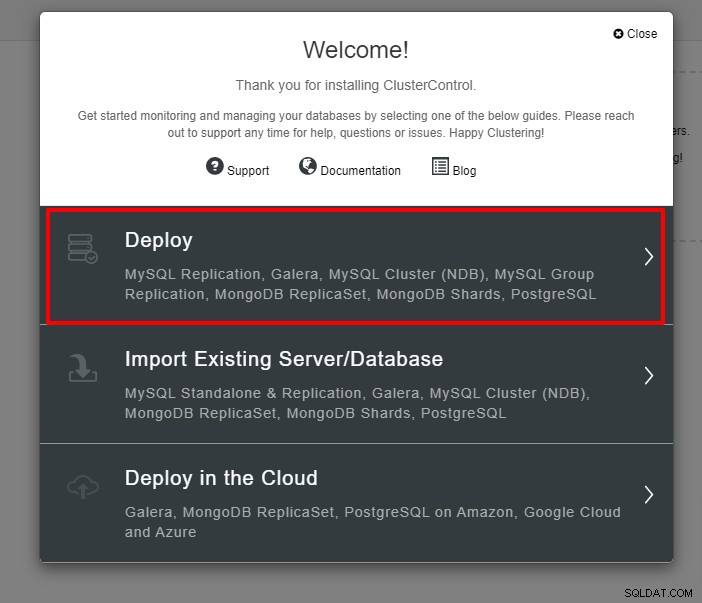
La capture d'écran ci-dessous vous sera présentée pour la prochaine étape du déploiement , choisissez l'onglet PostgreSQL pour continuer :
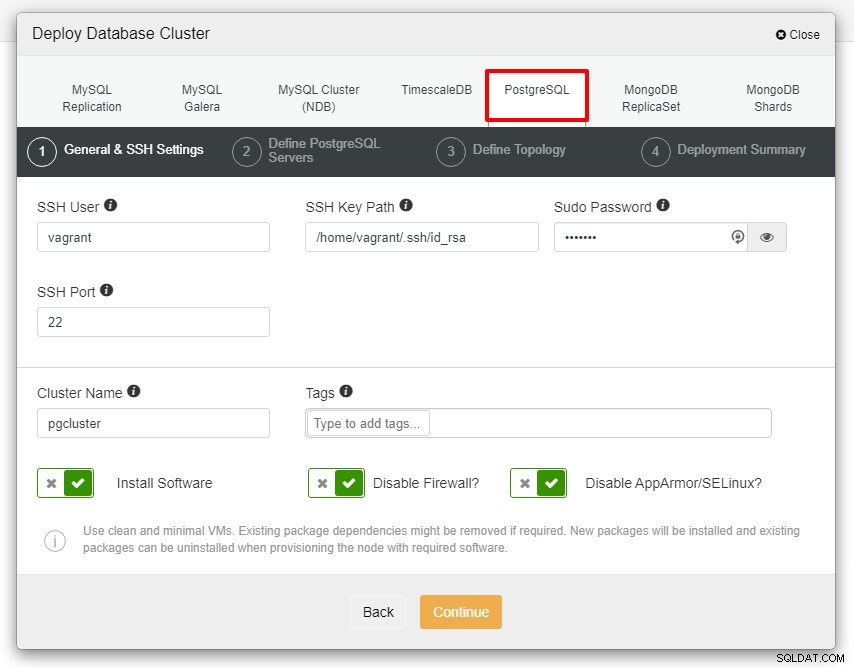
Avant d'aller plus loin, je voudrais vous rappeler que la connexion entre le nœud ClusterControl et les nœuds de bases de données doit être sans mot de passe. Avant le déploiement, tout ce que nous avons à faire est de générer le ssh-keygen à partir du nœud ClusterControl, puis de le copier sur tous les nœuds. Remplissez l'entrée pour l'utilisateur SSH, le mot de passe Sudo ainsi que le nom du cluster selon vos besoins et cliquez sur Continuer.
