Une couche proxy peut être très utile pour augmenter la disponibilité de votre niveau de base de données. Cela peut réduire la quantité de code côté application pour gérer les défaillances de la base de données et les changements de topologie de réplication. Dans cet article de blog, nous expliquerons comment configurer un HAProxy pour qu'il fonctionne sur PostgreSQL.
Tout d'abord, HAProxy fonctionne avec les bases de données en tant que proxy de couche réseau. Il n'y a aucune compréhension de la topologie sous-jacente, parfois complexe. Tout ce que fait HAProxy est d'envoyer des paquets de manière circulaire à des backends définis. Il n'inspecte pas les paquets ni ne comprend le protocole dans lequel les applications communiquent avec PostgreSQL. Par conséquent, HAProxy n'a aucun moyen d'implémenter la division lecture/écriture sur un seul port - cela nécessiterait l'analyse des requêtes. Tant que votre application peut séparer les lectures des écritures et les envoyer à différentes adresses IP ou ports, vous pouvez implémenter la séparation R/W à l'aide de deux backends. Voyons comment cela peut être fait.
Configuration HAProxy
Vous trouverez ci-dessous un exemple de deux backends PostgreSQL configurés dans HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkComme nous pouvons le voir, ils utilisent les ports 3307 pour les écritures et 3308 pour les lectures. Dans cette configuration, il y a trois serveurs - un réplica actif et deux réplicas de secours. Ce qui est important, tcp-check est utilisé pour suivre la santé des nœuds. HAProxy se connectera au port 9201 et s'attend à voir une chaîne renvoyée. Les membres sains du backend renverront le contenu attendu, ceux qui ne renverront pas la chaîne seront marqués comme indisponibles.
Configuration de Xinetd
Comme HAProxy vérifie le port 9201, quelque chose doit l'écouter. Nous pouvons utiliser xinetd pour écouter et exécuter des scripts pour nous. Un exemple de configuration d'un tel service peut ressembler à :
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Vous devez vous assurer d'ajouter la ligne :
postgreschk 9201/tcpau /etc/services.
Xinetd démarre un script postgreschk, dont le contenu est comme ci-dessous :
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";La logique du script est la suivante. Deux requêtes sont utilisées pour détecter l'état du nœud.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Le premier vérifie si PostgreSQL est en récupération - il sera "faux" pour le serveur actif et "vrai" pour les serveurs de secours. La seconde vérifie si PostgreSQL est en mode lecture seule. Le serveur actif retournera "off" tandis que les serveurs de secours retourneront "on". Sur la base des résultats, le script appelle la fonction return_ok() avec un bon paramètre ("maître" ou "esclave", selon ce qui a été détecté). Si les requêtes échouent, une fonction ‘return_fail’ sera exécutée.
La fonction Return_ok renvoie une chaîne basée sur l'argument qui lui a été transmis. Si l'hôte est un serveur actif, le script renverra "Le maître PostgreSQL est en cours d'exécution". S'il s'agit d'une veille, la chaîne renvoyée sera :"L'esclave PostgreSQL est en cours d'exécution". Si l'état n'est pas clair, il renverra :"PostgreSQL est en cours d'exécution". C'est là que la boucle se termine. HAProxy vérifie l'état en se connectant à xinetd. Ce dernier démarre un script, qui renvoie ensuite une chaîne que HAProxy analyse.
Comme vous vous en souvenez peut-être, HAProxy attend les chaînes suivantes :
tcp-check expect string master\ is\ runningpour le backend d'écriture et
tcp-check expect string is\ running.pour le backend en lecture seule. Cela fait du serveur actif le seul hôte disponible dans le backend d'écriture tandis que sur le backend de lecture, les serveurs actifs et de secours peuvent être utilisés.
PostgreSQL et HAProxy dans ClusterControl
La configuration ci-dessus n'est pas complexe, mais sa configuration prend un certain temps. ClusterControl peut être utilisé pour configurer tout cela pour vous.
