Ceci est la partie 2 de cette série de blogs. Vous pouvez lire la partie 1, ici : La transformation numérique est un parcours de données de la périphérie à l'insight
Cette série de blogs suit les données de fabrication, d'exploitation et de vente d'un constructeur de véhicules connectés alors que les données passent par des étapes et des transformations généralement vécues dans une grande entreprise de fabrication à la pointe de la technologie actuelle. Le premier blog a présenté une entreprise de fabrication de véhicules connectés simulés, The Electric Car Company (ECC), pour illustrer le cheminement des données de fabrication tout au long du cycle de vie des données. Pour ce faire, ECC s'appuie sur la plate-forme de données Cloudera (CDP) pour prévoir les événements et avoir une vue descendante du processus de fabrication de la voiture dans ses usines situées à travers le monde.
Après avoir terminé l'étape de collecte de données dans le blog précédent, la prochaine étape d'ECC dans le cycle de vie des données est l'enrichissement des données. ECC enrichira les données collectées et les rendra disponibles pour être utilisées dans l'analyse et la création de modèles plus tard dans le cycle de vie des données. Vous trouverez ci-dessous l'ensemble des étapes du cycle de vie des données, et chaque étape du cycle de vie sera prise en charge par un article de blog dédié (voir Fig. 1) :
- Collecte de données – ingestion et surveillance des données à la périphérie (qu'il s'agisse de capteurs industriels ou de personnes dans une salle d'exposition de véhicules)
- Enrichissement des données – traitement, agrégation et gestion du pipeline de données afin de préparer les données pour une analyse plus approfondie
- Rapports – fournir des informations commerciales (analyse et prévision des ventes, budgétisation à titre d'exemples)
- Servir – contrôler et exécuter les opérations commerciales essentielles (opérations des concessionnaires, suivi de la production)
- Analyse prédictive – analyse prédictive basée sur l'IA et l'apprentissage automatique (maintenance prédictive, optimisation des stocks basée sur la demande, par exemple)
- Sécurité et gouvernance – un ensemble intégré de technologies de sécurité, de gestion et de gouvernance sur l'ensemble du cycle de vie des données

Fig. 1 Le cycle de vie des données d'entreprise
Défi d'enrichissement des données
ECC a besoin d'une vue complète et d'une solide compréhension de toutes les données liées à la fabrication, aux opérations des concessionnaires et à l'expédition de leurs véhicules. Ils devront également identifier rapidement les problèmes liés aux données, tels que les capteurs opérationnels qui génèrent des données pouvant inclure de faux pics de température causés par des arrêts de machine imprévus ou des démarrages brusques. Les données qui n'ont aucun rapport avec le processus lorsque les agents de maintenance retirent un capteur d'un réservoir de trempage acide lors d'inspections de routine, par exemple, ne doivent pas être prises en compte dans l'analyse.
De plus, ECC est confronté aux défis suivants en matière de données qui doivent être résolus pour faire passer avec succès la fabrication de moteurs tout au long de sa chaîne d'approvisionnement. Ces défis liés aux données incluent les éléments suivants :
- Récupérer des données dans différents formats à partir de différentes sources : Les pipelines d'ingénierie de données nécessitent que des données soient importées de diverses sources et dans de nombreux formats différents. Que les données proviennent de capteurs situés sur la chaîne de production, prenant en charge les opérations de fabrication ou de données ERP contrôlant la chaîne d'approvisionnement, elles doivent toutes être rassemblées pour une analyse plus approfondie.
- Filtrer les données redondantes ou non pertinentes : La suppression des données en double ou non valides et l'assurance de l'exactitude des données restantes constituent une étape clé dans la préparation des données en vue d'une utilisation ultérieure dans l'analyse prédictive avancée.
- Capacité à identifier les processus inefficaces : L'ECC nécessite la capacité de voir quels processus de données prennent le plus de temps et de ressources, ce qui permet de cibler facilement les parties les moins performantes du pipeline afin d'accélérer le processus global.
- Capacité à surveiller tous les processus à partir d'un seul volet : ECC a besoin d'un système centralisé qui leur permet de surveiller tous les processus de données en cours ainsi que d'un moyen d'étendre leur infrastructure actuelle tout en maintenant la transparence.
