MongoDB est un magasin de données de documents qui existe depuis plus d'une décennie. Au cours des dernières années, MongoDB est devenu un produit mature qui propose des options de niveau entreprise telles que l'évolutivité, la sécurité et la résilience. Cependant, avec le mouvement exigeant des nuages, cela ne suffisait pas.
Les ressources cloud, telles que les machines virtuelles, les conteneurs, les ressources de calcul sans serveur et les bases de données sont actuellement très demandées. De nos jours, de nombreuses solutions logicielles peuvent être lancées en une fraction du temps qu'il fallait auparavant pour se déployer sur son propre matériel. Cela a lancé une tendance et changé les attentes des marchés en même temps.
Mais la qualité d'un service en ligne ne se limite pas au seul déploiement. Les utilisateurs ont souvent besoin de services supplémentaires, d'intégrations ou de fonctionnalités supplémentaires qui les aident à faire leur travail. Les offres cloud peuvent encore être très limitées et peuvent causer plus de problèmes que ce que vous pouvez gagner de l'automatisation et de l'infrastructure à distance.
Alors, quelle est l'approche de MongoDB Inc. pour ce problème courant ?
La réponse était MongoDB Atlas, qui apporte des extensions internes dans le cadre d'une plus grande plate-forme cloud/d'automatisation. Avec l'ajout de composants tiers, MongoDB a prospéré. Dans le blog d'aujourd'hui, nous allons voir ce qu'ils ont développé et comment cela peut vous aider à répondre à vos besoins en matière de traitement de données.
Les éléments que nous allons explorer aujourd'hui sont...
- Graphiques MongoDB
- Point MongoDB
