PostgreSQL est un projet génial et il évolue à une vitesse incroyable. Nous nous concentrerons sur l'évolution des capacités de tolérance aux pannes dans PostgreSQL à travers ses versions avec une série d'articles de blog. Ceci est le deuxième article de la série et nous parlerons de la réplication et de son importance sur la tolérance aux pannes et la fiabilité de PostgreSQL.
Si vous souhaitez assister à la progression de l'évolution depuis le début, veuillez consulter le premier article de blog de la série :Évolution de la tolérance aux pannes dans PostgreSQL
Réplication PostgreSQL
Réplication de base de données est le terme que nous utilisons pour décrire la technologie utilisée pour conserver une copie d'un ensemble de données sur une télécommande système. Conserver une copie fiable d'un système en cours d'exécution est l'une des plus grandes préoccupations de la redondance et nous aimons tous des copies maintenables, faciles à utiliser et stables de nos données.
Regardons l'architecture de base. En règle générale, les serveurs de base de données individuels sont appelés nœuds . L'ensemble du groupe de serveurs de base de données impliqués dans la réplication est appelé cluster . Un serveur de base de données qui permet à un utilisateur d'apporter des modifications est appelé maître ou principal , ou peut être décrit comme une source de changements. Un serveur de base de données qui uniquement autorise l'accès en lecture seule est connu sous le nom de Hot Standby . (Le terme Hot Standby est expliqué en détail sous le titre Modes de veille. )
L'aspect clé de la réplication est que les modifications de données sont capturées sur un maître, puis transférées vers d'autres nœuds. Dans certains cas, un nœud peut envoyer des modifications de données à d'autres nœuds, ce qui est un processus appelé cascading ou relais . Ainsi, le maître est un nœud émetteur mais tous les nœuds émetteurs n'ont pas besoin d'être maîtres. La réplication est souvent classée selon que plusieurs nœuds maîtres sont autorisés, auquel cas elle sera appelée réplication multimaître .
Voyons comment PostgreSQL gère la réplication au fil du temps et quel est l'état de l'art en matière de tolérance aux pannes en termes de réplication.
Historique de réplication PostgreSQL
Historiquement (autour de l'année 2000-2005), Postgres se concentrait uniquement sur la tolérance/récupération des pannes à un seul nœud, ce qui est principalement réalisé par le WAL, le journal des transactions. La tolérance aux pannes est gérée en partie par MVCC (système de concurrence multi-version), mais il s'agit principalement d'une optimisation.
La journalisation en écriture anticipée était et est toujours la plus grande méthode de tolérance aux pannes dans PostgreSQL. Fondamentalement, il suffit d'avoir des fichiers WAL où vous écrivez tout et pouvez récupérer en termes d'échec en les rejouant. Cela était suffisant pour les architectures à nœud unique et la réplication est considérée comme la meilleure solution pour atteindre la tolérance aux pannes avec plusieurs nœuds.
La communauté Postgres croyait depuis longtemps que la réplication est quelque chose que Postgres ne devrait pas fournir et devrait être gérée par des outils externes, c'est pourquoi des outils comme Slony et Londiste sont devenus existants. (Nous aborderons les solutions de réplication basées sur des déclencheurs dans les prochains articles de blog de la série.)
Finalement, il est devenu clair que la tolérance d'un serveur n'est pas suffisante et que de plus en plus de personnes ont exigé une tolérance de panne appropriée du matériel et une méthode de commutation appropriée, ce qui est intégré à Postgres. C'est à ce moment que la réplication physique (puis le streaming physique) a vu le jour.
Nous passerons en revue toutes les méthodes de réplication plus tard dans l'article, mais voyons les événements chronologiques de l'historique de réplication PostgreSQL par versions majeures :
- PostgreSQL 7.x (~2000)
- La réplication ne doit pas faire partie du cœur de Postgres
- Londiste – Slony (réplication logique basée sur des déclencheurs)
- PostgreSQL 8.0 (2005)
- Récupération ponctuelle (WAL)
- PostgreSQL 9.0 (2010)
- Réplication en continu (physique)
- PostgreSQL 9.4 (2014)
- Décodage logique (extraction du jeu de modifications)
Réplication physique
PostgreSQL a résolu le besoin de réplication de base avec ce que font la plupart des bases de données relationnelles ; a pris le WAL et a rendu possible son envoi sur le réseau. Ensuite, ces fichiers WAL sont appliqués dans une instance Postgres distincte qui s'exécute en lecture seule.
