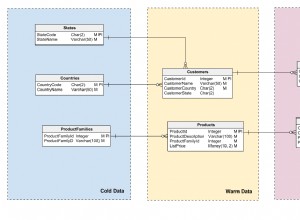
Solution appropriée
SELECT *
FROM (
SELECT day::date
FROM generate_series(timestamp '2007-12-01'
, timestamp '2008-12-01'
, interval '1 month') day
) d
LEFT JOIN (
SELECT date_trunc('month', date_col)::date AS day
, count(*) AS some_count
FROM tbl
WHERE date_col >= date '2007-12-01'
AND date_col <= date '2008-12-06'
-- AND ... more conditions
GROUP BY 1
) t USING (day)
ORDER BY day;
-
Utilisez
LEFT JOIN, bien sûr. -
generate_series()peut produire une table d'horodatages à la volée, et très rapidement. -
Il est généralement plus rapide d'agréger avant tu rejoins. J'ai récemment fourni un cas de test sur sqlfiddle.com dans cette réponse connexe :
- PostgreSQL – Trier par un tableau
-
Caster l'
timestampàdate(::date) pour un format de base. Pour en savoir plus, utilisezto_char(). -
GROUP BY 1est un raccourci de syntaxe pour référencer la première colonne de sortie. Peut êtreGROUP BY dayégalement, mais cela pourrait entrer en conflit avec une colonne existante du même nom. OuGROUP BY date_trunc('month', date_col)::datemais c'est trop long à mon goût. -
Fonctionne avec les arguments d'intervalle disponibles pour
date_trunc(). -
count()ne produit jamaisNULL(0pour aucune ligne), mais leLEFT JOINfait.
Pour renvoyer0au lieu deNULLdans leSELECTexterne , utilisezCOALESCE(some_count, 0) AS some_count. Le manuel. -
Pour une solution plus générique ou des intervalles de temps arbitraires considérez cette réponse étroitement liée :
- Meilleur moyen de compter les enregistrements par intervalles de temps arbitraires dans Rails+Postgres