La réplication joue un rôle crucial dans le maintien d'une haute disponibilité. Les serveurs peuvent échouer, le système d'exploitation ou le logiciel de base de données peut nécessiter une mise à niveau. Cela signifie remanier les rôles de serveur et déplacer les liens de réplication, tout en maintenant la cohérence des données dans toutes les bases de données. Des changements de topologie seront nécessaires et il existe différentes façons de les effectuer.
Promotion d'un serveur de secours
C'est sans doute l'opération la plus courante que vous devrez effectuer. Il existe plusieurs raisons - par exemple, la maintenance de la base de données sur le serveur principal qui aurait un impact inacceptable sur la charge de travail. Il peut y avoir des temps d'arrêt planifiés en raison de certaines opérations matérielles. Le plantage du serveur primaire qui le rend inaccessible à l'application. Autant de raisons d'effectuer un basculement, qu'il soit planifié ou non. Dans tous les cas, vous devrez promouvoir l'un des serveurs de secours pour qu'il devienne un nouveau serveur principal.
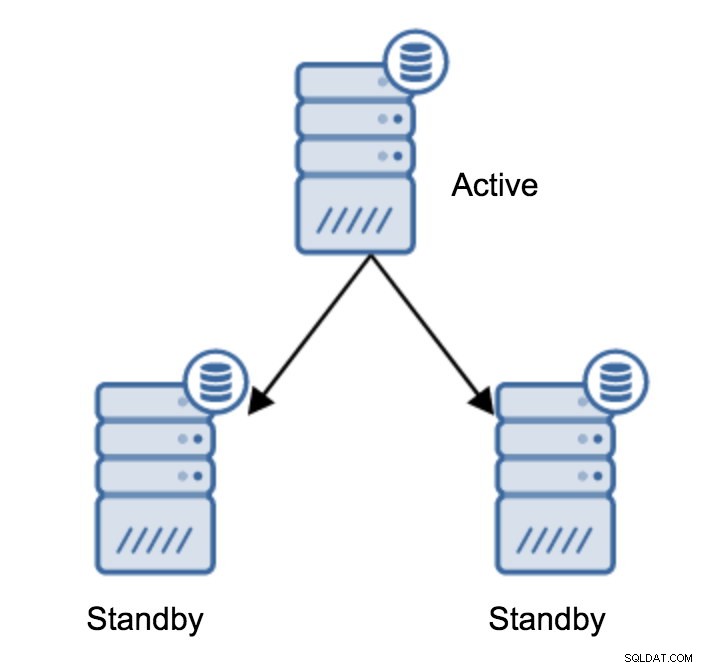
Pour promouvoir un serveur de secours, vous devez exécuter :
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
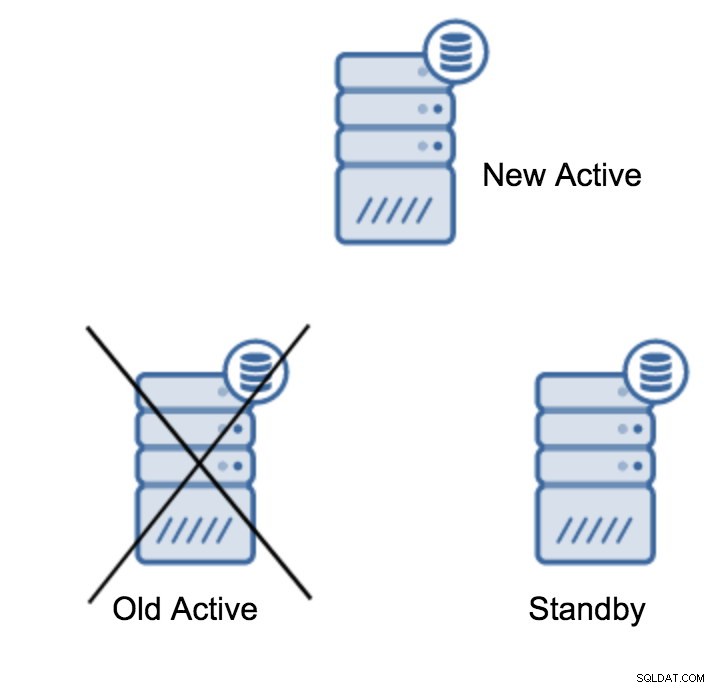