L'instance de secours en lecture seule applique uniquement les modifications (par WAL) et les seules opérations d'écriture viennent à nouveau du même journal WAL. Voici comment la réplication en continu mécanisme fonctionne. Au début, la réplication envoyait à l'origine tous les fichiers -l'envoi de journaux- , mais plus tard, il a évolué vers le streaming.
Dans l'envoi de journaux, nous envoyions des fichiers entiers via la archive_command . La logique est assez simple :il vous suffit d'envoyer l'archive et le journal placez-le quelque part - comme l'ensemble du fichier WAL de 16 Mo - et ensuite vous appliquez vers quelque part, puis vous récupérez le suivant et postuler celui-là et ça va comme ça. Plus tard, il est devenu un streaming sur le réseau en utilisant le protocole libpq dans PostgreSQL version 9.0.
La réplication existante est plus correctement connue sous le nom de Physical Streaming Replication, puisque nous diffusons une série de changements physiques d'un nœud à un autre. Cela signifie que lorsque nous insérons une ligne dans un tableau, nous générons des enregistrements de modification pour l'insert plus toutes les entrées d'index .
Quand on VACUUM une table, nous générons également des enregistrements de modification.
De plus, Physical Streaming Replication enregistre toutes les modifications au niveau octet/bloc , ce qui rend très difficile de faire autre chose que de tout rejouer
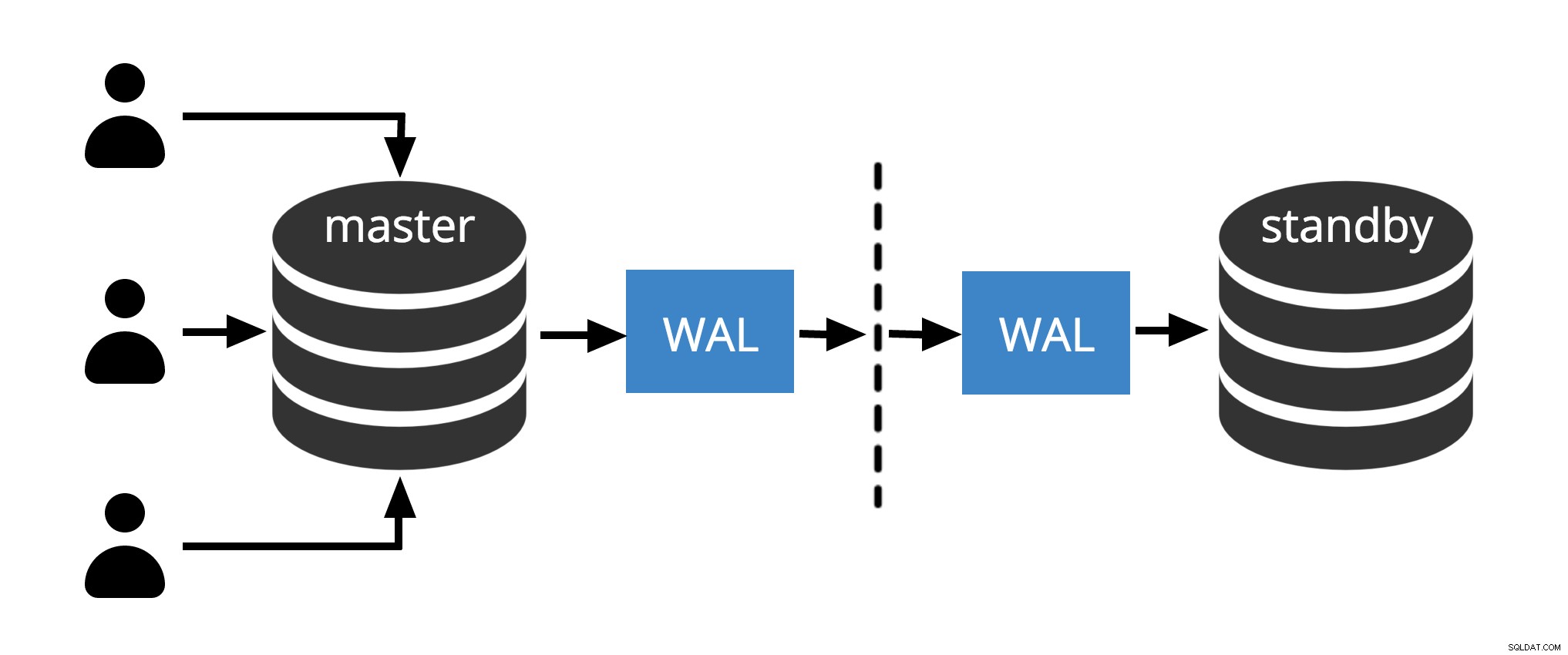
Fig.1 Réplication physique
