Je continue une série d'articles sur les bases d'EXPLAIN dans PostgreSQL, qui est une courte revue de Comprendre EXPLAIN par Guillaume Lelarge.
Pour mieux comprendre le problème, je recommande fortement de revoir l'original « Comprendre EXPLAIN » par Guillaume Lelarge et lisez mes premier et deuxième articles.
TRIER PAR
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Dans un premier temps, vous exécutez un parcours séquentiel (Seq Scan) de la table foo puis, faites le tri (Sort). Le signe -> de la commande EXPLAIN indique la hiérarchie des étapes (nœud). Plus l'étape est exécutée tôt, plus son retrait est important.
La clé de tri est une condition de tri.
Méthode de tri :disque de fusion externe, un fichier temporaire sur le disque d'une capacité de 4 592 ko est utilisé lors du tri.
Vérifiez avec l'option BUFFERS :
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
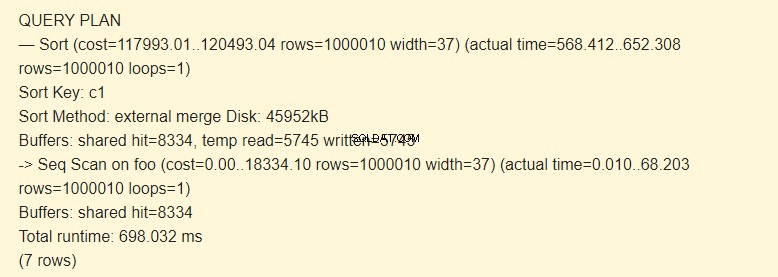
En effet, la ligne temp read=5745 written=5745 signifie que 45960Ko (5745 blocs de 8Ko chacun) ont été stockés et lus dans le fichier temporaire. Les opérations avec 8334 blocs ont été exécutées dans le cache.
Les opérations avec le système de fichiers sont plus lentes que les opérations en RAM.
Essayons d'augmenter la capacité mémoire de work_mem :
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Méthode de tri :quicksort Mémoire :102 702 ko – l'ensemble du tri a été exécuté en RAM.
L'index est le suivant :
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Il ne nous reste plus qu'Index Scan, ce qui a considérablement affecté la vitesse de la requête.
LIMITER
Supprimez l'index précédemment créé :
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Comme prévu, Seq Scan et Filter sont utilisés.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan lit les lignes du tableau et les compare (Filtre) avec la condition. Dès que 10 enregistrements remplissent la condition, l'analyse se termine. Dans notre cas, pour obtenir 10 lignes de résultats, nous n'avons dû lire que 3063 enregistrements plutôt que toute la table. 3 053 lignes de ce nombre ont été rejetées (Lignes supprimées par le filtre).
La même chose se produit avec l'analyse de l'index.
JOIGNEZ-VOUS
Créez une nouvelle table et générez des statistiques pour celle-ci :
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
La requête pour deux tables est la suivante :
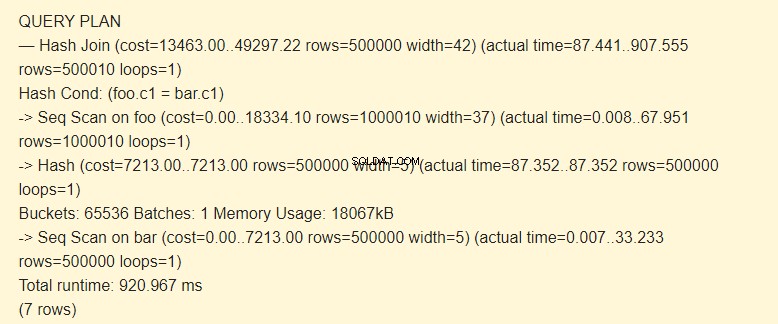
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Tout d'abord, le balayage séquentiel (Seq Scan) lit la table des barres. Un hachage (Hash) est calculé pour chaque ligne.
Ensuite, il parcourt la table foo, et pour chaque ligne, un hachage est calculé qui est comparé (Hash Join) avec le hachage de la table bar par la condition Hash Cond. S'ils correspondent, une chaîne résultante est générée.
18 067 Ko de mémoire sont utilisés pour stocker les hachages de la barre.
Ajouter l'index :
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Le hachage n'est plus utilisé. Merge Join et Index Scan sur les index des deux tables améliorent considérablement les performances.
JOINTURE GAUCHE :
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
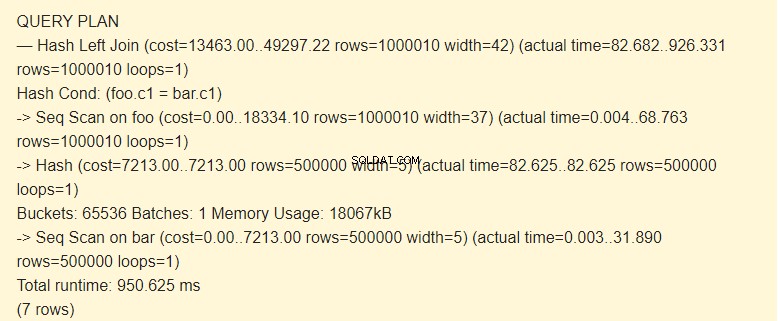
Numérisation séquentielle ?
Voyons quel résultat nous aurons si nous désactivons Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Selon le planificateur, l'utilisation d'index est plus coûteuse que l'utilisation de hachages. Ceci est possible avec une quantité suffisante de mémoire allouée. Vous souvenez-vous que nous avons augmenté work_mem ?
Cependant, si vous n'avez pas assez de mémoire, le planificateur se comportera différemment :
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Si nous désactivons Index Scan, quel résultat EXPLAIN affichera-t-il ?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
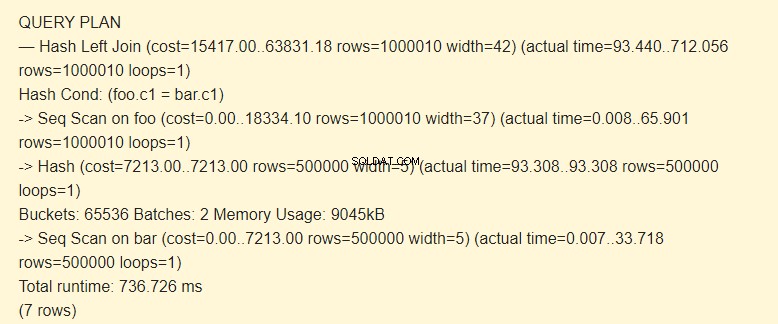
Lots :2 a un coût accru. Le hachage entier ne tenait pas dans la mémoire ; nous avons dû le diviser en deux packages de 9045 Ko.
Merci d'avoir lu mes articles! J'espère qu'ils ont été utiles. Si vous avez des commentaires ou des commentaires, n'hésitez pas à me le faire savoir.