server promotedIl est facile d'exécuter cette commande, mais assurez-vous d'abord d'éviter toute perte de données. Si nous parlons d'un scénario de « serveur principal en panne », vous n'avez peut-être pas trop d'options. S'il s'agit d'une maintenance planifiée, alors il est possible de s'y préparer. Vous devez arrêter le trafic sur le serveur principal, puis vérifier que le serveur de secours a reçu et appliqué toutes les données. Cela peut être fait sur le serveur de secours, en utilisant la requête comme ci-dessous :
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Une fois que tout va bien, vous pouvez arrêter l'ancien serveur principal et promouvoir le serveur de secours.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancRéasservir un serveur de secours à un nouveau serveur primaire
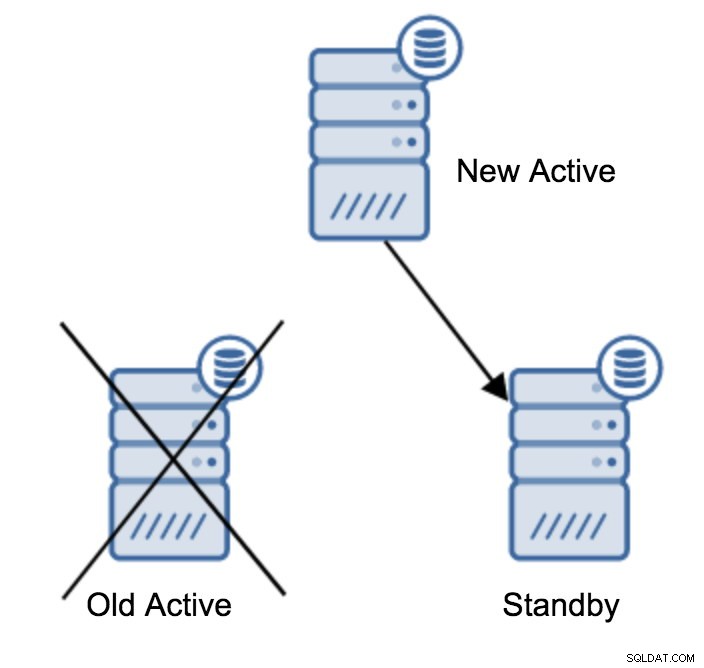
Vous pouvez avoir plusieurs serveurs de secours asservissant votre serveur principal. Après tout, les serveurs de secours sont utiles pour décharger le trafic en lecture seule. Après avoir promu un serveur de secours en nouveau serveur principal, vous devez faire quelque chose pour les serveurs de secours restants qui sont toujours connectés (ou qui tentent de se connecter) à l'ancien serveur principal. Malheureusement, vous ne pouvez pas simplement modifier le fichier recovery.conf et le connecter au nouveau serveur principal. Pour les connecter, vous devez d'abord les reconstruire. Il existe deux méthodes que vous pouvez essayer ici :la sauvegarde de base standard ou pg_rewind.