La figure 1 montre comment la réplication physique fonctionne avec seulement deux nœuds. Le client exécute des requêtes sur le nœud maître, les modifications sont écrites dans un journal de transactions (WAL) et copiées sur le réseau vers WAL sur le nœud de secours. Le processus de récupération sur le nœud de secours lit ensuite les modifications de WAL et les applique aux fichiers de données comme lors de la récupération après un crash. Si le standby est en hot standby mode, les clients peuvent émettre des requêtes en lecture seule sur le nœud pendant que cela se produit.
Remarque : La réplication physique fait simplement référence à l'envoi de fichiers WAL sur le réseau du nœud maître au nœud de secours. Les fichiers peuvent être envoyés par différents protocoles comme scp, rsync, ftp… La différence entre la réplication physique et réplication de flux physique est Streaming Replication utilise un protocole interne pour l'envoi de fichiers WAL (sender et processus récepteurs )
Modes veille
Plusieurs nœuds offrent une haute disponibilité. Pour cette raison, les architectures modernes ont généralement des nœuds de secours. Il existe différents modes pour les nœuds de veille (veille chaude et veille à chaud). La liste ci-dessous explique les différences fondamentales entre les différents modes de veille et montre également le cas d'une architecture multi-maître.
Veille chaude
Peut être activé immédiatement, mais ne peut pas effectuer de travail utile tant qu'il n'est pas activé. Si nous envoyons continuellement la série de fichiers WAL à une autre machine qui a été chargée avec le même fichier de sauvegarde de base, nous avons un système de secours à chaud :à tout moment, nous pouvons faire apparaître la deuxième machine et elle aura une copie presque à jour de la base de données. La veille à chaud n'autorise pas les requêtes en lecture seule, la Fig.2 représente simplement ce fait.