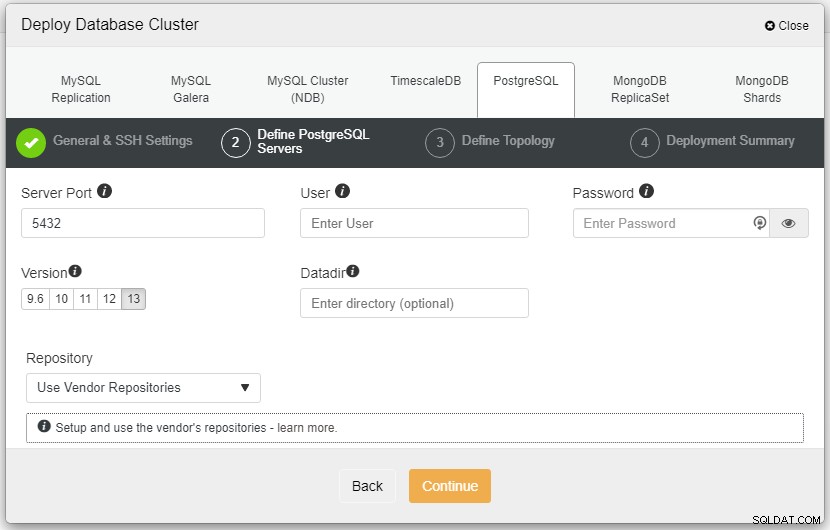
Dans la capture d'écran ci-dessus, vous devrez définir le Port du serveur (au cas où vous souhaiteriez en utiliser d'autres), l'utilisateur que vous souhaitez ainsi que le mot de passe et la Version que vous souhaitez à installer.
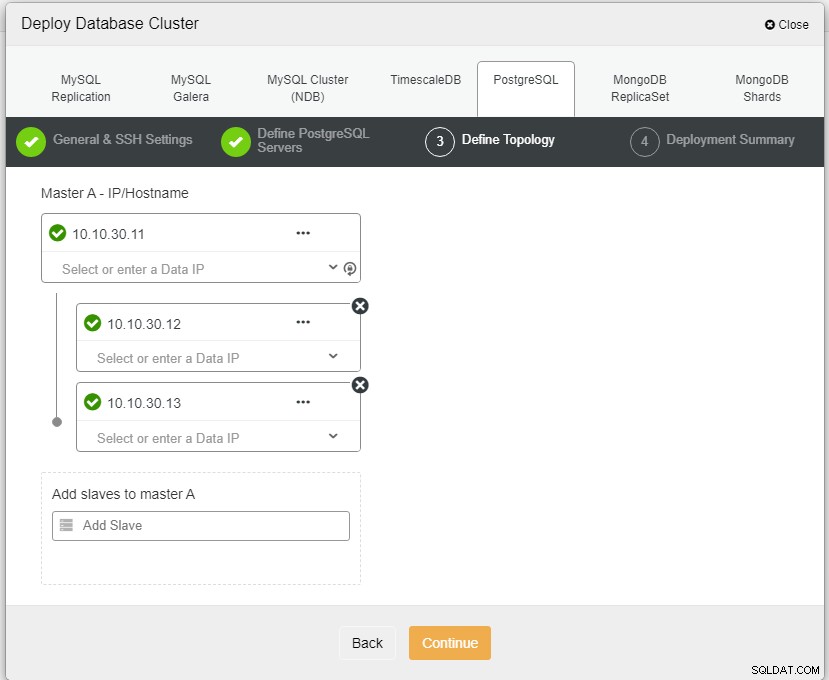
Ici, nous devons définir les serveurs en utilisant le nom d'hôte ou l'adresse IP, comme dans ce cas 1 maître et 2 esclaves. La dernière étape consiste à choisir le mode de réplication pour notre cluster.