Des ensembles de données de qualité et organisés sont l'épine dorsale de toute initiative d'analyse avancée. Pour ce faire, un cadre d'ingénierie des données doit être utilisé pour permettre la construction de toute la tuyauterie et la plomberie nécessaires pour déplacer, manipuler et gérer les données des différentes pièces du véhicule dans le cycle de vie des données.
Construire un pipeline à l'aide de Cloudera Data Engineering
Avant que les données ne soient enrichies et discutées dans le premier blog, les flux de données IT et OT collectés depuis l'usine seront nettoyés, manipulés et modifiés. L'ID d'usine, l'ID de la machine, l'horodatage, le numéro de pièce et le numéro de série peuvent être capturés à partir d'un code QR imprimé sur le moteur électrique. Au fur et à mesure que le moteur est assemblé dans le véhicule connecté, des données sont capturées, telles que le type de modèle, le VIN et le coût de base du véhicule.
Une fois le véhicule vendu, les informations de vente telles que le nom du client, ses coordonnées, le prix de vente final et l'emplacement du client sont enregistrées séparément. Ces données seront cruciales pour contacter le client pour tout rappel potentiel ou maintenance préventive ciblée. Les données de géolocalisation sont également stockées, ce qui aidera à cartographier les emplacements des clients aux latitudes et longitudes pour mieux comprendre où se trouvent ces moteurs après avoir été vendus dans un véhicule.
ECC utilisera Cloudera Data Engineering (CDE) pour relever les défis de données ci-dessus (voir Fig. 2). CDE mettra ensuite les données à la disposition de Cloudera Data Warehouse (CDW), où elles seront mises à disposition pour des analyses avancées et des rapports de veille économique. Les étapes du CDE sont décrites ci-dessous.
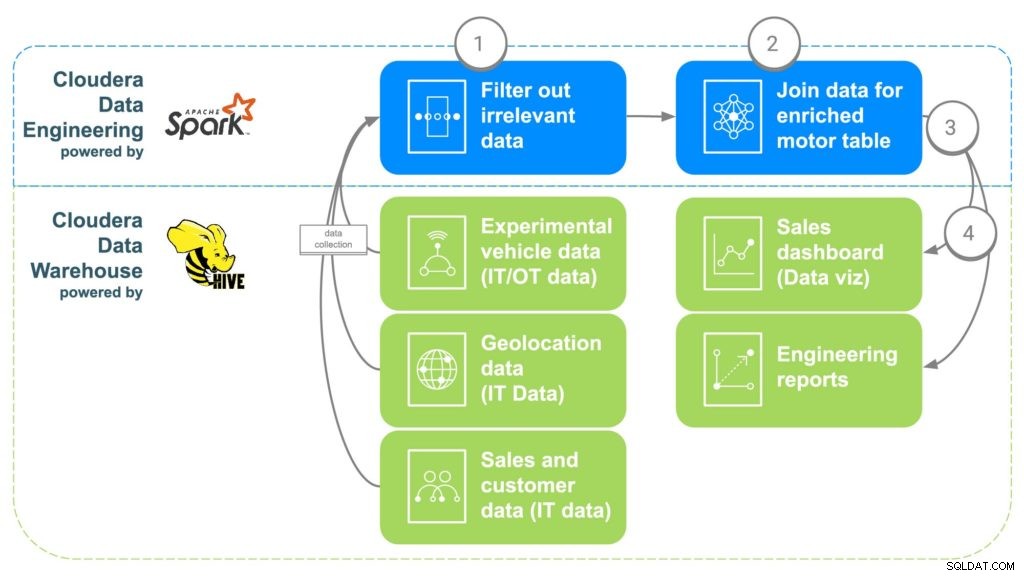
Fig. 2 Pipeline d'enrichissement des données ECC
ÉTAPE 1 :Filtrez et séparez les données
La première étape dans l'utilisation de CDE consiste à créer un travail PySpark qui fait entrer les données de ces différentes sources "brutes" de l'étape 1. C'est l'occasion de filtrer les données non pertinentes telles que les clients de moins de 16 ans par exemple, car cela est généralement l'âge minimum pour conduire. Les données en double et autres données non pertinentes peuvent également être filtrées ou séparées.
