L'une des plus grandes préoccupations lors de la gestion et de la gestion des bases de données est la complexité de leurs données et de leur taille. Souvent, les organisations s'inquiètent de la façon de gérer la croissance et de gérer l'impact de la croissance parce que la gestion de la base de données échoue. La complexité s'accompagne de préoccupations qui n'ont pas été abordées au départ et qui n'ont pas été vues, ou qui pourraient être ignorées, car la technologie actuellement utilisée doit être capable de gérer par elle-même. La gestion d'une base de données complexe et volumineuse doit être planifiée en conséquence, en particulier lorsque le type de données que vous gérez ou manipulez devrait croître massivement, soit de manière anticipée, soit de manière imprévisible. L'objectif principal de la planification est d'éviter les catastrophes indésirables ou, dirons-nous, d'éviter de partir en fumée ! Dans ce blog, nous verrons comment gérer efficacement de grandes bases de données.
La taille des données est importante
La taille de la base de données est importante car elle a un impact sur les performances et sa méthodologie de gestion. La manière dont les données sont traitées et stockées contribuera à la manière dont la base de données sera gérée, ce qui s'applique à la fois aux données en transit et au repos. Pour de nombreuses grandes organisations, les données sont de l'or, et la croissance des données pourrait avoir un changement radical dans le processus. Par conséquent, il est essentiel d'avoir des plans préalables pour gérer les données croissantes dans une base de données.
Au cours de mon expérience de travail avec des bases de données, j'ai été témoin de problèmes rencontrés par des clients face aux pénalités de performances et à la gestion d'une croissance extrême des données. Des questions se posent s'il faut normaliser les tables ou dénormaliser les tables.
Tableaux de normalisation
La normalisation des tables préserve l'intégrité des données, réduit la redondance et facilite l'organisation des données de manière plus efficace pour gérer, analyser et extraire. L'utilisation de tables normalisées est plus efficace, en particulier lors de l'analyse du flux de données et de la récupération de données via des instructions SQL ou de l'utilisation de langages de programmation tels que les interfaces C/C++, Java, Go, Ruby, PHP ou Python avec les connecteurs MySQL.
Bien que les problèmes avec les tables normalisées entraînent une baisse des performances et peuvent ralentir les requêtes en raison d'une série de jointures lors de la récupération des données. Alors que les tables dénormalisées, tout ce que vous devez prendre en compte pour l'optimisation repose sur l'index ou la clé primaire pour stocker les données dans la mémoire tampon pour une récupération plus rapide que d'effectuer des recherches sur plusieurs disques. Les tables dénormalisées ne nécessitent aucune jointure, mais elles sacrifient l'intégrité des données et la taille de la base de données tend à devenir de plus en plus grande.
Lorsque votre base de données est volumineuse, envisagez d'avoir un DDL (Data Definition Language) pour votre table de base de données dans MySQL/MariaDB. L'ajout d'une clé primaire ou unique pour votre table nécessite une reconstruction de la table. La modification d'un type de données de colonne nécessite également une reconstruction de table car l'algorithme applicable à appliquer est uniquement ALGORITHM=COPY.
Si vous faites cela dans votre environnement de production, cela peut être difficile. Doublez le défi si votre table est immense. Imaginez un million ou un milliard de nombres de lignes. Vous ne pouvez pas appliquer une instruction ALTER TABLE directement à votre table. Cela peut bloquer tout le trafic entrant qui devra accéder à la table où vous appliquez actuellement le DDL. Cependant, cela peut être atténué en utilisant pt-online-schema-change ou le grand gh-ost. Néanmoins, il nécessite une surveillance et une maintenance tout en effectuant le processus de DDL.
Sharding et partitionnement
Avec le sharding et le partitionnement, il permet de séparer ou de segmenter les données en fonction de leur identité logique. Par exemple, en séparant en fonction de la date, de l'ordre alphabétique, du pays, de l'état ou de la clé primaire en fonction de la plage donnée. Cela aide la taille de votre base de données à être gérable. Maintenez la taille de votre base de données à sa limite afin qu'elle soit gérable par votre organisation et votre équipe. Facile à mettre à l'échelle si nécessaire ou facile à gérer, en particulier en cas de sinistre.
Lorsque nous disons gérable, tenez également compte des ressources de capacité de votre serveur ainsi que de votre équipe d'ingénieurs. Vous ne pouvez pas travailler avec des données volumineuses et volumineuses avec peu d'ingénieurs. Travailler avec des données volumineuses telles que 1000 bases de données avec un grand nombre d'ensembles de données nécessite une énorme demande de temps. La compétence et l'expertise sont indispensables. Si le coût est un problème, c'est le moment où vous pouvez tirer parti des services tiers qui offrent des services gérés ou une consultation ou une assistance payante pour tout travail d'ingénierie de ce type à prendre en charge.
