Dans notre précédent Tut Hadoop o rial , nous vous avons fourni une description détaillée de InputFormat. Maintenant, dans ce blog, nous allons couvrir le Hadoop OutputFormat.
Nous discuterons de Qu'est-ce que OutputFormat dans Hadoop, Qu'est-ce que RecordWritter dans MapReduce OutputFormat. Nous couvrirons également les types de OutputFormat dans MapReduce.
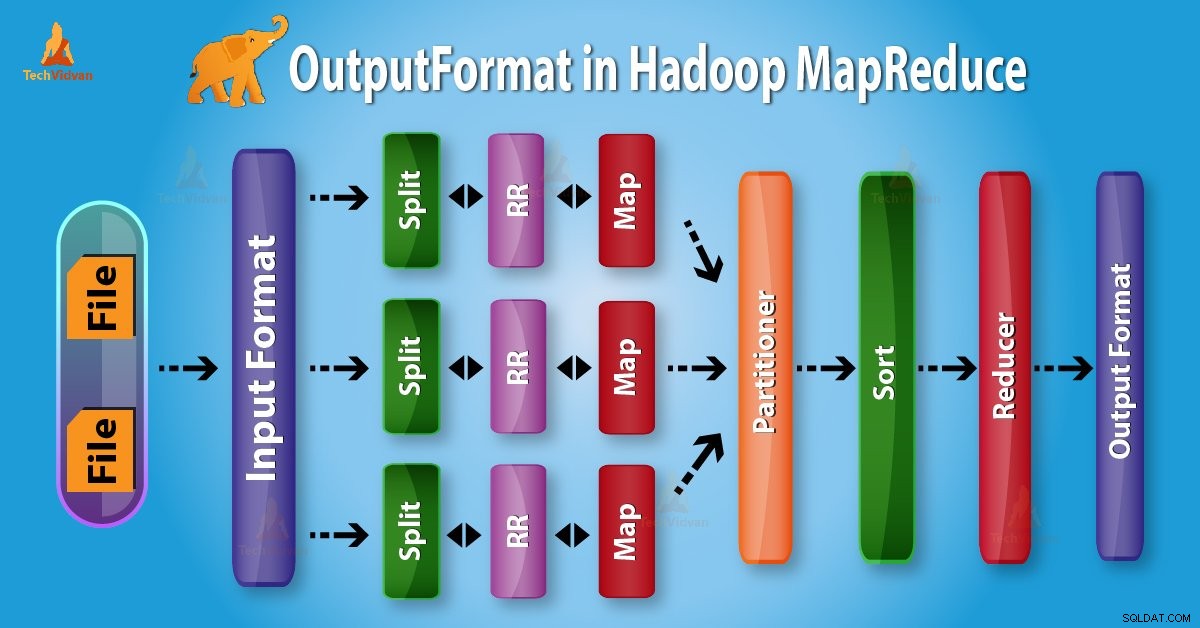
Introduction au format de sortie Hadoop
Format de sortie vérifiez la spécification de sortie pour l'exécution de la tâche Map-Reduce. Il décrit comment l'implémentation de RecordWriter est utilisée pour écrire la sortie dans les fichiers de sortie.
Avant de commencer avec OutputFormat, apprenons d'abord ce qu'est RecordWriter et quel est le travail de RecordWriter dans MapReduce ?
1. RecordWriter dans Hadoop MapReduce
Comme nous le savons, Réducteur prend Mappeurs sortie intermédiaire comme entrée. Ensuite, il exécute une fonction de réduction sur eux pour générer une sortie qui est à nouveau zéro ou plusieurs paires clé-valeur.
Ainsi, RecordWriter dans l'exécution de la tâche MapReduce écrit ces paires clé-valeur de sortie de la phase Reducer dans les fichiers de sortie.
2. Format de sortie Hadoop
D'en haut, il est clair que RecordWriter prend les données de sortie de Reducer. Ensuite, il écrit ces données dans les fichiers de sortie. OutputFormat détermine la manière dont ces paires clé-valeur de sortie sont écrites dans les fichiers de sortie par RecordWriter.
Les fonctions OutputFormat et InputFormat sont similaires. Les instances OutputFormat sont utilisées pour écrire dans des fichiers sur le disque local ou dans HDFS. Dans l'exécution de la tâche MapReduce sur la base de la spécification de sortie ;
- La tâche Hadoop MapReduce vérifie que le répertoire de sortie n'est pas déjà présent.
- OutputFormat dans le travail MapReduce fournit l'implémentation RecordWriter à utiliser pour écrire les fichiers de sortie du travail. Ensuite, les fichiers de sortie sont stockés dans un FileSystem.
Le framework utilise FileOutputFormat.setOutputPath() méthode pour définir le répertoire de sortie.
Types de format de sortie dans MapReduce
Il existe différents types de OutputFormat qui sont les suivants :
1. Format de sortie de texte
Le OutputFormat par défaut est TextOutputFormat. Il écrit des paires (clé, valeur) sur des lignes individuelles de fichiers texte. Ses clés et ses valeurs peuvent être de n'importe quel type. La raison en est que TextOutputFormat les transforme en chaîne en appelant toString() sur eux.
Il sépare la paire clé-valeur par un caractère de tabulation. En utilisant MapReduce.output.textoutputformat.separator propriété, nous pouvons également la modifier.
KeyValueTextOutputFormat est également utilisé pour lire ces fichiers texte de sortie.
2. SequenceFileOutputFormat
Ce OutputFormat écrit des fichiers de séquences pour sa sortie. SequenceFileInputFormat est également un format intermédiaire utilisé entre les tâches MapReduce. Il sérialise des types de données arbitraires dans le fichier.
Et le SequenceFileInputFormat correspondant désérialisera le fichier dans les mêmes types. Il présente les données au prochainmappeur de la même manière qu'il était émis par le réducteur précédent. Les méthodes statiques contrôlent également la compression.
3. SequenceFileAsBinaryOutputFormat
C'est une autre variante de SequenceFileInputFormat. Il écrit également des clés et des valeurs dans un fichier de séquence au format binaire.
4. MapFileOutputFormat
C'est une autre forme de FileOutputFormat. Il écrit également la sortie sous forme de fichiers de carte. Le framework ajoute une clé dans un MapFile dans l'ordre. Nous devons donc nous assurer que le réducteur émet des clés dans un ordre trié.
5. Sorties Multiples
Ce format permet d'écrire des données dans des fichiers dont les noms sont dérivés des clés et des valeurs de sortie.
6. LazyOutputFormat
Lors de l'exécution d'une tâche MapReduce, FileOutputFormat crée parfois des fichiers de sortie, même s'ils sont vides. LazyOutputFormat est également un wrapper OutputFormat.
7. DBOutputFormat
Il s'agit de l'OutputFormat pour l'écriture dans les bases de données relationnelles et HBase. Ce format envoie également la sortie de réduction à une table SQL. Il accepte également les paires clé-valeur. En cela, la clé a un type étendant DBwritable.
Conclusion
Par conséquent, différents OutputFormats sont utilisés en fonction des besoins. J'espère que vous trouverez ce blog utile. Si vous avez des questions sur Hadoop OutputFormat, veuillez laisser un commentaire dans une zone de commentaire. Nous serons heureux de les résoudre.