Nous n'entrerons pas dans les détails sur la façon d'effectuer une sauvegarde de base - nous l'avons couvert dans notre article de blog précédent, qui se concentrait sur la prise de sauvegardes et leur restauration sur PostgreSQL. S'il vous arrive d'utiliser ClusterControl, vous pouvez également l'utiliser pour créer une sauvegarde de base :
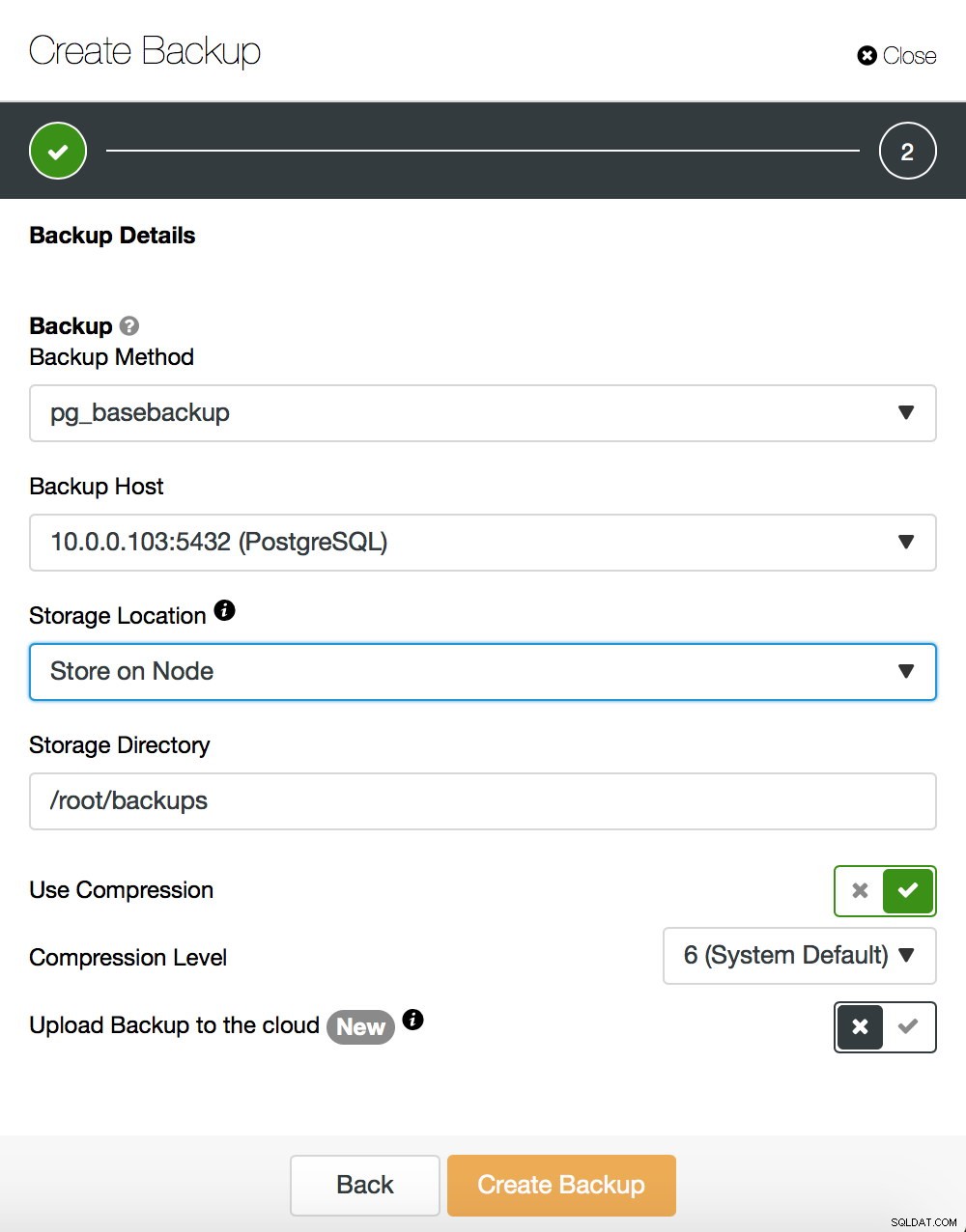
D'autre part, disons quelques mots sur pg_rewind. La principale différence entre les deux méthodes est que la sauvegarde de base crée une copie complète de l'ensemble de données. Si nous parlons de petits ensembles de données, cela peut être acceptable, mais pour des ensembles de données de plusieurs centaines de gigaoctets (ou même plus), cela peut rapidement devenir un problème. En fin de compte, vous souhaitez que vos serveurs de secours soient rapidement opérationnels - pour décharger votre serveur actif et disposer d'un autre serveur de secours vers lequel basculer, en cas de besoin. Pg_rewind fonctionne différemment - il ne copie que les blocs qui ont été modifiés. Au lieu de tout copier, il copie uniquement les modifications, ce qui accélère considérablement le processus. Supposons que votre nouveau maître ait une adresse IP de 10.0.0.103. C'est ainsi que vous pouvez exécuter pg_rewind. Veuillez noter que vous devez arrêter le serveur cible - PostgreSQL ne peut pas y être exécuté.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Cela fera un essai à blanc , testant le processus mais n'apportant aucune modification. Si tout va bien, tout ce que vous aurez à faire sera de le relancer, cette fois sans le paramètre ‘--dry-run’. Une fois cela fait, la dernière étape restante sera de créer un fichier recovery.conf, qui pointera vers le nouveau maître. Cela peut ressembler à ceci :
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Vous êtes maintenant prêt à démarrer votre serveur de secours et il se répliquera à partir du nouveau serveur actif.
