Ce tutoriel Hadoop est tout au sujet du brassage et du tri MapReduce. Ici, nous vous fournirons une description détaillée de la phase Hadoop Shuffling and Sorting.
Tout d'abord, nous discuterons de ce qu'est MapReduce Shuffling, puis de MapReduce Sorting, puis nous aborderons en détail la phase de tri secondaire de MapReduce.
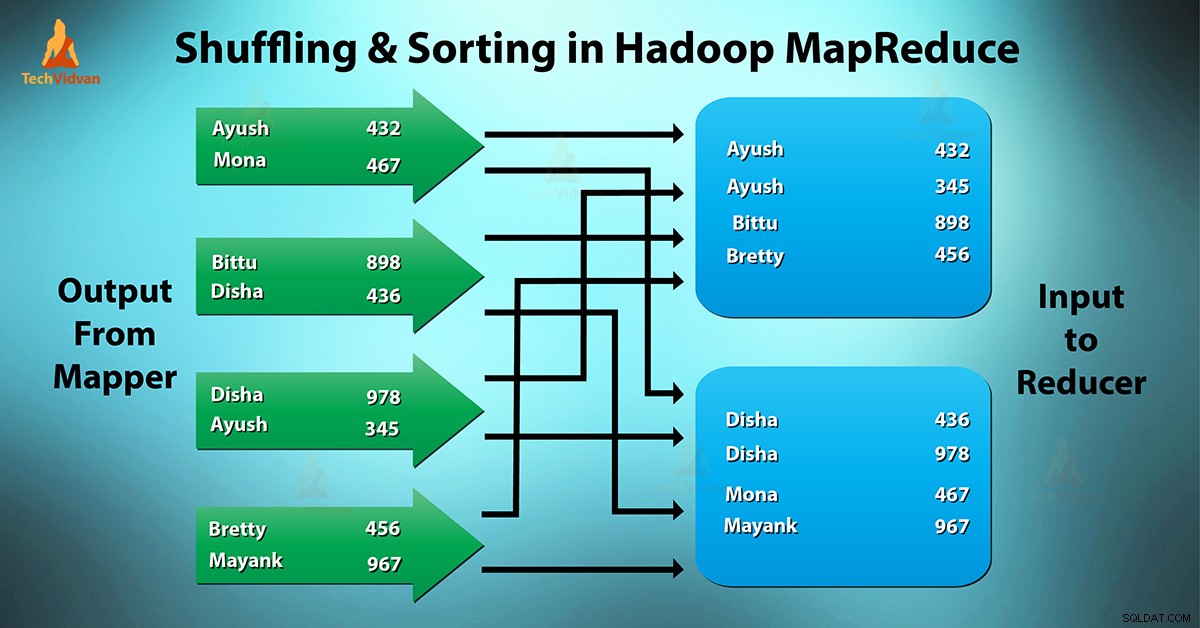
Qu'est-ce que le brassage et le tri MapReduce ?
Mélange est le processus par lequel il transfère les mappers sortie intermédiaire vers le réducteur. Le réducteur obtient 1 ou plusieurs clés et les valeurs associées sur la base des réducteurs.
La clé intermédiaire - la valeur générée par le mappeur est triée automatiquement par clé. Dans la phase de tri, la fusion et le tri de la sortie de la carte ont lieu.
Le brassage et le tri dans Hadoop se produisent simultanément.
Mélange dans MapReduce
Le processus de transfert des données des mappeurs vers les réducteurs est chaotique. C'est également le processus par lequel le système effectue le tri. Ensuite, il transfère la sortie de la carte au réducteur en tant qu'entrée. C'est la raison pour laquelle la phase de shuffle est nécessaire pour les réducteurs.
Sinon, ils n'auraient aucune entrée (ou entrée de chaque mappeur). Étant donné que le mélange peut commencer avant même la fin de la phase de carte. Cela permet donc de gagner du temps et de terminer les tâches en moins de temps.
Trier dans MapReduce
MapReduce Framework trie automatiquement les clés générées par le mappeur. Ainsi, avant le démarrage du réducteur, toutes les paires clé-valeur intermédiaires sont triées par clé et non par valeur. Il ne trie pas les valeurs transmises à chaque réducteur. Ils peuvent être dans n'importe quel ordre.
Le tri dans une tâche MapReduce aide le réducteur à distinguer facilement quand une nouvelle tâche de réduction doit commencer.
Cela fait gagner du temps au réducteur. Le réducteur dans MapReduce démarre une nouvelle tâche de réduction lorsque la clé suivante dans les données d'entrée triées est différente de la précédente. Chaque tâche de réduction prend des paires clé-valeur en entrée et génère une paire clé-valeur en sortie.
La chose importante à noter est que le mélange et le tri dans Hadoop MapReduce n'auront pas lieu du tout si vous spécifiez zéro réducteur (setNumReduceTasks(0)).
Si reducer est égal à zéro, la tâche MapReduce s'arrête à la phase de mappage. Et la phase de carte n'inclut aucun type de tri (même la phase de carte est plus rapide).
Tri secondaire dans MapReduce
Si nous voulons trier les valeurs des réducteurs, nous utilisons une technique de tri secondaire. Cette technique nous permet de trier les valeurs (par ordre croissant ou décroissant) passées à chaque réducteur.
Conclusion
En conclusion, MapReduce Shuffling and Sorting se produit simultanément pour résumer la sortie intermédiaire de Mapper. Hadoop Shuffling-Sorting n'aura pas lieu si vous spécifiez zéro réducteur (setNumReduceTasks (0)).
Framework trie toutes les paires clé-valeur intermédiaires par clé, et non par valeur. Il utilise le tri secondaire pour trier par valeur. Si vous avez des suggestions ou des questions concernant la phase de mélange et de tri de MapReduce, veuillez laisser un commentaire dans une boîte de commentaires.
Nous serons heureux de les résoudre.