- Intégrations MongoDB Kubernetes avec Ops Manager
- Migration MongoDB Cloud
- Recherche en texte intégral
- MongoDB Data Lake (bêta)
Graphiques MongoDB
MongoDB Charts est l'un des services accessibles via la plateforme MongoDB Atlas. Il fournit simplement un moyen simple de visualiser vos données vivant dans MongoDB. Vous n'avez pas besoin de déplacer vos données vers un autre référentiel ou d'écrire votre propre code car MongoDB Charts a été conçu pour fonctionner avec des documents de données et faciliter la visualisation de vos données.
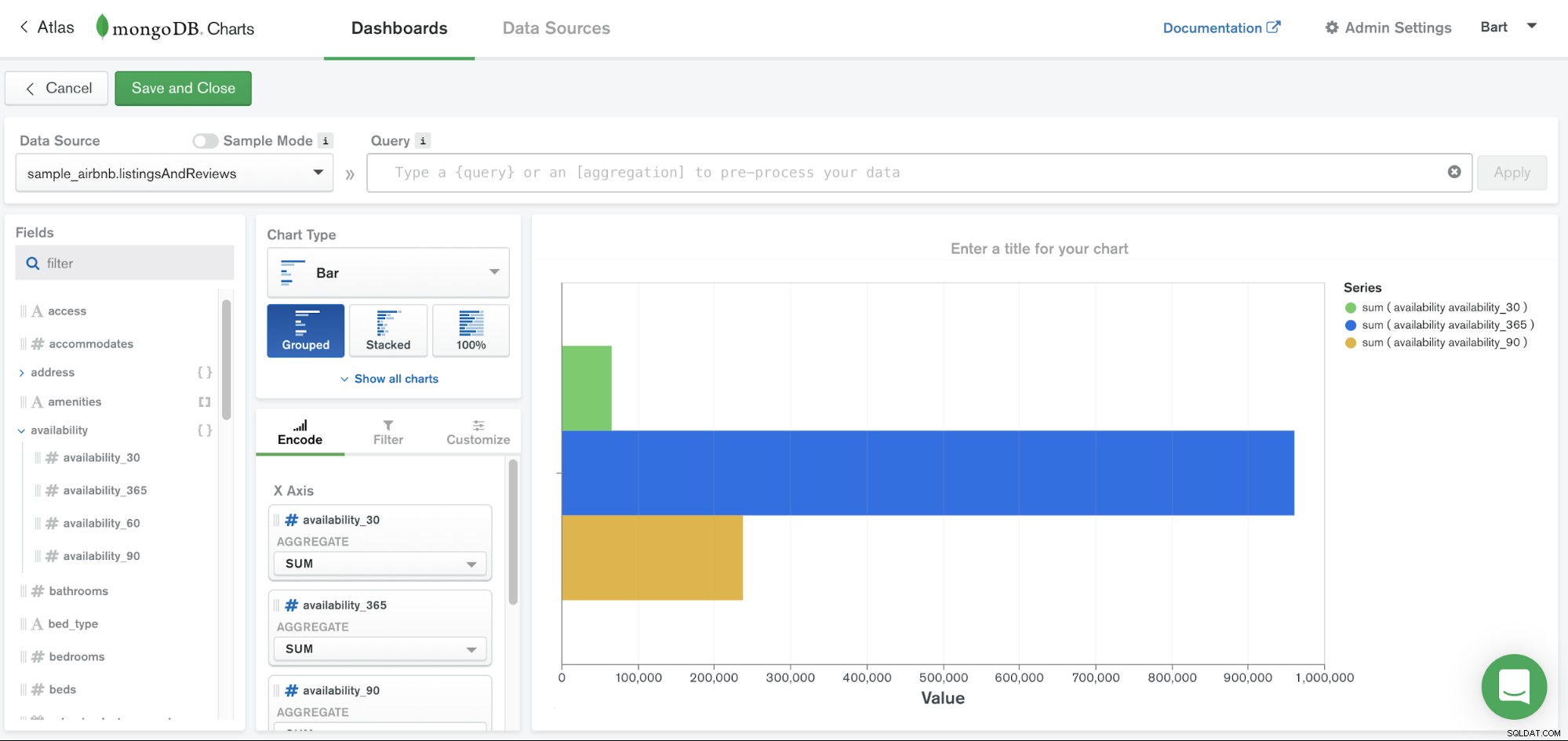
MongoDB Charts facilite la communication de vos données en fournissant des outils intégrés pour partager et collaborer facilement sur des visualisations. La visualisation des données est un élément clé pour fournir une compréhension claire de vos données, mettre en évidence les corrélations entre les variables et faciliter la discernement des modèles et des tendances au sein de votre ensemble de données.
Voici quelques fonctionnalités clés que vous pouvez utiliser dans les graphiques.
Agrégation
Le cadre d'agrégation est un processus opérationnel qui manipule des documents à différentes étapes, les traite conformément aux critères fournis, puis renvoie les résultats calculés. Les valeurs de plusieurs documents sont regroupées, sur lesquelles d'autres opérations peuvent être effectuées pour renvoyer des résultats correspondants.
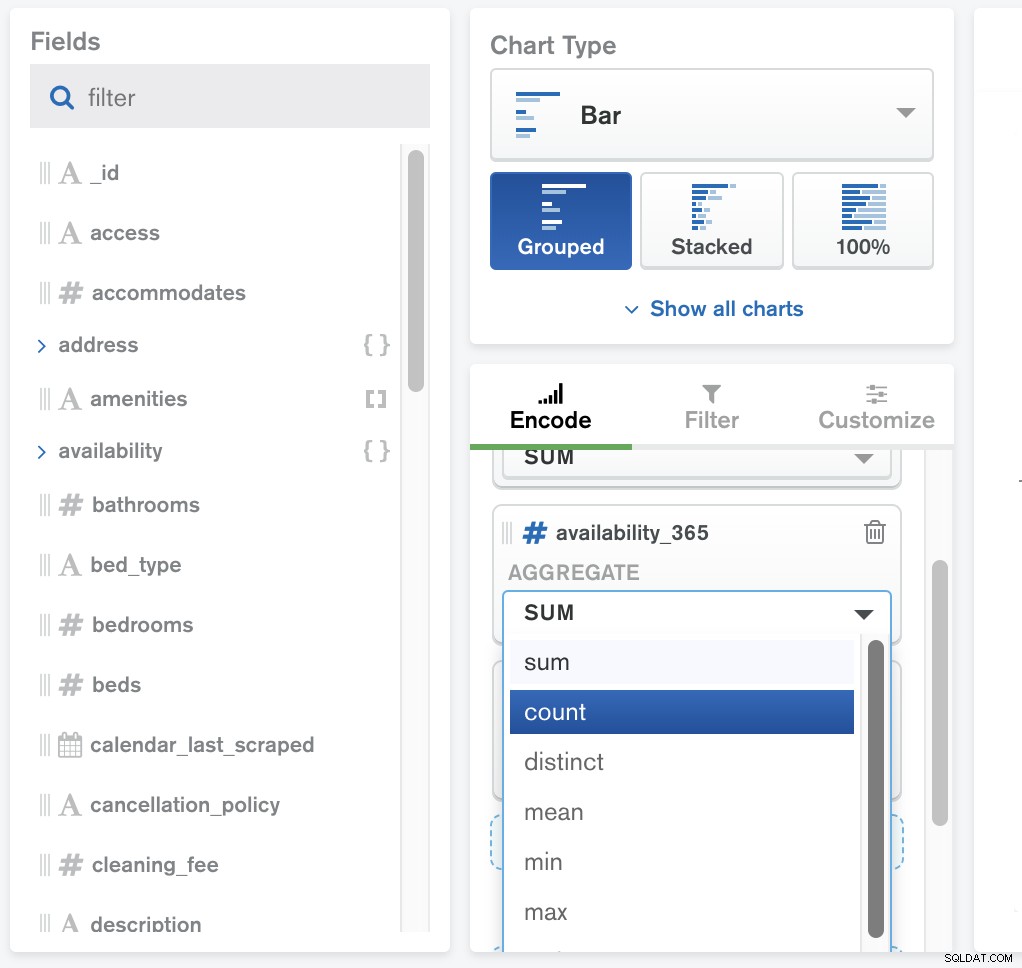
MongoDB Charts fournit une fonctionnalité d'agrégation intégrée. L'agrégation vous permet de traiter vos données de collecte selon une variété de mesures et d'effectuer des calculs tels que la moyenne et l'écart type.