Réplication en chaîne
Il existe de nombreuses raisons pour lesquelles vous souhaiterez peut-être créer une réplication en chaîne, bien que cela soit généralement fait pour réduire la charge sur le serveur principal. Servir le WAL aux serveurs de secours ajoute un peu de temps système. Ce n'est pas vraiment un problème si vous avez un serveur de secours ou deux, mais si nous parlons d'un grand nombre de serveurs de secours, cela peut devenir un problème. Par exemple, nous pouvons minimiser le nombre de serveurs de secours répliquant directement à partir de l'actif en créant une topologie comme ci-dessous :
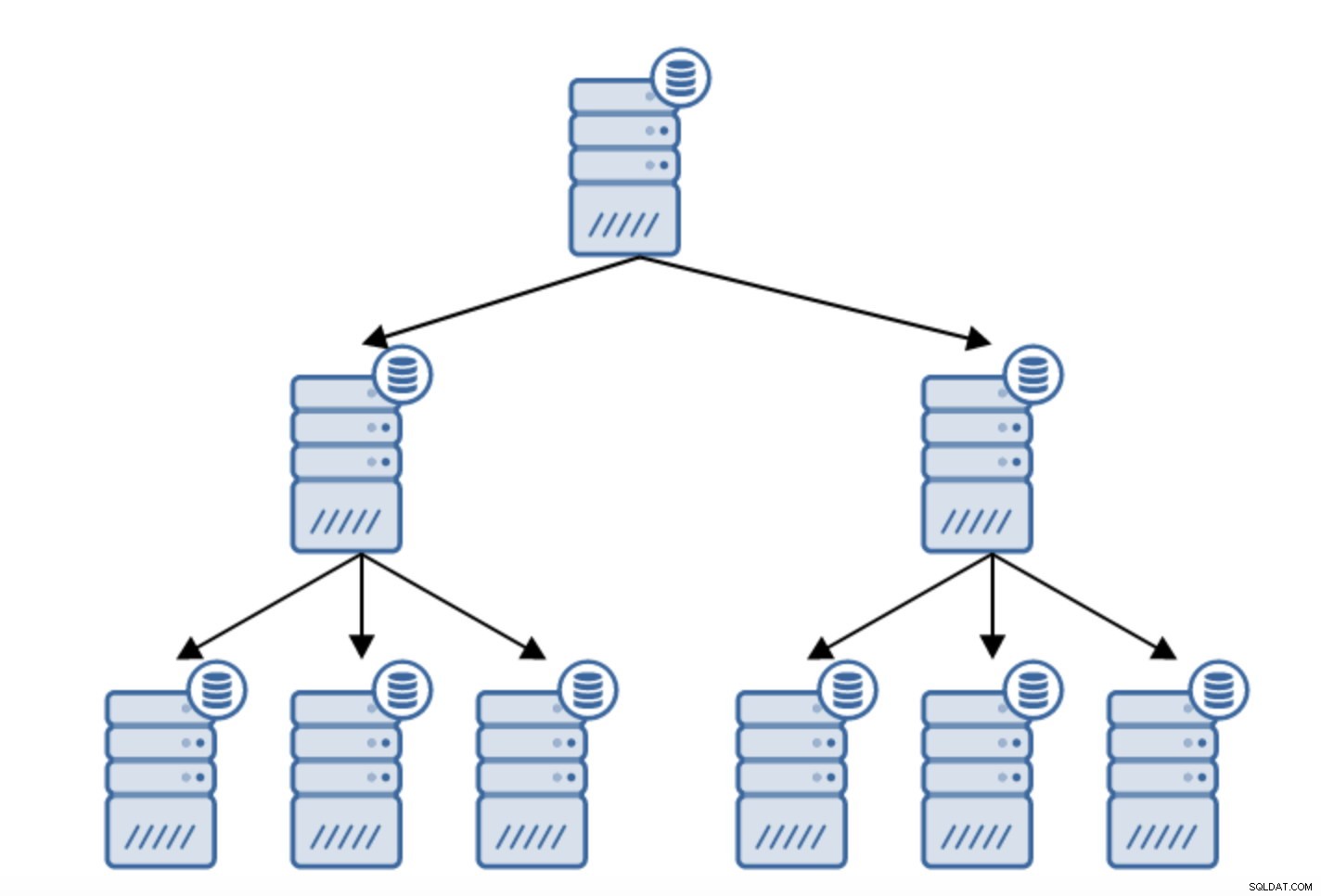
Le passage d'une topologie de deux serveurs de secours à une réplication chaînée est assez simple.
