L'objectif principal de ce tutoriel Hadoop est de vous fournir une description détaillée de chaque composant utilisé dans le fonctionnement d'Hadoop. Dans ce didacticiel, nous allons couvrir le partitionneur dans Hadoop.
Qu'est-ce que Hadoop Partitioner, quel est le besoin de Partitioner dans Hadoop, Quel est le partitionneur par défaut dans MapReduce, Combien de MapReduce Partitioner sont utilisés dans Hadoop ?
Nous répondrons à toutes ces questions dans ce tutoriel MapReduce.
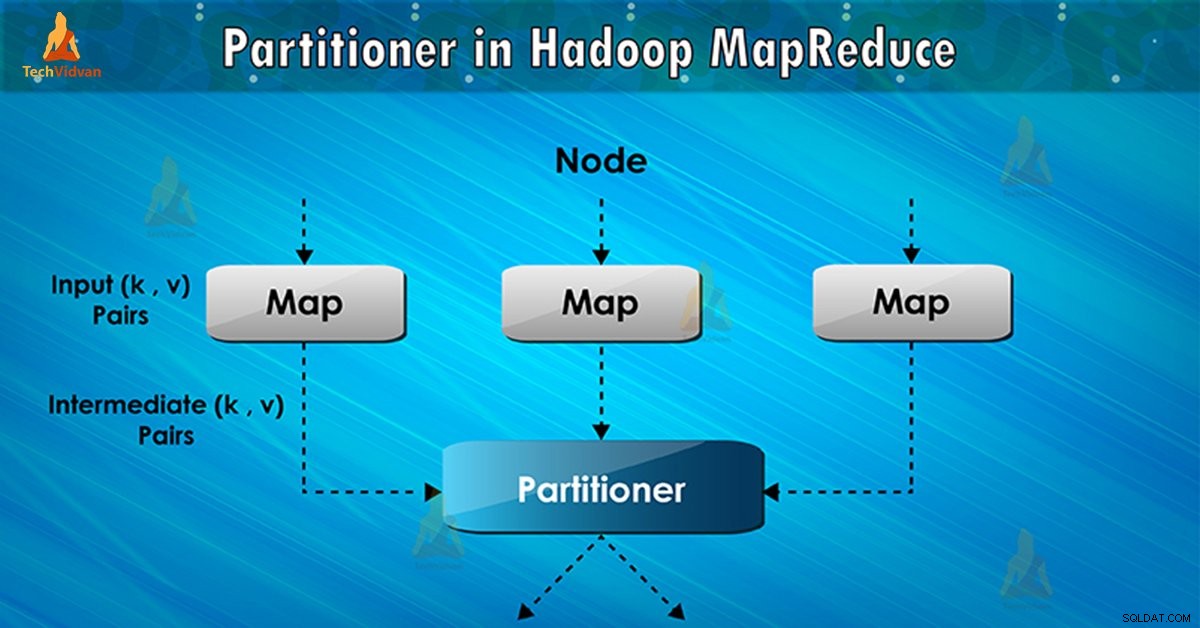
Qu'est-ce que le partitionneur Hadoop ?
Le partitionneur dans l'exécution de la tâche MapReduce contrôle le partitionnement des clés des sorties de carte intermédiaires. À l'aide de la fonction de hachage, la clé (ou un sous-ensemble de la clé) dérive la partition. Le nombre total de partitions est égal au nombre de tâches de réduction.
Sur la base de la valeur clé , partitions de framework, chaquemappeur production. Les enregistrements ayant la même valeur de clé vont dans la même partition (au sein de chaque mappeur). Ensuite, chaque partition est envoyée à un réducteur .
La classe de partition décide à quelle partition une paire donnée (clé, valeur) ira. La phase de partition dans le flux de données MapReduce a lieu après la phase de carte et avant la phase de réduction.
Besoin de MapReduce Partitioner dans Hadoop
Dans l'exécution de la tâche MapReduce, il prend un ensemble de données d'entrée et produit la liste des paires clé-valeur. Cette paire clé-valeur est le résultat de la phase de carte. Dans lequel les données d'entrée sont divisées et chaque tâche traite la division et chaque carte, génère la liste des paires de valeurs clés.
Ensuite, le framework envoie la sortie de la carte pour réduire la tâche. Réduire traite la fonction de réduction définie par l'utilisateur sur les sorties de carte. Avant la phase de réduction, le partitionnement de la sortie de la carte a lieu sur la base de la clé.
Le partitionnement Hadoop spécifie que toutes les valeurs de chaque clé sont regroupées. Il s'assure également que toutes les valeurs d'une seule clé vont au même réducteur. Cela permet une distribution uniforme de la sortie de la carte sur le réducteur.
Le partitionneur dans une tâche MapReduce redirige la sortie du mappeur vers le réducteur en déterminant quel réducteur gère la clé particulière.
Partitionneur Hadoop par défaut
Partitionneur de hachage est le partitionneur par défaut. Il calcule une valeur de hachage pour la clé. Il attribue également la partition en fonction de ce résultat.
Combien de partitionneur dans Hadoop ?
Le nombre total de partitionneur dépend du nombre de réducteurs. Hadoop Partitioner divise les données en fonction du nombre de réducteurs. Il est défini par JobConf.setNumReduceTasks() méthode.
Ainsi, le réducteur unique traite les données d'un partitionneur unique. La chose importante à noter est que le framework crée un partitionneur uniquement lorsqu'il existe de nombreux réducteurs.
Mauvais partitionnement dans Hadoop MapReduce
Si dans la saisie de données dans le travail MapReduce, une clé apparaît plus que toute autre clé. Dans ce cas, pour envoyer des données à la partition, nous utilisons deux mécanismes qui sont les suivants :
- La clé apparaissant le plus de fois sera envoyée à une partition.
- Toutes les autres clés seront envoyées aux partitions sur la base de leur hashCode() .
Si hashCode() La méthode ne distribue pas d'autres données de clé sur la plage de partition. Les données ne seront alors pas envoyées aux réducteurs.
Un mauvais partitionnement des données signifie que certains réducteurs auront plus d'entrées de données que d'autres. Ils auront plus de travail à faire que les autres réducteurs. Ainsi, l'ensemble du travail doit attendre qu'un réducteur finisse sa part extra-large de la charge.
Comment surmonter un mauvais partitionnement dans MapReduce ?
Pour surmonter un partitionneur médiocre dans Hadoop MapReduce, nous pouvons créer un partitionneur personnalisé. Cela permet de partager la charge de travail entre différents réducteurs.
Conclusion
En conclusion, Partitioner permet une distribution uniforme de la sortie de la carte sur le réducteur. Dans MapReducer Partitioner, le partitionnement de la sortie de la carte s'effectue sur la base de la clé et de la valeur.
Par conséquent, nous avons couvert la vue d'ensemble complète de Partitioner dans ce blog. J'espère que tu l'as aimé. En cas de doute sur Hadoop Partitioner, n'oubliez pas de nous en faire part.