Les graphiques offrent une intégration transparente avec MongoDB Atlas. Vous pouvez lier les graphiques MongoDB aux projets Atlas et commencer rapidement à visualiser les données de votre cluster Atlas.
Gestion des données du document
MongoDB Charts comprend nativement les avantages du modèle de données de document. Il gère les données basées sur des documents, y compris les objets fixes et les tableaux. L'utilisation d'une structure de données imbriquée offre la flexibilité de structurer vos données en fonction de votre application tout en conservant les capacités de visualisation.
MongoDB Charts fournit une fonctionnalité d'agrégation intégrée qui vous permet de traiter vos données de collecte en utilisant une variété de métriques. Il est suffisamment intuitif pour être utilisé par des non-développeurs, permettant une analyse de données en libre-service, ce qui en fait un excellent outil pour les équipes d'analyse de données.
Point MongoDB
Avez-vous entendu parler de l'architecture sans serveur ?
Avec Serverless, vous composez votre application en fonctions individuelles et autonomes. Chaque fonction est hébergée par le fournisseur sans serveur et peut être mise à l'échelle automatiquement à mesure que la fréquence des appels de fonction augmente ou diminue. Cela s'avère être un moyen très rentable de payer les ressources informatiques. Vous ne payez que les fois où vos fonctions sont appelées, plutôt que de payer pour que votre application soit toujours active et attende des demandes sur autant d'instances différentes.
MongoDB Stitch est un autre type de service MongoDB qui ne prend que ce qui est le plus utile dans les environnements d'infrastructure cloud. Il s'agit d'une plate-forme sans serveur qui permet aux développeurs de créer des applications sans avoir à configurer une infrastructure de serveur. Stitch est réalisé sur MongoDB Atlas, intégrant automatiquement la connexion à votre base de données. Vous pouvez vous connecter à Stitch via les SDK Stitch Client, qui sont ouverts pour de nombreuses plates-formes que vous développez.
Intégrations MongoDB Kubernetes avec Ops Manager
Ops Manager est une plateforme de gestion pour les clusters MongoDB que vous exécutez sur votre propre infrastructure. Les capacités d'Ops Manager incluent la surveillance, l'alerte, la reprise après sinistre, la mise à l'échelle, le déploiement et la mise à niveau des ensembles de répliques et des clusters fragmentés, ainsi que d'autres produits MongoDB. En 2018, MongoDB a introduit l'intégration bêta avec Kubernetes.
MongoDB Enterprise Operator est compatible avec Kubernetes v1.11 et supérieur. Il a été testé avec Openshift 3.11. Cet opérateur nécessite Ops Manager ou Cloud Manager. Dans ce document, lorsque nous faisons référence à "Ops Manager", vous pouvez remplacer "Cloud Manager". La fonctionnalité est la même.
L'installation est assez simple et nécessite
- Installation de l'opérateur MongoDB Enterprise. Cela peut être fait via helm ou un fichier YAML.
- Rassemblez les propriétés d'Ops Manager.
- Créer et appliquer un fichier Kubernetes ConfigMap
- Créez l'objet secret Kubernetes qui stockera la clé d'API Ops Manager
Dans cet exemple de base, nous allons utiliser le fichier YAML :
kubectl apply -f crds.yaml
kubectl apply -f https://raw.githubusercontent.com/mongodb/mongodb-enterprise-kubernetes/master/mongodb-enterprise.yamlL'étape suivante consiste à obtenir les informations suivantes que nous allons utiliser dans le fichier ConfigMap. Tout cela se trouve dans le gestionnaire d'opérations.