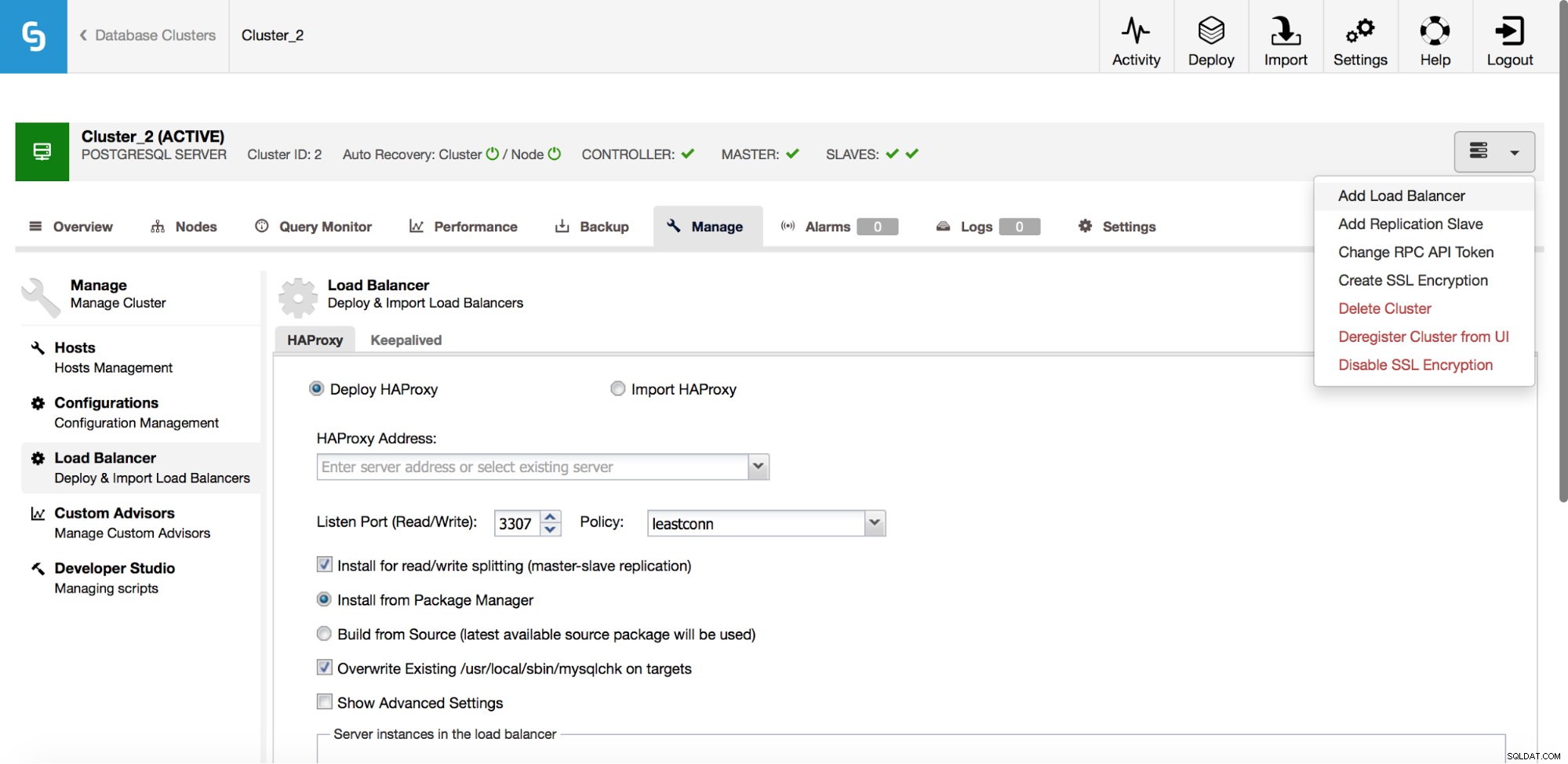
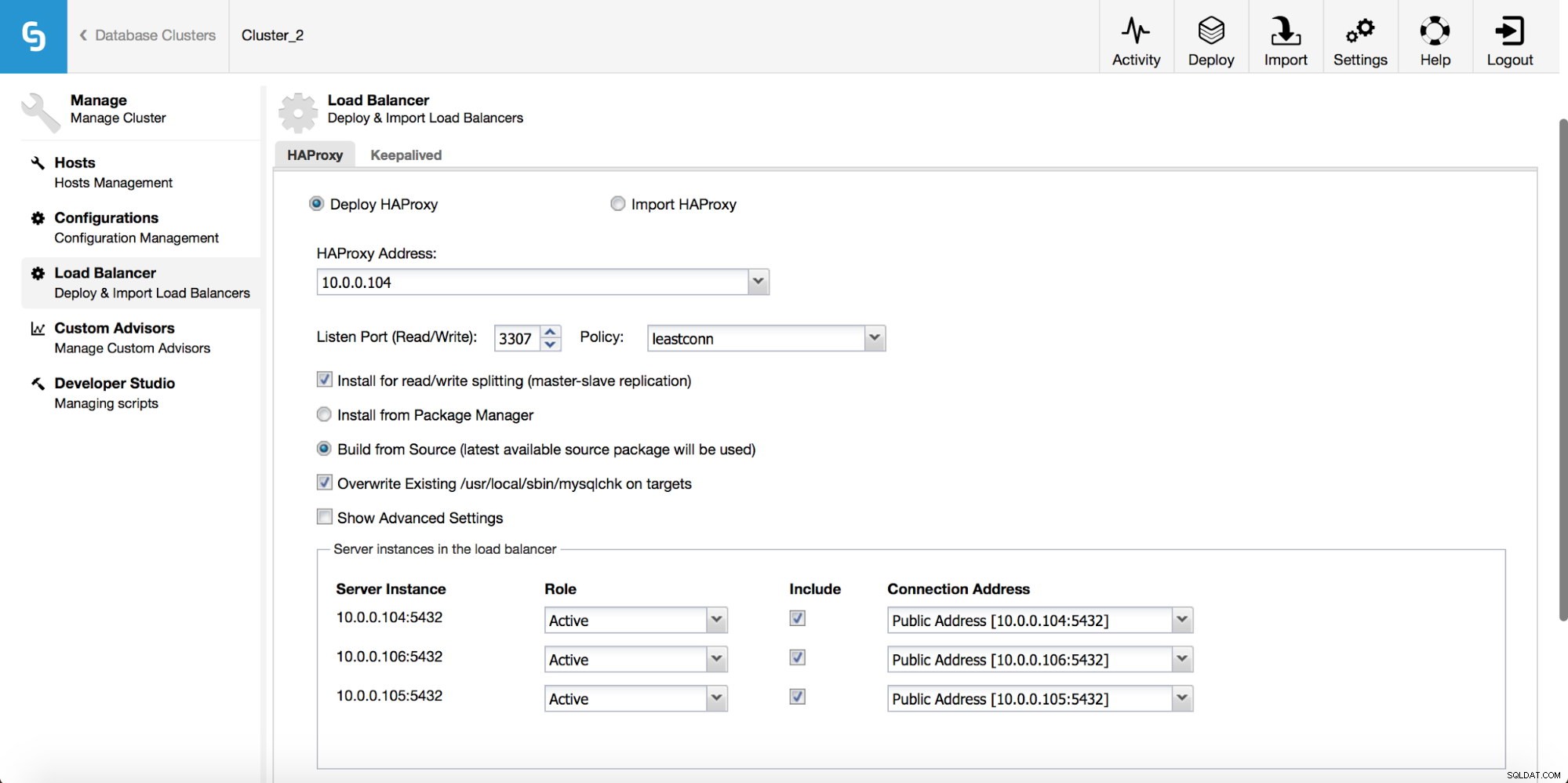
Dans le menu déroulant de la tâche de cluster, vous avez la possibilité d'ajouter un équilibreur de charge. Ensuite, une option pour déployer HAProxy apparaît. Vous devez indiquer où vous souhaitez l'installer et prendre des décisions :à partir des référentiels que vous avez configurés sur l'hôte ou de la dernière version, compilée à partir du code source. Vous devrez également configurer les nœuds du cluster que vous souhaitez ajouter à HAProxy.