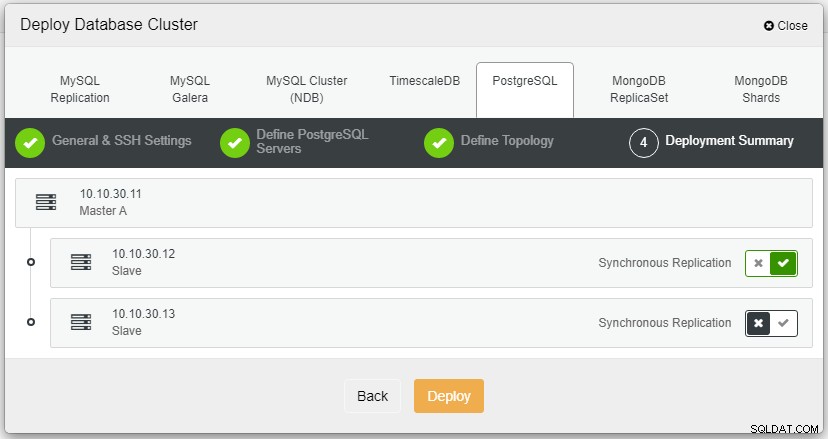
Après avoir cliqué sur Déployer, le processus de déploiement démarre et nous pouvons suivre la progression dans l'onglet Activité.
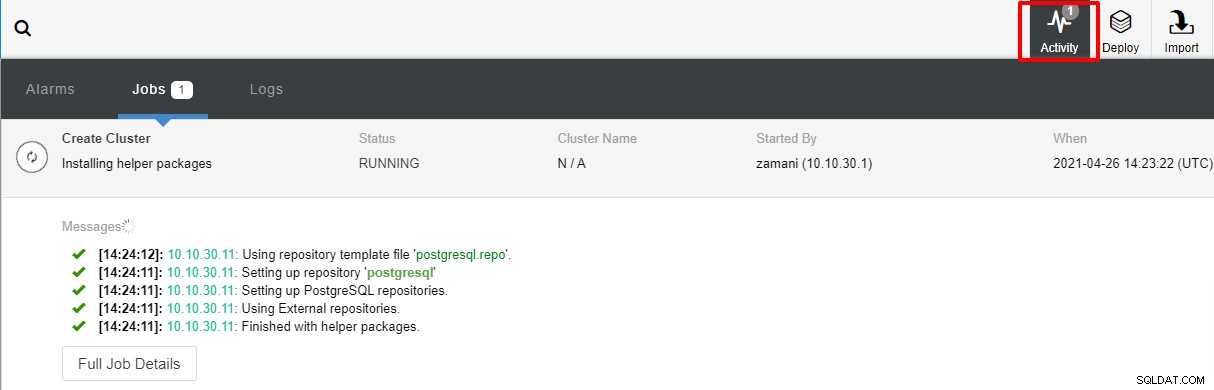
Le déploiement prend normalement quelques minutes, les performances dépendent principalement du réseau et des spécifications du serveur.

Maintenant que PostgreSQL est installé à l'aide de ClusterControl.
Déploiement PostgreSQL à l'aide de la CLI ClusterControl
L'autre manière alternative de déployer PostgreSQL est d'utiliser la CLI. à condition que nous ayons déjà configuré la connexion sans mot de passe, nous pouvons simplement exécuter la commande suivante et la laisser se terminer.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logVous devriez voir le message ci-dessous une fois le processus terminé avec succès et vous pouvez vous connecter au Web ClusterControl pour vérifier :
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Conclusion
Comme vous pouvez le voir, il existe plusieurs façons de déployer PostgreSQL. Dans cet article de blog, nous avons appris à le déployer en utilisant Ansible et en utilisant notre ClusterControl. Les deux méthodes sont faciles à suivre et peuvent être réalisées avec une courbe d'apprentissage minimale. Avec ClusterControl, la configuration de la réplication en continu peut être complétée par HAProxy, VIP et PGBouncer pour ajouter le basculement de connexion, l'adresse IP virtuelle et le regroupement de connexions à la configuration.
Notez que le déploiement n'est qu'un aspect d'un environnement de base de données de production. Le maintenir opérationnel, automatiser les basculements, récupérer les nœuds cassés et d'autres aspects tels que la surveillance, les alertes et les sauvegardes sont essentiels.
J'espère que ce billet de blog sera bénéfique pour certains d'entre vous et vous donnera une idée sur la façon d'automatiser les déploiements PostgreSQL.