La réponse sera bien sûr "ça dépend" mais en se basant sur le test de cette fin...
En supposant que
- 1 million de produits
producta un index clusterisé surproduct_id- La plupart des produits (sinon tous) ont des informations correspondantes dans le
product_codetableau - Index idéaux présents sur
product_codepour les deux requêtes.
Le PIVOT la version nécessite idéalement un index product_code(product_id, type) INCLUDE (code) alors que le JOIN la version nécessite idéalement un index product_code(type,product_id) INCLUDE (code)
Si ceux-ci sont en place, donnez les plans ci-dessous
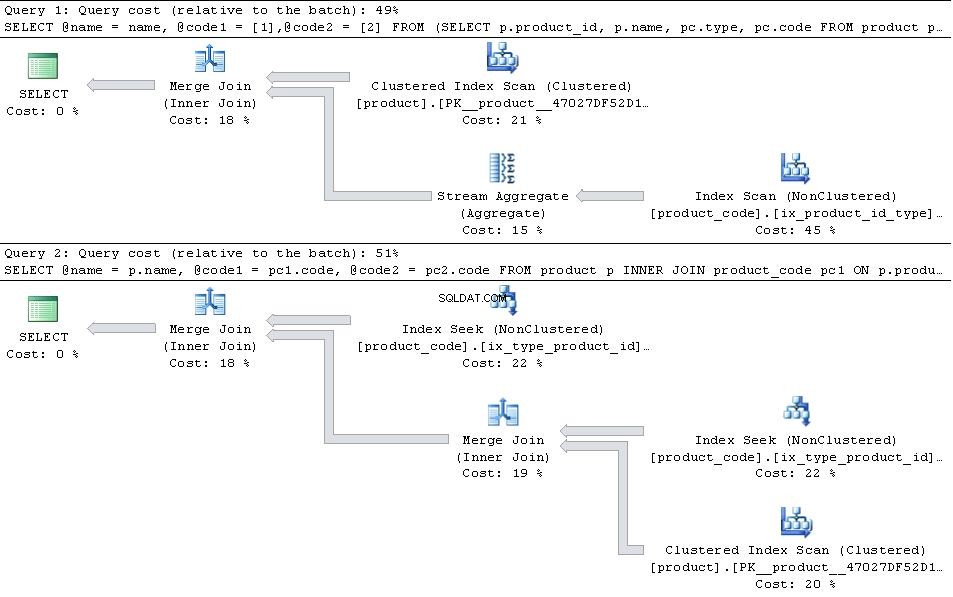
puis le JOIN version est plus efficace.
Dans le cas où type 1 et type 2 sont les seuls types dans le tableau puis le PIVOT la version a légèrement l'avantage en termes de nombre de lectures car elle n'a pas à chercher dans product_code deux fois, mais cela est plus que compensé par la surcharge supplémentaire de l'opérateur d'agrégation de flux
PIVOTER
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
JOIGNEZ-VOUS
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
S'il existe des type supplémentaires enregistrements autres que 1 et 2 le JOIN version augmentera son avantage car il ne fait que fusionner des jointures sur les sections pertinentes du type,product_id index tandis que le PIVOT le plan utilise product_id, type et devrait donc scanner le type supplémentaire lignes qui sont entremêlées avec le 1 et 2 lignes.