Une fois l'instance HAProxy déployée, vous pouvez accéder à quelques statistiques dans l'onglet "Nœuds" :
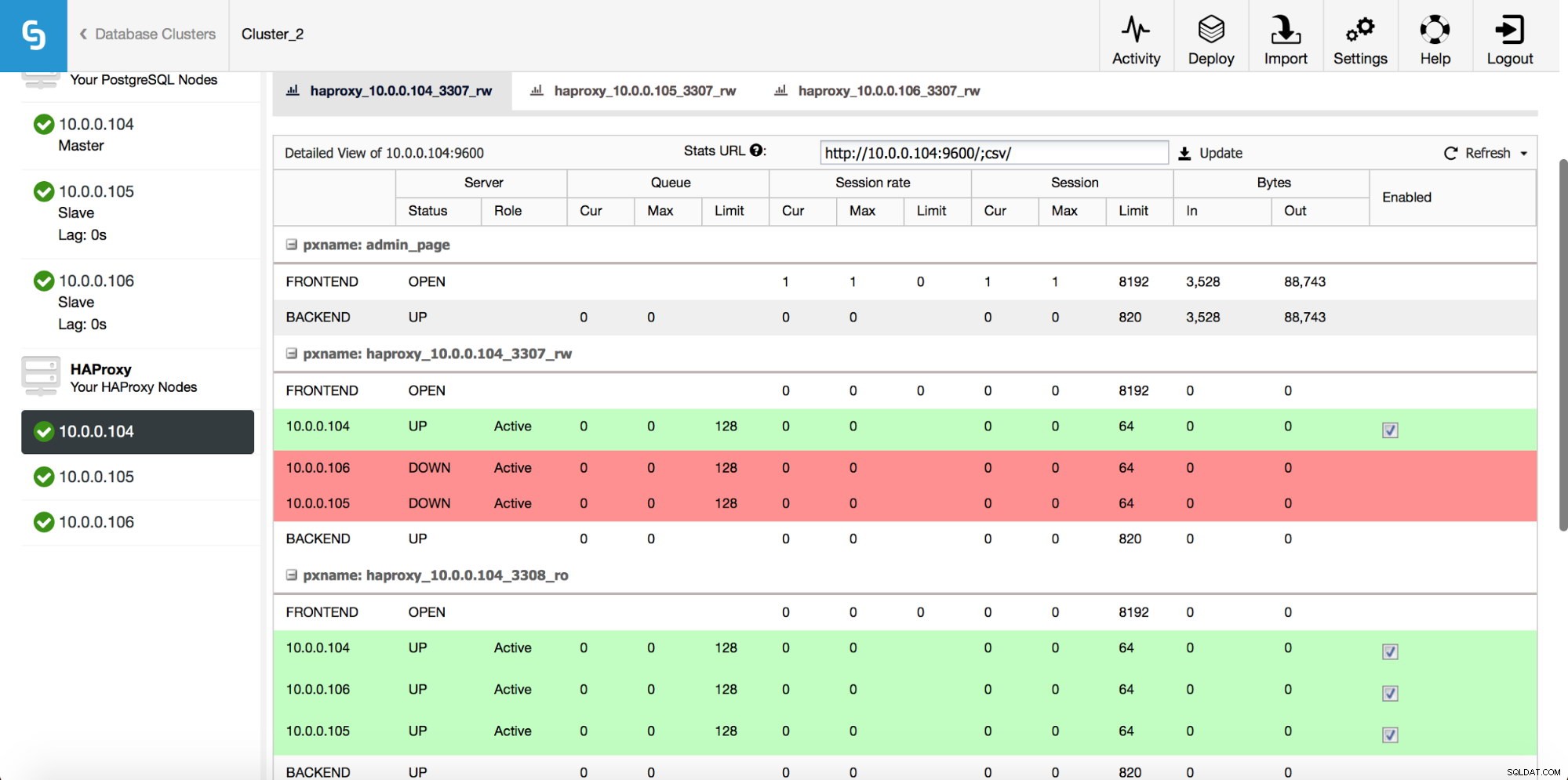
Comme nous pouvons le voir, pour le backend R/W, un seul hôte (serveur actif) est marqué comme actif. Pour le backend en lecture seule, tous les nœuds sont actifs.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancGardé
HAProxy se situera entre vos applications et les instances de base de données, il jouera donc un rôle central. Il peut malheureusement aussi devenir un point de défaillance unique, s'il échoue, il n'y aura pas de route vers les bases de données. Pour éviter une telle situation, vous pouvez déployer plusieurs instances HAProxy. Mais alors la question est - comment décider à quel hôte proxy se connecter. Si vous avez déployé HAProxy à partir de ClusterControl, c'est aussi simple que d'exécuter une autre tâche "Ajouter un équilibreur de charge", cette fois en déployant Keepalived.