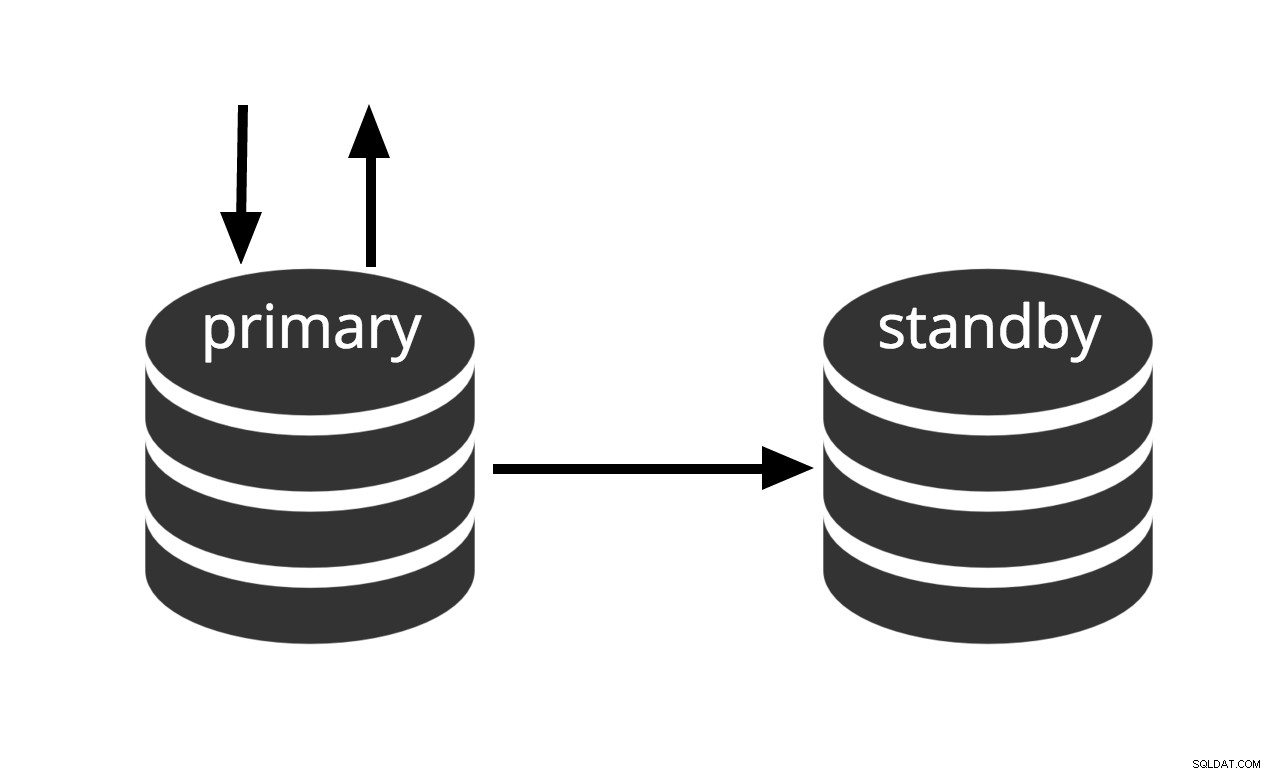
Fig.2 Warm Standby
Les performances de récupération d'un secours à chaud sont suffisamment bonnes pour que le secours ne soit généralement qu'à quelques instants de la disponibilité totale une fois qu'il a été activé. Par conséquent, cela s'appelle une configuration de secours à chaud qui offre une haute disponibilité.
Veille automatique
La redondance d'UC est le terme utilisé pour décrire la possibilité de se connecter au serveur et d'exécuter des requêtes en lecture seule pendant que le serveur est en mode de récupération d'archive ou de veille. Ceci est utile à la fois à des fins de réplication et pour restaurer une sauvegarde à un état souhaité avec une grande précision.
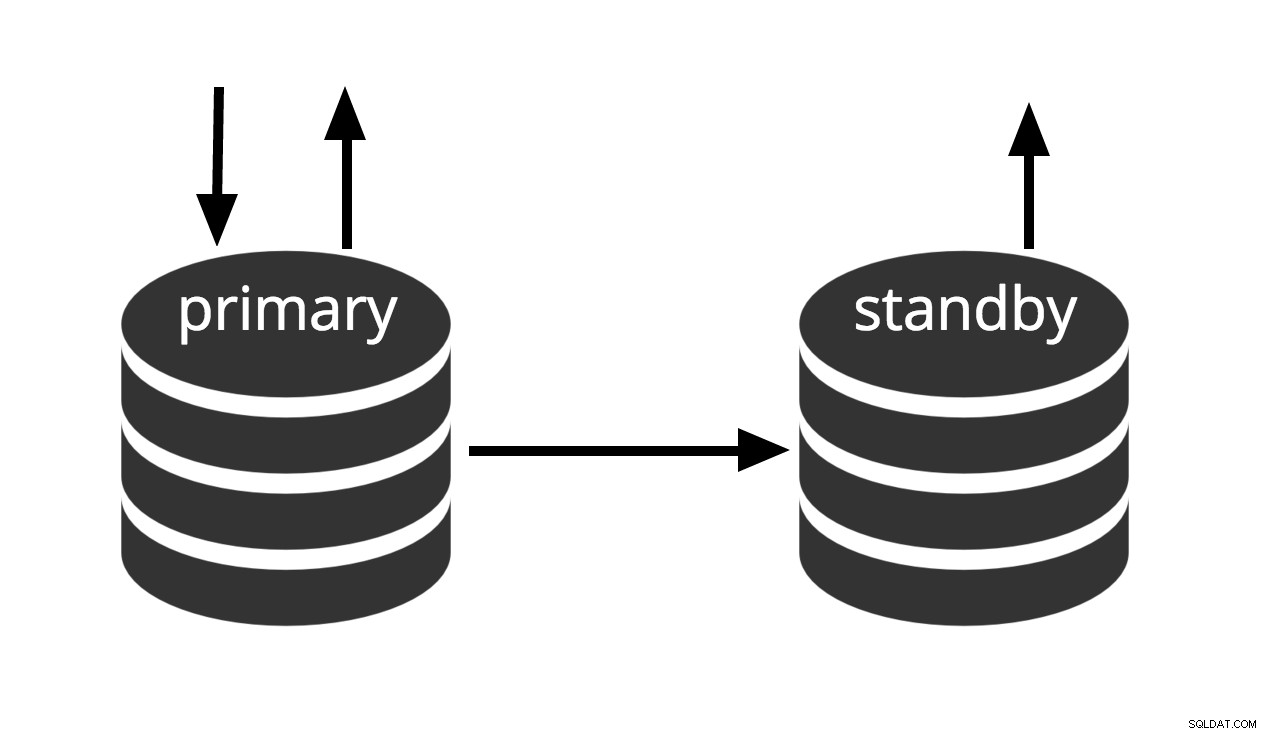 Fig.3 Redondance d'UC
Fig.3 Redondance d'UC
Le terme "hot standby" fait également référence à la capacité du serveur à passer de la récupération à un fonctionnement normal pendant que les utilisateurs continuent d'exécuter des requêtes et/ou maintiennent leurs connexions ouvertes. La figure 3 montre que le mode veille autorise les requêtes en lecture seule.
Multi-maître
Tous les nœuds peuvent effectuer un travail de lecture/écriture. (Nous couvrirons les architectures multi-maîtres dans les prochains articles de blog de la série.)
Paramètre de niveau WAL
Il existe une relation entre la configuration de wal_level paramètre dans le fichier postgresql.conf et à quoi ce paramètre convient-il. J'ai créé une table pour montrer la relation pour PostgreSQL version 9.6.