Jeux de caractères et classement
Les jeux de caractères et les classements affectent le stockage et les performances des données, en particulier sur le jeu de caractères donné et les classements sélectionnés. Chaque jeu de caractères et collations a son objectif et nécessite généralement des longueurs différentes. Si vous avez des tables nécessitant d'autres jeux de caractères et classements en raison de l'encodage des caractères, les données à stocker et à traiter pour votre base de données et vos tables ou même avec des colonnes.
Cela affecte la façon de gérer efficacement votre base de données. Cela a un impact sur votre stockage de données et sur les performances, comme indiqué précédemment. Si vous avez compris les types de caractères à traiter par votre application, notez le jeu de caractères et les classements à utiliser. Les jeux de caractères de type LATIN suffiront principalement pour le type de caractères alphanumériques à stocker et à traiter.
Si c'est inévitable, le partitionnement et le partitionnement permettent au moins d'atténuer et de limiter les données pour éviter de gonfler trop de données dans votre serveur de base de données. La gestion de données très volumineuses sur un seul serveur de base de données peut affecter l'efficacité, en particulier à des fins de sauvegarde, de sinistre et de récupération, ou de récupération de données en cas de corruption ou de perte de données.
La complexité de la base de données affecte les performances
Une base de données volumineuse et complexe a tendance à avoir un facteur lorsqu'il s'agit de pénalité de performance. Complexe, dans ce cas, signifie que le contenu de votre base de données se compose d'équations mathématiques, de coordonnées ou d'enregistrements numériques et financiers. Mélangez maintenant ces enregistrements avec des requêtes qui utilisent de manière agressive les fonctions mathématiques natives de sa base de données. Jetez un œil à l'exemple de requête SQL (compatible MySQL/MariaDB) ci-dessous,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Considérez que cette requête est appliquée sur une table allant d'un million de lignes. Il y a une énorme possibilité que cela puisse bloquer le serveur, et cela pourrait être gourmand en ressources, ce qui pourrait mettre en danger la stabilité de votre cluster de base de données de production. Les colonnes impliquées ont tendance à être indexées pour optimiser et rendre cette requête performante. Cependant, l'ajout d'index aux colonnes référencées pour des performances optimales ne garantit pas l'efficacité de la gestion de vos grandes bases de données.
Lorsque vous gérez la complexité, le moyen le plus efficace consiste à éviter l'utilisation rigoureuse d'équations mathématiques complexes et l'utilisation agressive de cette capacité de calcul complexe intégrée. Cela peut être exploité et transporté à travers des calculs complexes à l'aide de langages de programmation principaux au lieu d'utiliser la base de données. Si vous avez des calculs complexes, alors pourquoi ne pas stocker ces équations dans la base de données, récupérer les requêtes, les organiser de manière plus facile à analyser ou déboguer en cas de besoin.
Utilisez-vous le bon moteur de base de données ?
Une structure de données affecte les performances du serveur de base de données en fonction de la combinaison de la requête donnée et des enregistrements lus ou extraits de la table. Les moteurs de base de données de MySQL/MariaDB prennent en charge InnoDB et MyISAM qui utilisent des arbres B, tandis que les moteurs de base de données NDB ou Memory utilisent Hash Mapping. Ces structures de données ont sa notation asymptotique qui exprime les performances des algorithmes utilisés par ces structures de données. Nous les appelons en informatique la notation Big O qui décrit les performances ou la complexité d'un algorithme. Étant donné qu'InnoDB et MyISAM utilisent des arbres B, il utilise O (log n) pour la recherche. Alors que les tables de hachage ou les cartes de hachage utilisent O(n). Les deux partagent le cas moyen et le pire pour ses performances avec sa notation.
Revenons maintenant au moteur spécifique, compte tenu de la structure de données du moteur, la requête à appliquer en fonction des données cibles à récupérer affecte bien sûr les performances de votre serveur de base de données. Les tables de hachage ne peuvent pas effectuer de récupération de plage, alors que B-Trees est très efficace pour effectuer ces types de recherches et peut également gérer de grandes quantités de données.
En utilisant le bon moteur pour les données que vous stockez, vous devez identifier le type de requête que vous appliquez pour ces données spécifiques que vous stockez. Quel type de logique ces données doivent-elles formuler lorsqu'elles se transforment en une logique métier.
Traiter des milliers ou des milliers de bases de données, utiliser le bon moteur en combinaison de vos requêtes et des données que vous souhaitez récupérer et stocker fournira de bonnes performances. Étant donné que vous avez prédéterminé et analysé vos besoins pour son objectif pour le bon environnement de base de données.
Les bons outils pour gérer de grandes bases de données
Il est très difficile et difficile de gérer une très grande base de données sans une plate-forme solide sur laquelle vous pouvez compter. Même avec des ingénieurs de base de données bons et compétents, techniquement, le serveur de base de données que vous utilisez est sujet aux erreurs humaines. Une erreur de modification de vos paramètres et variables de configuration peut entraîner un changement radical entraînant une dégradation des performances du serveur.