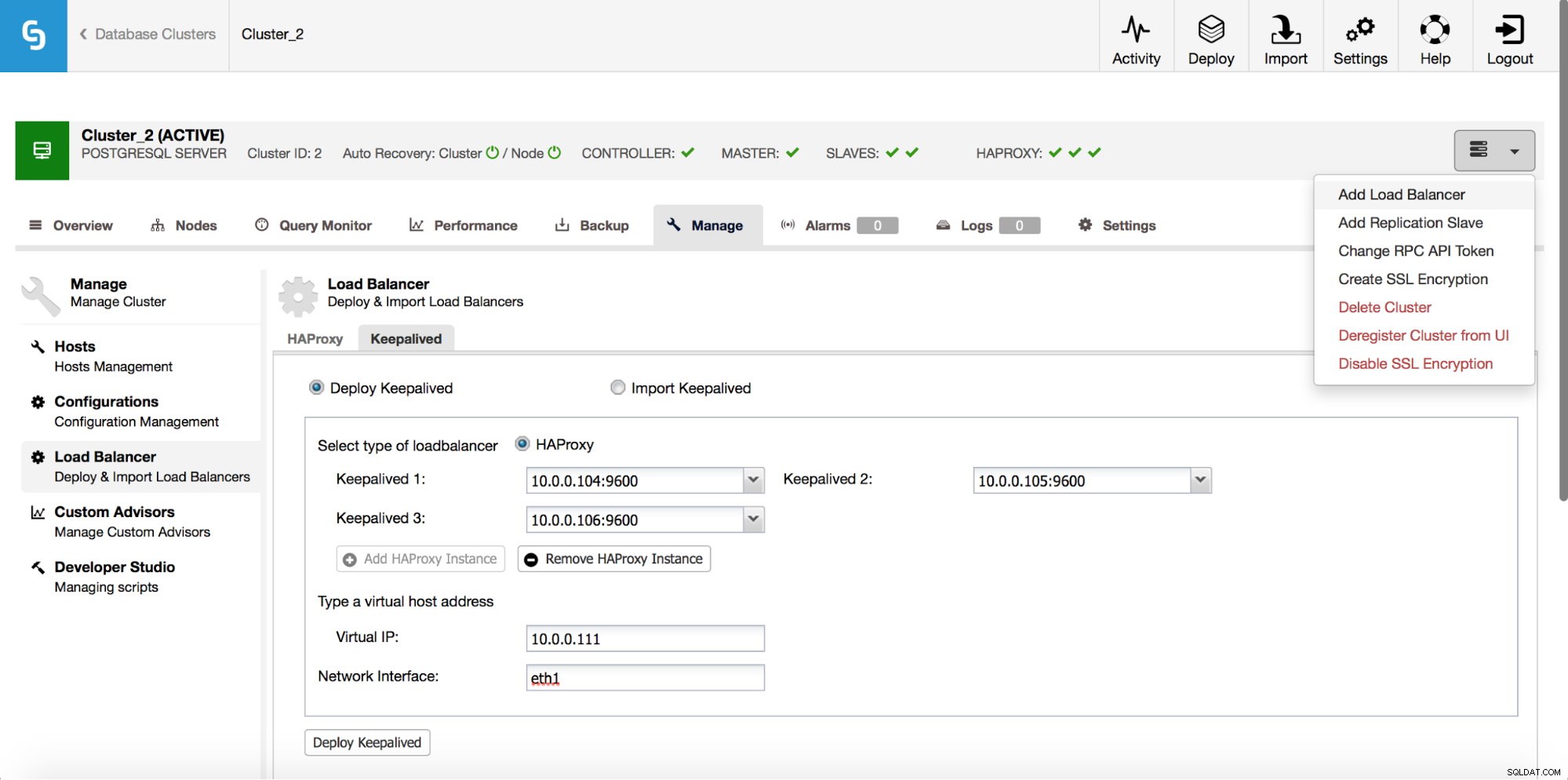
Comme nous pouvons le voir dans la capture d'écran ci-dessus, vous pouvez choisir jusqu'à trois hôtes HAProxy et Keepalived sera déployé sur eux, surveillant leur état. Une adresse IP virtuelle (VIP) sera attribuée à l'un d'entre eux. Votre application doit utiliser cette adresse IP virtuelle pour se connecter à la base de données. Si le HAProxy "actif" devient indisponible, le VIP sera déplacé vers un autre hôte.
Comme nous l'avons vu, il est assez facile de déployer une pile haute disponibilité complète pour PostgreSQL. Essayez-le et faites-nous savoir si vous avez des commentaires.