Basculement et basculement
Dans la réplication mono-maître, si le maître décède, un des standby doit prendre sa place (promotion ). Sinon, nous ne pourrons pas accepter de nouvelles transactions d'écriture. Ainsi, les désignations de terme, maître et veille, ne sont que des rôles que n'importe quel nœud peut prendre à un moment donné. Pour déplacer le rôle de maître vers un autre nœud, nous effectuons une procédure nommée Switchover .
Si le maître meurt et ne récupère pas, le changement de rôle le plus grave est appelé Basculement . À bien des égards, ceux-ci peuvent être similaires, mais il est utile d'utiliser des termes différents pour chaque événement. (Connaître les conditions de basculement et de basculement nous aidera à comprendre les problèmes de chronologie lors du prochain article de blog.)
Conclusion
Dans cet article de blog, nous avons discuté de la réplication PostgreSQL et de son importance pour assurer la tolérance aux pannes et la fiabilité. Nous avons couvert la réplication physique en continu et parlé des modes de veille pour PostgreSQL. Nous avons mentionné le basculement et le basculement. Nous continuerons avec les échéanciers de PostgreSQL lors du prochain article de blog.
Références
Documentation PostgreSQL
Réplication logique dans PostgreSQL 5432… Présentation MeetUs par Petr Jelinek
Livre de recettes d'administration PostgreSQL 9 – Deuxième édition