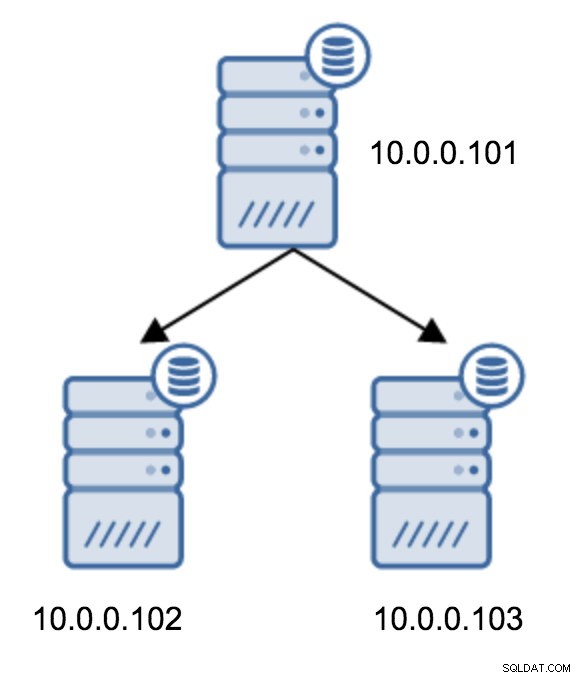
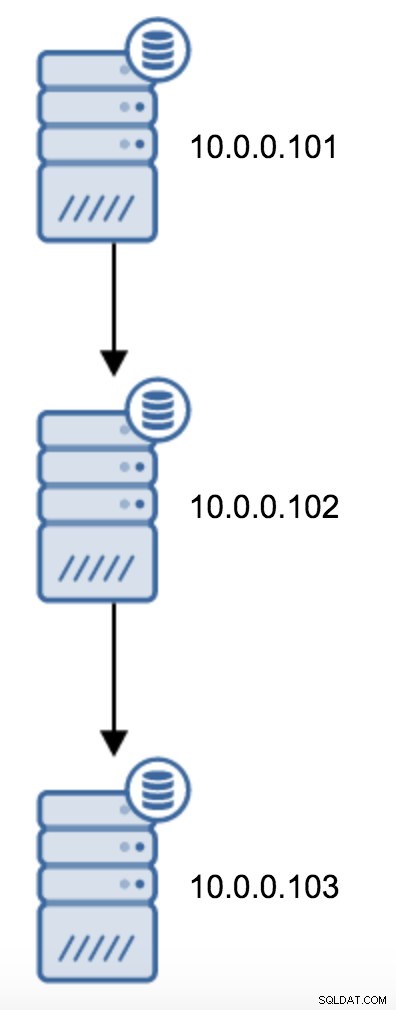
Vous devrez modifier recovery.conf sur 10.0.0.103, le pointer vers 10.0.0.102 puis redémarrer PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Après le redémarrage, 10.0.0.103 devrait commencer à appliquer les mises à jour WAL.
Voici quelques cas courants de changements de topologie. Un sujet qui n'a pas été abordé, mais qui est tout de même important, est l'impact de ces changements sur les applications. Nous aborderons cela dans un article séparé, ainsi que la façon de rendre ces changements de topologie transparents pour les applications.