- URL de base. L'URL de base est l'URL de votre gestionnaire d'opérations ou de votre gestionnaire de cloud.
- Identifiant du projet. ID d'un projet Ops Manager dans lequel l'opérateur Kubernetes se déploiera.
- Utilisateur. Un nom d'utilisateur Ops Manager existant
- Clé d'API publique. Utilisé par l'opérateur Kubernetes pour se connecter au point de terminaison de l'API REST Ops Manager
Maintenant que nous avons acquis les informations de configuration Ops Manager nécessaires, nous devons créer un fichier Kubernetes ConfigMap pour Kubernetes. À des fins d'exercice, nous pouvons appeler ce fichier project.yaml.
apiVersion: v1
kind: ConfigMap
metadata:
name:<<Name>>
namespace: mongodb
data:
projectId:<<Project ID>>
baseUrl: <<OpsManager URL>>L'étape suivante consiste à créer ConfigMap sur Kubernetes et le fichier secret
kubectl apply -f my-project.yaml
kubectl -n mongodb create secret generic <<Name of credentials>> --from-literal="user=<<User>>" --from-literal="publicApiKey=<<public-api-key>>"Une fois que nous l'avons, nous pouvons déployer notre premier cluster
apiVersion: mongodb.com/v1
kind: MongoDbReplicaSet
metadata:
name: <<Replica set name>>
namespace: mongodb
spec:
members: 3
version: 4.2.0
persistent: false
project: <<Name value specified in metadata.name of ConfigMap file>>
credentials: <<Name of credentials secret>>Pour des instructions plus détaillées, veuillez consulter la documentation MongoDB.
Migration MongoDB Cloud
Le service Atlas Live Migration peut migrer vos données depuis votre environnement existant, qu'il soit sur AWS, Azure, GCP ou sur site, vers MongoDB Atlas, la base de données cloud mondiale pour MongoDB.
La migration se fait via un service de réplication dédié. Le processus Atlas Live Migration diffuse les données via un serveur d'applications contrôlé par MongoDB.
La migration en direct fonctionne en gardant un cluster dans MongoDB Atlas synchronisé avec votre base de données source. Au cours de ce processus, votre application peut continuer à lire et à écrire à partir de votre base de données source. Étant donné que le processus surveille les modifications à venir, tout sera répliqué et la migration peut être effectuée en ligne. Vous décidez quand modifier le paramètre de connexion de l'application et effectuer le basculement. Pour rendre le processus moins enclin, Atlas fournit l'option Valider qui vérifie l'accès IP de la liste blanche, la configuration SSL, l'autorité de certification, etc.
Recherche en texte intégral
La recherche en texte intégral est un autre service cloud fourni par MongoDB et n'est disponible que dans MongoDB Atlas. Les déploiements MongoDB non-Atlas peuvent utiliser l'indexation de texte. Atlas Full-Text Search est construit sur Open Source Apache Lucene. Lucene est une puissante bibliothèque de recherche de texte. Lucene a une syntaxe de requête personnalisée pour interroger ses index. C'est une base de systèmes populaires tels que Elasticsearch et Apache Solr. Il permet de créer un index pour la recherche en texte intégral, c'est la recherche, la sauvegarde et la lecture. Il est entièrement intégré à Atlas MongoDB, il n'y a donc aucun système ou infrastructure supplémentaire à provisionner ou à gérer.
MongoDB Data Lake (bêta)
La dernière fonctionnalité cloud de MongoDB que nous aimerions mentionner dans MongoDB Data Lake. C'est un service relativement nouveau qui aborde le concept populaire des lacs de données. Un lac de données est un vaste réservoir de données brutes dont la finalité n'est pas encore définie. Au lieu de placer les données dans un magasin de données spécialement conçu à cet effet, vous les déplacez dans un lac de données dans son format d'origine. Cela élimine les coûts initiaux de l'ingestion de données, comme la transformation. Une fois les données placées dans le.
L'utilisation d'Atlas Data Lake pour ingérer vos données S3 dans les clusters Atlas vous permet d'interroger les données stockées dans vos compartiments AWS S3 à l'aide de Mongo Shell, de MongoDB Compass et de n'importe quel pilote MongoDB.
Il y a cependant quelques limitations. Les fonctionnalités suivantes ne fonctionnent pas encore comme la surveillance des lacs de données avec les outils de surveillance Atlas, la prise en charge d'un seul compte AWS S3, la liste blanche d'adresses IP et les limitations des comptes AWS et des groupes de sécurité AWS ou l'absence de possibilité d'ajouter des index.