ÉTAPE 2 :Combinez les données
Afin de combiner toutes les données, CDE corrélera les liens communs entre eux. Tout d'abord, les données de vente de voitures seront liées au client qui a acheté la voiture afin d'obtenir les métadonnées du client, telles que les coordonnées, l'âge, le salaire, etc. Les données de géolocalisation seront ensuite utilisées pour obtenir des informations de localisation plus précises pour le client. , ce qui aidera à cartographier les moteurs plus tard. Les données d'installation des pièces seront utilisées pour identifier les numéros de série de chaque moteur installé dans la voiture du client. Enfin, les données d'usine seront alignées pour correspondre au numéro de série du moteur qui identifiera l'usine, la machine et la date de création de chaque moteur spécifique.
ÉTAPE 3 :Envoyer des données à Cloudera Data Warehouse
Une fois toutes les données rassemblées dans une table enrichie, une simple commande Apache Spark écrira les données dans une nouvelle table au sein de Cloudera Data Warehouse. Cela rendra les données accessibles à tous les scientifiques des données qui souhaiteraient y accéder pour effectuer des analyses supplémentaires.
ÉTAPE 4 :Générer des tableaux de bord et des rapports de visualisation des données
Avec toutes les données au même endroit, il est désormais possible de créer des rapports qui permettront aux employés de prendre des décisions plus éclairées et d'ouvrir des fonctionnalités qui n'existaient pas. Des cartes thermiques peuvent être créées pour suivre l'emplacement du moteur et corréler tout problème avec des emplacements géographiques potentiels, tels qu'une panne due à un froid ou à une chaleur extrême. Ces données pourraient également être utilisées pour suivre exactement quels clients pourraient être affectés s'il y avait un problème dans une certaine usine sur une période donnée, ce qui faciliterait le suivi des clients qui pourraient avoir besoin d'un rappel ou d'une maintenance préventive.
Conclusion
Cloudera Data Engineering permet à ECC de créer un pipeline capable de corréler les données de fabrication et de pièces, le type d'utilisation des clients, les conditions environnementales, les informations sur les ventes, etc., afin d'améliorer la satisfaction des clients et la fiabilité des véhicules. ECC a atteint ses objectifs et relevé ses défis en suivant les données liées à la fabrication de ses moteurs et en bénéficiant des manières suivantes :
- ECC a accéléré le retour sur investissement en orchestrant et en automatisant les pipelines de données pour fournir des ensembles de données de qualité organisés de manière sécurisée et transparente à partir de diverses sources de données.
- ECC a pu identifier les données pertinentes et filtrer les données redondantes et en double.
- ECC a pu assurer la surveillance du pipeline de données à partir d'un seul volet, tout en étant en mesure d'être alerté pour détecter rapidement les problèmes grâce à un dépannage visuel afin de résoudre rapidement les problèmes avant que l'activité ne soit affectée.
Recherchez le prochain blog qui se plongera dans les rapports qui montrera comment les ingénieurs ECC exécutent des requêtes ad hoc dans CDW par rapport à ces données organisées et joignent les données à d'autres sources pertinentes au sein d'un entrepôt de données d'entreprise. CDW facilite le regroupement de toutes les données et fournit un outil de visualisation de données intégré pour passer des résultats interrogés aux tableaux de bord. Restez à l'écoute pour le prochain !
Plus de ressources de collecte de données
Pour voir tout cela en action, veuillez cliquer sur les liens connexes ci-dessous pour en savoir plus sur l'enrichissement des données :
- Vidéo :si vous souhaitez voir et entendre comment cela a été construit, regardez la vidéo sur le lien.
- Tutoriels :si vous souhaitez le faire à votre propre rythme, consultez une procédure pas à pas détaillée avec des captures d'écran et des instructions ligne par ligne sur la configuration et l'exécution.
- Meetup – Si vous souhaitez parler directement avec des experts de Cloudera, veuillez rejoindre une rencontre virtuelle pour voir une présentation en direct. Il y aura du temps pour des questions-réponses directes à la fin.
- Utilisateurs – Pour voir plus de contenu technique spécifique aux utilisateurs, cliquez sur le lien.