L'exécution d'une sauvegarde de votre base de données sur une très grande base de données peut parfois être difficile. Il arrive que la sauvegarde échoue pour des raisons étranges. Généralement, les requêtes susceptibles de bloquer le serveur sur lequel la sauvegarde est en cours d'exécution échouent. Sinon, vous devez en rechercher la cause.
L'utilisation d'automatisations telles que Chef, Puppet, Ansible, Terraform ou SaltStack peut être utilisée comme votre IaC pour fournir des tâches plus rapides à effectuer. Tout en utilisant d'autres outils tiers également pour vous aider à surveiller et à fournir des images graphiques de haute qualité. Les systèmes d'alerte et de notification d'alarme sont également très importants pour vous informer des problèmes pouvant survenir, du niveau d'avertissement au niveau d'état critique. C'est là que ClusterControl est très utile dans ce genre de situation.
ClusterControl permet de gérer facilement un grand nombre de bases de données ou même avec des types d'environnements fragmentés. Il a été testé et installé des milliers de fois et a fonctionné dans des productions fournissant des alarmes et des notifications aux administrateurs de base de données, aux ingénieurs ou aux DevOps exploitant l'environnement de base de données. Qu'il s'agisse de la préparation ou du développement, des contrôles qualité ou de l'environnement de production.
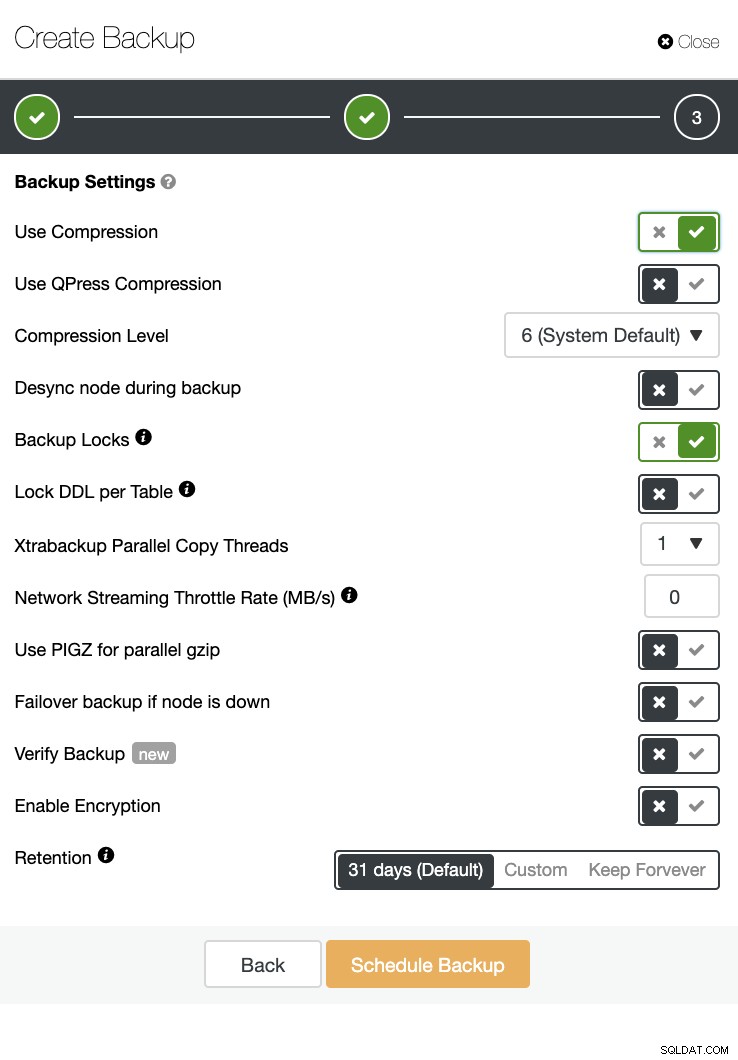
ClusterControl peut également effectuer une sauvegarde et une restauration. Même avec de grandes bases de données, il peut être efficace et facile à gérer puisque l'interface utilisateur fournit une planification et dispose également d'options pour le télécharger sur le cloud (AWS, Google Cloud et Azure).
Il existe également une vérification de sauvegarde et de nombreuses options telles que le cryptage et la compression. Voir la capture d'écran ci-dessous par exemple (création d'une sauvegarde pour MySQL à l'aide de Xtrabackup) :
Conclusion
Gérer de grandes bases de données comme un millier ou plus peut être fait efficacement, mais cela doit être déterminé et préparé à l'avance. L'utilisation des bons outils tels que l'automatisation ou même l'abonnement à des services gérés aide considérablement. Bien que cela entraîne des coûts, le délai d'exécution du service et le budget à verser pour acquérir des ingénieurs qualifiés peuvent être réduits tant que les bons outils sont disponibles.



